XNview
XNview
Elk bestaand digitaal afbeeldingsformaat valt wel te "converteren" met XNview.

Je kan XNview downloaden via www.xnview.com






Elk bestaand digitaal afbeeldingsformaat valt wel te "converteren" met XNview.
Je kan XNview downloaden via www.xnview.com
HTML is geen programmeertaal, maar een markeertaal waarmee je het begin en einde van elk element in een tekst aanduidt.
Met WOBBEL oefen je online in HTML, CSS en javascript.
De eerste typemachine gebruikte een klavier van een piano als toetsenbord.
Voor de eerste keer in de geschiedenis werden knappe jonge vrouwen ingezet in de reclame. De typemachine richtte zich ook op vrouwen. Het bood vrouwen een uitgelezen kans om buitenshuis te gaan werken.

Volg ook de navigatiestructuur van deze website. De verschillende onderdelen vind je daar ook als HTML-pagina's terug.
 1. Hoe werkt het web?
1. Hoe werkt het web?Download de volledige cursus (nieuwe hoofdstukken): Download
Download een ZIP-bestand met afbeeldingen van 'mensen' en '3D-objecten': Download
Download een ZIP-bestand met afbeeldingen van 'alfakanaal':
Download

Voorbeeld van een affiche-ontwerp in Adobe Photoshop.
Onderdelen die aan bod komen:

Heb je het moeilijk om het gezegde van een zin te herkennen? Dit programmaatje helpt je door samen met jou, stap voor stap, het gezegde te zoeken.
Opgelet: het programma is nog niet helemaal klaar, maar je kan het wel al perfect gebruiken. Start...


test blog 2
Hier komt de tekst van het artikel.







Onze industriële garagepoorten bestaan uit standaard panelen die volledig op maat van uw bedrijf worden gemaakt. Zo kan u uw poort laten maken in verschillende kleuren zodat u deze volledig kan afstemmen op de huisstijl van uw bedrijf. U heeft mogelijkheid om een deur en/of kijkvenster in de poort te integreren om zo de functionaliteit van uw industriële garagepoort te vergroten.



Al onze producten voldoen aan de laatste Europese richtlijnen.

MIBA-poorten
Vanaf komend weekend is het Engels Plein opnieuw afgesloten voor doorgaand verkeer
Vanaf komend weekend is het Engels Plein opnieuw afgesloten voor doorgaand verkeer. Het verkeer aan de Vaartkom rijdt dan naast het water, aan de kant van het Engels Plein.De parking van het gebouw Van der Elst blijft bereikbaar via het Engels Plein, vanaf de Kolonel Begaultlaan. Tot eind april werkt de aannemer het Engels Plein af met een voetpad aan het parkeergebouw (voor de winkel), een houten speelveld en bomen. In augustus wordt het voetpad aan het parkeergebouw afgewerkt. Het Engels Plein gaat in september definitief opnieuw open.
Bron: Stad Leuven

Leuven Bears heeft voor het eerst dit kalenderjaar een competitiepartij kunnen winnen.
Leuven Bears heeft voor het eerst dit kalenderjaar een competitiepartij kunnen winnen. De ploeg van coach Van Meerbeeck was sterker dan Brussels (82-74). In de rangschikking blijven de Leuvenaars ondanks hun vierde zege van het seizoen de houder van de rode lantaarn.
De eerste helft was niet veel soeps. Beide ploegen klungelden er op los waardoor het wel spannend bleef (15-17). Bohacik zorgde voor de eerste uitschieter (28-24) maar kon niet vermijden dat de hoofdstedelijken met een kleine voorsprong de rust in doken (ruststand: 36-39). Na de pauze trokken Westrol en Lasisi de partij naar zich toe (52-45). Brussels begaf nog niet en vocht terug tot 55-55. Daarna was het weer Lasisi die zijn ploeg op sleeptouw nam (73-67). In tegenstelling tot de voorbije duels hielden de Bears het hoofd koel en wonnen voor het eerst sinds 20 december 2014. Deroover ontbrak omwille van een buikblessure.

De Leuvense handelaars zijn niet blij met de carnavalsstoet die traditioneel op zaterdag door de stad trekt. Toch haasten de handelaars zich om te stellen dat ze niet tegen carnaval zijn in Leuven. Integendeel, ze verwelkomen de kleurrijke stoet met open armen maar dan wel op zondag.



Hier komt de inleiding.
Wetenschappelijke studies bewijzen dat BioSil fijne lijntjes en rimpels helpt te verminderen, de elasticiteit van de huid verhoogt, het haarvolume en de sterkte van het haar en nagels verbetert, en helpt bij het behoud van sterke botten en soepele gewrichten.
BioSil: de wetenschappelijke doorbraak voor je huid, haar, nagels en botten
Met krill beschikken we over omega-3 van topkwaliteit.
Krillolie heeft een aantal grote voordelen ten opzichte van visolie:
Magic Krill is de ideale omegamix als aanvulling op de westerse voeding, kortom het allerbeste voor jouw gezondheid!

Een aantal kilo's teveel? Een Bourgondische periode achter de rug? Bereik opnieuw je silhouet van je dromen op een veilige en gezonde manier. Bevat enkel natuurlijke ingrediënten.
Prijs: € 48
Je hebt resultaat bereikt met Slimming A en je wil verder? Bereik absoluut je silhouet van je dromen op een veilige en gezonde manier. Bevat enkel natuurlijke ingrediënten.
Prijs: € 48

Reinigende en voedende spons voor de gevoelige huid. Deze spons mag ook gebruikt worden voor baby's.

Reinigende en voedende spons voor het hele lichaam. De Green Tea spons zal je huid zachter en gladder maken.

antioxidant, maakt de huid zachter, gladder en subtieler

verbetert cel-regeneratie, goed tegen acné, wegwerken van mee-eters

voor de gevoelige huid, puur de vitaminen en mineralen van de Konjac plant

krachtig antioxidant, tegen vrije-radicalen, + 40 jaar

tegen vette huid, tegen tieneracne break-outs, tieners

tegen eczeem en dermatitis, tegen acne en vlekken, combinatie huid

huid verzachten en elastisch maken, voorkomt vlekken of pigmentatie, herstellen en voeden van de huid

krachtig antioxidant, anti-veroudering, verbetering collageen

voor de gevoelige huid, verstevigen van de huid, anti-rimpel

verzacht en hydrateert, beschermt tegen vervuiling, voor droge huid



















Ben je minder energiek? Iets prikkelbaarder? Een zwaar gevoel?
Minder goede stoelgang? Dan is je organisme wellicht vervuild.
Door verkeerde voeding, stress, tijdsdruk, opgekropte emoties zijn vitale organen als lever, blaas, nieren, maag en darmen overbelast. Hou je lichaam gezond met regelmatige ontgiftingskuren.
Een inwendige zuivering die werkt. Je voelt het verschil.
Prijs: € 29
Deze zachte en huidvriendelijke reiniging zuivert de huid in de diepte, zonder het gebruik van schurende deeltjes. De zuiverende reiniging, verfijnt de huid, verwijdert onzuiverheden en bereid de huid voor op het liftende masker.
Evenwaardig aan meest gerenommeerde schoonheidsinstituten, zorgt het liftend masker voor een âhervormingâ van de gezichtscontouren in slechts enkele minuten terwijl het de huid hydrateert en beschermd. Een krachtige lifting en micro-circulatie activator. Liftend masker brengt u een gevoel van blijvende huidverjonging bij elk gebruik.
Speciaal ontwikkeld voor gebruik na het liftend masker. Het serum hersteld, kalmeert en hydrateert voor een stralende teint. De anti-rimpel ingrediënten werken in de diepte en hebben een blijvend effect op rimpels en fijne lijntjes.
De verschillende anti-verouderingsingrediënten werken bij iedere aanbreng geleidelijk op elkaar in en zorgen week na week voor een diep en blijvend anti-verouderingseffect.












Hier komt de inleiding.
Hier komt de tekst van het a
rtikel.

Hier komt de inleiding.
P
 our lâassurance maison nous nâavons que trouvez 4 use cases. Cela pourrait donc signifier que lâIoT dans ce type dâassurance est encore dans une phase dâintroduction.
our lâassurance maison nous nâavons que trouvez 4 use cases. Cela pourrait donc signifier que lâIoT dans ce type dâassurance est encore dans une phase dâintroduction.
Exemple de use case: Dans les états unis lâassureur Western Property & Casualty Insurance offre une réduction de prime pour lâassurance maison quand un smart-thermostat est acheté et installé par un installateur avec certificat INCERT. Un exemple dâun objet connecté qui fera en sorte quâune réduction de prime sera appliquée est le smart-thermostat Nest de Google. Nest Protect est non seulement un détecteur de fumé mais aussi un détecteur de CO qui vous appelle sur votre smartphone dès quâil détecte de la fumé, ou un taux haut de carbone. Il vous prévient avant que de grands accidents peuvent arriver. Le but de cette action de Western Property & Casualty insurance est que le client achète sont smart-thermostat lui-même (pour le Nest Protect câest un prix de $129) et ensuite prouve a son assurance quâelle a été installé par un installateur avec certificat INCERT. De cette façon le client obtiendra une réduction et lâassureur aura diminué le risque dâincendie ou dâintoxication CO.
Hier komt de inleiding.
P
 our lâassurance maison nous nâavons que trouvez 4 use cases. Cela pourrait donc signifier que lâIoT dans ce type dâassurance est encore dans une phase dâintroduction.
our lâassurance maison nous nâavons que trouvez 4 use cases. Cela pourrait donc signifier que lâIoT dans ce type dâassurance est encore dans une phase dâintroduction.
Exemple de use case: Dans les états unis lâassureur Western Property & Casualty Insurance offre une réduction de prime pour lâassurance maison quand un smart-thermostat est acheté et installé par un installateur avec certificat INCERT. Un exemple dâun objet connecté qui fera en sorte quâune réduction de prime sera appliquée est le smart-thermostat Nest de Google. Nest Protect est non seulement un détecteur de fumé mais aussi un détecteur de CO qui vous appelle sur votre smartphone dès quâil détecte de la fumé, ou un taux haut de carbone. Il vous prévient avant que de grands accidents peuvent arriver. Le but de cette action de Western Property & Casualty insurance est que le client achète sont smart-thermostat lui-même (pour le Nest Protect câest un prix de $129) et ensuite prouve a son assurance quâelle a été installé par un installateur avec certificat INCERT. De cette façon le client obtiendra une réduction et lâassureur aura diminué le risque dâincendie ou dâintoxication CO.
Hier komt de inleiding.
Hier komt de tekst van het artikel.

Zo bouw je nieuwe webpagina's in Architext.




Het bewerken van de inhoud van webpagina's in Architext.



Je kan op verschillende manieren afbeeldingen toevoegen aan een pagina.





Een afbeelding kan je snel vervangen door er op te klikken. Bekijk de stappen 7 en 8 hier boven.
30 jan

In 2015 schreef ik aan de KULeuven een paper met als titel âDe functie en betekenis van dierensymboliek in de berichtgeving rond de Tiense Furie (1635) â. Op zich een vreemde titel voor wie niet zo veel af weet van het verleden van de âzoeteâ stad. Het behandelt de berichtgeving rond de Tiense Furie, waarin zo goed als de hele stad werd vernield in de blinde oorlog tussen Nederland en Frankrijk aan de ene kant, Spanje aan de andere kant. Godsdienst werd ook toen âgebruiktâ om politieke belangen te dienen, een visie die vaak omgedraaid wordt en dan heet het godsdienstoorlog.
De vernietigende brand van de Furie had niet alleen de stad in puin gelegd, maar ook de binnen de muren opgeslagen voorraad graan was in de vlammen opgegaan, waardoor Frederik-Hendrik zijn leger niet meer van het benodigde voedsel kon voorzien. De Tiense Furie en het nieuws over de plunderingen en baldadigheden hadden een afschrikkend effect op de wijde omgeving. Een aantal Franse soldaten deserteerden door het uitblijven van soldij en het gebrek aan voedsel. Een poging om nog snel Leuven te bezetten, mislukte hierdoor. De hoop van de Republiek om de katholieken in het zuiden voor zich te winnen, ging door de berichtgeving over de verkrachtingen, de martelingen en de verwoestende brand voorgoed verloren.
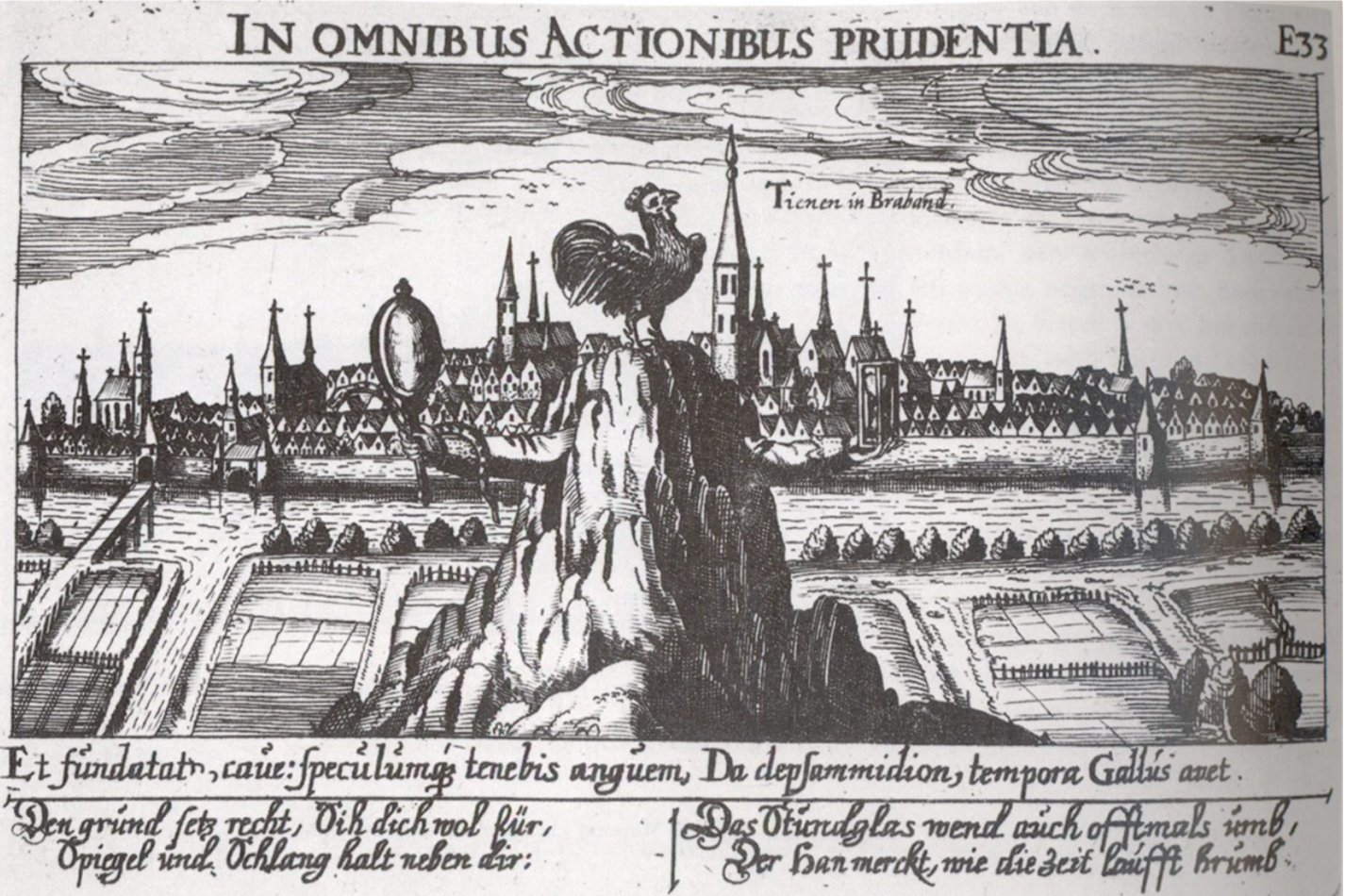
In prenten uit die tijd vertolkten tekenaars de gevoelens van de strijdende partijen en van Tienen zelf. EeÌn van de prenten toont een zicht op de stad Tienen. Op een rots, symbool voor onverzettelijkheid, staat een haan die de waakzaamheid uitbeeldt. Uit de rots steken twee armen. Een slang slingert rond de rechterarm die een spiegel vasthoudt. De spiegel symboliseert zelfkennis. De slang verpersoonlijkt hier niet het kwaad uit het boek Genesis, maar de voorzichtigheid. Het schaap op het wapenschild van Tienen dook op na de Tiense Furie en stond bijna letterlijk voor de vermoorde (geofferde) onschuld. Het beeld van de schapen maakt nog steeds deel uit van de symboliek van de stad Tienen.
In vergelijking met andere Brabantse steden kent Tienen zo goed als geen gebouwen meer die dateren van voor de zeventiende eeuw. Het Burgerhuis Ark van NoeÌ in de gelijknamige Ark van NoeÌstraat zou eÌeÌn van de enige huizen zijn die de brand van 1635 zou hebben overleefd. Hieraan zou het gebouw ook zijn naam te danken hebben. Plaatsnaamkundige Paul Kempeneers toonde echter aan dat hiervoor geen historisch bewijs te vinden is. Een ander gebouw van voor de Furie zou het verkommerde Sint-Jansgasthuisin de Gasthuismolenstraat zijn.
 Het mag dan ook vreemd heten dat de Tiense politici tot op heden,
ondanks talloze beloftes, en aangekondigde verbouwingen (de stellingen voor het gebouw zijn ondertussen zelf reeds aan restauratie toe) niets ondernemen om dit stuk van het stedelijk verleden te conserveren. De berichten over âI love Tienenâ die de sociale media sinds een paar weken opvrolijken, getuigen wel van een hernieuwd voornemen om de verkommerde stad te herleven⦠iets wat we vaker horen bij het begin van een nieuw jaar. Simultaan duiken echter persberichten op over het aanpakken van de leegstand en verkrotting.
Het oude vergeten Sint-Jansgasthuis dient daarbij opnieuw als coverbeeld
. Boetes op leegstand zullen verhoogd worden om dit probleem aan te pakken.
Was dit gebouw niet eigendom van de gemeente zelf? Hoe zit dat dan met die boete?
Het verleden mag geld opleveren, maar geen kosten? Het voelt vreemd dat politici in al die jaren van goede voornemens hun beloftes niet nakomen en echt werk maken van een degelijke conservatie. Ook hier lijkt, jammer genoeg, het
kortetermijndenkente primeren. Het lijkt een kroniek van een aangekondigde dood. In âThe History Manifestoâ schreven de historici Jo Guldi en David Armitage:
Het mag dan ook vreemd heten dat de Tiense politici tot op heden,
ondanks talloze beloftes, en aangekondigde verbouwingen (de stellingen voor het gebouw zijn ondertussen zelf reeds aan restauratie toe) niets ondernemen om dit stuk van het stedelijk verleden te conserveren. De berichten over âI love Tienenâ die de sociale media sinds een paar weken opvrolijken, getuigen wel van een hernieuwd voornemen om de verkommerde stad te herleven⦠iets wat we vaker horen bij het begin van een nieuw jaar. Simultaan duiken echter persberichten op over het aanpakken van de leegstand en verkrotting.
Het oude vergeten Sint-Jansgasthuis dient daarbij opnieuw als coverbeeld
. Boetes op leegstand zullen verhoogd worden om dit probleem aan te pakken.
Was dit gebouw niet eigendom van de gemeente zelf? Hoe zit dat dan met die boete?
Het verleden mag geld opleveren, maar geen kosten? Het voelt vreemd dat politici in al die jaren van goede voornemens hun beloftes niet nakomen en echt werk maken van een degelijke conservatie. Ook hier lijkt, jammer genoeg, het
kortetermijndenkente primeren. Het lijkt een kroniek van een aangekondigde dood. In âThe History Manifestoâ schreven de historici Jo Guldi en David Armitage:
âA spectre is haunting our time: the spectre of the short term.We live in a moment of accelerating crisisthat is characterisedby the shortage of long-term thinking.â
Voor wie echt een hart heeft voor Tienen en dit letterlijk zichtbaar maakt door een sticker op de jas te plakken, laat dit dan ook wat dieper gaan. Kijk in het hart van uw eigen stad, naar het verleden dat er achter ligt. Kijk als waakzame hanen in de spieghel historiael, voorbij de oppervlakkigheid van een opgeplakt hart, vooraleer de Furie van het kortetermijndenken uw laatste resten verleden ontneemt. Aan de dames en heren politici die blaken van goede voornemens: schep duidelijkheid, toon daadkracht. Laat het niet bij denken alleen, maar durf nu eindelijk te doen.
Kris Merckx

In Architext bouw je een site door een nieuwe bundel aan te maken. Een "bundel" of "site" is eigenlijk een soort van rubriek. Vergelijk het met een krant. Een krant bevat meerdere rubrieken en elke rubriek behandelt een bepaald thema.
Wanneer je dus een Nederlandstalige en een Franstalige site wil, bouw je gewoon 2 bundels.






De meeste gebruikers vinden de "navigatiestructuur" het leukste onderdeel van Architext. Vooral mannen natuurlijk, want het is leuk speelgoed.



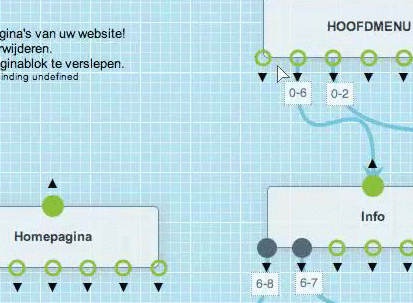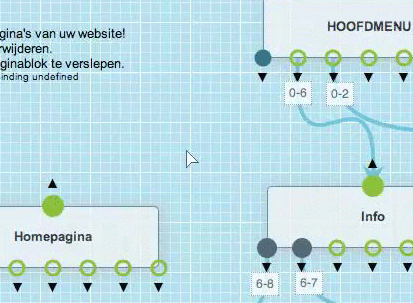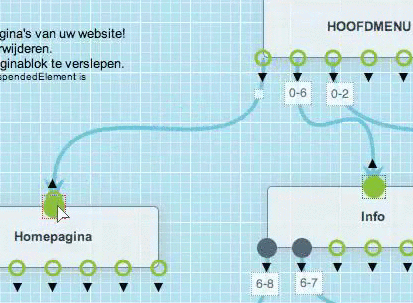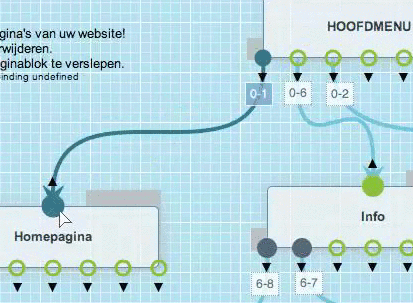

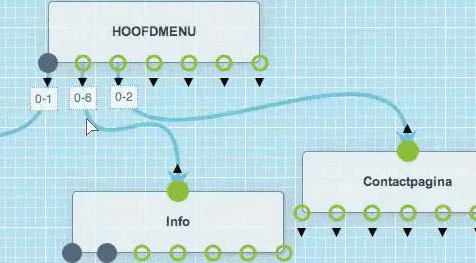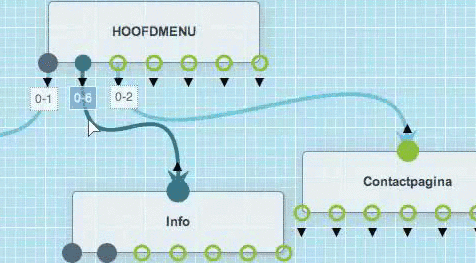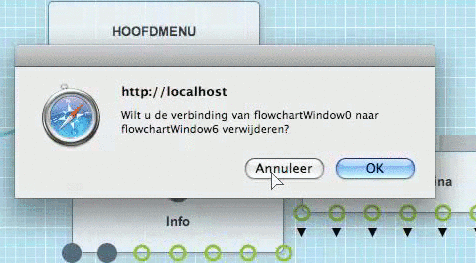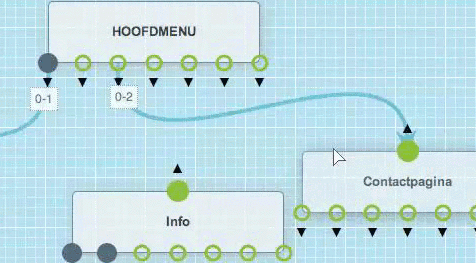
Je kan een bundel of pagina heel simpel verwijderen.





Panikeer niet als je per ongeluk een pagina verwijderd hebt. De inhouden die op de pagina stonden, zijn artikels en die worden afzonderlijk bewaard. Je kan dus heel snel dezelfde pagina opnieuw bouwen.
AR_code laat je toe om heel snel speciale code in te voeren in je HTML. Voor de nerds onder de gebruikers: custom tags



<fbcomments>Aantal</fbcomments>
<fbrecommend>item</fbrecommend>
<fbshare>item</fbshare>
<fblikeposts>item</fblikeposts>
<fblike>item</fblike>
<fbfollow>item</fbfollow>
<here></here>
<ar_url></ar_url>
<hier></hier>
<ar_thissite></ar_thissite>
<site></site>
<ar_license></ar_license>
<ar_author></ar_author>
<google>zoekterm</google>
<yt>zoekterm</yt>
<nlwiki>zoekterm</nlwiki>
<enwiki></enwiki>zoekterm
<gmap>plaats</gmap>
<ar_systemname></ar_systemname>
Iedereen kent wel het getal pi. Minder bekend is het Griekse getal PHI voor de gulden snede. Reeds in de Oudheid bestond het geloof dat alles wiskundig verklaarbaar was, of beter gezegd, "meetbaar", in de vorm van getallen of verhoudingen van getallen. Alles was uit te drukken in verhoudingen tussen die getallen, ratio's. De meest perfecte ratio was terug te vinden in de Gulden Snede, waarin vormen zich met een ratio van circa 1.6 tot elkaar verhouden.
Bron: STRATEN, M., Tien verdwenen dagen, 2012.
`1/2 + sqrt(5)/2 = (1+sqrt(5))/2 = phi`
De vierkantswortel van 5 bedraagt ongeveer 2,236068. De Gulden Snede is dan ongeveer `(1+2.236068)/2 = 3.236068/2 = 1,618034`.



Phi is een irrationaal getal, want vreemd genoeg kan je zeggen dat
Dit zou je eveneens als volgt kunnen omschrijven:
In het artikel "rekenen van rechts naar links" kom je te weten hoe we rekenen met machten en posities.
Wij rekenen met het decimale of tiendelige talstelsel omdat we tien vingers hebben. Er bestaan echter ook andere getalsystemen, zoals het 16-delige of hexadecimale talstelsel. Daarvoor hebben we dus 16 verschillende cijfers voor nodig. In het tiendelige talstelsel gebruiken we de tien Arabische cijfers (en de van oorsprong Indische 0). We gebruiken de cijfers 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Tien verschillende cijfers of SYMBOLEN.
Vermits de positie van het cijfer in het getal de waarde verhoogt, kunnen we voor het hexadecimale stelsel dus niet simpel verder gaan met 10, 11, 12 enz.
Om tot 16 verschillende symbolen te komen, gebruiken we in het hexadecimale stelsel voor de overige symbolen letters. Zo komen we eveneens tot 16 verschillende tekens:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F
A=10, B=11, C=12, D=13, E=14, F=15
|
Cijfer
|
F | F |
|
Positie
|
1 | |
|
Waarde
|
15*16
1=240
|
15 * 16
=15
|
Het getal FF komt dus overeen met de waarde 255 in het decimale talstelsel. In kleursystemen gebruikt men vaak hexadecimale waardes. De kleur #FFFFFF staat voor FF waarde rood, FF waarde groen, FF waarde blauw. Als we die waardes "mengen", krijgen we wit. De waarde 00 rood, 00 groen, 00 blauw geeft zwart. Er zit namelijk geen enkele kleur in.
| RGB | R | G | B | Resultaat |
| #000000 | 00 | 00 | 00 |
|
| #FF0000 | FF | 00 | 00 |
|
| #00FF00 | 00 | FF | 00 |
|
| #0000FF | 00 | 00 | FF |
blauw
|
Bij RGB-waardes moet je het hexadecimale getal dus eerst opsplitsen in groepjes van 2 en niet de totale waarde berekenen. Door een getal met twee posities te nemen in het hexadecimale talstelsel, kan je voor elke kleur 256 verschillende combinaties bekomen.
In totaal kan je met het RGB-systeem op die manier (met enkel 6 symbolen!)
256
3 = 256 * 256 * 256 = 16 777 216kleurcombinaties samenstellen.

Bron afbeelding:
https://en.wikipedia.org/wiki/RGB_color_model#/media/File:RGB_illumination.jpg
Copyright: Kris Merckx -
http://www.ardeco.be- 2015
Copyright: Kris Merckx 2015
Dit boek start met deel 0. In programmeertalenis het eerste element in een reeks objecten nooit gewoon 1, maar element 0. In menselijke taal zouden we dit deel de inleiding noemen, maar toch is het belangrijk dat je net deze inleiding even leest. Hiernaast zie je een afbeelding, een soort cirkel, een voorstelling van het IPOS-modelwaarover je meteen meer leest.
In dit boek probeer ik je digitale systemen beter te leren begrijpen. Je leert meer over hun werking, over hun mogelijkheden en beperkingen en over de uitdagingen voor de toekomst. Je zal interactief leren door te doen en te ervaren.
Wat is een computersysteem eigenlijk en hoe werkt het? Nee, we gaan niet uitleggen wat een harde schijf is en waarvoor RAM-geheugen dient... dat weet je ondertussen ook al wel. Maar we gaan even een heel klein beetje de filosofische tour op. Als je alle computersystemen op een hoop gooit, wat hebben ze dan gemeenschappelijk?
Meestal komt dan het zogenaamde IPOS-modelom de hoek kijken: Input â Processing â Output â Storage.
1. Onder inputverstaan we alle soorten informatie die je in zo'n toestel propt: tekst, foto's, film, muziek... Hiervoor heb je een reeks invoerapparaten nodig: een toetsenbord, een webcam, een USB-kabel, een SD-kaart, een scanner, muis, microfoon of zelfs gewoon een andere computer. Een computersysteem kan ook zelf op zoek gaan naar invoerdata, zoals dat bij BIG DATA wel eens gebeurt.
2. Het toestel zal met die informatie iets gaan doen. In een aantal gevallen vind er een conversieslag plaats, een vertaling van analoge informatie naar digitale informatie (hier leer je nog over). Die verwerking of â processingâ kan gebeuren tijdens de invoer of achteraf als de computergebruiker die input wil bewerken. Als je een tekst intikt in een tekstverwerker gebeurt de input en verwerking simultaan. Wanneer je een foto bewerkt in een beeldbewerkingsprogramma, dan gebeurt de verwerking meestal achteraf.
3. Om dit mogelijk te maken moet het computersysteem ook in staat zijn de ingevoerde data te bewaren ( storage).
4. Een computersysteem zal de gebruiker feedbackgeven. Dat kan in realtime door bijvoorbeeld te zeggen dat er iets fout is gegaan, door een bevestiging te vragen enz. Een programma kan ook feedback geven aan zichzelf: als dit gebeurt, dan doe ik dat, in het andere geval... In zo'n geval spreken we van âopen loopâ-feedback. Wanneer de gebruiker op één of andere manier moet bevestigen of iets doen, dan spreken we van âclosed loopâ-feedback.
5. Maar de bedoeling is meestal dat de computer toont wat het resultaat van die bewerking is. In veel gevallen ziet de gebruiker het resultaat meteen op een scherm. Je ziet meteen het eindresultaat: what you see, is what you get ( WYSIWYG). Ook nadien kan je de bewaarde en verwerkte data nog âbekijkenâ door het bestand te openen, af te drukken, te posten op een website enz. Inderdaad, dat is wat we met outputbedoelen.

In wezen is een computersysteem voor een deel gebouwd naar hoe we onze âeigenâ werking als mens zien. Je ondergaat heel wat âinvloedenâ van je omgeving, van het weer tot die giftige sneer van een opmerking die de docent je gaf tijdens de les omdat je even niet aan het opletten was. Je hoort, ziet, proeft, voelt... en je registreert (INPUT via ondermeer âsensorenâ), je selecteert waar je mee bezig wil zijn (je favoriete APPS) of moet zijn (standaard PROCESSEN), je verwerkt het (soms krijg je het niet verwerkt en CRASH je letterlijk). Je zegt soms dat het allemaal een beetje te veel is of dat je geen twee dingen tegelijk kan (te weinig RAM-geheugen, MULTITASKING). Je onthoudt ook zaken, dat kan gaan over pure herinneringen aan gebeurtenissen in je leven, verplichte leerstof, ervaringen (kortom FILES en FOLDERS). Sommige dingen heb je niet geleerd, je doet ze automatisch zoals bijvoorbeeld ademen (BIOS, OPERATING SYSTEM). Maar je leert ook dingen doen: je kan fietsen, koffie maken, schrijven (PROGRAMMA's, SOFTWARE, APPS). En uiteindelijk geef ook jij feedback: je kan boos zijn om wat men je aandoet of net heel blij of gelukkig (FEEDBACK). Of je kan een alarminstallatie installeren omdat er werd ingebroken (FEEDBACK = nieuwe SOFTWARE). Je gaat naar school om nieuwe dingen te leren doen (APPS) om later werk te vinden (PROCESSING).
Uiteraard stemt dit niet overeen met de werkelijkheid van wat het is om een mens te zijn. Een mens is geen computer en herinneringen werken volledig anders dan "files". Het helpt enkel om de werking van een systeem beter te vatten.
Onderstaand artikel uit Cursus multimedia (K. Merckx)
Computers, laptops, tablets, smartphones, internet of things... Hoe maken we die digitale en elektronische wereld bevattelijk? Er is meer onder de zon dan de strijd tussen Microsoft en Apple of Android en iOS. In dit hoofdstuk leer je je weg te vinden in wat digitaal en elektronisch nu eigenlijk is. Hoe verhouden de diverse toestellen zich tot elkaar? Wat is het verschil tussen de boordcomputer in je auto en je laptop? Is je TV ook een computer als je ermee op internet kan?
Je zal een stap voor zijn op de meerderheid van het grote publiek dat zulke toestellen wel massaal gebruikt, maar eigenlijk niet goed weet hoe die werken en nog veel minder hoe je zo'n toestellen zelf op maat kan bouwen. Wat leeft er allemaal in die âdigitale wereldâ? Wat is het verschil of de verhouding tussen analoog en digitaal, tussen elektronica en computers, tussen computers en microcontrollers, tussen embedded systemen en firmware, tussen hardware en software? Volg je nog? Ok, laat het ons een even allemaal op een rijtje zetten. Opgelet: we staan niet stil bij klassieke computers of televisietoestellen of diverse âmerkenâ.
Een computer(de hardware), of het nu gaat om een klassiek desktop-onding, een tablet, smartphone of een laptop, bestaat uit een hoop onderdelen. Je vindt er een processor in, een tijdelijk werkgeheugen (RAM), een opslagmedium (harde schijf, SSD, SD...), invoerapparaten (muis, touchscreen, toetsenbord...) en ook een outputsysteem (bestanden, scherm, webserver...). Al die diverse toestellen doen in wezen niet zo'n aardig verschillende dingen. Ze verwerken invoer en tonen en/of bewaren de uitvoer. Dat heb je op de schoolbanken geleerd. Ze kunnen niet zonder âsoftwareâ, de ongrijpbare programma's die ergens virtueel zijn âgeïnstalleerdâ als digitale gegevens op een opslagmedium. De softwaregeeft onder de vorm van âbinaireâ code instructies aan de toestellen, verwerkt de invoer en presenteert de uitvoer.
Software bestaat op diverse niveaus:
1. een basissysteem (bios, uefi) dat de contacten tussen alle onderdelen regelt,
2. een besturingssysteem (zoals Android, iOS, Linux, Mac OS X, UNIX, Windows...)
3. of gewoon software met een heel specifieke taak (zoals GIMP, MS Word of... Processing).
Maar er bestaan ook andere verschijningsvormen die men gemakshalve eveneens aanduidt met de naam âcomputerâ, maar in wezen niet helemaal voldoen aan de definitie hier boven. Een microcontroller is zo'n âcomputerâ. Men gebruikt een microcontroller of microprocessor om elektronische apparatuur te besturen. Heel wat moderne apparaten bevatten zo'n microcontroller: een magnetron, een auto, een wasmachine, sommige telefoons...

Er bestaan ook kruisbestuivingentussen beide. De immens populaire Raspberry Piis daar een voorbeeld van.
Ongetwijfeld heb je op het vlak van âconsumentenelektronicaâ al gehoord over â embedded systemenâ en â firmwareâ. Een embedded system (ingebed of geïntegreerd systeem) is heel vaak gebaseerd op een microcontroller (met een microprocessor en/of DSP of 'digital signal processor') of op een SoC (System on a chip). Het vervult een bepaalde functie binnen een groter mechanisch of elektrisch systeem.In een koelkast kan het de temperatuur regelen, in een wasmachine regelt het de functie van alle âprogramma-instellingenâ, in je auto zorgt het voor alle foutmeldingen die op je dashboard verschijnen, maar ook voor alle andere digitale informatie, voor het aansturen van bepaalde onderdelen van je motor enz.
Vroeger bestonden regelsystemenhoofdzakelijk uit mechanische en later elektronische onderdelen. Nu neemt de in een âmicrocontrollerâ geïntegreerde software veel van die taken over. Een microcontroller integreert hardware en software. Er zit geen âharde schijfâ in waarop de software manueel kan geïnstalleerd worden, vaak zit de software geïntegreerd in de hardware, als vrijwel niet te wijzigen programma's. Soms kan de ingesloten software geüpdated worden, dan spreekt men van â firmwareâ.
Zo'n integratie biedt tal van voordelen in vergelijking met een âcomputerâ.
Nadeel is dat de functionaliteit heel beperkt is. Je kan bijvoorbeeld geen tekstverwerker installeren in je koelkast of videomontagesoftware in je auto.
Het Leuvense IT-bedrijf EASICS ontwikkelde de beeldherkenningshardware waarmee de sorteermachines van de Belgische firma BEST zijn uitgerust.De hardware van EASICS herkent tegen een onwaarschijnlijk hoog tempo âongewensteâ elementen tussen bijvoorbeeld razendsnel voorbij rollende frieten, krenten, garnalen, spijkers of wat dan ook en activeert een luchtdrukstraal die het ongewenste element wegspuit. Een âmultifunctioneleâ computer, hoe krachtig en snel ook, zou er niet in slagen om die taak zo snel af te handelen. Omdat de programmacode in de chip is gecodeerd, verloopt de verwerking hier onwaarschijnlijk snel.
Even bekeken volgens et IPO-model: input = beeld van camera, processing = herkennen van ongewenste elementen, output en feedback = verwijderen van ongewenst element.
Vaak worden embedded systemen met één bepaald doel voor ogen ontwikkeld, zijn ze heel âgespecialiseerdâ, maar je kan ook herbruikbare microcontrollersontwikkelen... en dan zitten we bij de Arduinoaan het juiste adres als âstartersmodelâ.

Een eigenhandig gebouwde smartphone op basis van een Arduino-microcontroller.
Een âembedded systeemâ bevat een sensorgedeeltedat informatie uit de werkelijkheid kan registreren. In een tweede fase kan het die informatie digitaliseren. Die digitale informatie moet verwerkt worden door de âmicroprocessorâ of de firmware. In een laatste fase zal een â actuatorâ bepaalde onderdelen aansturen of zorgen voor zichtbare of hoorbare output.
Naast de term âmicrocontrollerâ en âembedded systemâ duikt ook wel eens de term âsystem on a chipâ (SoC)op. Een SoC (met een C wel te begrijpen), integreert alle componenten van een computer en/of elektronisch systeem op één enkele chip. SoC's worden veelvuldig toegepast in de markt van mobiele consumentenelektronica. Een âembedded systeemâ bevat vaak een SoC.

Oeps, waar ligt dan de grens tussen een âmicrocontrollerâ en een âSoCâ? De term âSystem on a chipâ is in dat geval niet de beste keuze geweest. Immers, een âmicrocontrollerâ is vaak pas echt gebaseerd op één enkele chip, waardoor het beschikbare RAM-geheugen vaak onder de 100 kb blijft. Een SoC bevat vaak een veel snellere processor met meer werkgeheugen waardoor het in staat is om een besturingssystemen zoals Linux te draaien. Het is dus niet altijd echt één chip, want een SoC maakt vaak gebruik van externe geheugenchips (SD-kaartje, RAM...). Een modern besturingssysteem, hoe compact ook, heeft wel wat meer nodig dan 100 kb. Het begrip SoC verwijst dus eerder naar een zeer sterke integratie van de chips, waardoor kleinere systemen mogelijk worden.
Waarom zou je met zulke toestellen aan de slag gaan of er tijd in steken, want in wezen zijn ze veel trager dan een standaard âcomputerâ of zelfs een goedkope smartphone? Embedded systemen en microcontrollers zijn aan een ware veroveringstocht bezig. Wellicht hoorde je de term âinternet of thingsâal eens vallen. Ruwweg houdt dit in dat stilaan elk huishoudelijk toestel, maar ook auto's, bewakingscamera'sen domoticasystemenzulke embedded systemen aan boord hebben. Wanneer je al die dingen (things) aansluit op het internet, krijg je een allesomvattend netwerk van digitaal verbonden toestellen: het internet of things. We stellen ons hier even geen vragen over de gevolgen en gevaren voor de privacy en de ethiek.
Kortom, embedded systemen, SoC's en microcontrollers zijn niet meer weg te denken uit de wereld van vandaag en morgen. Be prepared!Wees voorbereid, want wie het kent, kan er zijn voordeel uit halen en zich behoeden voor al te grote 'schendingen' van zijn vrijheid en privacy. Hoe meer je erover weet, hoe beter je er mee kan omgaan, hoe beter je het systeem kan âhackenâ (=uit elkaar halen en begrijpen).
De fysieke wereld waarin wij leven gedraagt zich
analoog. Natuurkundige fenomenen zoals licht, geluid, temperatuur ... kunnen voortdurend wijzigen. Een
elektronisch apparaat
zet signalen uit de omgeving (geluid, licht, warmte ...) om in elektrische signalen (spanningen, stromen ...). Net zoals een foto-elektrische cel licht omzet in een elektrisch signaal, zet een microfoon drukgolven in de lucht om in een veranderlijke elektrische spanning.
Een computer is een elektronisch systeem, maar niet elk elektronisch systeem is een computer;Een televisietoestel verwerkt net zoals een computer een binnenkomend signaal met behulp van elektronische onderdelen en toont die op het scherm. Maar dit betekent daarom nog niet dat een televisietoestel dan ook een "digitaal" systeem is; Digitale systemen verwerken alle invoer met behulp van binaire code.
Zonder dat we het zelf goed en wel beseffen worden we omringd door sensoren. Je vindt ze in je mobiele telefoons (camera, microfoon, accelerometer ...), het toetsenbord en de muis van je computer, de thermostaat van de verwarming, in automatische lampen, het scherm van een tabletcomputer ... Als je na een nachtje stappen aan de kant wordt gezet door de politie, vind je ze zelfs in de alcoholtester (een chemische sensor). Omdat de opgewekte elektrische signalen vaak te zwak zijn om bruikbaar te zijn, bevat veel elektronica ingebouwde of aangesloten versterkers. Analoog houdt in dat de informatie als een continue golf of âstroomâ wordt opgeslagen. Zoals je weet, bestaat geluid in werkelijkheid uit een reeks voortdurende trillingen in de lucht, een golf met andere woorden. Bij een microfoon brengen de trillingen van de lucht een membraan 1 in beweging. Deze beweging wordt omgezet in een veranderlijk elektrisch signaal, dat opgeslagen kan worden op magneetbanden. Analoog betekent dus ânaar analogie met de werkelijkheidâ. Analoge signalen zijn erg onderhevig aan storingen of interferenties van bijvoorbeeld andere apparaten.
Actuatorenvormen een ander onderdeel van een elektronisch systeem: zij zetten elektrische signalen om in andere signalen zoals mechanische kracht, geluid ... Een luidspreker is een bekend voorbeeld van een actuator. Hij laat de lucht trillen door eerst zelf te trillen. Zo zet een elektrische motor elektriciteit om in een mechanische beweging, een lamp en een beeldscherm zetten elektrische energie om in licht enzovoort.
Naast de invoer via sensoren en de uitvoer via actuatoren voert de elektronica zelf een aantal berekeningen, algoritmes of programmaâs uit op de binnenkomende signalen. Elektronica kan naar analogie met de werkelijkheid het elektrische signaal continue bewaren, zoals dit bijvoorbeeld met geluid op een magneetband gebeurt. Toch kunnen hier wat fouten of afwijkingen optreden. Als je destijds een audiocassette te lang op een warm dashboard liet liggen, merkte je het aan de geluidskwaliteit!

Een klassieke audiocassette bewaarde geluid analoog op een magneetband .
Elektronisch is nog wat anders dan digitaal , ook al hoor je de termen weleens door elkaar gebruiken. Het sleutelwoord bij digitaal is â discretisatie â in ruimte en tijd.Wanneer we analoge informatie digitaliseren, plaatsen we een denkbeeldig raster over de fysieke wereld en meten we de binnenkomende signalen enkel op bepaalde tijdstippen, meestal op vaste intervallen. Dit gebeurt doorgaans zeer snel, want anders zouden we veel âinformatieâ missen. Discretisatie in ruimte en tijd heet in het vakjargon ook wel bemonstering, maar is vooral bekend onder de Engelse benaming âsamplingâ. Een sample of een monster van een beeld noemen we een âpicture elementâ of âpixelâ. Een digitaal systeem meet ook de signaalniveaus (discretisatie van de signaalwaarden), zoals de lichtintensiteit van een pixel.
Bij het bouwen van zoân systeem moeten er vooraf afsprakengemaakt worden. Bij een afbeelding kan dit gaan om de hoeveelheid pixels die men horizontaal of verticaal wil meten, bij geluid over het aantal metingen per seconde. Een audio-cd bevat bijvoorbeeld 44100 samples of metingen per seconde (sample rate van 44.100 Hertz = 44,1 kHz). Elke sample of meting wordt uitgedrukt als een getal tussen 0 en een vooraf bepaalde maximale waarde. Hoe hoger die waarde, hoe groter het bereik en hoe nauwkeuriger het signaal kan worden gemeten en weergegeven. Wanneer we licht meten met slechts twee lichtintensiteitswaarden, bevat ons eindresultaat enkel wit of zwart.
Simpel gezegd werkt een elektronisch of digitaal toestel op basis van elektriciteit en die kent ruwweg maar twee toestanden: aan (1) of uit (0). Het lijkt dus op het eerste gezicht niet zo eenvoudig om getallen hoger dan de waarde 1 te meten of te bewaren in een digitale omgeving. Daarom maken digitale systemen gebruik van het binaire stelsel, een tweetallig getalsysteem dat alle getallen weergeeft met de symbolen 0 en 1.
Een binair cijfer of bit (binary digit) kan dus slechts twee vormen aannemen: een 0 of een 1. Een binair getal noemen we anders naargelang het bereik. Zo noemen we een getal van 8 bits een byte. Wij leren op school letterlijk tellen op onze vingers (digitus in het Latijn) en we gebruiken daarom niet voor niets een tiendelig of decimaal talstelsel. Daarom is het ook even wennen als we met binaire getallen aan het tellen gaan. Je leert meer over binaire getallen via deze link.
Een bereik van 8 bits geeft 2 tot macht 8 (256) mogelijke waarden. Een audio-cd heeft een bereik van 16 bits of 32.768 mogelijke waarden. Deze vorm van discretisatie beiÌnvloedt in sterke mate de kwaliteit. Hoe lager het aantal beschikbare bits of hoe trager het bemonsteren gebeurt, hoe lager de kwaliteit. Een te hoog bereik is echter evenmin zinvol. Het menselijk oor kan de extra kwaliteit toch niet altijd waarnemen.
Daarom probeert men vaak een gulden middenweg te vinden tussen kwaliteit en âbeperkingenâ,zoals opslagcapaciteit en doorvoersnelheid (bijvoorbeeld de snelheid van de internetverbinding). In onze tijd worden digitale gegevens ook opgeslagen en voor langere tijd bewaard.
Hoe gaat dit fysisch precies in zijn werk en welke voordelen biedt deze manier van opslaan? In een digitaal systeem bestaat elke waarde uit een reeks bitjes, die elk afzonderlijk slechts 2 geldige waarden kennen, namelijk 0 of 1. In een elektronische schakeling kunnen we dit zien als een verschil tussen bijvoorbeeld 0 en 1,8 Volt, op een cd als een minuscuul putje of net geen, op een harde schijf als een klein gebiedje dat al dan niet gemagnetiseerd is, op een flash-geheugenkaartje als een pakketje elektronen (elektrische lading) dat wordt vastgehouden in een transistor ...
Samengevat betekent âdigitaalâ dus dat we de informatie bewaren als een reeks binaire getallen.Een geluidsgolf kunnen we bijvoorbeeld weergeven als een reeks getallen met een bepaalde grootte. Als we die getallen op een grafiek zetten, zien we de oorspronkelijke golf weer verschijnen. Digitale informatie wordt altijd met binaire en niet met decimale getallen weergegeven. In het binaire stelsel wordt elk getal voorgesteld als een combinatie van nullen en enen. Binaire getallen zijn uitermate geschikt om door elektrische schakelingen of bedrading te sturen omdat die enkel maar een aan-toestand (1) en uit-toestand (0) herkennen. In een analoog systeem kan elke gewenste waarde tussen een bepaalde ondergrens en bovengrens worden voorgesteld.
Als er ruisoptreedt door bijvoorbeeld slijtage op een magneetband of een elektromagnetische storing, kan het oorspronkelijk signaal niet meer onderscheiden worden van de ruis. De ruis die er achteraf bijgekomen is, heeft de oorspronkelijke signaalniveaus immers aangetast. Ook in een digitaal systeem kan ruis optreden. Een kras in een optische schijf zoals een cd kan putjes minder diep maken of elektromagnetische storingen kunnen bepaalde zones op een harde schijf demagnetiseren. Toch kan over het algemeen het oorspronkelijke niveau hersteld worden (als de storing niet te groot is) omdat elke bit slechts twee geldige waarden heeft: het is ofwel 1 ofwel 0 en daaruit moet het systeem zelf kiezen. Een kras kan bij wijze van spreken van 0 een 0,3 maken, maar die waarde ligt dichter bij de 0 dan bij de 1. Enkel een 0,5 zou een twijfelgeval kunnen worden. Als de schade door slijtage, ruis of storingen dus niet te groot is, kan een digitaal systeem de oorspronkelijke informatie of kwaliteit volledig herstellen. Maar zelfs in het geval van grote schade kan men door codeertechnieken (het uitrekenen van bepaalde controlegetallen over groepen van bits) de fouten toch nog herstellen (uiteraard binnen bepaalde grenzen). Sommige systemen maken gebruik van symbolen die meer dan twee waarden kunnen aannemen, waarbij eÌeÌn geheugencel 2 of 3 bit aan informatie kan bevatten. Dit soort transistors houden pakketjes elektronen van 4 of 8 verschillende (nominale) groottes vast. Zulke systemen zullen echter sneller falen bij kleine storingen of ruis. Toepassingen die een hoge betrouwbaarheid vereisen (zoals medische implantaten of ruimtevaart) zullen daarom 1 bit-cellen gebruiken. Digitalisering biedt nog tal van andere voordelen. Zodra een signaal is gedigitaliseerd, kan het makkelijk bewerkt en aangepast worden. Voor het toepassen van een filter op een afbeelding hebben we bijvoorbeeld niet langer een speciaal onderdeel of toestel nodig, dit kan met een computerprogramma. Dezelfde geheugendragers kunnen gebruikt worden om verschillende vormen van informatie te bewaren: fotoâs, tekst, muziek, beeld, programmaâs â¦
Pulsbreedtemodulatie (PWM of pulse width modulation)is het begrip als het gaat om het omzetten van digitale signalen naar analoge signalen. Cool, echt een begrip om mee uit te pakken aan de toog van je stamcafé, maar je kan best toch zorgen dat je dan tenminste weet waarover je het hebt. Zeker als die onbekende man op de hoek van de toog een ingenieur blijkt te zijn. Ben je er klaar voor?
Stel dat je dit boek nu niet zou lezen, maar dat je naar de audioversie ervan zou luisteren, dan zou het geluid van mijn opgenomen stem de lucht laten trillen. De luchtdeeltjes zouden als een voortdurend wijzigende golf je oren bereiken, met steeds wisselende pieken en dalen: een analoog geluidssignaal, naar âanalogieâ met de werkelijkheid. Nochtans werkt die luispreker op basis van elektrische signalen die nu eens uit en dan weer aan kunnen staan. Ofwel stuur je een pulsje stroom, ofwel niet, want elektriciteit beweegt nu eenmaal niet zoals een golf zeewater. Het is het een of het ander bij elektriciteit. De stroom staat aan of uit, 1 of 0. Hoe kan je dan met elektrische stroom een geluidsgolf genereren, een motor zachter laten draaien, een LED-licht dimmen?
Je kent het antwoord al, met PWM! Maar hoe gaat dit nu in zijn werk?Met PWM moduleren we de stroom. We schakelen bliksemsnel tussen 5V en 0V. Stel dat je de voltage de helft van de tijd instelt op 5V en de helft van de tijd op 0V dan krijg je een gemiddelde stroom van 5V of een âduty cycleâ van 50%. Laat je de stroom 10% van de tijd op 5V staan, dan krijg je gemiddeld 0.5V. Als je op deze manier een motor aanstuurt, zal de motor langzamer draaien bij een lagere duty cycle. De motor krijgt dan wel zijn maximale spanning, maar niet continu. M.a.w. als je de schakelaar continu aan laat staan, zal je motor constant snel draaien, je LED-licht continu âfelâ branden. Als je snel aan en uit pulst, zal de motor zachter beginnen draaien en je licht dimmen.
Het binaire talstelsel werd âbedachtâ door de wiskundige en filosoof Gottfried Wilhelm Leibniz (1646â 1716), een tijdgenoot van het onovertroffen genie Isaac Newton (1643â1727). In zijn tijd zag niemand het nut in van zoân binair talstelsel en hij zelf gebruikte het vermoedelijk enkel in filosofische discussies over godsdienst: de 1 zou daarbij staan voor het bestaan van God en de 0 voor de afwezigheid van God. Andere vondsten van Leibniz, zoals het âis gelijk aanâ-teken (=) of de dubbele punt bij delingen (:), raakten wel ingeburgerd. Het binaire getalsysteem werd in de eerste helft van de 20e eeuw dankbaar opgevist voor gebruik in de eerste digitale computers.
Ook al was het binaire talstelsel nog niet uitgevonden, toch bestond het âdigitaalâ programmeren van machines al veel langer. Heron van Alexandrië bouwde tweeduizend jaar geleden automatische theaters met gewichten, touwen, assen en pinnen. Aan het ene uiteinde van het touw bevestigde hij een gewicht, dat hij boven op een met tarwekorrels gevulde cilinder plaatste. Door een sleufje onder in de cilinder open te trekken, vloeiden de korrels weg. Hierdoor begon het gewicht met enige vertraging te zakken. Aan de andere kant hingen twee touwen. Elke touw was rond een afzonderlijke as (de linker en de rechter vooras) gewikkeld. In beide assen waren op gelijkmatige afstanden gaten geboord. Het zakkende gewicht trok niet alleen aan de touwen, maar liet de beide assen ook draaien. De machine kon eenvoudig geprogrammeerd worden door in de gaten pinnen te plaatsen. Als je een touw rond een bepaalde pin liet teruglopen, kon je een van beide assen op elk gewenst moment in de andere richting laten roteren. Net zoals in moderne programmeertalen slaagde Heron er ook in om een âtimerâ-functie in te bouwen. Hiervoor plakte hij met was een stuk van het touw vast aan de as. Het zakkende gewicht trok het was stilaan los. Als het touw eenmaal was losgekomen, begon de as weer te roteren.

Je zou de instructies voor Herons robot kunnen uitschrijven in de code voor Lego® Mindstorms- robots:
task main(){
OnFwd(OUT_A,75);
OnFwd(OUT_B,100);
Wait(3000);
}
De OnFwd-instructie laat de motor naar keuze (A of B) vooruitbewegen. De Wait-instructie laat het toestel voor een bepaalde duur (milliseconden) halt houden. Uiteraard schreef Heron geen programmeerinstructies. Ze waren vastgelegd in zijn machine, maar op zoân manier dat je het toestel kon herprogrammeren door de pinnen te verplaatsen. Het programma werd âopgeslagenâ in de assen met wat we binaire instructies zouden kunnen noemen. Een pin staat voor een 1, een gat zonder pin voor een 0 (of omgekeerd). Het automatische theater van Heron reed volkomen zelfstandig het podium van het theater op. Daar stopte het en toonde een toneelstuk van mechanische poppen, die eveneens door een mechanisme van pinnen, gewichten, touwen, assen, tandwielen en hefbomen werden aangedreven. Het theater was voorzien van decorwissels en geluidseffecten. Door op een bepaald moment een sleuf open te trekken, vielen loden ballen op een trom, wat het geluid van donder simuleerde.
Wellicht bestond de techniek voor het programmeren van toestellen al langer en heeft Heron het niet zelf bedacht. De techniek om toestellen te programmeren dook ook op bij Islamgeleerden, in middeleeuwse klokken, bij Leonardo da Vinci. In de 18e eeuw paste men de techniek enigszins aan door de cilinders met pinnen te vervangen door kaarten met gaten (ponskaarten). Men begon ze in te zetten voor het automatisch weven van kleren in weefgetouwen (Jacquard). De techniek van de ponskaart als middel om gegevens of programma-instructies te bewaren, bleef in gebruik als opslagmedium voor computers tot in de jaren 1980.

Een ponskaart voor de opslag van geprogrammeerde muziek (19e eeuw).
1.4 Microcontrollers en SoC's voor doe-het-zelvers
De Arduino is niet enkel een microcontroller. Het is een speciaal ontworpen bord voor het programmeren en het maken van âprototypesâ met Atmel-microcontrollers. Als je er al eentje hebt aangeschaft, zal je ondertussen wel weten dat het goedkoop is. Voor een kleine 25 euro haal je een Arduino UNO in huis. Bovendien is het aardig makkelijk om mee te werken. Je sluit het via USB aan op je computer. Arduino-programma's schrijf je met een gratis stuk software. (http://arduino.cc/en/Main/Software).

De Arduino krijgt stroom via een USB-verbinding, maar kan ook los van de computer functioneren via een netadapter of batterijen. De Arduino meldt zich bij uw computer aan als een âvirtuele seriële poortâ. Als je code schrijft, kan je ze met een eenvoudige klik op de knop uploaden naar de Arduino. De standaard Arduino beschikt over 32 KB flashgeheugen om je code te bewaren. Dat is niet veel, maar ruim voldoende voor de meeste projecten.
Een Arduino telt 13 digitale en 6 analoge pins om externe hardware en sensoren aan te sluiten. Voor wie wat meer thuis is in de elektronicawereld: het bord heeft ook een ICSP-connector waarmee je de Arduino rechtstreeks als een serieel toestel kan aanspreken. Via deze poort kan je de Arduino âherstartenâ (bootload) wanneer de chip niet meer met je computer wil âsprekenâ.
Afhankelijk van het project dat je wilt bouwen, kan je extra bordjes, sensoren of uitvoerapparaten op de Arduino aansluiten of in de pins âklikkenâ. Wanneer je een gewenst onderdeel aankoopt, vind je op de website van de fabrikant over het algemeen het schema voor het bouwen van de hardware-applicatie en de benodigde code. Controleer dit vooraf zodat je niet voor ongewenste verrassingen komt te staan. Houd er ook rekening mee dat je voor sommige modules met een soldeerbout overweg moet kunnen.
|
Sensoren |
Gyroscoop, accelerometer, ultrasone sensor, GPS, IR-afstandssensor, verstelbare IR-sensor, bewegingssensor |
|---|---|
|
Shields |
Wifi, Ethernet, Motor, Color LCD, AM&FMÂontvanger, VoiceBox (voice en sound synthesizer), Musical Intrument, Audio Player, Joystick, Xbee |
|
Modules en adapters |
Voide recognition, radiocommunicatie, Xbee, Bluetooth, WiichunkÂadapter, SDÂ lezer, Power over ethernetÂmodule, GSMÂmodule |
Wiring is de naam van een hardwareproject, een soort broertje of zusje voor Arduino. Meer informatie vind je op . Net zoals Arduino is Wiring een open-source
elektronica prototyping platform. Wat open source is, leer je in een later hoofdstuk.
Je kan er op heel eenvoudige manier een âprototypeâ van een programmeerbare elektronische schakeling mee bouwen.
De Raspberry Pi is een minicomputer (ook wel een singleboardcomputer genoemd) met een ARM-processor die ook dienst kan doen als microcontroller voor kleine elektronicaprojecten. Vermits het een gewone computer is, kan je er ook randapparatuur zoals een muis en toetsenbord (via USB), een microfoon, luidspreker of beeldscherm (TV via HDMI) op aansluiten. Een hele rits Linux-distributies (maar ook bijvoorbeeld Risc OS en Plan 9) zijn geschikt om op de Pi geïnstalleerd te worden. Het toestel kan ingezet worden als fileserver, NAS, mailserver... Voor een kleine 50 euro koop je een Raspberry Pi wat mede heeft bijgedragen tot zijn gigantische succes.

Een Raspberry Pi met een Linuxbesturingssysteem via HDMI aangesloten op een televisie.
Processorfabrikant Intel keek al snel met groeiend ongenoegen naar het succes van de op een ARM-processor gebouwde Raspberry Pi. Daarom lanceerde het bedrijf zijn eigen minicomputer aan onder de naam Intel Galileo. Het toestel draait op de energiezuinige Quark x1000-SoC.
Omdat de Raspberry Pi ook kan gebruikt worden voor elektronicaprojecten zag Intel de Arduino als een nuttige bongenoot in de zijn "oorlog" tegen het ARM-geweld. De Galileo is daarom niet alleen compatibel met zijn "Pentium Instruction Set Architecture", maar ook met de Arduino-bibliotheken en IDE.
Wie toch zijn eigen elektronica wil âprogrammerenâ en samenstellen zonder één letter code te schrijven of met kabels of soldeerbouten aan de slag te moeten gaan, moet zeker eens kijken naar Little bits. Met de eenvoud van Lego bouw je met Little bits coole elektronicaprojecten. Je klikt de diverse onderdelen poepsimpel via kleine magneetjes aan elkaar en klaar is kees.

Audacity: Tijdens de les digitaliseren we audio met het open sourceprogramma Audacity ( www.audacityteam.org). We bekijken hoe het audiosignaal er in digitale vorm uitziet.
Adobe Photoshop / GIMP:We zetten een foto om in zwart-wit en verlagen het aantal pixels drastisch. We bekijken hoe discretisatie aan het werk is gegaan.
http://www.ardeco.be/sirk/screen.html:Pixelweergave met een raster. Hoe stuur je boodschappen door in binair formaat?
Tijdens de les kan een student nota's nemen in de cursus. Dit lukt enkel als de beheerder die mogelijkheid heeft voorzien . Op dit moment kan je nota's nemen, markeringen toevoegen, tekst verwijderen, tekst plakken, afbeeldingen slepen en afdrukken.
De toepassing onthoudt op dit moment je aanpassingen niet. Je kan wel de notities naar je eigen e-mailadres mailen, maar in heel wat mailprogramma's gaan de ingeleurde markeringen verloren. Vetgedrukt, onderstreept, schuin en doorstreept, evenals tekstuele aanpassingen blijven in mail wel bewaard.
1. Ga naar de gewenste pagina.

2. Klik op het knopje links op het beeldscherm.

3. Klik op de knop "Neem notities".

4. Boven de tekst verschijnen de knoppen "Druk pagina af" en "Verzend".

3. Klik in de tekst om aanpassingen aan te brengen. Opgelet: enkel jij ziet deze aanpassingen, anderen niet.

4. Het opmaakmenu verschijnt enkel als je een stuk tekst selecteert.

5. Je kan ook afbeeldingen van je computer naar het artikel slepen, tekst plakken uit andere toepassingen (zoals MS Word, Excel, webpagina's...)
6. Als je klaar bent, kan je de pagina met notities afdrukken.


In dit deel zal je leren hoe mensen communiceren met computers; Welke interactieve mogelijkheden bestaan er? Hoe bouw je een gebruiksvriendelijke interface? Wat zijn programmeertalen en hoe werken ze?
Mensen en computers communiceren met elkaar. Als je op een computer werkt, dan ben je voortdurend in wisselwerking (interactie) met het digitaal systeem. Mens en machine, in dit geval alle denkbare vormen van digitale systemen, kunnen niet zonder problemen met elkaar communiceren. Informatie die voor mensen heel begrijpelijk is, zoals het herkennen van andere mensen en objecten, is voor computers onbegrijpelijk. Een computer zet alle informatie om in enen en nullen, zonder echt te begrijpen waar de inhoud over gaat. Om de communicatie en interactie mogelijk te maken, voorziet een digitaal systeem in een interface. Een interface zorgt ervoor dat de informatie van het ene systeem (mens of computer) herkenbaar en begrijpelijk wordt voor het andere.
In dit deel bekijken we hoe een mens met een computer communiceert. Welke mogelijkheden tot interactiviteit bestaan er op dit moment en wat wordt misschien ooit mogelijk? Hoe ontwerp je een gebruiksvriendelijke en aantrekkelijke interface? Hoe vertellen mensen aan computers welke taken ze moeten verrichten?
Niet alle computers staan rechtstreeks in wisselwerking met de mens. Volgens het IPOS-model definiëren we een computer als een machine die inkomende signalen verwerkt volgens een reeks instructies en op één of andere manier output doorgeeft. Die output kan naar een mens gaan, maar evenzeer naar een andere computer of een databank. In dit deel bekijken we echter die computersystemen die in directe wisselwerking staan met een mens: een smartphone, een PC, een laptop, een tablet... De laag of schil waar mensen en computers in wisselwerking treden, noemen we een interface. Omdat de wisselwerking in twee richtingen gaan spreken we van een interactieve interface. Men spreekt in dit geval van human-machine interaction (HMI), man-machine interaction (MMI) of computer-human interaction (CHI).
De interface richt zich in grote lijnen op visuele output op een display. Via grafische bedieningselementen zoals knoppen, pictogrammen, schuifbalken enz. is interactieve omgang met de computer mogelijk. We spreken daarom van een Graphical User Interface of GUI. (Bron: MERCKX, K.,)
Via een command line interface geeft de gebruiker opdrachten aan het computersysteem door het invoeren van commando's. Nadeel is dat de gebruiker de benodigde commando's moet onthouden. Om dit probleem te verhelpen voorzien veel CLI's ook in een helpfunctie met een overzicht van alle commando's. Die helpfunctie eveneens met een commando opgeroepen worden. In de meeste besturingssystemen is nog steeds een CLI verborgen. Onder Mac OS X heeft dit net zoals op tal van UNIX- en Linux-systemen de Terminal. Linuxnerds zweren bij het gebruik van de Console. Onder Windows kunnen gebruikers het opdrachtregelvenster openen, door velen nog steeds het DOS-venster genoemd (naar het oude besturingssysteem Ms DOS of Microsoft Disk Operating System).
 De huidige CLI's zijn beschikbaar naast de GUI of grafische interface. Oorspronkelijk vormden ze echter de gebruikersinterface voor de meeste computersystemen. Gebruikers gaven via tekstcommando's de opdrachten in. Een CLI ondersteunt over het algemeen het gebruik van de muis niet, enkel invoer van en via het toetsenbord. De monitor toonde de invoer van de gebruiker en de uitvoer via tekstregels die onder elkaar werden weergegeven. De volledige ruimte van het scherm kan niet benut worden. De computermonitoren konden doorgaans slecht een beperkt aantal kleuren of slechts één kleur weergeven.
De huidige CLI's zijn beschikbaar naast de GUI of grafische interface. Oorspronkelijk vormden ze echter de gebruikersinterface voor de meeste computersystemen. Gebruikers gaven via tekstcommando's de opdrachten in. Een CLI ondersteunt over het algemeen het gebruik van de muis niet, enkel invoer van en via het toetsenbord. De monitor toonde de invoer van de gebruiker en de uitvoer via tekstregels die onder elkaar werden weergegeven. De volledige ruimte van het scherm kan niet benut worden. De computermonitoren konden doorgaans slecht een beperkt aantal kleuren of slechts één kleur weergeven.
 De volgende stap of verbetering bestond erin om het ganse scherm te benutten voor de weergave van de output en het gebruik van de muis of een ander pointing device mogelijk te maken. Primitieve vensters en knoppen werden ingezet. Zulke TUI's zijn nog steeds in gebruik voor het instellen van het basissysteem (BIOS) van computers en soms duiken ze ook nog op bij ietwat out-of-date kassasystemen. De diverse CLI-commando's werden verborgen achter âknoppenâ. Een TUI kon aangestuurd worden met de muis, maar al even snel via âmnemonicsâ: in het tekstopschrift op de knop werd één letter onderstreept. Wanneer de gebruiker die indrukte op zijn toetsenbord werd de opdracht uitgevoerd. De eerste versies van de iPod (niet de iPad!) hadden een TUI-interface, net zoals heel wat GSM's.
De volgende stap of verbetering bestond erin om het ganse scherm te benutten voor de weergave van de output en het gebruik van de muis of een ander pointing device mogelijk te maken. Primitieve vensters en knoppen werden ingezet. Zulke TUI's zijn nog steeds in gebruik voor het instellen van het basissysteem (BIOS) van computers en soms duiken ze ook nog op bij ietwat out-of-date kassasystemen. De diverse CLI-commando's werden verborgen achter âknoppenâ. Een TUI kon aangestuurd worden met de muis, maar al even snel via âmnemonicsâ: in het tekstopschrift op de knop werd één letter onderstreept. Wanneer de gebruiker die indrukte op zijn toetsenbord werd de opdracht uitgevoerd. De eerste versies van de iPod (niet de iPad!) hadden een TUI-interface, net zoals heel wat GSM's.



Een grafische gebruikersinterface of GUIverschilt van de voorgaande interfaces omdat het het scherm aanstuurt op pixelniveau via wat men omschrijft als de schermbuffer. Elke pixel kan hierdoor ingekleurd of aangestuurd worden. Dit vraagt echter veel meer rekenkracht van de processor en de grafische kaart. In onze tijd is de rekenkracht meer dan hoog genoeg om dit mogelijk te maken waardoor zelfs tablets en smartphones over een GUI beschikken.
De leercurve van een GUI is laag omdat het uitgaat van het ontwerpprincipe âherkenning boven herinneringâ. De gebruiker hoeft geen commando's meer te 'kennen' of in te voeren. De meeste gebruikers maken geen onderscheid meer tussen de GUI en het achterliggende besturingssysteem. Wanneer men spreekt over MS Windows, Mac OS X, iOS... dan stelt men zich dat vooral visueel voor. In commerciële software zijn OS (besturingssysteem) en GUI inderdaad onlosmakelijk met elkaar verbonden. Onder Linux is dit niet zo. Afhankelijk van de eigen smaak of voorkeur, kan de Linuxgebruiker kiezen tussen diverse desktopomgevingen (desktopomgeving = GUI). De meest bekende GUI's voor Linux zijn Gnome en KDE. Rijzende sterren zijn ondermeer Unity (de desktop van de nieuwe Linux Ubuntu), Xfce, Cinnamon (GUI van Linux Mint). Linux GUI's zijn bijzonder configureerbaar waardoor je het echt op maat kan âversnijdenâ. Het is perfect bruikbaar om in te zetten als KIOSK-computer.
Een gebruiker bedient de GUI via vensters (Window), icoontjes (Icon), menu's (Menu) en bijvoorbeeld een muis en toetsenbord (Pointing Device). Daarom gebruikt men voor een GUI ook wel eens de naam WIMP. Door het gebruik van vensters is multitaskingmogelijk. Je kan meerdere programma's simultaan gebruiken. Binnen een venster voorziet de software-ontwikkelaar een aantal visuele menu's en intuïtief te gebruiken bedieningselementen. Schermpictogrammen maken het mogelijk om een programma snel te starten. Heel wat besturingssystemen proberen het gebruik van pictogrammen op het virtuele bureaublad te beperken. Bij Mac OS X zijn de pictogrammen ondergebracht in de dock onderaan het scherm, maar toch houdt Apple nog meer vast aan het gebruik dan bijvoorbeeld Microsoft. In Apples iOS voor iPhone en iPad zijn schermpictogrammen de manier om het toestel te bedienen. Microsoft heeft schermpictogrammen vervangen door zijn nieuwe metro-interface waarbij ze zijn vervangen door grote aanklikbare vlakken. Toch merk je dat veel gebruikers verknocht zijn aan het gebruik van pictogrammen. Door het gebruik van menubalken en uitklapbare menu's is het oproepen van bepaalde functies en commando's heel makkelijk. In veel gevallen moet de gebruiker eerst het te bewerken onderdeel (een deel van een tekst, een stuk van een afbeelding, het ganse 'bestand'...) selecterenen vervolgens op een menuknop drukken. Met een muis of een andere âpointing deviceâ zoals een tekentablet, een trackpad enz. kan de gebruik op schermpictogrammen of menuknoppen klikken of dubbelklikken, hij kan elementen selecteren of verslepen.
De WIMP-interface is niet bedacht door Apple of Microsoft, ook al lees je vaak het verhaal dat Microsoft de GUI is gaan âstelenâ van Apple. vergeleek hun snelheid en nauwkeurigheid. Uit alle âkandidatenâ, waaronder ook knie-, neus- en hoofdbesturingen, kwam de muis als grote overwinnaar uit de strijd. Hij bedacht ook de grafische gebruikersinterface met vensters, netwerksoftware, het knippen en plakken van tekst op een monitor, hypertekst (aanklikbare tekst) en teleconferencing. Hij vertrok vanuit het leerproces van kinderen zoals de oog-handcoördinatie en niet vanuit wat professionele computergebruikers in die tijd verwachtten. Op 8 december 1968 presenteerde hij zijn technieken in de allereerste teleconferencing ooit via het vooruitstrevende nls (oNLine System). In de vroege jaren zeventig stapten heel wat werknemers van sri over naar Xerox Parc, dat een paar jaar later startte met de ontwikkeling van een computer voor persoonlijk gebruik (pc). Het mag dan ook geen verbazing wekken dat veel ideeën van Douglas werden geïntegreerd. Het was de eerste computer met een grafische gebruikersinterface (gui) met een virtueel âbureaubladâ als schermmetafoor. Veel ideeën van deze eerste gui leefden en leven door in latere besturingssystemen zoals Microsoft Windows, linux kde en gnome, Mac os ... Het virtuele bureaublad had vensters, aanklikbare iconen, uitklapmenuâs voor terugkerende taken zoals het openen, verplaatsen of verwijderen van bestanden. In 1974 begon de ontwikkeling van het programma Gypsy een soort teksteditor die werkte volgens het âWhat you see is what you getâ principe (wysiwyg): wat je op het scherm zag, kun je ongewijzigd afdrukken op een âprinterâ. In 1981 kwam de Xerox Star op de markt, maar de prijs was te hoog om door te breken bij het grote publiek. Andere ontwikkelaars zoals Microsoft, Apple en Amiga (deze firma werd in 1984 opgekocht door het beroemde Commodore om een vervolg te breien aan hun Commodore64-succesverhaal) hadden op dat moment hun ogen al lang de kost gegeven. (Bron: MERCKX, K.,)
De manier waarop mensen een digitale interface bedienen is nog ver verwijderd van de wijze waarop mensen met elkaar communiceren: spraak, aanraking, lichaamstaal en gebaren, gevoelens herkennen... Nieuwe interfaces integreren zoals het aanraakschermen proberen die omgang herkenbaarder en natuurlijker te maken. Hierdoor bepekt het aansturen van commando's zich niet langer tot klikken en dubbelklikken, maar kan de computer ook andere âgebarenâ herkennen. Apple integreerde een deel van die gebarenherkenning ook in de zogenaamde Magic Mouse en trackpad: het toestel herkent niet langer slechts één vinger, maar kan bijvoorbeeld een afbeelding roteren door met twee vingers een draaiende beweging te maken.
Het bouwen van spraakgestuurde interfaces (Voice User Interfaces of VUI) loopt inet van een leien dakje. Hoe dit komt, leer je in deel 3.
Op de consumentenmarkt raken NUI's steeds meer ingeburgerd, vooral dankzij spelcomputers. De Wii herkent de handbewegingen van de gebruikers/speler zo lang hij een pointing device (de Wiimote, een soort afstandsbediening) vasthoudt. De Kinect is een invoerapparaat voor motion sensing met ingebouwde microfoon en webcam van Microsoft voor gebruik bij de Xbox 360. Dankzij de Kinect wordt interactie mogelijk zonder game controllers. Samen met de Wiimote, tablets (iPad) en multitouch-smartphones behoort het tot de eerste generatie STAG (Speech, touch and Gestures)- toestellen. En de Kinect is al zeker zonder enige twijfel het eerste NUI (Natural User Interface)- apparaat voor de massa! Gebaren en gesproken commando's volstaan om instructies door te geven aan de (spel)computer. Sommigen noemen de Kinect ook het eerste voorbeeld van een Zero interface, omdat je niets in je âhandenâ hebt. De software werd ontwikkeld door Rare (een firma die eveneens in handen is van Microsoft) en de cameratechnologie door de IsraeÌlische ontwikkelaars PrimeSense. De camera bouwt een 3D-beeld op van de omgeving aan de hand van infrarood laserprojecties. De 3D-scanner (Light Coding) gebruikt een soort image-based 3D-reconstructie. Het toestel beschikt over voice recognition, full-body 3D motion capture en gezichtsherkenning. Volgens Microsoft herkent het toestel simultaan tot 6 personen en kan het bewegingsanalyse uitvoeren op 2 actieve spelers. PrimeSense daarentegen beweert dat het aantal herkende personen enkel beperkt is door het aantal dat binnen de field-of-view van de camera valt.
De Leap Motionis een via USB aan te sluiten toestel dat gesture recognition naar de gewone computers (Linux, Windows, Mac OS X) brengt.
De afkorting TUI kan staan voor Text User Interface zoals we kennen uit het oeroude DOS of de Terminal van Mac OS X, maar in deze context staat het voor Tangible User Interface. Bij een Tangible User Interfacegebruik je echte voorwerpen als interface-elementen. Bij een TUI worden echte objecten âverhoogdâ (augmented) met digitale functionaliteit! Zo kan je bijvoorbeeld een echte (fysieke) tastbare draaiknop op het scherm plaatsen in plaats van een digitale knop. Wanneer je aan die knop draait, herkent de computer de draaibeweging en voert een daaraan gekoppelde functie uit. Een TUI maakt interactie tussen fysieke objecten en computers mogelijk via markers en computer vision. De PlayStation Eye bestaat uit een digitale camera en gebruikt software en hardware voor computer vision en âgesture recognitionâ. Het toestel kan patronen, kleuren, markers en geluid herkennen.
Jef Raskin, ontwikkelaar van de GUI voor het oorspronkelijke Mac OS-systeem, ontwierp THE (The Humane Environment), later omgedoopt tot Archy ( RASKIN, J.,). Hij combineerde in die omgeving de kracht van een CLI en een GUI. Archy had geen "eindige" virtueel bureaublad (zoals we dat bij Windows en Mac OS X nog steeds terugvinden), maar een oneindige ZUI. Raskin doopte zijn zoomable interface Zoomworld. Zijn ideeën vonden hun weg naar de Canon Cat-computer en worden nu verder ontwikkeld door het Raskin Center for Humane Interfaces. Sinds zijn dood in 2005 probeert zijn team de focus te verleggen naar de integratie van de "Archy"-ideeën in andere software, zoals de Ubiquity-extensie voor Firefox.
De pogingen om een GUI te vervangen door een volledige ZUI, zijn tot nog toe niet echt succesvol te noemen ( https://en.wikipedia.org/wiki/Zooming_user_interface#History).
Ook de combinatie van een ZUI met een 3D-ervaring zoals bij Sun's Looking Glass-GUI voor Solaris UNIX, leverde niet het verhoopte succes. In combinatie met een traditionele GUI raakte de ZUI wel ingeburgerd via de âzoomingâ-functionaliteit in Apple's iOS voor de iPhone en iPad. De zoomfunctionaliteit wordt door gebruikers als zinvol ervaren als men hierdoor bepaalde informatie in meer detail kan bekijken zoals bij Google Earth, Google Maps, het bekijken van producten in Ebay... of wanneer alle informatie niet in één keer op een âklassiekâ bureaublad kan weergegeven worden zoals bij de online presentatietool Prezi.

De 3D-ZUI Looking Glass van Sun Microsystems
 Het is niet zo eenvoudig om het begrip
augmented realityduidelijk te omschrijven. In het Nederlands vertaalt men het vaak als 'toegevoegde realiteit', maar 'uitgebreide' of 'verhoogde werkelijkheid' dekt misschien beter de lading. In de rest van het boek zullen we de Engelstalige afkorting AR gebruiken. Bij AR worden directe of indirecte live beelden aangevuld met digitale door de computer gegenereerde informatie. Die informatie wordt als een gedeeltelijk transparante laag over de live-beelden heen gelegd. De term AR zou in 1990 voor het eerst gebruikt zijn door Thomas Caudell, een ontwikkelaar bij Boeing. Hij gebruikte de term voor een head mounted display (HMD) die de arbeiders die de bedrading in de vliegtuigen aanbrachten, moest helpen bij die ingewikkelde taak. De digitale beelden verrijken hun beeld van de werkelijkheid. De HMD zelf was geen uitvinding van Thomas Caudell, maar werd reeds in de jaren '60 van de vorige eeuw ontwikkeld door de computerwetenschappers Bob Sproull en Ivan Sutherland, voor de weergave van virtual reality-beelden. Tegenwoordig kennen we AR vooral van applicaties zoals Layar op de smartphones met iOS en Google Android. Die AR-apps nemen met de webcam een live beeld van de omgeving en voorzien dit van een extra laag informatie. Omdat de zoekopdracht niet meer door de gebruiker wordt ingegeven, maar automatisch door het toestel wordt opgevraagd en weergegeven, lijkt het alsof we hier met kunstmatige intelligentie of artificial intelligence (AI) te maken hebben. Vaak is de waarheid iets minder geavanceerd, maar je kan het gerust als een eerste stap zien in de richting van AI in de dagdagelijkse werkelijkheid. De invoer voor AR komt soms, maar lang niet altijd via user-input, maar tegenwoordig vaak via sensoren en chips. Een smartphone met AR-functionaliteit registreert via een GPS-chip de lokatie van de gebruiker en via een digitaal kompas zijn orieÌntatie, vergelijkt de resultaten met de informatie in een databank en toont het eindresultaat aan de gebruiker. Bij indirecte AR zijn de gegevens vaak wel door "onzichtbare" personen ingegeven, daarom stellen gebruikers zich in dit geval minder vragen.
Het is niet zo eenvoudig om het begrip
augmented realityduidelijk te omschrijven. In het Nederlands vertaalt men het vaak als 'toegevoegde realiteit', maar 'uitgebreide' of 'verhoogde werkelijkheid' dekt misschien beter de lading. In de rest van het boek zullen we de Engelstalige afkorting AR gebruiken. Bij AR worden directe of indirecte live beelden aangevuld met digitale door de computer gegenereerde informatie. Die informatie wordt als een gedeeltelijk transparante laag over de live-beelden heen gelegd. De term AR zou in 1990 voor het eerst gebruikt zijn door Thomas Caudell, een ontwikkelaar bij Boeing. Hij gebruikte de term voor een head mounted display (HMD) die de arbeiders die de bedrading in de vliegtuigen aanbrachten, moest helpen bij die ingewikkelde taak. De digitale beelden verrijken hun beeld van de werkelijkheid. De HMD zelf was geen uitvinding van Thomas Caudell, maar werd reeds in de jaren '60 van de vorige eeuw ontwikkeld door de computerwetenschappers Bob Sproull en Ivan Sutherland, voor de weergave van virtual reality-beelden. Tegenwoordig kennen we AR vooral van applicaties zoals Layar op de smartphones met iOS en Google Android. Die AR-apps nemen met de webcam een live beeld van de omgeving en voorzien dit van een extra laag informatie. Omdat de zoekopdracht niet meer door de gebruiker wordt ingegeven, maar automatisch door het toestel wordt opgevraagd en weergegeven, lijkt het alsof we hier met kunstmatige intelligentie of artificial intelligence (AI) te maken hebben. Vaak is de waarheid iets minder geavanceerd, maar je kan het gerust als een eerste stap zien in de richting van AI in de dagdagelijkse werkelijkheid. De invoer voor AR komt soms, maar lang niet altijd via user-input, maar tegenwoordig vaak via sensoren en chips. Een smartphone met AR-functionaliteit registreert via een GPS-chip de lokatie van de gebruiker en via een digitaal kompas zijn orieÌntatie, vergelijkt de resultaten met de informatie in een databank en toont het eindresultaat aan de gebruiker. Bij indirecte AR zijn de gegevens vaak wel door "onzichtbare" personen ingegeven, daarom stellen gebruikers zich in dit geval minder vragen.
Wat is het verschil tussen Augmented Reality en Virtual Reality? Paul Milgram en Fumio Kishino definieerden in 1994 het "Milgram's Reality Virtuality Continuum". Ze onderscheiden in "mixed reality" vier stappen:
real environment (de echte omgeving)
augmented reality (AR)
augmented virtuality (AV)
virtual environment (volledig virtuele omgeving)
Bij "real environment" gaat het niet zo zeer over het waarnemen van de werkelijkheid, maar nog steeds over het mengen van echte met virtuele beelden. Een bekend voorbeeld zijn TUI's (Tangible User interfaces) of NUI's (natural user interfaces). Hierbij gebruik je echte voorwerpen (eventueel uitgerust met sensoren) of mensen voor de interactie met computers. Een aantal voorbeelden van TUI's vind je op http://www.guillaumeriviere.name/collection/tui.html.
Heel erg ingeburgerd zijn toestellen als de Wii en de Xbox Kinect zijn de KUI's (Kinetic User Interfaces) waarbij natuurlijke bewegingen van voorwerpen of mensen zorgen voor de interactie met computers.
Bij AR maakt men een onderscheid tussen Spatial AR, See-through AR en Projection Augmented Models (PA-models).
Bij Spatial AR worden door de computer gegenereerde informatie in de omgeving geprojecteerd. De gebruiker kan interactief met de projecties omgaan of de projectie/computer reageert op de gebruiker.
Bij See-through AR draagt de gebruiker een HMD, AR-contactlens of bril.
AV doet net het omgekeerde van AR. Het voegt echte beelden toe aan een virtuele omgeving.
De meest geavanceerde head mounted display of head-up display is in gebruik bij de Amerikaanse luchtmacht. Piloten van een F-35 kunnen de gewenste vorm van informatie selecteren. Het directe beeld van de omgeving dat ze door hun helm en door de ramen van het vliegtuig te zien krijgen, wordt aangevuld met symbolen en/of een kaart. 's Nachts toont de HUD een 3D-wireframe van de omgeving zodat de piloten letterlijk blindelings kunnen vliegen.
Oorlogvoering is gelukkig niet het enige toepassingsgebied van HUD's en HMD's. Ook voor games, extreme sporten, geneeskunde, wetenschappelijk onderzoek enz. bestaan er gelijkaardige systemen die de gebruiker bij zijn taak moeten helpen. Voor de consument is een HUD natuurlijk een beetje te veel van het goede, maar de ontwikkeling gaat ook op dit vlak razendsnel. Een simpele AR-bril of zelfs AR-contactlens behoort tot de mogelijkheden. Het idee van AR-contactlenzen stamt uit SF-verhalen. Het is misschien wel wat raar om aan de cyborg in Terminator AR-contactlenzen te geven. In het geval van een robot zullen de digitale data rechtstreeks in het virtuele brein zitten als een reeks te verwerken instructies. Maar het schept natuurlijk wel de juiste sfeer voor de film en de achtervolgingsscenes. In de boeken van de SF-schrijver, wiskundige en informaticus Vernor Vinge hebben de personages geen hersenimplantaten of smartphones voor AR-informatie, maar elektronische contactlenzen.
 De
Virtual Retinal Displayvan Microvision (www.mvis.com) is een vorm van HUD waarbij de beelden rechtstreeks op het netvlies worden geprojecteerd. Babak A. Parviz, professor bionanotechnologie aan de universiteit van Washington (Seattle) werkt samen met een team van professoren en studenten aan een AR- contactlens. Een eerste werkende versie is klaar voor "massaproductie", ook al is de functionaliteit op dit moment nog erg beperkt. Naast een glucosemonitor bouwde zijn team ook biosensoren die informatie met bepaalde molecules kunnen uitwisselen via elektrische signalen. Ze hebben m.a.w. alle technologie voor handen die nodig is voor de verdere ontwikkeling van AR-contactlenzen. De lenzen zijn ingepakt in een polymeerlaag en grondig op veiligheid getest (op konijnen!). De lens voorziet zichzelf van energie via lage radio-frequentie-signalen (RF power) waarmee een kleine hoeveelheid energie kan worden opgewekt, want slechts een paar microwatt zijn nodig om een voor het oog zichtbaar beeld op te bouwen. Het menselijk oog heeft immers geen massa licht nodig om informatie te registreren. Anders dan bij een computermonitor of smartphonescherm waar het grootste deel van de uitgezonden energie verloren gaat, helpt bij de AR-lens elk foton bij de opbouw van het AR-beeld omdat de lens meteen op het oog ligt. Eens voldoende ontwikkeld kan de lens tekst, grafieken, kaarten, afbeeldingen of zelfs film direct 'op het oog' weergeven. Uiteraard moet in dat geval nog steeds een extern draagbaar toestel zorgen voor het draadloos doorgeven van de informatie aan de lens. Maar het is niet moeilijk om toekomstige mogelijkheden voor deze vorm van nanotechnologie te bedenken. Mogelijk vervangt het in de toekomst computerschermen!
De
Virtual Retinal Displayvan Microvision (www.mvis.com) is een vorm van HUD waarbij de beelden rechtstreeks op het netvlies worden geprojecteerd. Babak A. Parviz, professor bionanotechnologie aan de universiteit van Washington (Seattle) werkt samen met een team van professoren en studenten aan een AR- contactlens. Een eerste werkende versie is klaar voor "massaproductie", ook al is de functionaliteit op dit moment nog erg beperkt. Naast een glucosemonitor bouwde zijn team ook biosensoren die informatie met bepaalde molecules kunnen uitwisselen via elektrische signalen. Ze hebben m.a.w. alle technologie voor handen die nodig is voor de verdere ontwikkeling van AR-contactlenzen. De lenzen zijn ingepakt in een polymeerlaag en grondig op veiligheid getest (op konijnen!). De lens voorziet zichzelf van energie via lage radio-frequentie-signalen (RF power) waarmee een kleine hoeveelheid energie kan worden opgewekt, want slechts een paar microwatt zijn nodig om een voor het oog zichtbaar beeld op te bouwen. Het menselijk oog heeft immers geen massa licht nodig om informatie te registreren. Anders dan bij een computermonitor of smartphonescherm waar het grootste deel van de uitgezonden energie verloren gaat, helpt bij de AR-lens elk foton bij de opbouw van het AR-beeld omdat de lens meteen op het oog ligt. Eens voldoende ontwikkeld kan de lens tekst, grafieken, kaarten, afbeeldingen of zelfs film direct 'op het oog' weergeven. Uiteraard moet in dat geval nog steeds een extern draagbaar toestel zorgen voor het draadloos doorgeven van de informatie aan de lens. Maar het is niet moeilijk om toekomstige mogelijkheden voor deze vorm van nanotechnologie te bedenken. Mogelijk vervangt het in de toekomst computerschermen!

 Het uitblijven van succes van
Google Glassbewijst dat AR niet meteen zijn weg vindt naar het grote publiek. Toch is de vermening van de digitale en de fysieke wereld reeds ingezet: de Apple Watch verzamelt informatie over onze gezondheid en bewaart die in de "cloud" (big data). De
Apple Watchbehoort bij de categorie van de wearables, waar ook "intelligente kleding" ondergebracht kan worden. Ook van de Arduino-microcontroller bestaat er een wearable versie en de nodige materialen om zelf intelligente kleding samen te stellen (https://store.arduino.cc/category/30). De
LilyPad Arduinois speciaal ontwikkeld voor wearables en e-textile. T. Olsson, D. Gaetano, J. Odhner en S. Wiklund beschrijven in hun boek "Open Softwear" hoe je software ontwikkelt voor e-textile.
Het uitblijven van succes van
Google Glassbewijst dat AR niet meteen zijn weg vindt naar het grote publiek. Toch is de vermening van de digitale en de fysieke wereld reeds ingezet: de Apple Watch verzamelt informatie over onze gezondheid en bewaart die in de "cloud" (big data). De
Apple Watchbehoort bij de categorie van de wearables, waar ook "intelligente kleding" ondergebracht kan worden. Ook van de Arduino-microcontroller bestaat er een wearable versie en de nodige materialen om zelf intelligente kleding samen te stellen (https://store.arduino.cc/category/30). De
LilyPad Arduinois speciaal ontwikkeld voor wearables en e-textile. T. Olsson, D. Gaetano, J. Odhner en S. Wiklund beschrijven in hun boek "Open Softwear" hoe je software ontwikkelt voor e-textile.
Niet enkel kleding, maar ook in je woning of klaslokaal kan je de fysieke en de digitale wereld in elkaar laten overvloeien. Met Bare Conductive Touch Board Starter Kiten elektrisch geleidende verf kan je AR-applicaties bouwen.
Virtual Environment of Virtual Reality is het andere uiterste. Het volledige beeld wordt door de computer gegenereerd. Wel kunnen er net zoals in een 3D-programma afbeeldingen uit de echte wereld als textures (vullingen) op virtuele objecten worden 'gemapt' (virtueel geprojecteerd).
Hier maakt men een onderscheid tussen Semi immersive VR en Immersive VR. Bij Semi Immersive VR vult het VR-beeld slechts een deel van het gezichtsveld van de gebruiker. Denk bijvoorbeeld aan een "flight simulator". Een Immersive VR-beeld vult het volledige gezichtsveld door gebruik van een HMD of projecties waarbij beelden over gans de omgeving van de gebruiker.
onderschrift: Het programma Terragen is gespecialiseerd in het 'uit het niets' genereren van landschappen, zeeën, gebergtes, wolken... Het resultaat zijn hyperrealistische beelden die in vrijwel niets te onderscheiden zijn van echte foto's (Bron afbeelding: www.picolous.com).
Het onderscheid tussen de verschillende fasen in het Milgram's continuum zijn niet altijd even duidelijk en vastomlijnd. Zo vormen PA-models echt een randgeval tussen Spatial AR en TUI's. Bij een PA-model wordt op een fysisch object een computerafbeelding geprojecteerd (gemapt), op een gelijkaardige manier als in een 3D-programma een vulling op een object wordt geplaatst.
Het lijkt ontsnapt uit een goedkope SF-film, maar het kan en het is beschikbaar voor een betaalbare prijs, het eerste invoerapparaat op basis van hersengolven (een neurale interface). De Emotiv Epocis voor een slordige 300 dollar te bestellen. Een SDK (software development kit) is beschikbaar voor de iets minder gebruikersvriendelijke prijs van ongeveer 750 dollar.
 Met de open source
OpenViBE-software, een C++-library voor Linux en Windows, kan je op basis van de Emotive-headset je eigen applicaties schrijven. De eveneens open source EMOKIT-software is speciaal ontworpen om samen te werken met de Emotive. OpenViBE wordt ontwikkeld door het Franse Institut national de recherche en informatique et en automatique (
http://openvibe.inria.fr/) en is bestemd voor het ontwerpen, uittesten en gebruiken van
Brain-Computer Interfaces (BCI). Een onwaarschijnlijke demonstratiefilm vind je op
http://openvibe.inria.fr/video.php?q=video-openvibe-introduction-en.
Met de open source
OpenViBE-software, een C++-library voor Linux en Windows, kan je op basis van de Emotive-headset je eigen applicaties schrijven. De eveneens open source EMOKIT-software is speciaal ontworpen om samen te werken met de Emotive. OpenViBE wordt ontwikkeld door het Franse Institut national de recherche en informatique et en automatique (
http://openvibe.inria.fr/) en is bestemd voor het ontwerpen, uittesten en gebruiken van
Brain-Computer Interfaces (BCI). Een onwaarschijnlijke demonstratiefilm vind je op
http://openvibe.inria.fr/video.php?q=video-openvibe-introduction-en.
EMOKIT daarentegen is een eenmansproject van de hacker DAEKEN en is ultrasimpel in gebruik. De softwarekit is gebaseerd op de programmeertaal Python (maakt gebruik van pywinusb en python-hid) waardoor je applicaties kan ontwikkelen voor Windows, Mac OS X en Linux. EMOKIT maakt verbinding met de Emotiv via Bluetooth via een HID-interface, leest de versleutelde data uit en stopt die in een queue die je dan weer in je eigen applicatie kan inlezen en gebruiken. Je vindt de software op http://daeken.com/emokit-hacking-the-emotiv-epoc-brain-computer-0en https://github.com/daeken/Emokit
Japanse onderzoekers slaagden er in 2008 reeds in om op basis van een fMRI-scan van de hersenen beelden te reconstrueren. Het onderzoek naar visual image reconstruction from brain activity gaat door aan verschillende onderzoekscentra en men bereikt op dit moment al onvoorstelbare resultaten.
Links:
De simulatiehypothese stelt dat de zichtbare realiteit niet echt is, maar dat we leven in een computersimulatie. De âgesimuleerdenâ (wij mensen) zijn zich er totaal niet van bewust. Dit idee vormt de basis achter SF-films zoals The Matrix. Volgens de Britse computerdeskundige Nick Bostrom zijn er argumenten om aan te nemen dat dit wel degelijk het geval is:
"A technologically mature "posthuman" civilization would have enormous computing power. Based on this empirical fact, the simulation argument shows that at least one of the following propositions is true:
1. The fraction of human-level civilizations that reach a posthuman stage is very close to zero;
2. The fraction of posthuman civilizations that are interested in running ancestor-simulations is very close to zero;
3. The fraction of all people with our kind of experiences that are living in a simulation is very close to one.
If (1) is true, then we will almost certainly go extinct before reaching posthumanity. If (2) is true, then there must be a strong convergence among the courses of advanced civilizations so that virtually none contains any relatively wealthy individuals who desire to run ancestor-simulations and are free to do so. If (3) is true, then we almost certainly live in a simulation. In the dark forest of our current ignorance, it seems sensible to apportion oneâs credence roughly evenly between (1), (2), and (3). Unless we are now living in a simulation, our descendants will almost certainly never run an ancestor-simulation."
Lees het volgende onderdeel: Interface ontwerp
In dit deel bestuderen we hoe digitale systemen zoals computers informatie verwerken. Begrijpen ze die informatie ook? Wat doet een computer met gesproken of geschreven taal? Wat betekent gezichtsherkenning precies? Zijn computers intelligent of lijken ze dat alleen maar? Hoe kan het dat een computer een foto kan weergeven of âonthoudenâ? Weet hij echt wat er op een foto staat?
Wat vormt de hersenen van de computer? Waardoor kan hij die gegevens verwerken? Zullen computers en andere digitale systemen de mens ooit voorbijsteken in intelligentie? Hoe ver staan die toestellen al op het vlak van KI (of AI)?
We kijken ook verder dan de interface tussen mens en machine. Hoe verwerkt een digitaal systeem al die binnenkomende signalen, de invoer van de gebruiker, hoe genereert hij diverse soorten feedback en output?
Als je een tekst invoert op je computer of een tekst publiceert op internet, weet je zelf waarover die tekst gaat. Computers kennen de inhoud niet, of beter gezegd, ze begrijpen absoluut niet waarover je het hebt. Ze snappen de betekenis niet. Voor een computer of stuk software is een tekst niet meer dan een reeks karakters die op hun beurt nog eens worden vertaald in bits (nullen en enen, je weet wel).
Wanneer een docent je op een examen een vraag stelt, dan kan je daar in het beste geval vlot op antwoorden. Je begrijpt de vraag, maakt in je hoofd de juiste analogie en vergelijkingen en je kan de inhoud simultaan vertalen in je eigen woorden. Je leert het niet uit je hoofd en je rammelt het niet woord voor woord betekenisloos af. Dat zou je natuurlijk kunnen doen, maar een docent verwacht dat je intrinsiek verbanden kan leggen, de betekenis snapt.
Wanneer je in de zoekmachine Google de zoekterm âhaarâ invoert, dan moet je niet meteen verwachten dat Google het dichtstbijzijnde kapsalon op het scherm tovert. âHaarâ heeft meerdere betekenissen (vb. een bezittelijk voornaamwoord). Meer nog, je voert zoektermen in omdat je beseft dat Google nog minder raad zou weten met de vraag âWat is het dichtstbijzijnde kapsalon?â Google herkent geen natuurlijke taal, zoals zo goed als geen enkel softwareprogramma eigenlijk. Daarom moet je ook niet lachen met Google Translate als hij geschifte vertalingen oplevert. Het is eerder verbazingwekkend te noemen wat âGoogle Translateâ wel kan.
Google en andere zoekmachines snappen totaal niet waarover de inhoud van die miljarden webpagina's op het wereldwijde web gaat.
âHallo wereldâ... De eerste applicatie die een programmeur in wording schrijft, levert als uitvoer steevast deze regel op. Nochtans begrijpt het programma zelf niet wat het aan het zeggen is. Of dit nu âHello worldâ of âVandaag eten we friet en banaanâ is. De programmeur schrijft het programma in een programmeertaal, maar die is geheel anders opgebouwd dan menselijke talen.
Je hoort het wel vaker. De computer kan geen âopen vragenâ interpreteren, âgesloten oefeningenâ wel. Een stuk software kan perfect kruiswoordraadsels, invuloefeningen, combinatie-oefeningen en dies meer verbeteren, maar open vragen zijn een ander paar mouwen. De computer weet niet veel raad met vragen als âWaarom probeerde België zich los te maken van Nederland in 1830 (en is het nog gelukt ook)?â
Beeld je de volgende oefening in:
Op 6 ......................... vieren we de verjaardag van â¦...........................
Zie ginds komt de ......................... uit ............................ weer aan.
We kunnen een stuk software schrijven dat dit soort oefeningen perfect kan verbeteren. We schrijven het zo dat ook andere zinnen kunnen ingevoerd worden. Een docent/leraar zou op de volgende manier een oefening kunnen aanmaken die door de software automatisch wordt omgezet in een invuloefening:
Op 6 <antwoord>december</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas</antwoord>
De software weet dat hij alle woorden tussen de markering â<antwoord></antwoord>â moet verbergen. Bovendien kan hij zelf tellen hoeveel vragen er zijn. In de eerste zin moeten twee woorden worden ingevuld. De oefening staat dus op 2 punten. Maar hier duikt meteen een probleem op. Wat als de student/leerling i.p.v. december gewoon een 12 invoert, of i.p.v. Sinterklaas, âde sintâ? Dit kan je als docent toch onmogelijk fout rekenen?
Heel wat programma's lossen dit op door aan de gebruiker te vragen meerdere mogelijke antwoorden in te voeren. In ons geval zou het er dan als volgt kunnen uitzien:
Op 6 <antwoord>december/12</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas/de sint</antwoord>
Maar ook dan zijn de problemen niet helemaal van de baan. Want wat moet je als docent doen met een leerling met dyslexie die â demecberâ schrijft of â sntriklaasâ? Ook die antwoorden moeten goedgekeurd worden. Uiteraard niet voor iedereen, enkel voor leerlingen met een schrijf/taalprobleem. Het zou niet zinvol zijn om alle mogelijke schrijffouten vooraf in te voeren. Bovendien zouden leerlingen zonder taalproblemen dan rijkelijk beloond worden.
Vaak worden zulke softwarematige âproblemenâ ervaren alsof software niet in de mogelijkheid zou verkeren om hier een echte oplossing voor te bieden. NLP of Natural Language Processing 1 kan echter heel wat van deze beperkingen opvangen.

NLP combineert elementen uit de wetenschap, de taalkunde en het domein van Artificiële Intelligentie (AI). Twee belangrijke domeinen waarop NLP zich toespitst zijn
het afleiden van betekenis uit menselijke (natuurlijke) talen en
het genereren van ânatuurlijke taalâ (denk aan Google Translate).
Alan Turinglegde de basis voor NLP met zijn beroemde Turingtestwaarbij een mens en een machine op afstand in vraag-antwoord-stijl met elkaar communiceren. Als de machine de mens kan overtuigen dat hij âeveneens een mensâ is, dan evenaart de machine in Turings ogen de menselijke intelligentie. De computer slaagt in de test als hij in meer dan 30% van de tijd voor een mens wordt aanzien.
Joseph Weizenbaum ontwikkelde tussen 1964 en 1966 ELIZA, de eerste beroemd geworden âchatbotâ. ELIZA simuleerde een psychotherapeut, een goed uitgangspunt om in vraag-antwoordstijl te werken. Omdat de kennis van ELIZA erg beperkt was, antwoordde de âchatbotâ vaak met open vragen zoals âWaarom zeg je dat je hoofdpijn hebt?â.
De supercomputer Eugene Goostman slaagde in juni 2014 voor de test door het âbreinâ van een 13-jarige te simuleren. 2

Om een machine (computer, software...) taalte laten begrijpen, moet ze ook de betekenis van een tekst of zin kunnen achterhalen.
Wanneer een kind taal leert, vertaalt het simultaan de werkelijkheid naar taal en omgekeerd. Een dorp bevat straten en huizen, een huis bevat kamers, kamers bevatten meubels enz.
Woorden en begrippen hebben relaties en staan in verband met elkaar... Woorden en begrippen vormen netwerken, interfereren met elkaar enz. In hun hoofd vormen en herkennen kinderen stapsgewijs al die relaties en begrippenkaders... ze krijgen een beeld van de wereld en van de werkelijkheid: een ontologie.
Vanaf de jaren 1970 zagen programmeurs in dat het nodig was om ook voor NLP zulke âontologieënâ te ontwikkelen. De ârelatiesâ en âbegrippenkadersâ uit de echte wereld moesten vertaald worden naar gegevens die door een computer konden begrepen worden.Voorbeelden van zulke âontologieënâ zijn ondermeer MARGIE, SAM en PAM... Ze leidden tot nieuwe chatbots zoals Parry en Jabberwacky 3 .
Deze manier van werken had tot gevolg dat in de jaren 1980 de meeste NLP-systemen bestonden uit eindeloze reeksen regeltjes, tot verregaande schematisering van taal. Vanuit softwarecode gezien leidde dit tot eindeloze âif-elseâ-structuren. Je kent het wel: âAls (if) je braaf bent, krijg je een koekje, anders (else) een stokje.âIn de werkelijkheidzit er veel meer variatie. Het is mogelijk dat het kind anders altijd heel braaf is en nu één keertje stout. Neem je dan het vieruurtje af?
In de werkelijkheid verloopt niet alles zwart (1) â wit (0), het is niet altijd zus of zo. Als je 4 tekorten hebt op je rapport is de kans groot dat je mama boos is, tenzij ze weet dat je heel erg je best hebt gedaan. In de echte wereld wegen we voortdurend af, volgen we niet altijd stricte regels, werken we volgens waarschijnlijkheden en statistische kansen.
Heel wat nieuwe NLP-systemen zouden zich gaan baseren op zulke statistische modellen. Die ârevolutieâ binnen de NLP-wereld was ook een gevolg van de beperkte rekenkracht van de toenmalige generatie computersystemen. Gokken ging nu eenmaal sneller en makkelijker dan eindeloze reeksen âifâ- en âelseâ-structuren te doorlopen. Ook de taaltheorieën van Noam Chomsky, de Amerikaanse taalkundige, die grammaticale gelijkenissen tussen talen zocht, eerder dan verschillen, vormden een rijke inspiratiebron.
Zulke statistische systemen werken veel beter in het geval van âonverwachte invoerâ van de gebruiker ( vb. sniterklaas i.p.v. Sinterklaas). In de echte wereld zijn afwijkingen en fouten immers niet ongewoon, integendeel. Vooral op het vlak van âvertalingenâ bieden de statistische technieken succes. Veel vertaalprogramma's die gebaseerd waren (en soms nog zijn) op woordenlijsten (een soort vertalende woordenboeken) liepen al snel tegen hun grenzen aan. Je kan immers geen zinnen vertalen door de individuele woorden te vertalen, maar door kleine brokjes data te vertalen en hieruit ook te âlerenâ.
Statistische systemen zijn echter ook niet heiligmakend (denk aan Google Translate). Recent ligt de focus op een combinatie van beide technieken: de âharde regeltjesâ-weg en de statistische techniek.
Het mag duidelijk zijn dat we ondanks het aanvankelijke optimisme in de jaren 1960 nog een hele weg moeten afleggen vooraleer machines menselijke talen begrijpen en er mee kunnen communiceren. Toch staan de ontwikkelingen niet stil. Bereikt de machine dan echt âkunstmatige intelligentieâ zoals Alan Turing stelde? Vreemd genoeg verandert de betekenis van AI (articifial intelligence)bij elke nieuwe vooruitgang. Zo werd âschakenâ lange tijd als het toppunt van menselijke intelligentie gezien. Toen de IBM-computer Deep Bluede wereldkampioen schaken Garry Kasparov versloeg, verloor schaken plots veel van zijn allure. De volgende uitdaging kwam er aan: computers zouden nooit creatief kunnen antwoorden op âopenâ vraagstellingen. In 2010 ging IBM's supercomputer Watsonde uitdaging aan en won: hij versloeg met glans de âall-time-greatest human Jeopardy champions, Ken Jennings en Brad Rutterâ 4 . De Jeopardyquiz stelt open vragen over alle domeinen van de menselijke cultuur. De vragen bevatten tal van woordspelingen en hints, maar zelden een duidelijke vraagstelling.
Op tal van terreinen die vroeger als uniek voor de menselijke intelligentie werden gezien, steekt de machine zijn menselijke tegenspeler voorbij. Machines zullen nooit gevoelens hebben of bewustzijn. Maar wat betekent dit precies?
Lees het kleine verhaaltje hieronder:
De hond slaapt in zijn mandje. Jacky is heel erg lief. Als ik thuis kom, komt hij al kwispelstaartend naar me toegelopen. Waar blijft hij vandaag? Weet jij het? Ik ben zo bang dat hij weggelopen is.
Als menselijke lezer snap je meteen waarover dit korte tekstje gaat. Hoe kunnen we een machine leren om deze tekst te begrijpen? Tussen mens en machine is er in dit geval al meteen een immens verschil. Een kind leert al snel een visueel beeld van een hond te koppelen aan het begrip âhondâ en de bijhorende geluiden. Denk maar aan de mama's en de papa's die vragen: âEn, hoe doetde hond? Nee, niet miauw.â
Het taalmechanismein het hoofd van het kind koppelt aan de hond bepaalde acties zoals blaffen, lopen, kwispelstaarten, maar ook onderdelen zoals staart, poten, tong... Een heel kader, onderdeel van de âwereldontologieâ in het hoofd van het kind.
Maar hoe vertalenwe die taalverwerking naar een computer? Oeps, dat is wat anders.
Laat ons eerst eens de tekst scheiden in zijn onderdelen: zinnen ( sentence breaking). Dat kan eenvoudig door te zoeken naar leestekens zoals punten, vraagtekens of uitroeptekens. Dit werkt perfect voor heel wat talen, maar niet voor pakweg Arabisch, Chinees of Japans, want daar is het gebruik van leestekens onbekend. Vervolgens kunnen we de zinnen splitsen in hun diverse woorden ( word segmentation), maar dat werkt al evenmin voor de genoemde talen: Arabisch kent bijvoorbeeld geen door spaties onderscheiden woorden. Daar bepaalt het uitzicht van een bepaald karakter (letter) of het gaat om het begin, het midden of het einde van een woord.
Zinnen bepalen of ze iets meedelen of eerder iets vragen (het vraagteken), en vragenop hun beurt kunnen open of gesloten (ja of neen, if of else, 1 of 0) zijn. De soort zinnen wordt bepaald door de âdiscourse analysisâ. De machine kijkt vervolgens naar de individuele woorden en probeert die te herleiden tot hun basis of stam in een proces dat âstemmingâ en âmorphological segmentationâ heet. In een taal als het Engels is dit een relatief eenvoudig proces:
openis de âstamâ van open, opens, opening, opened...
In talen zoals het Turks is dit een uiterst moeizame techniek. De stam is niet noodzakelijk hetzelfde als de morfologische âwortelâ van het woord. Meestal volstaat het dat verwante woorden dezelfde stam bevatten. Heel wat zoekmachines behandelen woorden met dezelfde stam als synoniemen om de zoekterm enigszins uit te breiden (conflatie).
Googlegebruikt âstemmingâ sinds 2003.
Voordien zou de zoekterm âvisâ niet âvissenâ of âgevistâ opgeleverd hebben.
Dit leidt soms tot foute resultaten. De machine kan teveel resultaten leveren (overstemming) zoals wanneer je âuniversiteitâ zoekt en ook âuniversumâ krijgt. In dit geval behandelt de machine beide woorden door hun gemeenschappelijke stam als synoniemen. In andere gevallen krijg je te weinig zoekresultaten (understemming).
Bij woorden zoekt het NLP-systeem niet alleen naar de stam, maar bovendien ook naar de woordsoort: gaat het om een adjectief of een zelfstandig naamwoord? Bovendien kunnen zelfstandige naamwoorden ook eigennamen zijn.
Jackyis een hond.
Deze techniek van ânamed entity recognitionâ werkt simpelweg door naar hoofdletters te kijken. Maar ook dit levert problemen op. Bij het begin van een zin schrijf je steevast een hoofdletter. In het Duits krijgen dan weer alle naamwoorden een hoofdletter.
Jackyist ein Hund.
En in het Engels schrijf je ook een hoofdletter als je het over jezelf hebt:
Iwanna be your dog.
De woordsoort wordt vaak bijgehouden in een soort lexicon, een soort lijst waarin op basis van de stam en eventuele voor- en achtervoegsels de woordsoort wordt bepaald (
Part-of-speech tagging). Maar eenvoudig is dit niet. Immers, afhankelijk van de zin kan een woord iets compleet anders betekenen:
Ik speel met de balop het bal.
Je merkt het al. De betekenis zit niet in het woord alleen, maar ook in zijn relatie met andere woorden: homoniemen (w
ord sense disambiguation). De volgende zin klinkt afhankelijk van tegen wie (je docent) of wat (een eik) je het zegt helemaal anders, maar een NLP-systeem heeft het er moeilijk mee:
Je bent een eikel.
Via de techniek van â
n
atural language understandingâ probeert een NLP-systeem logica te vinden in korte fragmenten tekst. Welke adjectieven horen bij zelfstandige naamwoorden (
conference resolution)? Wat zijn de onderlinge relaties tussen objecten in een zin (
r
elationship extraction)?
Op die manier probeert een NLP-systeem stilaan de zin te âparsenâ, een stamboom te maken van een zin en tenslotte van het hele verhaal.
âJe bent een eikel,âzei ik tegen de directeur .Ik was woedend.Hij werd door mijn uitspraak eveneens razend.
Deze zin verklapt hoe beide partijen zich voelen. Een NLP-systeem kan op basis van de betekenis van woorden en de frequentie waarmee ze voorkomen, raden wat het gevoel is dat uit een tekst spreekt:
sentiment analysis
. Je kan het zelf uittesten op
https://semantria.com/.
 Fouten laten herkennen door een machine vraagt geen âhogereâ intelligentie.
Fouten laten herkennen door een machine vraagt geen âhogereâ intelligentie.
 Een basisvoorbeeld van âtokenizationâ: van elk woord wordt bepaald of het alfabetisch, numeriek of symbolisch is:
Een basisvoorbeeld van âtokenizationâ: van elk woord wordt bepaald of het alfabetisch, numeriek of symbolisch is:
 Een voorbeeld van âtaggingâ waarbij van elk woord de woordsoort wordt opgegeven op basis van een âlexiconâ (een woordenlijst):
Een voorbeeld van âtaggingâ waarbij van elk woord de woordsoort wordt opgegeven op basis van een âlexiconâ (een woordenlijst):

In het volgende hoofdstuk behandelen we OCR, een techniek om een gescande of gekopieerde tekst (uit afbeeldingen dus) te converteren naar bewerkbare tekst. Dat is relatief gezien â
peanutsâ in vergelijking met NLP.
Vooraleer machines vlekkeloos in menselijke talen kunnen communiceren, is er nog een hele weg af te leggen. Het draait niet enkel om de semantiek.In de Studio 100-reeks ROX praat de gelijknamige auto vlekkeloos met de andere (menselijke) personages. Hij herkent en interpreteert hun vragen en antwoorden en reageert er vaak laconiek op. Onze vriend âROXâ combineert het beste op het vlak van NLP met speech recognition, speech segmentationen speech processingen als kers op de taart natural language generation.
Het verstaan van gesproken taal (speech recognition) is nog een aardig stuk moeilijker dan het lezen of interpreteren van gedrukte tekst omdat er in gesproken tekst nauwelijks pauzes zijn tussen woorden. Ook letters vloeien onhoorbaar in elkaar over. Het verdelen van een uitspraakin afzonderlijke woorden (speech segmentation) is vreselijk moeilijk te programmeren. Natural language generation, het genereren van taal in geluidsvorm, is daarentegen al aardig ingeburgerd in bijvoorbeeld GPS-systemen. De software kan in dat geval gebruik maken van vooraf opgenomen geluid (afzonderlijke woorden of zinnen) dat het tot de gewenste zinnen samenvoegt. Dat is echter nog heel wat anders dan het kunstmatig âtoon per toonâ genereren van spraak (speech synthesis).
Lees het volgende deel: Deel 3b: Afbeeldingen digitaliseren
1Opgelet: Natural Language Processing is niet hetzelfde als Neuro Linguïstisch Programmeren (http://nl.wikipedia.org/wiki/Neurolingu%C3%AFstisch_programmeren
2"Computer denkt voor het eerst als mens in Turing Testâ, http://www.automatiseringgids.nl/nieuws/2014/24/computer-denkt-voor-het-eerst-als-mens-in-turing-test, Geraadpleegd op 23 september 2014.
4Bostrom, N. Superintelligence. Paths, dangers, strategies, Oxford, 2014.

Bron afbeelding: Kris Merckx -
www.ardeco.be
Ongetwijfeld ken je het pentagram, de vijfpuntige ster die vaak in verhalen en teksten over hekserij en magie opduikt. Het pentagram beantwoordt op verschillende manieren aan de verhouding van de gulden snede.

| `a/b=phi` | `b/c=phi`
|
`c/d=phi`
|
Prachtige voorbeelden van de relatie tussen Fibonaccireeksen en de gulden snede vind je in de natuur.

Bron: http://io9.com/5985588/15-uncanny-examples-of-the-golden-ratio-in-nature

Bron:
http://io9.com/5985588/15-uncanny-examples-of-the-golden-ratio-in-nature

In het Parthenon, de tempel gewijd aan de godin Athena op de Akropolis in Athene, is die "gulden verhouding" terug te vinden. Het vooraanzicht is 1,6 keer breder dan de hoogte. De zuilen zijn 1,6 keer langer dan de te ondersteunen bovenkant.

Esthetische ontwerpen wekken de perceptie dat ze eenvoudiger in gebruik en dus gebruiksvriendelijker zijn, ook al is dit niet automatisch zo. Esthetische ontwerpen nodigen meer uit tot een positieve attitude. Mensen zijn ook toegeeflijker en toleranter tegenover ontwerpfouten als het ontwerp er esthetisch goed uitziet. Een mooi interface-ontwerp werkt als katalysator voor de creativiteit en probleemoplossend denken. Minder esthetische ontwerpen, verstikken de creativiteit. Esthetische ontwerpen worden sneller geaccepteerd, en wekken de indruk dat ze gebruiksvriendelijker zijn. Uiteraard blijft âschoonheidâ en âesthetiekâ een zeer subjectief gegeven, maar de perceptie is op dit vlak moeilijk te wijzigen. Denk aan het idee dat veel Applegebruikers hebben over de producten van hun favoriete merk. Wie aan Apple denkt, denkt aan mooi design, gebruiksvriendelijkheid, eenvoud in gebruik, stabiliteit... ook al klopt dat niet altijd. Voor concurrenten is het bijzonder moeilijk om die perceptie voor de eigen productlijn op te wekken.
âOver kleuren en smaken valt niet te discussiërenâ zegt het spreekwoord. Nochtans klopt dit niet helemaal. Je kan twee kleuren die op het eerste zicht met elkaar âvloekenâ bij elkaar plaatsen als dat uw smaak is. Maar wanneer je er andere kleuren of tinten bij betrekt, gaat die stelling niet meer op. Passende kleurcombinaties kan je wiskundig berekenen. Niet alle kleuren of tinten passen bij elkaar. Op paletton.com kan je passende kleurpaletten berekenenen voor je eigen ontwerpen.
Consistentie van stijl en kleur maken een systeem meer helder en bruikbaar.
Oeps, dit lijkt wel een stukje wiskunde en dat is het ook. Fibonaccireeksen (oneerbiedig ook wel eens âkonijnenreeksenâ genoemd naar het voortplantingsgedrag waarmee deze dieren worden vereenzelvigd) komen in de natuur heel vaak voor. In een Fibonaccireeks is elk volgend getal de som van de twee voorgaande getallen
Fibonaccireeksen duiken op in de natuur, maar ook in de vormgeving.
Vaak gebruikt men Fibonaccireeks in nauw verband met de zogenaamde Gulden Snede, één van de invloedrijkste patronen in wiskunde en vormgeving. Bij de Gulden Snede snijdt men een rechthoek zodanig in twee delen dat (⦠lees nu even heel aandachtigâ¦) het grootste deel en het kleinste deel zich net zo verhouden als het grootste deel tov. de ganse rechthoek. Euh???? Je merkt het al in het bovenstaande voorbeeld. In de rechthoek hebben we een vierkant afgezonder van 8 bij 8 ruitjes en eentje van 5 bij 8 ruitjes. Je kan die kleinste rechthoek opnieuw gaan indelen zodat je (net zoals in een Fibonaccireeks) opnieuw een gelijkaardige verhouding verkrijgt.
Plaats je een passer op het scheidingspunt tussen twee vierhoeken en trek je een kwartcirkel, dan bekom je een soort van spiraalvorm. De Gulden Snede duikt op in de natuur en reeds in de Oudheid gebruikten kunstenaar het in de architectuur en de kunst.
De Gulden Snede bereken je op de volgende manier: a : b = (a+b) : a (waarbij a en b de verhouding zijn van de brede en de lange zijde). De verhouding tussen a en b heet het Gulden Getal en uitgedrukt met de Griekse letter PHI (opgelet: niet PI of 3,14...)

Is het een voorbeeld van onze onbewuste voorkeur voor esthetiek en verhoudingen?
In de architectuur en vormgeving dook vooral sinds de twintigste eeuw de idee op dat esthetiek ondergeschikt is aan de functie. Functies zijn inderdaad minder subjectief dan esthetische overwegingen. Toch heeft het voorgaande al duidelijk aangeduid dat esthetiek niet onbelangrijk is. Als ontwerper kies je niet tussen vorm en functie. De vorm kan best wel afgestemd zijn op de functie. De functionaliteit mag niet verloren gaan achter het uitzicht.
 e.
e.
Symmetrie wordt altijd als schoon ervaren. We onderscheiden drie vormen van symmetrie
Weerspiegeling,
rotatie,
translatie
 Symmetrie in webdesign.
3
Symmetrie in webdesign.
3
Leesbaarheid gaat verder dan enkel het kunnen lezen van een aanwezige tekst. De informatie moet vlot opgenomen worden en bestendigen in het geheugen en de herinnering van de eindgebruiker. Informatie in welke vorm ook (teksten, afbeeldingen, artikels, invulformulieren...) kunnen zo gepresenteerd worden dat de informatie vlotter toegankelijk is en de gebruiker meteen een duidelijk overzicht krijgt.
Referenties
KNIGHT, K., "Symmetry in Design: Concepts, Tips and Examples", (http://sixrevisions.com/web_design/symmetry-design/), Geraadpleegd op 9 september 2015.
"Welk lettertype gebruik ik het best?", (http://www.wallacesanders.be/veelgestelde-vragen/welk-lettertype-gebruik-ik-het-best/), Geraadpleegd op 10 september 2015.
Dit bestand is auteursrechtelijk beschermd. Gebruik het enkel voor studiedoeleinden.
Rechtenvrije films en foto's: www.pixabay.com
Transparante PNG-afbeeldingen: www.stickpng.com
Geluid en muziek: https://freemusicarchive.org/
Lees eerst Soorten interfaces
UX-design staat voor User Experience design. Bij het ontwikkelen van digitale interfaces moet men uitgaan van een âUser centered design processâ. De ontwikkelaar(s) moeten verschillende factoren tegen elkaar afwegen:
User Centered Design Process
User needs
Business needs
Bij het ontwikkelen van een interface komt heel wat kijken:
visual design
information architecture
user interface design
usability
Bekijk zeker eens dit filmpje: https://www.youtube.com/watch?v=Ovj4hFxko7c
De ontwikkelaar bevindt zich op het knooppunt tussen het digitale systeem en de eindgebruiker. Aan de kant van de machine moet hij kennis hebben van grafisch ontwerp, besturingssysteem, programmeertalen en ontwikkelomgevingen. Aan de menselijke kant komen grafisch ontwerp, communicatietheorie, taal, sociale wetenschappen, psychologie, emoties... om de hoek kijken. Daarom is het ontwerp van een HCI (Human Computer Interface) zelden het werk van één persoon.
In dit deel bekijken we niet zo zeer hoe je een interactieve interface ontwerpt, want daarvoor moet je doorgaans al aardig wat kunnen programmeren. We bekijken echter een aantal universele ontwerpprincipes, die niet enkel gelden voor HC-interfaces, maar voor elk product dat een bedieningsinterface nodig heeft, en bij uitbreiding voor nagenoeg elk ontwerp (product, affiche...) dat je ooit zal maken of bedenken. De tips die je in dit onderdeel leest, zijn niet altijd âwetenschappelijkâ bewezen, maar in veel gevallen eerder âgood practiceâ. Hanteer ze bij het ontwerp van presentaties, websites, producten, affiches, logo's, reclamefolders. Uiteraard bespreken we onderstaande tips vooral in het kader van HC-interfaces.
Tip: Met de open source tool Pencil ( http://pencil.evolus.vn/) kan je snel een GUI prototypen. Dat wil zeggen dat je er een interface mee kan bouwen van hoe een programma of GUI voor een applicatie er volgens jou zou moeten uitzien.
Arduino en Little bits uit het vorige deel zijn voorbeelden van modulair ontwerp. Ook desktopcomputers en in wezen elke âthuisâcomputer, zijn voorbeelden van modulair ontwerp. Wie wat overweg kan met computeronderdelen kan zijn eigen toestel modulair samenstellen. Een externe harde schijf, een USB-stick, een printer/scanner... kan je beschouwen als afzonderlijke modules. Ook in moderne programmeertalen (zogenaamde object-georiënteerde talen) werken modulair, met klein herbruikbare stukjes code. Software en apps op tabletcomputers en smartphones kan je beschouwen als apart te installeren modules. Een modulair ontwerp maakt het voor de gebruiker mogelijk om zijn digitaal systeem uit te breiden of te wijzigen.
Applehardware (iPhone, iPad) is vaak bewust heel beperkt modulair. Je kan de opslagcapaciteit niet eigenhandig uitbreiden, je bent als gebruiker beperkt bij het aansluiten van randapparatuur. Nochtans is ook de âbinnenkantâ van pakweg een iMac heel erg modulair opgebouwd (www.ifixit.com).
Modulariteit betekent echter niet automatisch dat we een systeem of een interface onbeperkt kunnen schalen. Iets wat functioneert op kleine schaal werkt bijvoorbeeld niet noodzakelijk op een grote schaal. Een touchscreeninterface werkt fijn op een smartphone of een tablet, maar op een computer met een groot beeldscherm is het niet meteen een gebruiksvriendelijke interface. Een toetsenbord werkt handig op een laptop of computer, maar is behoorlijk onhandig op een mobiele telefoon.
Toegankelijkheid blijft niet beperkt tot een systeem bruikbaar maken voor mensen met een beperking. Iedere gebruiker heeft baat bij een toegankelijk systeem. Een interface dient zo ontworpen te worden dat hij vlot toegankelijk is voor iedereen. Bedieningsgemak en eenvoud in gebruik zijn belangrijke normen. Een goed ontworpen interface zorgt ervoor dat gebruikers zo min mogelijk fouten kunnen maken.
Toegankelijkheid en gebruiksvriendelijkheid hangen af van een heleboel factoren.
Een gebruikersinterface moet eerst de lagere behoeften van de gebruiker bevredigen, daarna pas de hogere. We hebben het hier uiteraard niet over voedselvoorziening, maar over de functionaliteit van een digitaal systeem. Een tekstverwerker bijvoorbeeld moet in eerste instantie de mogelijkheid bieden om tekst in te voeren, tekstopmaak, het toevoegen van tabellen en afbeeldingen zijn hogere behoeften.
Hierin volgt een ontwerper de behoeftepiramide.
|
Functionaliteit |
Bepaalde functies mogelijk maken. |
|---|---|
|
Betrouwbaarheid |
Een videorecorder moet echt opnemen als je op de ârecordâ-knop drukt. |
|
Gebruiksgemak |
Je kan dingen makkelijk doen. |
|
Bekwaamheid |
Je kan dingen beter doen dan voordien. |
|
Creativiteit |
Alle behoeften zijn bevredigd. Indien je dit niveau bereikt, verkrijg je van de gebruikers soms een loyaliteit met cultachtige status (vb. Apple) |
Bij het ontwerp kies je niet tussen flexibiliteit (veel mogelijkheden) en gebruiksgemak. Je moet zelf afwegen welk onderdeel voor jouw ontwerp of interface het meest doorweegt. Een flexibel ontwerp biedt de gebruiker meer mogelijkheden, maar is minder efficiënt.
Een vaak gemaakte fout is veronderstellen dat flexibiliteit boven gebruiksgemaak gaat. Een PC is bijvoorbeeld heel flexibel, maar moeilijker aan te leren en te bedienen dan een smartphone. Bij een PC zijn veel mogelijkheden bij aankoop nog onbekend. Een student die de richting multimedia start, heeft geen idee waarvoor hij/zijn zijn toestel een paar maand later allemaal zal gebruikt hebben. De verkoper/ontwerper moet in dit geval anticiperen op het toekomstig gebruik. Als het publiek inzicht heeft in wat het wil, heeft specialisatie voorkeur. Voor iemand die klaar en duidelijk weet dathij enkel af en toe wat wil surfen op het internet, volstaat een tabletcomputes. Wie niet precies weet waarvoor hij een computer allemaal zal inzetten, mikt op flexibiliteit.
Flexibiliteit betekent echter niet dat we gebruiksgemak uit het oog moeten verliezen. Eenvoud in gebruik heeft steeds de voorkeur boven complexiteit. Volg het KISS-principe ( keep it simple and smoothof keep it simple and stupid). Twijfel je bij het ontwerp van een interface tussen een simpele oplossing en een meer complexe omdat die bijvoorbeeld intelligenter overkomt, kies dan steevast voor de simpele (de regel van âOckhams scheermesâ).
c. Mapping:
Als een gevolg overeenkomt met de verwachting dan zit de mappinggoed. Wanneer een knop of een reeks acties of commando's in een digitaal systeem precies leidt tot wat de gebruiker verwacht, dan zit het gebruiksgemak goed. Plaats de bedieningsonderdelen (knoppen, sliders...) zodanig dat mensen weten wat er zal gebeuren als ze er gebruik van maken.
d. Prestaties
Het is niet omdat iets beter âpresteertâ, dat de voorkeur van de gebruiker daarnaar uitgaat.
e . H erkenning boven herinnering:
In de eerste computerinterfaces gaf de gebruiker commando's via een tekstinterface. Je moest de instructies of commando's goed onthouden om de computer te vertellen wat je precies wou doen. In een GUI zitten commando's achter knoppen verstopt. Dat maakt het gebruik veel eenvoudiger. De gebruiker âherkentâ de commando's en hoeft ze niet meer te onthouden. Houd hier rekening mee wanneer je een interface bouwt. Wanneer de gebruiker te veel stappen moet onthouden, zal hij sneller geneigd zijn hulp in te roepen. Maak de gebruiker desnoods bij elke stap duidelijk wat de volgende stap is. De in besturingssystemen aanwezige API's maken het voor programmeurs mogelijk om herkenbare dialoogvenster op te roepen vanuit hun eigen software. Maak zelf ook gebruik van herkenbare symbolen en de plaats waar je ze geeft op het computerscherm. Hoe herkenbaarder, hoe groter het gebruiksgemak.
a. G epercipieerd gebruiksgemak:
Esthetische ontwerpen wekken de perceptie dat ze eenvoudiger in gebruik en dus gebruiksvriendelijker zijn, ook al is dit niet automatisch zo. Esthetische ontwerpen nodigen meer uit tot een positieve attitude. Mensen zijn ook toegeeflijker en toleranter tegenover ontwerpfouten als het ontwerp er esthetisch goed uitziet. Een mooi interface-ontwerp werkt als katalysator voor de creativiteit en probleemoplossend denken. Minder esthetische ontwerpen, verstikken de creativiteit. Esthetische ontwerpen worden sneller geaccepteerd, en wekken de indruk dat ze gebruiksvriendelijker zijn. Uiteraard blijft âschoonheidâ en âesthetiekâ een zeer subjectief gegeven, maar de perceptie is op dit vlak moeilijk te wijzigen. Denk aan het idee dat veel Apple-gebruikers hebben over de producten van hun favoriete merk. Wie aan Apple denkt, denkt aan mooi design, gebruiksvriendelijkheid, eenvoud in gebruik, stabiliteit... ook al klopt dat niet altijd. Voor concurrenten is het bijzonder moeilijk om die perceptie voor de eigen productlijn op te wekken.
b. Kleuren:
âOver kleuren en smaken valt niet te discussiërenâ zegt het spreekwoord. Nochtans klopt dit niet helemaal. Je kan twee kleuren die op het eerste zicht met elkaar âvloekenâ bij elkaar plaatsen als dat uw smaak is. Maar wanneer je er andere kleuren of tinten bij betrekt, gaat die stelling niet meer op. Passende kleurcombinaties kan je wiskundig berekenen. Niet alle kleuren of tinten passen bij elkaar. Op paletton.com kan je passende kleurpaletten berekenen voor je eigen ontwerpen.
Consistentie van stijl en kleur maken een systeem meer helder en bruikbaar.
c. Fibonaccireeksen en de Gulden Snede
Oeps, dit lijkt wel een stukje wiskunde en dat is het ook. Fibonaccireeksen (oneerbiedig ook wel eens âkonijnenreeksenâ genoemd naar het voortplantingsgedrag waarmee deze dieren worden vereenzelvigd) komen in de natuur heel vaak voor. In een Fibonaccireeks is elk volgend getal de som van de twee voorgaande getallen. Fibonaccireeksen duiken op in de natuur, maar ook in de vormgeving ( Gulden snede ).
Plaats je een passer op het scheidingspunt tussen twee vierhoeken en trek je een kwartcirkel, dan bekom je een soort van spiraalvorm. De Gulden Snede duikt op in de natuur en reeds in de Oudheid gebruikten kunstenaar het in de architectuur en de kunst.
De Gulden Snede bereken je op de volgende manier: `a : b = (a+b) : a` (waarbij a en b de verhouding zijn van de brede en de lange zijde). De verhouding tussen a en b heet het Gulden Getal en uitgedrukt met de Griekse letter PHI (opgelet: niet PI of 3,14...)

d. Vorm volgt functie:
In de architectuur en vormgeving dook vooral sinds de twintigste eeuw de idee op dat esthetiek ondergeschikt is aan de functie. Functies zijn inderdaad minder subjectief dan esthetische overwegingen. Toch heeft het voorgaande al duidelijk aangeduid dat esthetiek niet onbelangrijk is. Als ontwerper kies je niet vorm en functie. De vorm kan best wel afgestemd zijn op de functie. De functionaliteit mag niet verloren gaan achter het uitzicht.
e. Symmetrie:
Symmetrie wordt altijd als schoon ervaren. We onderscheiden drie vormen van symmetrie
Weerspiegeling,
rotatie,
translatie
Translatie-symmetrie in een gridsysteem voor websites. 1
Rotatie-symmetrie 2

 Een interface/ontwerp moet vlot leesbaar zijn. Het letterbeeld, het gekozen lettertype, de lettergrootte kunnen de leesbaarheid bevorderen of kraken. In doorlopende tekst gebruik je een vlot leesbaar lettertype. Schreefloze letters zijn vlotter leesbaar voor dyslectici, maar uiteindelijk haalt iedereen er voordeel uit.
Een interface/ontwerp moet vlot leesbaar zijn. Het letterbeeld, het gekozen lettertype, de lettergrootte kunnen de leesbaarheid bevorderen of kraken. In doorlopende tekst gebruik je een vlot leesbaar lettertype. Schreefloze letters zijn vlotter leesbaar voor dyslectici, maar uiteindelijk haalt iedereen er voordeel uit.
Bron 4
Leesbaarheid gaat verder dan enkel het kunnen lezen van een aanwezige tekst. De informatie moet vlot opgenomen worden en bestendigen in het geheugen en de herinnering van de eindgebruiker. Informatie in welke vorm ook (teksten, afbeeldingen, artikels, invulformulieren...) kunnen zo gepresenteerd worden dat de informatie vlotter toegankelijk is en de gebruiker meteen een duidelijk overzicht krijgt.
a. Hiërarchie:De zichtbaarheid kan erg verbeteren door hiërarchische verbanden te visualiseren. Die techniek is zeer effectief om de structuur en de toegankelijkheid te te bestendigen in het geheugen van de gebruiker. Dit kan op diverse manieren met boomstructuren, netstructuren, trapstructuren, lagen...

c. Beeldende representatie: gebruik van pictogrammen en afbeeldingen
Bron afbeelding
5: Schermiconen op het bureaublad van de Xerox Star, de opvolger van de Xerox Alto (1981).
De meeste GUI's maken veelvuldig gebruik van pictogrammen. De metrointerface van Microsoft Windows is daar tendele van afgestapt. Het gebruik van schermpictogrammen als symbolische links naar bepaalde programma's of bestanden is reeds aanwezig van bij de eerste âgraphical user interfacesâ voor de Xerox Alto-computer in de vroeger jaren 1970.
Men onderscheidt in interfacedesign verschillende soorten pictogrammen:
â vergelijkbare pictogrammen: tekeningen die lijken op een handeling, object of concept.
â voorbeeldpictogrammen: dingen die geassocieerd worden met een handeling (vb. hangslot voor beveiliging).
â symbolische pictogrammen: afbeeldingen van een handeling op eenhoger abstractieniveau.
â weinig of geen verwantschap (vb. een schelp in SmartSchool om naar je puntenboek te gaan).
â
Een beeld zegt meer dan duizend woorden,â is een veel gehoorde uitspraak, maar klopt slechts ten dele. Men doelt dan op het zogenaamde visuele geheugen, maar er is weinig wetenschappelijk bewijs voor het bestaan van iets als een âvisueelâ of âauditiefâ geheugen. Uiteraard geldt ook hier âherkenning boven herinneringâ, maar meer afbeeldingen leiden niet noodzakelijk tot een âbetere herinneringâ.In het ontwerp van user interfaces en presentatie gaat de voorkeur uit naar een
combinatie van tekst en afbeelding.
d . S tapsgewijze informatieverstrekking (progressive disclosure):
De complexiteit van een toepassing kan aardig verlagen door de informatie niet alleen in kleine onderdelen (chunks) op te splitsen, maar ze ook stapsgewijs te verstrekken. Een slideshow, 'lees meer'-knop, uitklapmenu's, leerpaden (in bijvoorbeeld e-learningomgevingen), tabbladen... verhogen op die manier eveneens het leerrendement.
e. Nabijheid en similariteit:
Gebruikers ervaren elementen die dicht bij elkaar liggen als gerelateerd, en elementen die elkaar overlappen als âgemeenschappelijkâ. Knoppen die op elkaar gelijken, lijken eerder bij elkaar te horen. Hoe dicht bepaalde elementen bij elkaar staan, bepaalt dus in sterke mate hoe ze door de gebruiker ervaren worden. Zorg ervoor dat benamingen vlak bij elementen staan en niet in afzonderlijke âlegendaâ (zoals bijvoorbeeld bij grafieken in MS Excel).
f. V an Restorff-effect:
Welke momenten uit je schooltijd heb je het best onthouden? Niet zo zeer de leerstof, maar vooral de anekdotes. Opvallende dingen onhoud je nu eenmaal beter dan gewone dingen. Dat heet het âVan Restorffâ-effect. Wil je elementen benadrukken, zorg dan dat ze opvallen. Gebruik eventueel ongewone beelden, speel met het tekstbeeld...
g . S eriële positie-effect:
Gebruikers onthouden items aan het begin van een lijst (of het nu gaat om een reeks slides in de presentatie, een lijst met knoppen...) het best, die in het midden het minst. Naar het einde van de lijst toe, blijven items weer beter in het geheugen hangen.. Dit recentheidseffectgeldt vooral bij een auditieve lijst.
h. Signaal-ruisverhouding:
Houd een interface of voorstelling overzichtelijk, en overlaadt ze niet met te veel beeld of animatie. Alles wat de ontvanger te veel afleidt van de eigenlijke boodschap vormt ruis. Een goede interface zorgt voor betere communicatie met de eindgebruiker. Richt je daarom op het âsignaalâ en beperk de âruisâ.
Ik bestel om 19 uur 's avonds treintickets op de website van de NMBS. Vooraleer ik de bestelling kan uitvoeren, moet ik de gebruiksvoorwaarden, die ik uiteraard niet lees, goedkeuren. Ik wil vooral dat dit snel is afgehandeld. Dat verwacht je ook van de gebruikersinterface. De betaling verloopt via een externe site en even later krijg ik in mijn mailde bestelde tickets in PDF-formaat. Wanneer ik ze afdruk, blijkt dat ik de (zo goed als) voorbije dag als afreisdatum heb ingesteld. Er zit niets anders op dan de tickets nogmaals aan te kopen en, inderdaad, nogmaals 65 euro te betalen. Ik meld mijn fout aan de online support van de NMBS, maar krijg nooit antwoord en het geld wordt ook niet terugbetaald. Als gebruiker ben ik bestraft voor mijn onoplettendheid en vooral omdat ik snel wou zijn. Nergens heeft de site me gewaarschuwd dat het wel vreemd is dat ik tickets bestel voor een dag die zo goed als afgelopen is. Nochtans is het nogal waanzinnig om tickets met toegang tot het pretpark Plopsaland de Panne te bestellen als het pretpark al een uur is gesloten. Het foutief betaalde bedrag krijg ik niet terug omdat ik âakkoordâ ben gegaan met de gebruiksvoorwaarden. Toegegeven, mijn fout, maar ook: welkom in de wereld van slecht interface-design en gebrek aan feedback. De support achter de digitale omgeving hult zich in stilzwijgen. In de echte fysieke wereld zouden zulke vormen van âbestraffingâ als bijzonder onrechtvaardig ervaren worden.
Een goede UI moet deze vormen van âdigitale onrechtvaardigheidâ voorkomen door gerichte foutcontroles in te bouwen.
a. B evestigingsprocedure:
Door bevestiging te vragen, kunnen onopzettelijke en ondoordachte handelingen voorkomen worden. Overdrijf hier echter niet in, want anders krijgen gebruikers het âben je hier wel zeker vanâ-gevoel. Verificatie is enkel noodzakelijk indien het beslissingen nadien niet meer kunnen aangepast worden. In het bovenstaande NMBS-voorbeeld had de site kunnen vragen: âU staat op het punt tickets te bestellen voor een dag die bijna afgelopen is. Bent u hier zeker van?â
b. Restricties:
 Door
stapsgewijze informatieverstrekkingkan het aantal potentiële fouten tot een minimum herleiden. Zulke
f
ysieke restricties(begrenzingen, paden) laten de gebruiker toe bepaalde functies enkel binnen een bepaalde zone uit te voeren.
Door
stapsgewijze informatieverstrekkingkan het aantal potentiële fouten tot een minimum herleiden. Zulke
f
ysieke restricties(begrenzingen, paden) laten de gebruiker toe bepaalde functies enkel binnen een bepaalde zone uit te voeren.
Daarnaast kan je het foutief gedrag van eindgebruikers voorkomen door een reeks p s ychologische restricties:
â symbolen: waarschuwing, icoontjes, pictogrammen kunnen gebruikersgedrag beïnvloeden
â conventies: rood is gevaar, geel is waarschuwing

â
mapping: welke handelingen zijn mogelijk? De zichtbaarheid, het uiterlijk, de plaatsing van de interface-elementen... spelen hier een rol.
c . G arbage in, garbage out:
Als je fouten kan invoeren, krijg je foute output (vb. in veld van postcode: niet invullen of geen cijfer invoeren). Foutcontrole voorkomt foute output. Als UI-ontwerper moet je voorkomen dat troepwordt ingevoerd. In webpagina's gebeurt op basis van âreguliere expressiesâ (zie 5.3.1) een controle op invoer van gebruikers in formuliervelden.
d. De wet van Fitts en inspanningsbelasting
Hoe verder een doel verwijderd is, hoe langer het duurt om het te bereiken. Hoe sneller de beweging en hoe kleiner het doel, hoe groter de foutenmarge (door snelheid en accuraatheid). Het menu dat tevoorschijn komt als je op de rechtermuisknop drukt staat meteen bij het doel. Die beperkt het aantal potentiële fouten bij de invoer of bewerking van gegevens. Hier geldt eveneens de inspanningsbelasting:
e . O perante conditionering:
Operante conditionering is een techniek om gewenst gedrag positief te bevestigen/belonen en ongewenst gedrag te bestraffen. Het duikt vaak op in leeromgevingen (e-learning) en games. Men hanteert bij UI-design drie methodes: positieve en negatieve bekrachtiging, bestraffing (vb. volgend level of game over).
a . W et van Hick en controle van de functionaliteit
![]() Hoe meer opties een gebruiker krijgt, hoe langer de benodigde tijd om een beslissing te nemen (wet van Hick). Dit wil niet zeggen dat je de mogelijkheden van een interface volledig moet afbouwen en de mensen enkel voorzien van een simplistische interface met nagenoeg geen mogelijkheden. Heel wat software begrenst de mogelijkheden afhankelijk van de kennis en de ervaring van de gebruikers. De gebruiker krijgt dan via een knop toegang tot een aantal
geavanceerdeopties. In games vorderen gebruikers stapsgewijs doorheen verschillende niveaus (levels).
Hoe meer opties een gebruiker krijgt, hoe langer de benodigde tijd om een beslissing te nemen (wet van Hick). Dit wil niet zeggen dat je de mogelijkheden van een interface volledig moet afbouwen en de mensen enkel voorzien van een simplistische interface met nagenoeg geen mogelijkheden. Heel wat software begrenst de mogelijkheden afhankelijk van de kennis en de ervaring van de gebruikers. De gebruiker krijgt dan via een knop toegang tot een aantal
geavanceerdeopties. In games vorderen gebruikers stapsgewijs doorheen verschillende niveaus (levels).

b. 80/20-regel:
Gebruikers benutten volgens schatting 80% van de werktijd slechts 20% van de functies in een UI. Bij het ontwerp van een interface moet je je dan ook richten op die 20%. Niet-kritische functies die behoren tot de 80%, beperk je tot een minimum of je gooit ze helemaal weg. Ondermeer om die reden zit bij software veel functionaliteit verborgen achter uitklapmenu's.
Herkenning gaat boven herinnering, Een herkenbare âomgevingâ verhoogt de gebruiksvriendelijkheid.
a. Affordance en skeuomorfisme
Afbeelding: Skeuomorfisme in Apple Garageband.
 De fysieke eigenschappen van een object of omgeving (bijvoorbeeld een interface) beïnvloeden het functioneren ervan. Dat klinkt nogal ingewikkeld, maar een paar voorbeelden maken veel duidelijk. Een deur nodigt uit om een kamer te betreden, een raam biedt die functie ook, maar is hiervoor minder âuitnodigendâ (tenzij je een inbreker zou zijn natuurlijk). Die vorm van âuitnodigingâ noemt men
affordance. Als de affordance van een object om omgeving goed overeenkomt met de bedoelde functie, dan verhoogt het gebruiksgemak en de doelmatigheid van de prestaties. Een deur met een âklinkâ nodigt uit om aan te trekken, niet om tegen te duwen. Als je de klink vervangt door een vlakke metalen plaat, weet de gebruiker meteen dat hij/zij tegen de deur moet duwen om binnen te komen. De affordance zit op dat moment zeer goed.
De fysieke eigenschappen van een object of omgeving (bijvoorbeeld een interface) beïnvloeden het functioneren ervan. Dat klinkt nogal ingewikkeld, maar een paar voorbeelden maken veel duidelijk. Een deur nodigt uit om een kamer te betreden, een raam biedt die functie ook, maar is hiervoor minder âuitnodigendâ (tenzij je een inbreker zou zijn natuurlijk). Die vorm van âuitnodigingâ noemt men
affordance. Als de affordance van een object om omgeving goed overeenkomt met de bedoelde functie, dan verhoogt het gebruiksgemak en de doelmatigheid van de prestaties. Een deur met een âklinkâ nodigt uit om aan te trekken, niet om tegen te duwen. Als je de klink vervangt door een vlakke metalen plaat, weet de gebruiker meteen dat hij/zij tegen de deur moet duwen om binnen te komen. De affordance zit op dat moment zeer goed.
Bij het ontwerp van software-interfaces gebruikt men vaak afbeeldingen van fysieke objecten om de functie van de interface-elementen te verduidelijken. Het programma Garageband van Apple gebruikt bijvoorbeeld herkenbare knoppen van gitaarversterkers om de affordance te verhogen. Die techniek waarbij men afbeeldingen van bestaande toestellen of onderdelen ervan gebruikt binnen een andere omgeving, heet skeuomorfisme. Het beperkt zich zeker niet tot software alleen. Het nabootsen van materialen in meubels of bij interieurdesign, is eveneens een vorm van skeuomorfisme. Bij software is het de bedoeling dat zogenaamde "skeuomorphs" de herkenbaarheid en het gebruiksgemak verhogen. In wezen kan je heel wat "metaforen" die men bij het ontwerpen van interfaces gebruikt, skeuomorfismen noemen: de prullenmand, het bureaublad. De graad waarin een ontwerper de overeenkomst met fysieke objecten doorvoert kan echter meer of minder prominent zijn. Steve Jobs en Apple-ontwerper Scott Forstall waren grote voorstanders van skeuomorfisch ontwerp. Na de dood van Steve Jobs en het ontslag van Forstall, kreeg John Ive, een groot tegenstander van skeuomorfisme, de leiding over de "look and feel" van iOS7. Dit verklaart de plotse ommekeer in de Apple-interface van een sterk aanwezig skeuomorfisme naar een meer vlakke stijl in de aard van Microsofts "metro"stijl. Tegenstanders van skeuomorfisme argumenteren dat skeuomorfisme enkel een "overgangsfase" was:
"Now recall what skeumorphism really is: itâs a transitional design to aid us over the bridge from old ways of doing something to the new way. But now almost all adults have crossed over that bridge. Future smartphone sales are going to be either replacement phones or to the young just entering the marketplace. And those latter wonât have any clue at all about those old ways of doing things. Who currently under the age of 20 will ever see a Rolodex outside a museum (or their grandparentsâ study)?"(Tim Worstal) 1
Toch wil dit geenszins zeggen dat hiermee elke overeenkomst met âfysiekeâ objecten of omgevingen overboord wordt gegooid.
b. Metaforen
Hoe sterk tegenstanders van skeuomorfisme ook hun best doen, een digitale interface blijft op één of andere manier wel steeds schatplichtig aan zijn analoge voorgangers. We spreken nog steeds van een bureaublad of desktop, ook al ervaart lang niet iedereen dit meer als een digitale versie van een âechtâ bureaublad. Een map (Engels: folder) heet nog steeds een map. Een âprullenmandâ blijft nog steeds aanwezig in zo goed als elke GUI. In heel wat applicaties blijven ontwikkelaars zich bedienen van metaforen en analogieën met âanaloge voorgangersâ. Adobe Photoshop gebruikt net zoals een massa andere digitale beeldbewerkingsapplicaties virtuele âlagenâ waarmee je als gebruiker composities kan samenstellen, net zoals tekenfilmmakers vroeger elk beeld opbouwden door afzonderlijke figuren op celluloidlagen boven elkaar te plaatsen. De tijdlijn in videomontagesoftware is nog steeds een virtuele weergave van een klassiek filmspoor. Adobe Flash noemt zijn werkgebied de âsceneâ en objecten kan je bewaren in de âlibraryâ. Gelijkenissen en metaforen zorgen voor herkenbaarheid en dat is misschien maar goed ook.
c. Mimicry
In de natuur bootsen wandelende takken een echte âtakâ na om zich te verbergen voor hun vijanden. Op dezelfde manier bootsen interface-ontwikkelaars fysische objecten of hun functionaliteit na om de herkenbaarheid te verhogen. Een klassiek telefoontoestel en zelfs een iPhone bootst in zijn toetsenbord het toetsenbord van een rekenmachine na. Die nabootsing kan op drie niveaus gebeuren:
|
het uiterlijk lijkt op iets anders |
pictogram van een map |
|
het ontwerp gedraagt zich zoals iets anders |
een robot die zich beweegt zoals een insect |
|
het ontwerp werkt zoals iets anders |
toetsenbord van een rekenmachine bij een oude Nokia-GSM. |
Een goed en herkenbaar verhaal, een pittige anekdote, een pakkend emotioneel verhaal... zorgt voor een gevoel van herkenbaarheid. Bij de presentatie van een product, een film of animatie, een presentatie trekt een sterk verhaal de aandacht van de gebruiker. Bij User Interface- of User Experience-design kan storytelling op nog een andere manier ter hulp schieten.
Het ontwerp bepaalt hoe gebruikers (mensen) het eindproduct ervaren. Dit gebeurt op verschillende niveaus en vertaalt zich in drie vormen van ontwerp: 2
|
Visceral design |
we houden automatisch van bepaalde dingen (knappe mensen, symmetrie...) en voelen ons afgestoten van andere (spinnen, rot vlees...). Dit niveau bepaalt onze eerste relatie met een ontwerp. |
We kiezen er bewust voor om âbangâ te zijn als we naar een griezelfilm gaan kijken. |
|
Behavioral Design |
Hoe werkt het product? De look and feel, gebruiksvriendelijkheid... |
Hoe ervaren we de film? |
|
Reflective Design |
Welke waarde kennen we aan het product toe na het eerste gebruik. |
We weten dat de vampieren niet echt bestaan en ons (zeker niet vanuit de film) lastig kunnen vallen. |
Bij het ontwerp van een product, dienst, interface... moeten we terdege rekening houden met die drie niveaus. Hoe de eindgebruiker de interface of het product emotioneel aanvoelt, bepaalt mee het succes van het ontwerp. Bij UX-design werken professionals met heel verschillende achtergronden samen aan één project. Er moet rekening gehouden worden met grafisch ontwerp, technische mogelijkheden en beperkingen, commerciële overwegingen enz. Het is niet eenvoudig om in zo'n samenwerkingsverband de eindgebruiker centraal te stellen. De eindgebruiker is het âExperience Themeâ (Cindy Chastain), de hoofdrolspeler van het UX-ontwerp. Zonder zo'n leidraad kan er wel een product afgeleverd worden, maar dan blijft het een verhaal zonder doel, of beter gezegd een verhaal zonder rode draad.
Oef, dit klinkt allemaal nogal ijl en wellicht denk je, wat moet ik hiermee? Nochtans is het niet zo vreemd dat het uiteindelijke doel van een ontwerp een eindgebruiker (en liefst meer dan één is). Ongetwijfeld heb je al een beeld voor ogen van het doelpubliek. Door fictieve personages met al even fictieve, maar potentieel mogelijke, verhalen te verzinnen voor de ontwerpronde, krijgt ieder lid van het ontwerpteam een duidelijk beeld van wat het uiteindelijke doel van het ontwerp is. Ieder lid van het team kan op die manier het oorspronkelijke doel en de strategie voor ogen houden, ongeacht zijn/haar taak of achtergrond. Elk lid van het ontwerpteam kan zich hierdoor inleven in de eindgebruiker.
1.
1KNIGHT, K., "Symmetry in Design: Concepts, Tips and Examples", (http://sixrevisions.com/web_design/symmetry-design/), Geraadpleegd op 9 september 2015.
2
Ibid.
3
Ibid.
4
"Welk lettertype gebruik ik het best?", (http://www.wallacesanders.be/veelgestelde-vragen/welk-lettertype-gebruik-ik-het-best/), Geraadpleegd op 10 september 2015.
5
INTERACTION DESIGN FOUNDATION,
"A Brief History of the Origin of the Computer Icon"
, (https://www.interaction-design.org/ux-daily/21/a-brief-history-of-the-origin-of-the-computer-icon), Geraadpleegd op 10 september 2015.
lorem ipsum
De Microsoft Kinect is een zeer geavanceerde spelcontroller voor de Xbox. Je kan het toestel ook 'hacken' en inzetten voor gebruik in andere software/hardware-omgevingen. BORENSTEIN, G.,
3D-scanning met Processing en Kinect: MELGAR, E.,DIEZ, C.,

3D motion tracking met Processing en Kinect:

Een interactieve interface met Processing en Kinect:

Een pixelafbeelding moet een bestaande afbeelding omzetten in digitale codes of een âbeeld uit de werkelijkheidâ omzetten in een reeks digitale codes. Het principe achter digitalisering is even eenvoudig als geniaal, en vooral ook niet nieuw. Reeds in de Klassieke Oudheid was de techniek van het âdigitaliserenâ of coderen van informatie bekend. Uiteraard digitaliseerde men toen geen afbeeldingen, maar gebruikte men een gelijkaardige techniek voor het verzenden van tekstboodschappen.
Cleoxenus en Democlitus bedachten een methode die verder werd uitgewerkt door Polybius, waardoor de communicatie op lange afstand aanzienlijk verbeterde. Ze gebruikten combinaties van fakkels, vastgemaakt aan panelen. Elke combinatie van fakkels vertegenwoordigde een bepaalde letter uit het alfabet. Hiervoor werden twee (houten?) panelen opgesteld. Elk paneel was voorzien van houders voor maximum 5 fakkels. Dit gaf een totaal van 25 mogelijke combinaties wat ongeveer overeen kwam met het aantal letters in het Griekse alfabet.
Naar analogie kunnen we dit vergelijken met de werking van een kruiswoordraadsel. Het eerste paneel staat dan voor de horizontale cijfers in het raster, het tweede (rechtse) paneel voor de verticale cijfers langs het raster. Twee fakkels op het linkerpaneel en vijf fakkels op het rechterpaneel stonden voor de letter k. De vergelijking met een kruiswoordraadsel doet een beetje afbreuk aan de inventiviteit van deze vondst.
De zender âscantâ een tweedimensionale rij van lettertekens. Hij verzendt informatie over de positie van elk element in een raster.Het roept vergelijkingen op met de methodes die door televisies en faxtoestellen worden gebruikt voor het scannen en verzenden van afbeeldingen. Het doet ook denken aan de discretisatie bij het digitaliseren van afbeeldingen
1
.
Vergelijk een digitale afbeelding met een tabel (zoals bijvoorbeeld in een rekenbladprogramma). Elke horizontale pixel krijgt een cel in een (horizontale) rij. Maar ook verticaal wordt elke pixel in een rij geplaatst. Een afbeelding van 300 x 400 pixels bevat op die manier 400 kolommen (horizontaal) en 300 rijen of een totaal van 120 000 pixels.
Net zoals in MS Excel kan je een tabel ook voorstellen als een grafiek. In het vak wiskunde heb je geleerd dat een grafiek een horizontale as (de x-as) en een verticale as (de y-as) heeft. In een grafiek raken de x- en de y-as elkaar links onderaan. Op dat punt is x=0 en ook y=0. Bij een beeldscherm of bij een afbeelding vormt de linkerbovenhoek het absolute ânulpuntâ. De pixel links bovenaan op je computerscherm, in je programmavenster of de linkerbovenhoek van een digitale afbeelding staat op x=0 en y=0. De positie van die pixel is dus x=0 en y=0. Als we één pixel opschuiven naar rechts, dan zitten we op x=1, y=0 enz. Gaan we in plaats van naar rechts, één pixel naar beneden, dan krijgen we x=0, y=1 enz.
In de meest eenvoudige vorm van een digitale afbeelding kan elke pixel twee mogelijke waarden krijgen: een 0 of een 1. Een 0 zou dan kunnen staan voor wit en een 1 voor zwart. We spreken dan van een âbitmapâ, of een âbit-kaartâ. Inderdaad, elke pixel heeft een plaatsje gekregen op de âkaartâ en kan een waarde van één bit krijgen.
Hieronder zie je hoe je op die manier een smiley zou kunnen tekenen.
|
1 |
1 |
1 |
||||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
|||||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
|||||||||
|
1 |
1 |
|||||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
1 |
1 |
1 |
||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
1 |
1 |
1 |
Elk van die pixels heeft een positie in de tabel. De eerste pixel (links bovenaan) staat bijvoorbeeld op x=0 en y=0. Pixelbewerkingen op zo'n afbeelding zijn relatief eenvoudig. Als we de afbeelding willen âinverterenâ, dan vervangen we alle 1'en door een 0 en omgekeerd.
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
|||||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
Uiteraard bevatten de meeste afbeeldingen meer dan 2 kleurwaarden. Hierover leer je meer in het volgende onderdeel.
Als we over digitale afbeelding spreken, dan hebben we het zowel over de manier waarop die afbeeldingen als bestanden worden bewaard, als over de manier waarop een digitaal beeldscherm de afbeeldingen weergeeft. Aan de binnenkant van een beeldscherm zitten de zogenaamde
pixels(picture elements), kleine âpuntenâ die het licht in een bepaalde kleur kunnen uitzenden. De
resolutievan een beeldscherm vertelt hoeveel pixels een scherm horizontaal en verticaal kan weergeven.
Pixels kunnen kleuren weergeven door de
primaire kleurenrood, groen en blauw in een bepaalde verhouding bij elkaar op te tellen (optellen= to add, vandaar
âadditiefâ kleursysteem).
De hoeveelheid die van elke primaire kleur nodig is om een bepaalde mengkleur te verkrijgen, drukt men uit in een getal van 8 bits oftwel 256 verschillende waarden. Vermits een computer ook 0 meerekent (geen hoeveelheid), kan de waarde variëren van 0 ('niets van die kleur') tot 255. Je kan die kleurwaarde ook uitdrukken in een âhexadecimaleâ waarde. Bij hexadecimale coderingkan je de volgende waarden toekennen om tot 256 verschillende combinaties te komen: 00 (tot 99 en alle combinaties daar tussen) tot FF (van AA tot FF en alle combinaties daar tussen). De waarde #CCCCCC geeft bijvoorbeeld lichtgrijs, #000000 geeft zwart, en #FFFFFF toont wit.
|
Kleur |
Rood |
Groen |
Blauw |
RGB-waarde |
|---|---|---|---|---|
|
Wit |
FF |
FF |
FF |
#FFFFFF |
|
Zwart |
00 |
00 |
00 |
#000000 |
|
Rood |
FF |
00 |
00 |
#FF0000 |
|
Groen |
00 |
FF |
00 |
#00FF00 |
|
Blauw |
00 |
00 |
FF |
#0000FF |
|
⦠|
⦠|
⦠|
⦠|
... |
Vermits elke kleur op die manier 256 verschillende waarden kan krijgen, komen we op een totaal van 256*256*256=16 777 216 mogelijke mengkleuren.
 â
In toepassingen waar een hogere kwaliteit vereist wordt worden ook wel 12, 16 of nog meer bits per kleur gebruikt, waarmee kleurwaardes tussen 0 en 4095 resp. 0 en 65535 of nog meer aangegeven kunnen worden, zo bevatten RAW-bestanden van digitale camera's meestal 12-bits kleurwaarden.â
2
â
In toepassingen waar een hogere kwaliteit vereist wordt worden ook wel 12, 16 of nog meer bits per kleur gebruikt, waarmee kleurwaardes tussen 0 en 4095 resp. 0 en 65535 of nog meer aangegeven kunnen worden, zo bevatten RAW-bestanden van digitale camera's meestal 12-bits kleurwaarden.â
2
Het kleurenpalet in Adobe Photoshop:
 Een aantal RGB-kleurwaarden
3
:
Een aantal RGB-kleurwaarden
3
:
Digitale foto's zijn ook opgebouwd uit pixels en kunnen eveneens verschillend van afmeting zijn. Het aantal pixels per inch (PPI) noemt men de resolutievan de digitale afbeelding. Hoe hoger de resolutie, des te beter is de detailweergave.
Elke pixel heeft een kleur. Die kleur wordt vaak beschreven met een of meerdere bits (een âbitâ is een afkorting voor âbinary digitâ). Het aantal bits per pixel bepaalt het aantal kleuren dat een pixel kan weergeven. Een twee-bit pixel kan 4 kleuren weergeven; een 8-bit (eÌeÌn byte)-pixel geeft 256 kleuren weer. In het algemeen kan een pixel 2nkleuren weergeven als nhet aantal bits is. Welke verschillende kleuren een pixel kan weergeven, hangt niet alleen af van het aantal bits dat beschikbaar is, maar ook van de gebruikte kleurcodering. Er kan worden afgesproken dat iedere primaire kleur een aantal bits krijgt (RGB) of dat iedere unieke combinatie bits verwijst naar een bepaalde kleur in een palet. Dit laatste systeem wordt gebruikt in GIF-plaatjes, die maximaal 256 kleuren kunnen gebruiken.
Hoe hoger de beeldresolutie en hoe groter het aantal bits per pixel, hoe meer computergeheugen nodig is om alle informatie op het scherm te verwerken. In de allereenvoudigste weergave (1 bit = 1 pixel) kan een pixel alleen âaanâ of âuitâ staan.
Een megapixelis gelijk aan 1 miljoen pixels. De resolutie van een digitale camera wordt vaak in megapixels aangegeven. Dit is dan de resolutie (of het aantal pixels) die de CCD- sensor aankan. Om het correcte aantal pixels te weten vermenigvuldig je het aantal horizontale lijnen met het aantal verticale lijnen van de digitale foto. Zo is dus een camera die een foto produceert met een resolutie van 1280 x 960 pixels een 1.3 megapixel camera en een 5 megapixels camera zal dan een foto produceren van 2560 x 1920 pixels.
Hoe meer pixels, hoe groter het âbestandâ. Hoe meer pixels een afbeelding bevat, hoe meer informatie over de individuele kleuren moet bewaard worden. Om de bestandsgrootte in te perken kan men diverse compressietechnieken toepassen.
1. Een eerste manier bestaat erin om het aantal mogelijke kleurwaarden (de kleurdiepte) te beperken. Een GIF-afbeelding bijvoorbeeld kan maar 256 verschillende kleurwaarden bevatten voor alle kleuren samen. Dit betekent dat een GIF-afbeelding relatief klein is in bestandsomvang, maar ook niet meteen een geschikt formaat voor het bewaren van afbeeldingen waarin het aantal kleuren echt wel van belang is, zoals bijvoorbeeld een foto van een gezicht of een schilderij. In zekere zin bevatten alle digitale afbeeldingen een vorm van âcompressieâ, omdat ze het aantal kleuren in de werkelijkheid altijd op één of andere manier âbeperkenâ. Toch zal een afbeelding met een kleurdiepte van 16-bit (tov. 8 bit bij RGB-kleuren) of 24-bit veel meer ruimte innemen omdat ze veel meer kleurencombinaties mogelijk maakt. Dat wil daarom nog niet zeggen dat alle afbeeldingen sowieso even groot zijn. Een foto van een grasveld zal bijvoorbeeld minder âplaatsâ in nemen op een opslagmedium dan de foto van een schilderij van Pieter Paul Rubens.
2. Ten tweede kan je ook het aantal pixels reduceren.Je kan met beeldbewerkingssoftware het aantal pixels verlagen. Zo kan je een afbeelding van 1920 pixels breedte verlagen naar bijvoorbeeld 300 pixels. Deze techniek wordt vaak toegepast bij het klaarstomen van afbeeldingen voor het gebruik op internet. Ook het aantal pixels per inch kan verlaagd worden (dpi of dots per inch). Voor drukwerk heb je afbeeldingen nodig van 300 dpi, voor internet volstaan afbeeldingen met een resolutie van 72 dpi.Het aantal pixels of dpi verhogen is eveneens mogelijk, maar dit betekent niet dat de kwaliteit van de afbeelding groter wordt. De software voegt dan kunstmatig pixels toe door bepaalde pixels te verdubbelen. Verloren informatie kan echter niet worden âtoegevoegdâ. In politieseries op TV zie je bijvoorbeeld hoe men een âduidelijkâ beeld tevoorschijn tovert uit een lageresolutiebeeld van een digitale camera. Dit kan in feite niet.
3. T enslotte kan men ook met wiskundige algoritmes afbeeldingen comprimeren.Afbeeldingsbestanden kunnen op diverse manieren bewaard worden. TIFF, jpg, gif, png... zijn bekende bestandsformaten voor pixelafbeeldingen. Ze hebben allemaal hun specifieke doeleinden alsook voor- en nadelen. Een TIFF-afbeelding kan zonder compressie worden bewaard, d.w.z. dat alle pixelinformatie en alle informatie over de kleuren behouden blijft in het bestand. Uiteraard zorgt dit ervoor dat een TIFF-bestand veel meer ruimte inneemt op een opslagmedium.
Bij andere afbeeldingsformaten past de gebruikte digitale camera of software een compressiealgoritme toe. In zo goed als alle gevallen betekent dit dat bepaalde pixelinformatie verloren gaat en nadien ook niet meer kan worden toegevoegd.
Een voorbeeld van een compressie-algoritme:
'Het menselijk oog is gevoeliger voor helderheid dan voor kleur. Om op een onzichtbare manier informatie te verwijderen is het de bedoeling dat we minder informatie aan kleur opslaan dan aan helderheid.'Bij een JPG-afbeelding worden op die manier heel wat kleurverschilen weggelaten. Simpel voorgesteld: een jpegverdeelt een afbeelding in een raster waarbij gemiddelde waardes worden gemeten. Veel variatie in kleur wordt weggelaten. Hoe meer verschillen weggelaten worden, hoe groter de compressie.
Ongetwijfeld heb je al gehoord van beeldbewerkingssoftware zoals Adobe Photoshop of het open source GIMP ( www.gimp.org). Met software kan je heel eenvoudige bewerkingen uitvoeren op pixelafbeeldingen, maar ook heel geavanceerde waarbij je software gebruikt om composities te bouwen door verschillende lagenpixels âbovenâ elkaar te plaatsen. Met beeldbewerkingssoftware kan je allerlei bewerkingen doen op individuele pixels of op groepen pixels in een afbeelding.
Hogerop heb je reeds gezien dat een pixelafbeelding bestaat uit een aantal pixels.
Elke pixel krijgt binnen een matrix een unieke positie op basis van zijn x- en y-waarde in die âtabelâ.
 Elke pixel heeft een kleurwaarde. In beeldbewerkingssoftware kan je op basis van de positie van elke pixel een bepaalde âactieâ uitvoeren. Een âgomâ in Adobe Photoshop zal bijvoorbeeld de positie van de muiscursor vergelijken met die van de pixels waarboven de muis zich bevindt en vervolgens de kleurwaarde van die pixels vervangen door âwitâ. Als je de âdigitale gomâ groter maakt, zal Photoshop niet alleen de pixel onder de muiscursor wit maken, maar ook alles in een straal daar rond.
Elke pixel heeft een kleurwaarde. In beeldbewerkingssoftware kan je op basis van de positie van elke pixel een bepaalde âactieâ uitvoeren. Een âgomâ in Adobe Photoshop zal bijvoorbeeld de positie van de muiscursor vergelijken met die van de pixels waarboven de muis zich bevindt en vervolgens de kleurwaarde van die pixels vervangen door âwitâ. Als je de âdigitale gomâ groter maakt, zal Photoshop niet alleen de pixel onder de muiscursor wit maken, maar ook alles in een straal daar rond.
Machines begrijpen niet welke informatie in een foto staat. Ze herkennen geen koe, zon, huis of mens.
Toch kan je via de website www.tineye.comzoeken op welke plaatsen op het internet een bepaalde foto reeds eerder is gepubliceerd. Ook een âdeelâ van een afbeelding volstaat om ze terug te vinden in de mazen van het wereldwijde web. De mobiele versie van Google kan streepjescodes, merknamen, schilderijen enz. herkennen en u op basis daarvan de gewenste zoekresultaten tonen. Google Picasa herkent gezichten en kan zelfs de daaraan gekoppelde âpersonenâ herkennen, eens je aan een gezicht een naam verbindt. De machines van de Belgische firma BEST kunnen dankzij de beeldherkenningschip van de Leuvense firma EASICS in een hels tempo producten herkennen. Ze filteren tegen een gigantische snelheid frieten en muizenketels uit krenten, of schroeven uit paperclips. Slimme camera's herkennen gezochte boeven, en digitale politiecamera's herkennen nummerplaten. Op luchthavens âzoekenâ camera's naar verdachte gedragingen van aanwezigen. Big Brother is watching you. Hoe gebeurt zulke â beeldherkenningâ ( image recognition)?
 Op de manier waarop beeldherkenning of âpatroonherkenningâ werkt, is geen eenduidig en al zeker geen âeenvoudigâ antwoord te geven. Moderne image recognition-algoritmes werken vaak angstaanjagend goed, maar niet feilloos.
Op de manier waarop beeldherkenning of âpatroonherkenningâ werkt, is geen eenduidig en al zeker geen âeenvoudigâ antwoord te geven. Moderne image recognition-algoritmes werken vaak angstaanjagend goed, maar niet feilloos.
Image recognitionstoot op een hele reeks problemen die niet eenvoudig te overbruggen zijn. Zelfs firma's die zich reeds jaren op de ontwikkeling van zulke algoritmes toeleggen, stuiten nog steeds op het probleem dat hun âtoolsâ niet feilloos en 100% betrouwbaar werken. Menselijke controle of bijsturing is in veel gevallen nog steeds noodzakelijk.
Stel dat we een stuk software willen schrijven dat âgezichtenâ herkent in een afbeelding. Begrijp het niet verkeerd: de software herkent gezichten, maar niet de namen of personen die er aan verbonden zijn. Voor een mens is het duidelijk wat een gezicht is, maar het is niettemin moeilijk om er een definitie op te plakken die je in een herkenbare formule voor een machine zou kunnen gieten. We stuiten al snel op een definitie-probleem:
Een gezicht bevat een neus, twee ogen en een mond... maar hoe definieer je die individuele onderdelen ( feature detection)?
De onderlinge verhouding en positie van die âonderdelenâ is misschien belangrijker. Maar wat te doen als de machine enkel het zijprofiel van het gezicht te zien krijgt? Herkent de software dan nog steeds een âgezichtâ? Wat met âPiet Piraatâ als hij een ooglapje draagt? Is een smiley ook een gezicht? Vaak âtraintâ men de software met een trainingsset, waarbij de software zo is geprogrammeerd (met neurale netwerken) dat hij âkan lerenâ (eventueel met de hulp van een mens) of hij nu echt een gezicht heeft gevonden of niet. De software leert dan bij en onthoudt, net zoals een kind dat woordjes moet leren lezen.
Bovendien kan een afbeelding een gezicht in close-up tonen, of een groepsfoto met meerdere gezichten. Hier stuiten we op het probleem van â schaling-invariantieâ. Hoe vertel je een machine dat hij zowel âkleineâ als âgroteâ gezichten in een afbeelding moet herkennen? Sommige algoritmes kunnen met dit probleem van schaling overweg, maar de handigste manier om dit probleem te omzeilen is door te zorgen voor een â gecontroleerde omgevingâ.
Een voorbeeld:als je een camera in een straat hangt, kan je hem zo plaatsen dat de gezicht van alle mensen die voorbij de lens wandelen steeds ongeveer even groot zijn. Op die manier voorkom je het schalingsprobleem. 's Nachts gaat de camera problemen ondervinden met het herkennen van âgezichtenâ omdat de geregistreerde pixels de âdonkerâ zijn. Er is namelijk te weinig contrast tussen de gezichten en de omgeving. Een goed verlichte inkomhal is dus een beter te âcontrolerenâ omgeving dan een plaats in open lucht, waar de camera niet alleen te leiden heeft onder verschillen in belichting, maar ook onder regen, stof en wind.
Het mag duidelijk zijn dat er nog een verre weg is af te leggen vooraleer machines en software in staat zijn om met het gemak van menselijke intelligentie patronen zoals gezichten, huizen, dieren, groenten, fruit enz. te herkennen in een pixelbeeld van de omgeving.
Vectorafbeeldingen bestaan uit losse of gecombineerde geometrische vormen die met een kleur, verlooptint of 'afbeelding' worden gevuld.
Een cirkel zou je kunnen omschrijven op de volgende manier:
fill(0,0,255);
ellipse(200, 200, 100, 100);
De vulling van de cirkel wordt uitgedrukt in een RGB-waarde. De kleur van de cirkel is dus âblauwâ. De instructie ellipse() bevat een viertal parameters. De eerste paar waarden behandelen de x- en de y-positie t.o.v. het programmavenster. De twee volgende waarden bepalen hoe groot de âhorizontaleâ en de âverticaleâ straal moet zijn. Maak je die beide waarden gelijk, dan teken je een perfecte cirkel, maak je de ene waarde groter dan de andere, dan teken je een ellips.
Omdat enkel de cooÌrdinaten en de vormen en vullingen dienen opgeslagen te worden, blijven de bestanden uiterst klein. Een groot voordeel aan vectorafbeeldingen is dat zij oneindig kunnen geschaald worden zonder kwaliteitsverlies. Om de bovenstaande âellipsâ te vergroten, moet je enkel de waardes aanpassen:
fill(0,0,255);
ellipse(200, 200, 10000, 10000);
Lettertypes zijn over het algemeen eveneens vectorieel. Door deze voordelen zijn vectorafbeeldingen uitermate geschikt voor logo's, maar niet voor âfoto'sâ.
Vectortekenprogramma's:
Adobe Illustrator (commercieel)
Adobe Flash (commercieel, vectoranimatie)
CorelDraw (commercieel)
Processing (open source, vectoranimatie)
Raphael.js (open source, weergave van vectoren in webpagina's)
Xara (commercieel, open source en gratis versie)
Inkscape (open source en gratis)
Anders dan bij bitmapafbeeldingen die uit beeldpunten of pixels bestaan, bestaan er voor vectorafbeeldingen weinig algemeen ondersteunde opslagformaten. Het W3C heeft een internationale XML-standaard voor vectorafbeeldingen ontwikkeld onder de naam SVG (scalable vector graphics).
1Merckx, K.. Niet van gisteren, Leuven, 2013.
2RGB, (nl.wikipedia.org), geraadpleegd op 20 oktober 2014.
3 http://www.rapidtables.com/web/color/RGB_Color.htm, geraadpleegd op 4/11/2014.
Deel 3: Verwerking de logica van een digitaal systeem
In het eerste deel heb je gezien wat microcontrollers, embedded systemen en firmware zijn en wat ze doen. De elektronica slaagt erin inkomende signalen van sensoren of invoer van mensen te digitaliseren. In grotere digitale systemen zoals laptops, desktopcomputers, tablets, smartphones enz. zijn zoveel onderdelen of modules aanwezig dat er meer nodig is dan een enkelvoudige chip of controller voor de verwerking.
âAn operating systemis the level of programming that lets you do things with your computer. The operating system interacts with a computer's hardware on a basic level, transmitting your commands into language the hardware can interpret. The OS acts as a platform for all other applications on your machine. Without it, your computer would just be a paperweight.â 1
Een computer is eigenlijk niet veel meer dan een krachtige rekenmachine. Het Engelse âto computeâ betekent niet meer of minder dan âberekenenâ. Het rekent met nullen en enen en sluits die door een reeks processors (verwerkers) en circuits. In vergelijking met een microcontroller of SoC (zie deel 1) is de laptop, tablet, smartphone of desktopcomputer waarmee je werkt, vooral bedoeld als een zeer veelzijdig toestel. Je moet het voor meerdere taken kunnen inzetten. Het is geen ijverige werkmier of honingbij die voor één specifieke taak wordt ingezet. Een OS of operating system maakt het mogelijk om complexe programma's uit te voeren die gebruik maken van de aanwezige hardware. De mogelijkheden van de hardware vormen vaak de grens waar software aan gebonden is. Een operating software is over het algemeen niet geprogrammeerd in de aanwezige chips of hardware, want dan zou een operating system weinig flexibel zijn. Besturingssystemen zoals het bekende Linux, Mac OS X, Windows... verschijnen in de vorm van te installeren software.
Cool, maar wat doet zo'n besturingssysteem nu eigenlijk. Vergelijk het met de manager in een bedrijf. Een OS (vanaf nu gebruiken we gemakshalve de afkorting OS, van 'operating system' of 'besturingssysteem') bekijkt welke taken aan de gang zijn en verdeelt de middelen die hiervoor beschikbaar zijn, zoals het RAM-geheugen (het tijdelijke werkgeheugen dat wordt gewist als je het toestel uitschakelt), de benodigde opslagruimte, toegang tot randapparatuur, rekenkracht van de processor... In het ideale geval zorgt het OS ervoor dat iedereen(elke gebruiker, elk stuk software...) zijn taak naar wens kan uitvoeren en het systeem niet crasht wegens overbelast.
Een programmeur (of een groep) die een programma schrijft voor een specifieke taak, moet niet van nul beginnen. Hij beschikt reeds over een aantal in het systeem aanwezige functies of mogelijkheden. Vergelijk het naar analogie even met iemand die een huis bouwt: je moet niet zelf je bakstenen bakken, planken zagen, kalk blussen of je eigen truweel smeden. Je kan heel eenvoudig bestaande elementen inzetten om het gewenste eindresultaat te bereiken. De vergelijking loopt uiteraard mank. Maar zonder twijfel heb je die standaardfunctionaliteit bij een digitaal systeem al wel eens opgemerkt. Het OS zorgt er voor dat een softwareontwikkelaar niet rechtstreeks code moet schrijven om bepaalde invoer- of uitvoerapparaten aan te spreken of bestanden te openen of bewaren. Het OS vormt een eenvoudige laag (een interface) tussen de software en de hardware. Denk terug aan de tekening bij het einde van het eerste deel (deel 0!). De grens tussen elke laag in een digitaal systeem (in dit geval tussen de lagen âlogicâ en âioâ, en daarnaast de lagen âlogicâ en âstorageâ) vormt een interface, een grens waar beide lagen met elkaar kunnen communiceren. De interface tussen software en hardware heet de API of Application Programming Interface.
Een voorbeeldje: wanneer je onder Mac OS X een bestand wil openen, krijg je in zo wat elk programma een gelijkaardig dialoogvenster te zien, met dezelfde functionaliteit. Die mogelijkheden om bestanden te openen, te bewaren, af te drukken... worden geleverd door de API van het OS. Cool of verwarrend?
Het printdialoogvenster in LibreOffice onder Mac OS X.

Het printdialoogvenster in Voorvertoning onder Mac OS X.
De meeste programmaâs gebruiken dezelfde dialoogvenstersen bijna identieke knoppenbalken. Programmeurs maken namelijk gebruik van de apiâsdie het besturingssysteem biedt. Een API maakt het immers mogelijk om op eenvoudige wijze systeemtaken (bestanden openen, opslaan, afdrukken) uit te voeren. De programmeur schrijft bijvoorbeeld een stuk code dat het print-dialoogvenster van Windows opent.
Omdat niet alleen de processor, maar ook het besturingssysteem en de corresponderende apiâs verschillen, is het niet zonder meer mogelijk om een Windowsprogramma op pakweg een Mac OS X - of Linuxmachine te installeren en omgekeerd.
Heel wat âprogrammeursâ gebruiken een visuele IDE(Integrated Development Environment). Daarin kunnen ze grafisch aan de slag volgens het wysiwyg-principe (what you see is what you get). In zoân omgeving kan de ontwikkelaar bedieningselementen zoals vensters, knoppen, menubalken enzovoort naar zijn ontwerpvenster slepen en de nodige functionaliteit programmeren. De ontwikkelaar moet zorgen voor een gemakkelijk te bedienen gui (Graphical User Interface)zoals vensters, knoppen enz. en die bedieningselementen moet hij laten âsamenwerkenâ met achterliggende verwerkings- en opslagfuncties. Wanneer de gebruiker bijvoorbeeld op een knop drukt, leest het programma gegevens uit een databank of bestand in of kan het nieuwe gegevens opslaan. Voor Windows en Mac OS X bestaan IDEâs die standaard voorzien zijn van toegang tot de API-functies van het besturingssysteem en de standaard-gui-elementen (knoppen, vensters, menuâs). Een programmeur kan ook gebruikmaken van een platformonafhankelijke IDE, bijvoorbeeld Qt, waarin hij codes kan schrijven voor meerdere besturingssystemen. De ide neemt in dat geval de vertaalslag voor de verschillende systemen voor zijn eigen rekening. Daarnaast kan een ontwikkelaar zich ook bedienen van een widget toolkit, een widget library of gui toolkit. Zoân toolkit is een stuk software dat de programmeur de mogelijkheid biedt om vensters, menubalken, knoppen en andere gui- elementen in zijn code op te nemen. Sommige van deze toolkits (bijvoorbeeld gtk) hebben âhuiseigenâ dialoogvensters voor de gecompileerde programmaâs.
Het miniaturiseren van de computer en zijn onderdelen heeft ertoe geleid dat de computer is uitgegroeid tot een product dat vooral sinds de jaren 1990 in zowat elke huiskamer staat. Niet alleen de hardware, maar ook de programmaâs zijn een bron van inkomsten voor firmaâs. Naast commercieÌle software, waarbij de gebruiker enkel de gecompileerde versie kan kopen maar niet de originele broncode, bestaat er ook een tweede circuit, waarbij eveneens de broncodes beschikbaar worden gesteld. Deze opensourcesoftware is een doorn in het oog van veel commercieÌle softwareontwikkelaars.
Via internet werken ontwikkelaars over heel de wereld samen aan de succesvolste opensourceprogrammaâs, tegenwoordig vaak via een open softwareplatform dat speciaal is bedoeld om met groepen mensen aan dezelfde code te werken nl. GIT, zogenaamde âversie controle beheerâ -software. De gebruikers downloaden de gecompileerde versie, en installeren en gebruiken die software gratis. Ontwikkelaars duiken in de code en het is zelfs toegelaten de code voor andere doeleinden te gebruiken of er blokjes code uit te gebruiken. Zo lang ze de originele auteur maar blijven vermelden ... en dat is niet meer dan normaal, toch?
Een van de belangrijkste opensourceprojecten is gnu/Linux. Dit besturingssysteem werd als hobby ontwikkeld door Linus Thorvalds (1969) als alternatief voor Microsoft Windows. Hij gooide de basiscode van zijn systeem in 1991 op het internet. Sindsdien werken wereldwijd ontwikkelaars en bedrijven aan verbeteringen en uitbreidingen van het systeem. Om programmeurs die elkaar niet persoonlijk kennen via internet met elkaar te laten samenwerken en overlappingen te voorkomen, werden versiecontrolesystemen ontwikkeld. Dit zijn softwareprogrammaâs die het beheer van de code automatiseren en controleren. Daar de code vrij is, is het aan anderen toegestaan hun eigen versie te schrijven en publiceren. Linux wordt vooral op internetservers en door kenners gebruikt. Sinds de jaren negentig van de 20e eeuw beheerst het besturingssysteem Windows van Microsoft de markt van de âpersonal computersâ. Microsoft sluit hiervoor overeenkomsten met producenten en leveranciers, zodat nieuwe computers steevast geleverd worden met een installatie van Windows.
Een alternatief voor Windows is de Applecomputer, met het Mac OS-besturingssysteem. Daarnaast bestaan er nog tal van kleine besturingssystemen, vaak hobbyprojecten van individuele ontwikkelaars of âcommunityâsâ (groepen van ontwikkelaars die zich organiseren via internet), en professionele systemen op basis van UNIX, een besturingssysteem dat het levenslicht zag in Bell Labs (Bell Telephone Laboratories) in 1969. Een besturingssysteem is in werkelijkheid een stuk software dat bij het starten van de computer in het geheugen wordt geladen. Hierdoor kunnen andere programmaâs die voor dat systeem zijn geschreven op een afgesproken manier bepaalde functies van de computer aanspreken en gebruiken. Om dit mogelijk te maken bevat het systeem zogenaamde apiâs (application programming interface) of door het systeem vastgelegde codes of functies die je vanuit je eigen code kunt oproepen.
Klassieke âdesktopprogrammaâsâ bestaan vaak uit duizenden, zo niet honderdduizenden regels code. Voordat die code door een computer uitgevoerd kan worden, moet ze â zoals eerder werd gezegd â worden gecompileerd. Dit wil zeggen dat de code door een stuk software (de compiler) in machinetaal (nullen en enen) wordt omgezet. De gecompileerde code kan rechtstreeks door de processor worden uitgevoerd.
Het succes van GSM's en later smartphones en tablets deed de nood ontstaan aan mobiele compacte besturingssystemen. Het is een zeer veranderlijke wereld. Mobiele b esturingssystemenverdwijnen al even snel van de markt als de repsectieve merken die ze gebruiken. Een populaire systemen zoals Symbian, Windows Mobile, Palm OS, webOS, Maemo, MeeGo, LiMo⦠worden niet langer ontwikkeld. Op dit moment zijn Android, Apple iOS, Windows Phone, BlackBerry, Firefox OS, Sailfish OS, Tizen en Ubuntu Touch OS in gebruik. Mobiele toestellen met Android overheersen op dit moment (anno 2015) de markt. Android is een open source besturingssysteem ontwikkeld door Google Inc. op basis van de Linux-kernel. De open source-licentie heeft ertoe geleid dat ook andere fabrikanten het OS inzetten op hun toestellen. Google bundelt Android met een reeks closed source-applicaties zoals Google Play, Google Music, Google Search⦠2
Interesse in de geschiedenis van Operating Systems? Dan vormen de volgende pagina's een leuke intro:

http://www.linux-netbook.com/linux/timeline/
Bron: http://www.linuxfoundation.org/news-media/infographics/memorable-linux-milestones
3
 Je doet het natuurlijk niet, want als je een computer koopt in een standaard computerwinkel of mediaketen, koop je het toestel met een kant-en-klaar geïnstalleerd besturingssysteem. Een PC of laptop komt met Windows, een Applecomputer met Mac OS X. Bij tablets of smartphones stellen we ons nog minder vragen: een iPad of iPhone komt met iOS, een andere tablet of smartphone met Android of Windows. Als je een desktopcomputer zelf samenstelt, moet je het besturingssysteem zelf nog installeren. Toch toont zo'n OS-loze computer ook de nodige output als je hem opstart. Je kent het heus wel van op een Windowstoestel. Bij het opstarten kan je één of andere functietoets indrukken om in een setup- of bootscherm terecht te komen. Hetzelfde geldt wanneer je voor de eerste keer een Raspberry Pi aan je televisiescherm koppelt. Wat je op dat moment te zien krijgt is de
firmware. De firmware is een interface die zich als een dun schilletje over de hardware heen legt. Het vormt dus geen onderdeel van het besturingsysteem zelf. Het doel van dit firmwareprogramma is te controleren of alles ok is met de hardware. Zo'n beetje als de conciërge van een winkel of school die 's morgens de deuren opent en alles nog eens controleert om te zien of zich nergens problemen hebben voorgedaan.
Op die manier controleert de firmware of de processor, het geheugen, de schijfstations en poorten geen fouten vertonen.
Op een Mac heet deze firmware UEFI (Unified Extensible Firmware Interface)
4
, op een Windowstoestel sprak men tot voor kort steevast over het BIOS (Basic Input Output System)
5
.
Je doet het natuurlijk niet, want als je een computer koopt in een standaard computerwinkel of mediaketen, koop je het toestel met een kant-en-klaar geïnstalleerd besturingssysteem. Een PC of laptop komt met Windows, een Applecomputer met Mac OS X. Bij tablets of smartphones stellen we ons nog minder vragen: een iPad of iPhone komt met iOS, een andere tablet of smartphone met Android of Windows. Als je een desktopcomputer zelf samenstelt, moet je het besturingssysteem zelf nog installeren. Toch toont zo'n OS-loze computer ook de nodige output als je hem opstart. Je kent het heus wel van op een Windowstoestel. Bij het opstarten kan je één of andere functietoets indrukken om in een setup- of bootscherm terecht te komen. Hetzelfde geldt wanneer je voor de eerste keer een Raspberry Pi aan je televisiescherm koppelt. Wat je op dat moment te zien krijgt is de
firmware. De firmware is een interface die zich als een dun schilletje over de hardware heen legt. Het vormt dus geen onderdeel van het besturingsysteem zelf. Het doel van dit firmwareprogramma is te controleren of alles ok is met de hardware. Zo'n beetje als de conciërge van een winkel of school die 's morgens de deuren opent en alles nog eens controleert om te zien of zich nergens problemen hebben voorgedaan.
Op die manier controleert de firmware of de processor, het geheugen, de schijfstations en poorten geen fouten vertonen.
Op een Mac heet deze firmware UEFI (Unified Extensible Firmware Interface)
4
, op een Windowstoestel sprak men tot voor kort steevast over het BIOS (Basic Input Output System)
5
.
Na de firmware laat standaard de bootloaderdie op zoek gaat naar beschikbare besturingssystemen (op de harde schijf, in een schijfstation, op een USB-stick). Op de meeste systemen is slechts één besturingssysteem aanwezig, vindt de bootloader er meerdere dan laat hij de gebruiker de keuze welk systeem hij wil opstarten.
Software? Over software valt heel wat te zeggen. Software bestaat in maten en gewichten: van dure professionele pakketten tot al even professionele open source software waarvoor je niets hoeft de betalen. In Deel 6 bekijken we software vanuit multimediaperspectief. We gebruiken software voor het verwerken en bewerken van tekst, drukwerk, beelden, film, animatie, 3D, audio...
Meer en meer software werkt online of maakt op zijn minst de combinatie tussen offline en online mogelijkheden. Meer en meer zien commerciële bedrijven hun software niet als een te verkopen afgewerkt product, maar als dienstverlening ( SaaS= software as a service). De software staat in de âcloudâ en kan, mits je over de juiste licentie beschikt (en voldoende betaalt), van waar ook gebruikt worden.
Heel wat softwaretoepassingen draaien volledig op het web: Gmail, Google Docs, Facebook enz. zijn enkele van die veelgebruikte online services. Die dienstverlening kan tegen betaling gebeuren of volkomen âgratisâ zijn. De producent/leverancier haalt zijn inkomsten uit reclame die vaak op basis van de inhouden van de gebruiker gegenereerd worden.
Die evolutie naar het zien van software als het leveren van een dienst is overal aanwezig. Weinig eindgebruikers zijn nog bereid om een paar duizend euro (of zelfs een paar tientallen euro) te betalen voor één licentie op een bepaald softwareproduct. Die evolutie kent vermoedelijke meerdere oorzaken:
De groei van het internet en de toegenomen snelheid door snelle verbindingen.
De kracht van open source software: Waarom betalen als je even goed kan werken met een gratis product?
Software die als âproductâ werd verkocht op bijvoorbeeld een CD-rom kon gemakkelijk gekopieerd worden. Software die je via een âhuiseigenâ installatieprogramma op je computer plaatst en bij elk gebruik de licentiegegevens online controleert, is veel minder makkelijk te kopiëren.
Lang niet iedereen heeft alle functionaliteit nodig. Veel gebruikers zijn tevreden met kleine apps met een welbepaalde mogelijkheid. Kijk maar naar het succes van de appstores van Apple en Google.
1How Mac OS X Works, ( http://computer.howstuffworks.com/macs/mac-os-x1.htm), geraadpleegd op 1 september 2015.
2"Mobile operating system", (https://en.wikipedia.org/wiki/Mobile_operating_system#World-Wide_Share_or_Shipments), Geraadpleegd op 8 september 2015.
3( http://www.linuxfoundation.org/news-media/infographics/memorable-linux-milestones), Gedownload op 1 september 2015.
4UEFI, ( https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface#/media/File:Efi-simple.svg), gedownload op 1 september 2015.
5UEFI boot: how does that actually work, then? ( https://www.happyassassin.net/2014/01/25/uefi-boot-how-does-that-actually-work-then/), geraadpleegd op 1 september 2015.
Voor de meeste mensen hangt er een waas van mysterie en magie rond software en hardware. Het lijkt allemaal ontzettend ingewikkeld. Een leek die voor het eerst de achterliggende programma-instructies bekijkt, voelt zijn hoofd duizelen. Een programma betekent letterlijk een âprogrammaâ, in de simpelste vorm een reeks instructies die je na elkaar moet voltooien. Je kan niet zonder meer de volgorde veranderen, net zoals je bij een recept een reeks instructies na elkaar moet volgen om het gewenste eindresultaat te bereiken. Anders zal je pudding of chocoladecake er niet zo netjes uitzien en wellicht ook niet eetbaar zijn. Een computerprogramma gaat vaak verder dan een simpele reeks instructies. Het stuk hardware (computer, microcontroller, smartphone...) moet het programma zelfstandig (eventueel met interactie van de gebruiker) kunnen afhandelen. Het programma staat er alleen voor. Pudding zal niet protesteren alsde kinderen met hun lepels pudding naar elkaar beginnen gooien. Maar hardware is nu eenmaal niet zo âintelligentâ als een kind, het beseft niet altijd wat gebruikers beginnen doen. Misschien doet de gebruiker wel dingen die de programmeur niet bedoeld heeft. Daarom moet de programmeur rekening houden met (bijna alle) denkbare â wat alsâ-scenario's.
Menselijke talen zijn veel te complex om dienst te doen als programmeertaal. Programmeertalen moeten zo zijn opgebouwd dat elke instructie maar één ding kan betekenen. Het is voor een computer âzusâ (0 of 1) of âzoâ (1 of 0). Je weet wel: binaire code. Dit komt omdat de huidige computersystemen niet meer zijn dan een gigantisch grote hoeveelheid schakelaars. Zo'n beetje zoals de schakelaar waarmee je het licht aan en uit schakelt, maar dan vele malen kleiner.
 Nullen en enen in een matrix om een afbeelding te tekenen (javascriptcode).
Nullen en enen in een matrix om een afbeelding te tekenen (javascriptcode).
Omdat het omgekeerd voor een mens behoorlijk moeilijk is om pakweg tien miljoen schakelaars te bedienen enkel door een reeks nullen en enen in te tikken, zijn er oplossingen bedacht in de vorm van programmeertalen. Een programmeertaalbevat wel woorden uit menselijke talen (meestal uit het Engels), waardoor ze bevattelijk wordt. Meestal gaat het om korte instructies, mnemotechnische hulpmiddelen, symbolen, operatoren of logische schakelingen zoals and, or, if, else, end, print... Omdat die taal niet uit binaire code (nullen en enen) bestaat, is ze voor computers niet begrijpelijk.

Een compileris een speciaal stukje software (weer een programma) dat de in een programmeertaal geschreven instructies omzet in binaire code of machinetaal. Zo blijft de code voor de programmeur leesbaar en kunnen de instructies nadien ook weer aangepast worden. Na elke aanpassing aan de code moet het programma weliswaar opnieuw worden gecompileerd.
Omdat het programmeren in dit soort assembleertaaltoch nog heel wat inzicht vroeg, zijn later de zogenaamde âhogere programmeertalenâ en âscriptingtalenâ ontwikkeld. Ze staan een stuk dichter bij de menselijke taal en zijn hierdoor eenvoudiger te leren. In de loop der jaren (en nog steeds) zijn er honderden verschillende programmeertalen bedacht, vaak met een specifiek doel voor ogen. Elke programmeertaal moet echter op één of andere manier âverwerktâ worden vooraleer het een bruikbaar programma is.
In de programmeertaal Processing tovert de instructie ellipse(20, 20, 20, 10); een cirkel op het scherm. Het middelpunt van de cirkel ligt op pixel 20 van de x-as en pixel 20 van de y-as te rekenen vanuit de linkerbovenhoek van het uiteindelijke programma (dus niet vanuit de rechterbenedenhoek zoals bij een grafiek in bijvoorbeeld MS Excel). De cirkel is 20 pixels breed en 10 pixels hoog... geen echte cirkel dus, maar een ellips.
Voor het bouwen van gebruiksvriendelijke programmaâs met een aangename interface zijn heel visuele programmeeromgevingengebouwd, waarbij je de code niet altijd meer moet kennen. Zo sleep je bij de programmeeromgeving voor de Lego® Mindstorms-robots de code in visuele blokjes bij elkaar op een computerscherm.
De manier waarop computers programmeercode verwerken kan verschillen:
|
Soort verwerking |
Uitleg |
Voorbeelden van software |
|
Compilers |
De meeste programma's worden gecompileerd . Een âcompilerâ is een stuk software dat de codes vertaalt naar nullen en enen. Omdat niet elk besturingssysteem en/of processor op dezelfde manier met nullen en enen omgaat, heb je voor elk benodigd platform een andere compiler nodig. Er bestaan niet voor alle programmeertalen compilers voor alle platformen. Microsoft bouwt voor zijn programmeertalen geen compilers voor pakweg Linux of Mac OS X. Een compiler maakt het werk van de programmeur dus niet op alle vlakken eenvoudiger. Hij moet bezinnen voor hij begint! Gecompileerde software is zeer snel omdat het eindresultaat uit nullen en enen bestaat, de taal van de processor zelf. De code is echter niet meer leesbaar, tenzij de programmeur de code ook publiceert (zoals bij open source het geval is). |
Besturingssystemen zoals Windows, Mac OS X, Linux, MS Office, OpenOffice... |
|
Interpreters |
Soms is een stuk code erg beperkt en kan die worden gecompileerd wanneer de gebruiker het programma opent. De code wordt op dat moment âgeïnterpreteerdâ, simultaan vertaald naar processorinstructies en uitgevoerd. De bekendste interpretertaal is javascript. Een webontwikkelaar kan javascript-code in zijn webpagina's opslaan. Wanneer de browser van een websitebezoeker de pagina opent, wordt de leesbare code door de browser âgeïnterpreteerdâ en (interactief) uitgevoerd. Een browser (Safari, Chrome, Internet Explorer, Opera, Firefox...) beschikt zo goed als altijd over een âjavascript-engineâ die de code in webpagina's kan interpreteren en uitvoeren. Vermits je enkel een âbrowserâ nodig hebt om het programma uit te voeren, werkt javascript doorgaans op alle platformen en systemen waarvoor een browser bestaat. |
Javascript in webpagina's, javascriptbibliotheken zoals jQuery... |
|
bytecode |
Bytecode bevindt zich ergens tussen compilers en interpreters in... Het lijkt een beetje op âinterpreterâsoftware omdat de code niet volledig wordt gecompileerd. Het heeft een extern programma nodig om âgestartâ te kunnen worden. Toch verschillen bytecode-programma's van scriptingtalen zoals javascript omdat de code gedeeltelijk wordt gecompileerd naar een tussenliggende taal, âbytecodeâ. Java is een bekend voorbeeld. Om Java-programma's te starten, heb je een âruntime environmentâ nodig. Zo'n runtime environment moet je eerst op je computersysteem of hardware installeren. Wanneer je het java-programma start, wordt op de achtergrond de âruntime environmentâ (de zogenaamde JRE) gestart. Wanneer de programmeur klaar is met de code, moet hij die exporteren. De code wordt op dat moment vertaald naar âbytecodeâ (geen nullen en enen) die door de âruntime environmentâ wordt uitgevoerd. Het grote voordeel is dat de programmeur slechts één keer code moet schrijven voor alle platformen. Java-programma's werken op alle platformen waarvoor een JRE bestaat, Flash werkt op alle platformen waarvoor een Flashplayer bestaat. Bytecode-programma's zijn wel trager dan gecompileerde programma's. |
Java (jar-bestanden) en de Java Runtime Environment Flash (swf-bestanden) met als âuitvoerprogramma's: de Flashplayer (voor browsers) en Adobe Air (voor desktopomgevingen). |
Vergelijk een programma of applicatie met een auto. De buitenkant van de auto en vooral het dashboard, stuur, pedalen, handrem, versnellingspook vormen de interface, waarmee de chauffeur de auto bestuurt. Onder de motorkap zit de motor die reageert op de acties van de chauffeur. Een programmeertaal zelf is nog geen motor en al zeker geen auto. Met een programmeertaal beschik je wel over een manier en de onderdelen om een auto met motor te bouwen. De programmeur is tegelijk de ingenieur en de monteur die de motor ontwikkelt en bouwt. Niet alle programmeurs zijn daarin even bedreven. Daarom heb je soms een uitzonderlijk goed programma op het vlak van functionaliteit, maar een vreselijke bedieningsinterface. Ook het omgekeerde kan het geval zijn. Uiteraard werken programmeurs niet altijd in hun eentje.
Een programma komt pas tot leven als het reageert op de gebruiker. Een programma zonder gebruikersinteractie lijkt op een auto zonder stuur. Je kan een programma dingen laten doen met of zonder interactie met de gebruiker. Maar natuurlijk wordt het pas echt leuk wanneer de gebruiker merkt dat het programma op zijn acties reageert. Je zou als gebruiker immers al snel denken dat er iets fout loopt als het programma zo maar wat dingen doet (of niet doet).
De analogie met een auto zal het hopelijk allemaal wat duidelijker maken:

In een auto zit een motor en die motor bestaat op zijn beurt uit een hoop kleinere modules. Er zit een carburator, een pomp, cilinders, een radiator, waterpomp enz. in. Uiteraard is zo'n motor alleen niet voldoende. De gebruiker kan de motor en alle onderdelen hiervan interactief besturen. Wanneer hij aan de sleutel draait, start de motor. Als de bestuurder het ontkoppelingspedaal indrukt, de versnellingsbak in de juiste versnelling plaatst en vervolgens het pedaal zachtjes loslaat, komt de auto in beweging. De pedalen, sleutel, versnellingen... zijn interface-elementen die er voor zorgen dat de gebruiker interactief de motor kan aansturen. Het resultaat is dat de auto in beweging komt, de ruitenwissers beginnen bewegen, de lichten kunnen worden aangezet enz. Tussen die interface-elementen en de onderdelen van de motor liggen verbindingen, kabels, slangen enz. die ervoor zorgen dat alles netjes wordt aangestuurd.
|
Programma |
auto |
|
Bedieningsinterface |
dashboard, pedalen, hendels... |
|
Methodes |
rijden, stoppen... |
|
Functies |
de motor die zorgt voor de aandrijving, de ruitenwissers (regenwater wegwissen), de waterpomp, de remmen... |
Methodes horen dus bij het object âautoâ. Functies staan daar los van. Meerdere objecten kunnen dezelfde functies delen. Het verschil zorgt vaak voor verwarring en je kan er inderdaad uren over discussiëren. Een methode hoort dus bij een âobjectâ. Een functie staat los van het object.
We testen het nu zelf eens uit in de programmeertaal Processing. Eerst moet je Processing ( www.processing.org) downloaden en installeren. Kies de juiste versie. Tijdens de les demonstreren we hoe je de IDE installeert en start.
Processing maakt het makkelijker door enkel te spreken over functies en niet het verschil te maken tussen methodes en functies. In de setup()-functie bepaal je hoofdzakelijk het âuitzichtâ van je programma zoals de breedte, de hoogte, de achtergrondkleur...
De draw()-functie is een soort container waarin wordt bepaald wat het programma moet tonen aan de gebruiker (bijvoorbeeld het webcambeeld, een tekening, een foto...).
void setup() { //algemene instellingen van het programma } void draw() { //wat moet er gebeuren? }
Het onderstaande Processing-voorbeeld tekent een witte cirkel van 300 pixels breed en hoog in het midden van een zwart "canvas" van 400 pixels breed en hoog.
void setup(){
size(400, 400);
background(0);
stroke(255);
ellipse(200, 200, 300, 300);
} Zowel size(), background(), stroke() als ellipse() zijn ingebouwde functies in Processing. Processing weet meteen wat hij moet doen als je zo'n functie oproept. Je kan ook parameters toevoegen. Denk nog eens even terug aan de auto. De knop zet de ruitenwissers in beweging, maar door aan het hendeltje te draaien, kan je de ruitenwissers sneller of trager of met een interval laten bewegen. Je kan dus aan een dezelfde âmotorâ meerdere parameters doorgeven. Zo gaat het ook in Processing. Als je geen parameters doorgeeft aan een bepaalde motor... excuseer, functie... dan valt Processing terug op een standaardinstelling. Uiteraard moet je goed weten hoeveel parameters elke functie kan ontvangen. Het heeft immers geen zin (en het zou enkel tot foutmeldingen leiden) als je zo maar wat parameters begint in te voeren. De parameters plaats je tussen de haakjes.
Bijvoorbeeld:
size(400, 400);De twee getallen geven aan hoe breed en hoe hoog (in pixels uitgedrukt) het uiteindelijke programma moet weergegeven worden.
De regel
ellipse(200, 200, 300, 300); vertelt Processing dat hij een ellips van 300 pixels bij 300 pixels moet tekenen met zijn middelpunt op pixel x=200 en y=200. Bij een programma van 400 bij 400 pixels, staat de ellips precies in het midden. Je merkt dus ook dat de volgorde van de parameters wel degelijk van belang is in een Processing-sketch.
Denk aan een auto, een Mercedes bijvoorbeeld. Daarbinnen heb je verschillende soorten die steevast een klasse worden genoemd, bijvoorbeeld de Mercedes C-klasse. Mensen herkennen andere mensen, dieren, koeien, weides, huizen, straten, auto's enz. In een programmeertaal zouden we dit geen âobjectâ noemen, maar een klasse. Ook voor mensen zijn dit niet meteen zelfstandige objecten, we noemen dit âsoortnamenâ. Auto's zijn dus een klasse, maar jouw eigen auto beschouw je wel als een âobjectâ. Het verschil tussen objecten en klassen zit in de meeste moderne programmeertalen. Wat je er mee doet?
Hieronder vind je een voorbeeld in javascript, de scriptingtaal (dus niet echt een programmeertaal: zie 2.2.2), die vooral bekend en populair is als de interactieve taal achter webpagina's. We bouwen een functie met de naam KindMaken, die natuurlijk niet echt doet wat ze belooft, maar we bouwen er wel een âdenkbeeldig virtueelâ kind mee. Niet dat er plots een kind op je computerscherm verschijnt. Elk kind heeft een aantal âparametersâ, in het onderstaande geval een voornaam, familienaam, leeftijd, oogkleur, geslacht. Je kan het nog uitbreiden. Misschien raar om ook de leeftijd als parameter door te geven, want een pasgeboren kind is nog maar een paar ogenblikken oud. Denk echter naar analogie aan een game, die je moet bevolken met virtuele mensen (objecten). In zo'n geval is het wel belangrijk om de leeftijd te kunnen instellen.
Om het enigszins te verduidelijken staan de âzelfbedachteâ woorden in het Nederlands, de ingebouwde woorden in het Engels. Met ingebouwde woorden bedoelen we in dit geval gereserveerde woorden die je niet zelf voor andere zaken kan gebruiken. Je kan dus niet de functieaanroep âalertâ vervangen door bijvoorbeeld âgilâ. Uiteraard verplicht niemand jou om Nederlands te gebruiken. De meeste programmeurs en ontwikkelaars schrijven alles in het Engels.
var KindMaken = function (Voornaam, Familienaam, Leeftijd, Oogkleur, Geslacht) {
this.voornaam = Voornaam;
this.familienaam = Familienaam;
this.leeftijd = Leeftijd;
this.oogkleur = Oogkleur;
this.geslacht= Geslacht;
}
var papa= new KindMaken("Jan", "Peeters", "50", "blauw", "m");
var mama= new KindMaken("An", "Filips", "48", "groen", "v");
alert(papa.voornaam + " en " + mama.voornaam + " gaan trouwen.");
De afkorting var staat voor âvariabele waarde. In dit geval zijn mama en papa twee variabelen en de functie (motor) kindmaken is dat ook, want je hebt die functie ook zelf gedefinieerd. Als je het bovenstaande stuk code kopieert en in een teksteditor (vb. Kladblok, zeker niet in een tekstverwerker) plakt en je bewaart het vervolgens als test.html. Dan kan je het eindresultaat bekijken in een webbrowser.
 Probeer de code ook eens aan te passen. Je computer zal niet crashen als je een fout maakt. Al spelend leer je. Zo gaat het ook tijdens het programmeren of scripten.
Probeer de code ook eens aan te passen. Je computer zal niet crashen als je een fout maakt. Al spelend leer je. Zo gaat het ook tijdens het programmeren of scripten.
Tja, misschien toch wel een beetje moeilijk voor een beginner. Programmeertalen zijn niet eenvoudig om te leren. Meer dan in menselijke taal zijn ze heel strikt gebonden aan regeltjes. Een fout stukje spelling of spraakkunst en ⦠oeps, het werkt niet zoals je wil of zelfs helemaal niet. Je bent trouwens niet de enige die programmeren moeilijk vindt. Jef Raskin die in een grijs verleden de interface van de Apple Macintosh-computer ontwierp, schrijft:
âThere is no question that modern systems are becoming increasingly complex and that programming tools need to accommodate this increasing complexity. Simple things have been made unnecessarily difficult, and we have failed to provide sufficient and sufficiently well-designed software tools needed to ease the difficulties of working in today's computer environmentâ. 1
Maar als je toch echt even wil proberen, kan het ook met mijn hobbyproject SIRK dat je vindt op
www.ardeco.be/sirk. De bedoeling van SIRK was om het programmeren een stapje dichter bij menselijke taal te brengen. Bovendien zijn de Engelse gereserveerde woorden hier vervangen door Nederlandstalige woorden met de bedoeling de indruk te wekken dat je kan programmeren in je eigen taal.
Stel dat je het getal 5 op je computerscherm wil weergeven (niet meteen hoogstaande kunst. Je zou denken: âIk open MS Word en tik gewoon 5.â), dan is dit voor een programmeertaal een variabel gegeven. In plaats van de afkorting âvarâ gebruiken we binnen SIRK, gewoon zoals in mensentaal, de bepaalde lidwoorden âdeâ en âhetâ. Onze bedoeling is nu âhet getal 5 afdrukken op het scherm.âWe maken met SIRK dus eerst een getal aan met de waarde 5. We laten het onthouden door de computer (bewaar, store...). Zo kunnen we het later op elk gewenst moment op ons scherm afdrukken (GEBRUIKEN of @ en OP_HET_SCHERM of print).
het getal
5 getal bewaar
getal GEBRUIKEN OP_HET_SCHERM We zouden het ook op de volgende manier kunnen schrijven:
var number
5 number store
number @ print Op www.ardeco.be/sirkvind je nog een boel leukere voorbeelden. Probeer bijvoorbeeld de spelletjes eens uit of de tekenvoorbeelden.
In het echte leven hangt veel wat we doen af van de omstandigheden. Als het regent, open je een paraplu bijvoorbeeld. Doe je dit wanneer de zon schijnt, dan word je raar bekeken.
In de meest eenvoudige vorm (0 of 1) kent een eenvoudig programma twee toestanden. Naar analogie gebruiken we de volgende situatie:
Om zulke condities te testen, gebruiken heel wat programmeertalen een if-else-conditie. Soms werkt dit zelfs letterlijk voor âregenâ. Bij een aantal auto's werken de ruitenwissers bijvoorbeeld als een sensor âregenâ op de ruit âvoeltâ.
In âpseudocodeâ zouden we dit zo kunnen uittekenen:
var regen= testRegensensor();
if(regen==1){
Ruitenwissers(1);
}else{
Ruitenwissers(0);
} Naast eenvoudige if/else-condities kan je ook gebruik maken van (beperkte) herhalingen (loop). Zoals bijvoorbeeld "beweeg 10 keer van links naar rechts op het scherm" of "teken 5 vierkanten met een willekeurige kleur op het scherm".
de xpositie
de ypositie
20 xpositie bewaar
20 ypositie bewaar
de breedte
20 breedte bewaar
de hoogte
20 hoogte bewaar
[
xpositie gebruiken 40 + xpositie bewaar
ypositie gebruiken 40 + ypositie bewaar
kleur xpositie gebruiken ypositie gebruiken hoogte gebruiken breedte gebruiken vierkant
] 5 keer Denk maar eens goed na waarvoor â40+â dient in de bovenstaande code.

1 RASKIN, J., The Humane Interface, New Directions for Designing Interactive Systems, Boston, 2010, 192-193.
Ongetwijfeld heb je het woord al eens gehoord: een algoritme. Het heeft niks met ritmische muziek te maken alhoewel Shazam wel algoritmes gebruikt voor patroonherkenning in muziek. Google gebrukt het PageRank-zoekalgoritme en wanneer je naar een MP3-muziekbestand luistert dan is dit eerst met een compressie-algoritme tot een relatief klein bestand herleid vooraleer het op je mediaspeler is beland. Algoritmes spelen een cruciale rol in de verwerking van big data. Algoritmes zijn in de digitale wereld alomtegenwoordig, maar wat zijn het eigenlijk? Een nette verklaring van het begrip vinden we op Wikipedia:
â(een algoritme) is een eindige reeks instructiesdie vanuit een gegeven begintoestandnaar een beoogd doelleiden. Algoritmen staan in beginsel los van computerprogramma's, al worden voor de uitvoering van algoritmen vaak computers gebruikt. Het doel van een algoritme kan van alles zijn met een duidelijk resultaat. De instructies kunnen in het algemeen omgaan met eventualiteiten die bij het uitvoeren kunnen optreden. Algoritmen hebben in het algemeen stappen die zich herhalen (iteratie) of die beslissingen (logica of vergelijkingen) vereisen om de taak te voltooien.â 1
In wezen gaat het om een stappenplan waarvan je weet dat je tot een bepaald resultaat zal leiden. Het gaat dus verder dan lukraak proberen een bepaald resultaat te bereiken. Je weet heel goed welke stappen je na elkaar moet zetten om tot een resultaat te komen. Op school leer je bijvoorbeeld woordjes alfabetisch rangschikken. Dat doe je in eerste instantie door naar de eerste letter te kijken. Bevatten veel woorden dezelfde beginletters, dan rangschik je die woorden door naar de tweede letter en vervolgens naar de volgende letters te kijken. Rangschikking vereist dus een algoritme, een strikt stappenplan om tot het beoogde eindresultaat (een alfabetische volgorde) te bereiken. Algoritmes blijven dus niet beperkt tot computerwetenschappen, maar je vindt ze al een âeeuwigheidâ terug in de wiskunde. In het tweede millennium voor Chr. gebruikten de Babyloniërs algoritmes voor het berekenen van machten en vierkantswortels.
Het alfabetisch rangschikken van woorden en het ordenen volgens grootte van getallen lijkt voor ons erg makkelijk. Maar het vraagt wel een stappenplan in ons hoofd, ook al doe je het na een tijdje zonder na te denken. Hoe beter het algoritme, hoe sneller de procedure. Dit soort algoritmes wordt reeds van in de beginjaren van de computer gebruikt in de computerwetenschappen. John von Neumann bedacht het âsort mergeâ-algoritme in de 1945. Het sorteert gegevens door het splitsen, ordenen en weer samenvoegen (merge) van data. Tony Hoare bedacht in 1959 het Quicksort-algoritme, dat zoals de naam al doet vermoeden, sneller werkt dan âsort mergeâ. 2 In 1964 bedacht J.W.J. Williams het âheapsortâ-sorteeralgoritme. 3
Zonder dit soort âsorteeralgoritmesâ zouden heel wat moderne computertechnieken zoals data mining, AI, linkanalyse... ondenkbaar zijn.
De het Fourier-transformatie-algoritme en de Fast Fourier-transformatie of het FFT-algoritme liggen aan de basis van heel wat compressie-algoritmen zoals JPG en MP3. Een Fourier-tansformatie zet een geluidssignaal of lichtintensiteit om in een golffunctie. Het internet, WiFi, een smartphone, computer, router, communicatiesatellieten enz., zo wat alle toestellen waarin een soort computer aanwezig is, gebruikt het deze algoritmen. Het meet analoge signalen doorheen de tijd en tekent die uit als een golf op basis van de gemeten frequenties. Door signalen op te zetten in (golf)functies, kan de intensiteit van de golf eveneens getransformeerd (vervormd) worden. Het FFT-algoritme wordt bijvoorbeed gebruikt bij afbeeldingsfilters waarbij men de intensiteit van kleuren of belichting 'transformeert'. Bij compressie worden lage intensiteitsverschillen weggegooid waardoor de bestandsgrootte erg verkleind.
"Fourier-transformaties worden gebruikt bij het omzetten van analoge signalen in digitale data en worden onder meer toegepast bij signaalverwerking, maar spelen ook een rol bij de compressie van beelden. Een complex signaal wordt met fft gereduceerd tot een aantal eenvoudig digitaal te representeren componenten. Daarvoor wordt een analoog sample opgedeeld in kleine stukjes, waarna de stukjes worden geanalyseerd en geconverteerd naar een digitaal signaal." 4
Compressie-algoritmes spelen een bijzonder belangrijke rol. Ze zorgen ervoor dat data kleiner worden, maar vaak gaat dit gepaard met kwaliteitsverlies. De algoritmes maken een afweging tussen kwaliteit en kwantiteit. In 3.2.5 (Compressie) leerde je al meer over de belangrijkste compressie-algoritmes voor afbeelding. In deel 6.2.7 (Codecs en containers) lees je meer over compressie van film.
Het klinkt in de eerste plaats al indrukwekkend, het â Proportional Integral Derivative Algorithmâ maar wat het doet is al even tot de verbeelding sprekend. Een PID-controllerberekent constant foutwaardes als het verschil tussen de gemeten signaalwaarde en het gewenste resultaat en werkt vervolgens de fout weg. PID-controllers worden in de industrie toegepast, maar ook in meer populaire toepassingen. Zangers zingen in een opnamestudio niet altijd netjes op de toon, doorheen een zangpartij zitten ze vaak wel eens net boven of net onder de juiste toon. Dat wil nog niet zeggen dat ze ronduit vals zingen, maar ze zitten zelden loepzuiver op de toon. Autotuningzorgt ervoor dat al die foutjes verdwijnen in de uiteindelijke gemixte opname. Het lied âBelieveâ van de zangeres Cher zou de eerste popsong zijn die van autotuning gebruik heeft gemaakt. Je merkt meteen het verschil als je naar opnames uit de jaren 1960 of 1970 luistert en die vergelijkt met opnames uit de digitale periode vanaf 1984. Beluister bijvoorbeeld eens het album âCommuniqueâ van Dire Straits en het loepzuivere digitale geluid van âBrothers in Armsâ van diezelfde groep. Niet dat we Dire Straits en Mark Knopfler âverdenkenâ van autotuning, maar de digitaliseringsalgoritmes hebben een blijvende âstempelâ gedrukt op alle opnames vanaf de komst van de CD.
Het Dijkstra-algoritme is vooral bekend als het kortste pad-algoritme. Het beschrijft de kortste afstand tussen twee punten.
âHet algoritme van Dijkstra wordt gebruikt door verschillende internetprotocollen, voor het vinden van de kortste route tussen computers of routers. Het algoritme van Dijkstra geeft gegarandeerd het kortste pad, als er überhaupt een pad tussen A en B bestaat, maar kan hier wel lang over doen. De snelheid van het algoritme is afhankelijk van de manier waarop de punten en lijnen opgeslagen zijn in het geheugen van de computer.â 5
Welke links bovenaan verschijnen in Googleszoekresultaten wordt bepaald door het PageRank-algoritme. Facebooktoont bij iedere gebruiker een andere newsfeedgebaseerd op de âvriendenâ met wie je het meest contact hebt (op Facebook dan toch), berichten die de meeste âlikesâ hebben gekregen enz. Wat je te zien krijgt, hangt dus af van een heleboel factoren en wordt bepaald door een linkanalyse-algoritme. Uiteraard verschillen de algoritmen maar de basis voor linkanalyse werd gelegd in 1976 door Gabriel Pinski en Francis Narin.
âWho uses this algorithm? Google in its Page Rank, Facebook when it shows you your news feed (this is the reason why Facebook news feed is not an algorithm but the result of one), Google+ and Facebook friend suggestion, LinkedIn suggestions for jobs and contacts, Netflix and Hulu for movies, YouTube for videos, etc. Each one has a different objective and different parameters, but the math behind each remains the same.
Finally, Iâd like to say that even thought it seems like Google was the first company to work with this type of algorithms, in 1996 (two years before Google) a little search engine called âRankDexâ , founded by Robin Li, was already using this idea for page ranking. Finally Massimo Marchiori, the founder of âHyperSearchâ, used an algorithm of page rank based on the relations between single pages. (The two founders are mentioned in the patents of Google).â 6
Wanneer je op twee verschillende computers van twee verschillende âmensenâ dezelfde zoekterm invoert in Google krijg je vaak andere zoekresultaten. Googles PageRank baseert de zoekresultaten immers ook op uw zoekgeschiedenis en toont op basis daarvan ook andere advertenties via het Google Adwords-algoritme. Wanneer je een zoekterm begint in te voeren toont Google Suggest reeds een reeks mogelijkheden waaruit je een optie kan selecteren. Ook iTunes, Amazon en Netflix tonen op basis van uw zoekgeschiedenis en aankopen andere producten die u wellicht interesseren. Eli Pariser noemt dit âinformatie determinismeâ. De gebruiker zit in een soort van âfilter bubbelâ waar hij zelf voor een deel de controle over verliest. Je kan dus niet zelf meer kiezen wat je te zien krijgt, algoritmes bepalen dit voor u. Vraag is of je, puur uit marketingoogpunt, op die manier geen potentiële kopers van bepaalde producten mist.
Online dating is eveneens een voorbeeld van een veelgebruikte dienst die op basis van suggestie-algoritmes functioneert. Het matching-algoritme van OKCupid (een online datingdienst) werd afgeleverd door de Harvardwiskundige Christian Rudder. Het maakt een âruweâ match op basis van gemeenschappelijke interesses. Vraag is natuurlijk of iemand met gelijkaardige interesses sowieso de beste partner is. Daarom berekent het algoritme eveneens hoe belangrijk elke vraag is voor de andere partij.
Steeds meer computergebruikers plakken hun webcam af met een stukje plakband, iedereen weet dat je privacy wel eens kan geschonden worden door al je internetavonturen. Toch rekenen we wel op veiligheid als we online bankieren of wanneer we een reis boeken via Booking.com en onze creditcardgegevens invullen in een App Store of in PayPal. Zonder dit gevoel van zekerheid en veiligheid zou je wel gek moeten zijn om je bankkaartgegevens ergens achter te laten. Het RSA-algoritme(ooit geschreven door de firma RSA) en het Secure hash-algoritmezorgen ervoor dat onze data veilig en versleuteld worden uitgewisseld tussen onze thuiscomputer en de servers van banken en online winkels. Een ander belangrijk algoritme in de wereld van de cryptografie is het Integer factorization- algoritme.
In 1948 schreef George Orwell het boek â1984â waarin hij scherpe kritiek leverde aan het adres van de USSR. Hij schetste
âeen onmenselijke dictatoriale eenpartijstaat die in alle opzichten volledig beheerst wordt door de Partij. De alom aanwezige leider van de Partij en het land wordt Big Brother genoemd. Iedere bewoner van het land wordt continu in de gaten gehouden via camera'sdie zelfs in de huizen zijn geïnstalleerd. Dit gebeurt onder de slogan â Big Brother is watching youâ (âGrote Broer houdt je in de gatenâ).â 7 Ondertussen leven wij in het westen niet in dictatoriale eenpartijstaten, maar Big Brother lijkt heel reëel. Ieder van ons wordt in de gaten gehouden, zij het niet door mensen, maar door algoritmes. Vanuit de USA houdt het National Security Agency (NSA) en zijn internationale partners (Five Eyes: US, Australië, Canada, Nieuw-Zeeland, Groot-Brittannië) wereldwijd miljoenen mensen in de gaten. Ze monitoren telefoongesprekken, SMS-berichten, e-mailberichten, webcambeelden, GPS-locaties enz. De hoeveelheid verzamelde informatie is veel te groot om te laten analyseren en interpreteren door mensen. De analyse gebeurt automatisch met behulp van krachtige algoritmes.
 Sommige algoritmes zoals
IBM's CRUSH, gaan nog een stukje verder. CRUSH of â Criminal Reduction Utilizing Statistical Historyâ zorgt voor
âpredictive analysisâen is in hoofdzaak bedoeld om misdaden te voorkomen. De politiediensten van Memphis konden de misdaadcijfers met 30% laten teruglopen dankzij CRUSH. Het aantal gewelddadige misdrijven liep sinds 2006 terug met 15%. Op basis van statistische gegevens, data-aggregatie en algoritmes, toont de software criminele hot spots op een kaart. Politie-eenheden kunnen op de manier pro-actief ingeschakeld worden en bij wijze van spreken aankomen voor een misdaad plaatsvindt. In de toekomst zullen criminelen heel snel opgespoord kunnen worden dankzij internetactiviteit, GPS en biosignaturen, verdacht gedrag...
Sommige algoritmes zoals
IBM's CRUSH, gaan nog een stukje verder. CRUSH of â Criminal Reduction Utilizing Statistical Historyâ zorgt voor
âpredictive analysisâen is in hoofdzaak bedoeld om misdaden te voorkomen. De politiediensten van Memphis konden de misdaadcijfers met 30% laten teruglopen dankzij CRUSH. Het aantal gewelddadige misdrijven liep sinds 2006 terug met 15%. Op basis van statistische gegevens, data-aggregatie en algoritmes, toont de software criminele hot spots op een kaart. Politie-eenheden kunnen op de manier pro-actief ingeschakeld worden en bij wijze van spreken aankomen voor een misdaad plaatsvindt. In de toekomst zullen criminelen heel snel opgespoord kunnen worden dankzij internetactiviteit, GPS en biosignaturen, verdacht gedrag...
âIn the future, these systems will largely take over the work of analysts. Criminals will be tracked by sophisticated algorithms that monitor internet activity, GPS, personal digital assistants, biosignatures, and all communications in real time. Unmanned aerial vehicles will increasingly be used to track potential offenders to predict intent through their body movements and other visual clues.â 8
De film Minority Report van Steven Spielberg uit 2002 toont al een glimp van waartoe dit in de toekomst kan leiden.
Algoritmes voor predictieve analyse zijn reeds lang in gebruik in de beurswereld. De analyse van razendsnel voorbijvliegende transacties gebeurt met behulp van slimme algoritmes. Soms kloppen de predicties niet, zoals bij de âFlash Crashâ van 2010.
Als je dobbelt met een dobbelsteen of de lotto speelt, speel je letterlijk met âtoevalâ. Een computer kan eveneens een lukraak getal genereren. In de meeste programmeertalen kan je de functie om een random getal te genereren eenvoudig oproepen. Random-getalgenerators zijn belangrijk in beveiliging en cryptografie, games, AI enz.
Rekenen kost veel te veel tijd, tijd die je aan aangenamer bezigheden kan besteden. Dat merkte men ook bij de Amerikaanse volkstelling van 1880: 500 ambtenaren hadden 7 jaar lang de handen vol om alle gegevens te verwerken. Herman Hollerith (1860â1929) was ambtenaar bij het landelijk bureau voor statistiek. Hij zag in dat je met de automatische verwerking van ponskaarten veel sneller zou kunnen werken. In 1890 introduceerde hij zijn Hollerithmachine. Gegevens zoals geslacht, leeftijd en nationaliteit van elke inwoner werden op ponskaarten opgeslagen. De machine telde en sorteerde! Met behulp van 42 machines slaagden hetzelfde aantal ambtenaren erin om de klus op een maand te klaren. In 1939 startte IBM met de ontwikkeling van een rekenmachine ,die vijf jaar later onder de naam Automatic Sequence Calculator (Mark I) het levenslicht zou zien. Het toestel werd samen met Harvard University ontwikkeld en was maar eventjes 15 meter lang en 2,5 meter hoog. De Duitser Konrad Zuse (1910â 1995) kende het werk van Babbage niet toen hij van start ging met zijn eigen rekenmachine, die volgens het binaire talstelsel van Leibnizwerkte. Zijn eerste model (Z1) gebruikte nog mechanische schakelingen, maar beschikte wel al over een geheugen. Stilaan begon hij te experimenteren met elektromechanische verbindingen, wat resulteerde in de Z3, de eerste computer waarbij zowel het geheugen als de processor elektromagnetisch functioneerde. Het binaire talstelsel volstond niet voor de verwerking van gegevens. Een elektronische schakeling levert een 1 wanneer er een stroomstoot doorgaat en een 0 wanneer dit niet het geval is. Bij computers is het van belang meerdere schakelingen te kunnen combineren. Soms mag een stroomstoot pas worden doorgegeven wanneer meerdere schakelaars op 1 staan, in andere gevallen volstaat het dat een van beide schakelaars een stroomstoot doorgeeft. De benodigde wiskunde werd geleverd door het werk van de Schotse wiskundige George Boole (1815â1864). Hij schreef in 1847 een boek waarin hij het binaire talstelsel combineerde met de logische verbindingen and, or, not. Voor de rekeneenheden van computers leverde dit de gepaste oplossing om meerdere verbindingen te kunnen combineren. De Brit Alan Turing (1912â1954) ontwikkelde een theoretisch model voor een âcomputerâ onder de naam turingmachine. Deze Logical Computing Machine bleef bij een gedachte-experiment. Turing werd vooral beroemd omdat hij tijdens de Tweede Wereldoorlog de geheime Enigma- code kon kraken. Hiervoor ontwierp hij samen met Tommy Flowers (1905â 1998) de Colossus-computers, die voldoende rekencapaciteit hadden om de Duitse codes te kraken. In 1952 werd hij gearresteerd op verdenking van homoseksualiteit en tot een experimentele chemische castratie veroordeeld. Op 7 juni 1954 werd hij levenloos teruggevonden. Hij zou zelfmoord hebben gepleegd door te bijten in een met cyanide vergiftigde appel. Volgens de legende staat deze appel symbool voor het logo van de Amerikaanse computerfirma Apple. Over Turings dood deden al snel wilde verhalen de ronde. Volgens eÌeÌn complottheorie was Turing om het leven gebracht door de Britse geheime dienst omdat hij door zijn werk tijdens de oorlog op de hoogte was van veel staatsgeheimen. De Hongaar John von Neumann (1903â1957) tekende kort na de oorlog de architectuur uit voor computers. Een computer moest beschikken over een invoereenheid, een processor voor de verwerking van de invoer, een uitvoereenheid en een geheugen voor de opslag van data. De gegevens en de programmaâs moesten binair (op basis van het talstelsel van Leibniz) worden opgeslagen. In 1945 bouwde hij zijn eerste edvac-computer, die echter duidelijk was afgekeken van een vroeger model van de Amerikaan John Atanasoff (1903â1995). Omdat het patent niet goed was geregeld, konden anderen met zijn ideeeÌn aan de haal gaan. Hierdoor stond zijn toestel ook ongewild model voor de eniac (Electronic Numerical Integrator and Calculator) van John Mauchly (1907â1980) en John Eckert (1919â 1995). Zij presenteerden vol trots hun toestel als de eerste elektronische digitale computer. Dankzij de elektronenbuizen was de rekencapaciteit enorm vergroot, maar de buizen maakten het toestel ook erg kwetsbaar. Een elektronenbuis of vacuuÌmbuis kan elektrische signalen versterken of nullen en enen doorgeven. De Mark I maakte voor zijn schakelingen gebruik van elektrische relais, die toelaten een grote stroom aan of uit te zetten met een kleine stroom. Hierdoor waren ze erg geschikt voor gebruik in computers. Maar het resulteerde wel in een zeer groot toestel met meer dan 700.000 onderdelen en 80 kilometer elektrische draden. In 1879 had Thomas Edison de elektrische gloeilamp uitgevonden. Hij leidde de stroom door een stukje verkoold katoen, waardoor het begon te gloeien en licht afgaf. Om te voorkomen dat de draad volledig verbrandde onder invloed van de lucht, plaatste hij het in een luchtledige glazen bol. Veel onderzoekers begonnen te experimenteren met de mogelijkheden van de lamp en dit leidde tot onder meer de radiobuis en de elektronenbuis, die ook perfect bruikbaar bleek als schakelaar in computers. Een relais bevatte veel bewegende onderdelen en zorgde voor relatief lange schakeltijden. Omdat een kleine wijziging in de elektronen een grote verandering kan veroorzaken in de doorgelaten stroom, was een elektronenbuis perfect bruikbaar als versterker. De ENIAC bevatte 18.000 buizen en was in alle opzichten sneller dan de Mark I. Toch had een elektronenbuis ook heel wat nadelen. Ze was niet alleen duur en erg breekbaar, maar slorpte ook massaâs energie op. De komst van de transistor in 1948 loste alle problemen op. De eerste patenten op een transistor dateren al uit 1928, maar lijken nooit in de praktijk te zijn omgezet. De transistor van William Bradford Shockley (1910â1989), John Bardeen (1908â1991), en Walter House Brattain (1902â1987) zou echter al snel de elektronenbuis verdringen. De transistor was veel kleiner, goedkoper en betrouwbaarder dan de elektronenbuis. Bovendien verbruikte hij minder elektriciteit en produceerde minder warmte. Net zoals een elektronenbuis is de transistor (transferÂresistor) een versterker, maar kan hij ook nullen en enen doorgeven. Jack Kilby (1923â2005) van Texas Instruments voegde in 1958 een tiental transistors samen in eÌeÌn geiÌntegreerde schakeling. Tegelijkertijd kwam Robert Noyce (1927â1990) van Fairchild Semiconductor met een soortgelijk circuit op de proppen. Het kreeg al snel de naam âicâ (integrated circuit), maar is bij het grote publiek vooral bekend geworden onder de naam âchipâ.
Sindsdien is de chip uitgegroeid tot het basisonderdeel van elektronische apparaten zoals de computer.Het aantal transistors op een chip zou steeds maar toenemen. Bovendien werden de transistors alsmaar kleiner, waardoor een chip in onze tijd al snel miljoenen tot zelfs meer dan een miljard transistors telt. Het groeiende aantal transistors heeft ertoe geleid dat ook de rekenkracht van computers enorm is toegenomen. Volgens de befaamde wet van Moore(Gordon Earle Moore, 1929) zou de benodigde oppervlakte voor eÌeÌn transistor om de twee jaar halveren. Elke twee jaar kwam er dus een nieuwe âchiptechnologiegeneratieâ met transistors die slechts half zo groot zijn als die van de vorige generatie. Uiteraard kan dit niet oneindig doorgaan. Men kan immers niet kleiner gaan dan de grootte van een atoom.Lange tijd daalde ook de prijs van nieuwe transistors, maar ook daaraan komt stilaan een einde. De initieÌle investeringen voor het ontwerp van een chip zijn door de miniaturisatie zo hoog geworden dat de prijzen enkel nog zakken bij immense productievolumes. Van grote invloed op de miniaturisatieis de consumentenelektronica met steeds lagere prijzen. De schaling leidt er ook toe dat we elektronische toestellen steeds sneller als voorbijgestreefd beschouwen, wat de wegwerpmaatschappij in de hand werkt.
1âAlgoritmeâ, ( https://nl.wikipedia.org/wiki/Algoritme), Geraadpleegd op 19 oktober 2015.
2âQuick sortâ, ( https://en.wikipedia.org/wiki/Quicksort), Geraadpleegd op 19 oktober 2015.
3âHeapsortâ, ( https://en.wikipedia.org/wiki/Heapsort), Geraadpleegd op 19 oktober 2015.
4DE MOOR, W., "Sneller algoritme voor Fourier-transformaties ontwikkeld", (http://tweakers.net/nieuws/79444/sneller-algoritme-voor-fourier-transformaties-ontwikkeld.html), 2012, Geraadpleegd op 19 oktober 2015.
5GUNNINK, M., "Padvinder vindt pad: over Pathfinding", (http://kninnug.nl/padvinder/index.html), Geraadpleegd op 20 oktober 2015.
6OTERO, M., "The real 10 algorithms that dominate our world" (https://medium.com/@_marcos_otero/the-real-10-algorithms-that-dominate-our-world-e95fa9f16c04), 2014, Geraadpleegd op 19 oktober 2015.
7âBig Brother (George Orwell)â, ( https://nl.wikipedia.org/wiki/Big_Brother_(George_Orwell)). Geraadpleegd op 20 oktober 2015.
8DVORSKY, G., "The 10 algorithms that dominate our world", (http://io9.com/the-10-algorithms-that-dominate-our-world-1580110464), 2014, Geraadpleegd op 20 oktober 2015.
Toen ik in 1991-1992 mijn thesis intikte, schreef ik eerst nog alles uit met de hand, met balpen op een massa velletjes papier. Een vriend beschikte toen reeds over een prille Applecomputer, tikte mijn teksten in (hij moet wel vaak hebben gegromd toen hij twee maanden lang stapels handgeschreven en moeilijke leesbare teksten onder de neus geduwd kreeg) en drukte de 200 A4-pagina's van mijn eindwerk af. Foto's moest ik er echter nog manueel aan toevoegen: foto kopieÌren op een witzwartkopieermachine, uitknippen, plakken en het geheel nogmaals kopieÌren. Niet veel anders gebeurde het bij de kranten. The times they are a-changin'.
Het grote voordeel van digitalisering is dat je de data ook achteraf kan bewerken. We bewaren al onze bestanden en gooien steeds minder weg, ook al is het dan virtueel. Seagate, de producent van harde schijven, verkocht in 2011 een totale capaciteit van 330 exabyte aan harde schijfruimte. Behoorlijk wat. Het world wide web zou in 2013 meer dan 3 zettabyte33 aan data hebben bevat en dat is sindsdien exponentieel toegenomen. In dit deel bekijken we hoe die overvloed aan data wordt bewaard. Hoe bewaart een digitaal systeem bestanden?
Naast de opdrachten die je tijdens de les moet maken, maakt iedereen individueel een animatie(film). Hoe dit in zijn werk gaat, leer je tijdens de lessen. Hieronder vind je alvast de uitgeschreven opdracht en een storyboard dat je kan gebruiken als leidraad:
Uitleg volgt nog tijdens de les!
Een digitaal systeem staat zelden alleen. Net zoals ieder van ons rond zich een sociaal netwerk van vrienden, kennissen, collega's, bekenden verzamelt, zo werkt een computer zelden in zijn âeentjeâ.
Computers kunnen in een netwerk samenwerken en uitgroeien tot eÌeÌn supercomputer door hun rekenkracht te combineren zoals bij het renderen van een 3D-film gebeurt. Ze kunnen ook hun opslagruimte combineren zoals bij big data of zoekmachines het geval is.
Het meest bekende netwerk is het internet, waarvan het web (http), e- mail (mailto), chat... de bekendste toepassingen vormen. Het internet of things moet in de nabije toekomst alle digitale apparaten via het internet informatie laten uitwisselen.
In dit deel leer je niet meteen hoe je netwerken opstelt, maar leer je iets dieper en vooral grondiger graven in het internet. Je leert sneller en beter informatie verzamelen en je leert hoe zoekmachines functioneren.
La Belgique industrielle: compte rendu de l'exposition des produits de l ... In dit boek uit 1836 lijsten de auteurs de tentoongestelde producten op van een tentoonstelling van industriële producten in 1835. (compte rendu de l'exposition des produits de l'industrie en 1835)
Link naar het boek online.
Het boek bevat een hoofdstuk over machines, maar geen enkele vermelding over het weefgetouw van Jacquard.
FAURE, F.,DUMOULIN, E.,VALÃRIUS, B.,
Jamar. undefined
Jaargang 1827-1828;
Vermelding van "Journal principalement destiné à répandre les connaissance utiles à l'industrie générale". "le gout de la mécanique industrielle, par la publication de son beau traité sur cette science." "l'art de construire les machines et de la mécanique purement rationelle" (p.388) NOG OP TE ZOEKEN
Diverse vermeldingen over de introductie van "le métier Jacquart(d)" in België.
PDF-bestand met vermeldingen:
Geschiedenis van de techniek in België. Nog niet beschikbaar voor de 19e eeuw. ( HALLEUX)
De rol van Jacquard in de techniek en automatisering ( MERCKX, K.,)
Geschiedenis van de wetenschap in België
 De eerste die een soortgelijk programmeerbaar systeem inzette voor industrieel gebruik was de Fransman Joseph Marie Jacquard (1752â1834). Hij ontwierp in 1801 een weefgetouw dat werd aangestuurd door ponskaarten. Hij baseerde zich voor zijn werk op de eerdere uitvindingen van onder anderen Basile Bouchon, Jacques Vaucanson (1709-1782) en Jean Falcon. Basile Bouchon, zoon van een orgelbouwer, bedacht al in 1725 een manier om een weefgetouw aan te sturen met
De eerste die een soortgelijk programmeerbaar systeem inzette voor industrieel gebruik was de Fransman Joseph Marie Jacquard (1752â1834). Hij ontwierp in 1801 een weefgetouw dat werd aangestuurd door ponskaarten. Hij baseerde zich voor zijn werk op de eerdere uitvindingen van onder anderen Basile Bouchon, Jacques Vaucanson (1709-1782) en Jean Falcon. Basile Bouchon, zoon van een orgelbouwer, bedacht al in 1725 een manier om een weefgetouw aan te sturen met
een geperforeerde rol papier. Het ponskaartsysteem zien we in de 19e eeuw ook opduiken in muziekdozen en pianolaâs. Ponskaarten werkten op een vergelijkbare manier als pin- of kamsystemen. In het geval van muziekdozen kon door de gaatjes lucht van een blaasbalg ontsnappen of er konden pinnetjes door schieten die instructies gaven aan de rest van het mechanisme. Bij Jacquard sprongen pinnen op door de openingen in de ponskaarten en lieten het weefgetouw een bepaald patroon weven. Het grootste voordeel van een ponssysteem was dat je veel meer instructies achter elkaar kon laten uitvoeren door de machine. Bij een cilindersysteem met pinnen of kammen was je beperkt door de omtrek van de cilinder. Ponsplaten kon je oprollen of opvouwen en door het mechanisme laten schuiven bij het uitvoeren van het programma. De wevers van Lyon vreesden voor hun werk en verbrandden het weefgetouw in 1808. Het mocht echter niet baten: het ponssysteem raakte heel snel verspreid in de wolverwerkende nijverheid en de textielindustrie.
Al snel zag men ook op andere vlakken van de samenleving het nut van een ponskaartsysteem. Je kon op een ponskaart allerlei soorten informatie in gecodeerde vorm opslaan en het geautomatiseerd laten uitlezen. Charles Babbage (1791â1871) tekende plannen voor een analytische rekenmachine en voorzag de invoer van ponskaarten. Zijn plannen betekenden een serieuze stap voorwaarts in de ontwikkeling van een rekenmachine. Eerder bouwde de Fransman Blaise Pascal (1623â1662) een mechanische rekenmachine, maar die was nooit een succes geworden. Ook de machine van Babbage kwam niet veel verder dan de ontwerptafel.
p.292

p. 293: vermelding van "boze" inwoners van Lyon.


p. 367. INTRODUCTIE IN BELGIÃ (Kortrijk, crisis in textielsector, 1838)


p. 369-370



p. 358: gebruik van Jacquards weefgetouw in Brussel: concurrentie van buitenland.

 De Académie royale des sciences, des lettres et des beaux-arts de Belgique of kortweg Académie royale de Belgique is de Franstalige tegenhanger van de Koninklijke Vlaamse Academie van België voor Wetenschappen en Kunsten (KVAB).
De Académie royale des sciences, des lettres et des beaux-arts de Belgique of kortweg Académie royale de Belgique is de Franstalige tegenhanger van de Koninklijke Vlaamse Academie van België voor Wetenschappen en Kunsten (KVAB).
Oorspronkelijk was dit de nationale Koninklijke Academie voor Wetenschappen, Letteren en Schone Kunsten van België. De voertaal was echter het Frans. Na de vernederlandsing van de Rijksuniversiteit Gent en de ontdubbeling van de leergangen aan de Université Libre de Bruxelles/Vrije Universiteit Brussel en de Université Catholique de Louvain/Katholieke Universiteit Leuven ontstond de behoefte om ook een academie in het Nederlands te organiseren. Deze werd opgericht in 1938. De Académie royale de Belgique bleef wel de nationale academie tot de eerste staatshervorming van 1970. Sindsdien valt de Académie royale de Belgique onder de Franse Gemeenschap.
p. 57: GIRAUD introduceert het weefgetouw van Jacquard in 1827 in België. Hij blijkt de enige met de technische vaardigheid om het toestel aan de praat te krijgen. Hij werkt bij M. VELLIQUS in Brussel. In 1829 haalt M. VIAL een ander toestel in Frankrijk maar nogmaals is GIRAUD de enige die het kan laten werken. Anno 1838 is de techniek wijdverbreid in België. Twee machinebouwers zijn in staat om de toestellen te bouwen: COCKERILL in Seraing en Huytens-Kerremans in Gent (beide hebben een EUROPESE REPUTATIE).

p. 80: M.F. LOUSBERGS gebruikt sinds 1832 "les métiers à la Jacquard" voor het weven van katoen. Hij beschikt over ongeveer 100 Jacquardweefgetouwen.

p. 103: Het weven zelf blijft gebruikmaken van de oude technieken maar wel met een mechanisch procédé (système hollande) in Wijnegem (M.E. Kums).

p . 140:

p. 179 - 180: De naam Jacquard wordt in één adem genoemd als de "techniek". M. De Poorter, fabrikant in Brussel, meer dan 700 werknemers. Vanaf 1827.


Charles Etienne Guillery - http://www2.academieroyale.be/academie/documents/FichierPDFBiographieNationaleTome2049.pdf#page=271
Als alternatief werd de Fransman Charles-Etienne Guillery (1791-1861) benoemd voor zowel de scheikunde als de fysica. Guillery, die zich pas in 1829 in Brussel had gevestigd, was op vele terreinen beslagen: aan het Atheneum te Brussel doceerde hij wiskunde, aan het Museum scheikunde en natuurkunde. Hoewel Guillery een aantal elektromagnetische toestellen bouwde (waaronder een elektrische telegraaf), ging zijn voorkeur toch uit naar de scheikunde en al na een jaar liet hij de cursus fysica over aan Floris Nollet (1794-1853), een verre nakomeling, zo werd gezegd, van de Franse abbeÌ Nollet die in het midden van de 18de eeuw de experimentele fysica in Frankrijk had gepopulariseerd. Guillery en Nollet doceerden ook allebei aan de in 1835 opgerichte Militaire School. In 1840 werden ze echter verplicht te kiezen voor eÌeÌn van beide instellingen. Aangezien Nollet aan de Militaire School bleef, nam Guillery de cursus fysica weer op tot aan zijn dood. Vanaf 1842 werd Pierre-NapoleÌon De Villers belast met de cursus wiskundige natuurkunde. ( http://www.dbnl.org/tekst/hall014gesc02_01/)
p. 98: vermelding van Jacquart(d) als "gewone uitvinder" die een "REVOLUTIE" veroorzaakte.

Geert V
ANPAEMELet Brigitte V
ANT
IGGELEN, « Science for the People : The Belgian Encylopédie populaire and the Constitution of a National Science Movement », dans Faidra P
APANELOPOULOU, Agustà N
IETO-G
ALANet Enrique P
ERDIGUERO(éd.),
Popularizing Science and Technology in the European Periphery, 1800-2000
, Farnham et Burlington, Ashgate (
Science, Technology and Culture, 1700â1945), pp. 65-88, spéc. pp. 76-88.



Revue de Bruxelles, 1839
Oprichting van modelbedrijven. Eerste "zal komen in buurt van Aalst".

Een link leggen gaat heel eenvoudig.
1. Selecteer een stuk tekst.

2. Klik op de knop in de opmaakbalk.

3. Plak je link.

4. Klik op het vinkje.

5. Je link is toegevoegd.

Je kan heel eenvoudig links leggen naar andere pagina's op je site.
1. Plaats je cursor in het artikel op de plaats waar je de link wil toevoegen.
2. Klik bovenaan in de menubalk op de knop "Sitelink".

4. Er verschijnt een ankerafbeelding op de plaats waar je de cursor hebt geplaatst.

5. Klik op die ankerafbeelding.

6. Selecteer de gewenste link.
7. De link is toegevoegd.

8. Bewaar je pagina.

1. Ga naar het bureaublad.

2. Klik op "bestanden uploaden".
3. Kies in de vervolgkeuzelijst de gewenste soort bestanden.


4. Sleep je bestanden naar het uploadvlak.

5. De bestanden staan op de server.
Je kan heel makkelijk een PDF- of ZIP-bestand linken aan een pagina.
1. Open de gewenste pagina.
2. Plaats je cursor op de plaats waar je de link naar het bestand of de bestanden wil toevoegen in je pagina.
3. Klik op "bestand" in de menubalk.

4. Op de plaats waar je cursor stond, staat nu een bestandsvlak.

5. Klik op het bestandsvlak.
6. Je krijgt nu een overzicht van alle bestanden (PDF, ZIP...) die op de server staan.

7. Klik op één of meerdere bestanden. Ze worden "groen" als je ze aanklikt. Klik nogmaals om ze te "deselecteren".

8. Je beschikt hier over nog vier andere functies:
| A.uploaden: | via deze knop kan je nieuwe bestanden uploaden.
|
| B.opschriften:
|
Als je op deze knop klikt, kan je het "opschrift" van het bestand wijzigen zodat de gebruiker niet de naam van het bestand te zien krijgt.
|
| C.sorteren:
|
Als je op sorteren klikt, kan je de volgorde van de bestanden wijzigen door ze te slepen met de linkermuisknop ingedrukt.
|
| D.toevoegen | Als je op toevoegen klikt, worden de links naar de bestanden opgenomen in je pagina.
|
1. Klik op uploaden.

2. Sleep je PDF-bestanden naar het uploadvlak of klik op het vlak om PDF-bestanden te selecteren.

3. Klik op "Keer terug" om terug te keren naar de vorige stap.

1. Klik op de knop "opschriften" om de tekstlinks aan te passen.
2. Je kan op de opschriften klikken om ze te wijzigen.
1. Klik op de knop "sorteren".
2. Versleep de bestanden met de linkermuisknop ingedrukt tot ze in de juiste volgorde staan.
1. Klik op "toevoegen" om de links naar de bestanden aan de pagina toe te voegen.

2. De lijst met bestanden staat nu in uw pagina.

1 Dec
In 2013 I started with the development of Agnes.js. The name of the tool refers to Agnes, the woman who was responsible for the elearningproject at CVO Diest Leuven. She retired and I would follow her. That way I wanted to pay homage to her work.
The main purpose of Agnes.js was to provide a javascript library/framework for the development of HTML5 based exercises, independent from jQuery.
First, Agnes had to make it possible to deliver all types of exercises that you can also build with HotPotatoes: filling in the blanks, multiple choice, combination, feedback, crossword...
Secondly, I also wanted to provide new functionality such as slideshows, learning paths and "filling in the blanks"-exercises on top of maps and images.
An important objective was to make this possible using simple HTML elements.
With Agnes.js you can build a filling in the blanks-exercise by creating a div or paragraph-element. Every "strong'-element in that root element becomes a word the user has to fill in. If there is more than one possible answer, you can divide them with a slash. That way a teacher can build an exercise in MS Word by simply selecting words, make them bold and deliver the DOC-file to someone with a little knowledge of HTML... That was the way we used it at CVO.
Please read the manual.
1. Open de gewenste pagina.
 2. Boven een artikel zie je een + knopje. Klik erop.
2. Boven een artikel zie je een + knopje. Klik erop.

3. Je hebt nu 2 mogelijkheden.
A. Klik op de titel van een bestaand artikel.

B. Voer een titel voor een nieuw artikel/onderwerp in.

21 Nov
 Firstly, I wanted to build a user interface for Agnes.js, a user friendly environment in which teachers can build their interactive lessons. There are already a range of software applications that you can use to develop e-learning material, but there is no integrated or easy-to-use environment. Most teachers are limited to the use of Powerpointpresentations or the tools provided by professional publishers of textbooks and learning methods. Most publishers sell digital versions of their textbooks augmented with digital media like audio and videomaterial. The largest part of this digital elearning content matches the classical way of frontal teaching.
Firstly, I wanted to build a user interface for Agnes.js, a user friendly environment in which teachers can build their interactive lessons. There are already a range of software applications that you can use to develop e-learning material, but there is no integrated or easy-to-use environment. Most teachers are limited to the use of Powerpointpresentations or the tools provided by professional publishers of textbooks and learning methods. Most publishers sell digital versions of their textbooks augmented with digital media like audio and videomaterial. The largest part of this digital elearning content matches the classical way of frontal teaching.
A first draft called "lesbouwer" ( www.schoolvoorbeeld.be/lesbouwer.php) I built in 2015. For the design of the GUI I made use of jQuery and jQuery UI and a lot of the tools I already wrote for ArchiText ( Core elements).
23 Nov
 As a student I really hate the way we have to annotate and write
bibliographical references. It must be possible to automate it, was my first thought. That's the reason I built an automated "referencing" tool which I integrated into ArchiText and WoWL. It really saves me a lot of work. The referencing tool makes use of the free to use REST-api of Google Books.
As a student I really hate the way we have to annotate and write
bibliographical references. It must be possible to automate it, was my first thought. That's the reason I built an automated "referencing" tool which I integrated into ArchiText and WoWL. It really saves me a lot of work. The referencing tool makes use of the free to use REST-api of Google Books.
The end user must be able to easily merge information from multiple online applications. Thanks to the OEMBED- and OG-protocol, it is possible to request by a simple link information from other pages, and embed them into your own page. Because most web applications and a lot of websites provide such OG- and OEMBED-information
WoWL became a real mashup-app. It goes beyond the original intent to create a GUI for Agnes.js.
Now the end user can add/embed Wikipedia-articles, YouTube, VIMEO, Prezi, Google Maps, Google Street View, Instagram... and content from tons of other webapps.
4 Jan
Kutlu Tuna, former employee of Facebook and twitter will use WoWL for his new course on social media.

WoWL is still in beta and we still have a way to go, but the core functionality works. The team for this project created example lessons and courses in Agnes.js and WoWL.
I prouly announce the first lessons completely built in WoWL:
LATIJN:
http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=4&pageid=393088714
EINSTEIN:
http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=2&pageid=831603605
LICHAMELIJKE OPVOEDING: http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=3&pageid=212516724
4 Jan
 Because WoWL has to be "easy-to-use", we choose for a facebook login system instead of a custom registration and login system. The end user can login using his facebook account. The first time he logs in, his facebook-ID, facebook username and facebook email address are stored in a MySQL-database. When the user creates an elearning course, another database table stores the course information, and remembers the facebook ID which created the course.
Because WoWL has to be "easy-to-use", we choose for a facebook login system instead of a custom registration and login system. The end user can login using his facebook account. The first time he logs in, his facebook-ID, facebook username and facebook email address are stored in a MySQL-database. When the user creates an elearning course, another database table stores the course information, and remembers the facebook ID which created the course.

9 Dec
 For this project we registered the domainnames www.wowl.be,
www.wowl.eu
and www.wowl.info.
For this project we registered the domainnames www.wowl.be,
www.wowl.eu
and www.wowl.info.
The icons in the webapp WoWL are nothing more than a font ( https://fortawesome.github.io/Font-Awesome/)
9 Jan
WoWL has a superb new feature: it supports the Open Dyslexia Fonttype. OpenDyslexic is a new open source font to increase readability for readers with dyslexia. When the user clicks on a paragraph it will be displayed in a bigger, highlighted Dyslexia font. The font may look a little strange for readers without reading difficulties, but it had been developed under the supervision of specialists.

24 dec
My first lesson in WoWL 1.0
The time has arrived for me to make my very first lesson in our own e-learning environment. As the interface is not ready for use yet, I will have to make do with my existing Html, CSS and J-Query skills. I have trained myself in Agnes.js, my fellow studentâs (and kind of also my teacher) Kris Merckxâ elearningframework. If you want to take a look at how it works in detail, he has written a really good guideline which can be found over here: http://www.schoolvoorbeeld.be/27-49-Agnes.html.
The result of my work can be admired over here: http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=6&pageid= . It took me quite a while and some help from Kris, but I am very proud of this simple lesson Iâve created. I used Brackets to write out the lesson, and Cyberduck to upload it all to Krisâ server. I am, however, very thankful to Kris that he is creating a intuitive, click-and-drag interface for our e-learning environment, because I most teachers would probably be scared off by al the programming that is involved in creating a lesson with Agnes.js.
A look behind the scenes: my lesson in Brackets


Tine. Thatâs me
Only 23, born and raised in Limburg, Belgium and a teacher-student-intern of Spanish, English and Dutch as a foreign language.
Iâm not a fan of blogging, but decided to give it a go anyway (rather: Iâm being forced â but thatâs okay.) I am, however, a fan of: languages (quelle surprise), computers (isnât that fortunate?), dancing, music, eating and sleeping.
Open My Blog
Maak een programmavenster van 400 bij 400 pixels. Dat bepalen we met de functie size() in de setup()-functie.
void setup(){
size(400,400);
}
Maak de achtergrond wit. Dit doen we door de waarden voor rood, groen en blauw op 255 te zetten:
void setup(){
size(400,400);
background(255,255,255);
}
Daarna tekenen we een zwarte cirkel in het middelpunt van het programmavenster. In functie fill() zetten we de RGB-waarden alle drie op 0. Dat levert zwart op. Om de cirkel te tekenen, gebruiken we de functie ellipse(). Die geven we vier waarden mee:
void draw(){
fill(0,0,0);
ellipse(200,200,40,40);
}
Processing tekent het scherm tientallen keren per seconde opnieuw. De cirkel blijft dus altijd netjes in het midden staan. Om een tekenprogramma te maken, doen we een kleine aanpassing. We laten de cirkel de muis volgen.
void draw(){
fill(0,0,0);
ellipse(mouseX,mouseY,40,40);
}
Je kan met de muis nu het hele scherm 'vol' schilderen. Probleem is wel dat eens je klaar bent, je geen verschil meer merkt. We missen nog een functie om het scherm opnieuw leeg te maken. Daarvoor voegen we de functie keyPressed() toe. Daarbinnen kan je om het even welke toets van je toetsenbord gebruiken om er interactieve functies aan te koppelen. Als de "key" gelijk is aan "x", dan maken we het scherm leeg.
void keyPressed(){
if(key=='x'){
clear();
background(255,255,255);
}
}
Je kan de afbeeldingen die je tekent ook bewaren met de functie saveFrame(). Als je dat in elk frame doet, krijg je een aardige reeks afbeeldingen op je opslagmedium. We voeren de functie enkel uit als we op de s-toets drukken.
void keyPressed(){
if(key=='x'){
clear();
background(255,255,255);
}
if(key=='s'){
saveFrame("###.png");
}
}

Het resultaat:

Meld je aan met je gebruikersnaam en wachtwoord.
1. Klik op de knop "sites en pagina's".

2. Je krijgt nu een lijst met al je "sites" te zien.

3. Klik op "paginabeheer" achter de gewenste site.

4. Je ziet nu een overzicht van alle pagina's in de geopende website.

5. Klik op "bewerk de inhoud" om de pagina te openen en de inhoud aan te passen.

Open de gewenste pagina zoals beschreven in het artikel "Een webpagina openen".
1. Selecteer de gewenste tekst met de muis.
2. Er verschijnt nu een bewerkingspalet.

Als je tekst wil
verwijderen, selecteer je het te verwijderen fragment, en klik je op de "delete"-knop van je toetsenbord.
Een foto kan je eenvoudig wijzigen door er op te klikken.
Je krijgt nu een lijst te zien van alle foto's op de server. Klik op de gewenste foto.
De snelste manier om een foto toe te voegen, is door hem te slepen vanaf je computer, naar de pagina die je aan het bewerken bent.

Meld je aan met je gebruikersnaam en wachtwoord.
In De inhoud van een webpagina aanpassen lees je hoe je foto's rechtstreeks vanaf je computer in je pagina kan slepen. Je kan ook afbeeldingen uit Word kopiëren en plakken in je tekst.
Het is ook mogelijk om meerdere foto's te uploaden naar je site. Die foto's kan je achteraf meerdere keren gebruiken in je pagina's of albums.
1. Klik op "Afbeeldingen".

2. Je komt nu in de foto-app terecht.

3. Klik op de knop "Upload" om naar het uploadprogramma te gaan.

4. In het uploadprogramma kan je op 2 manieren foto's toevoegen.

- Je kan foto's vanaf je computer slepen naar het uploadvenster.
- Je kan klikken op de knop "Bestanden toevoegen".

Hoe bouw je een foto-album?
Meld je eerst aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".

2. Het overzicht van alle albums verschijnt in beeld.

3. Als er nog geen albums in de lijst staan, start je met een nieuw album.
4. Klik op de knop "Nieuw album".

5. Voer een titel in en klik op de knop "Voeg toe".

1. Klik bij het gewenste album op de knop "Afbeeldingen toevoegen".

2. Je komt nu automatisch in de foto-app terecht.

3. Afbeeldingen toevoegen is nu heel eenvoudig.
4. Zorg dat je het gewenste album selecteert in de vervolgkeuzelijst, rechtsbovenaan.

5. Vink de gewenste foto's aan. De foto's zitten nu automatisch in het album.

Meld je aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".

2. Klik op de knop "Album bewerken" achter het gewenste album.

3. Je krijgt nu een lijst te zien van alle afbeeldingen in het album.

a. Sleep afbeeldingen met de linkermuisknop ingedrukt in de gewenste volgorde. De eerste afbeelding wordt meteen ook het coverbeeld.
b. Klik op het afsluitsymbool om een afbeelding uit het album te verwijderen. Je verwijdert hiermee niet de afbeelding zelf.

c. Je kan de naam, de auteur en de korte beschrijving van het album wijzigen.

4. OPGELET: Vergeet de aanpassingen niet te bewaren! Klik bovenaan op de knop "Bewaar aanpassingen".

Meld je aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".
2. Klik bovenaan op de knop "Verwijder".

3. Achter de albums verschijnt nu een verwijderknopje. Klik erop om het gewenste album te verwijderen.

4. Sluit de verwijderfunctie als je klaar bent. Klik op de knop "Sluit verwijderfunctie".

Meld je aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".
2. Klik op het meest rechtse knopje in de werkbalk.


3. Je kan nu de volgorde van de albums wijzigen.
4. Sleep met de linkermuisknop ingedrukt, de albums in de gewenste volgorde.

http://www.schoolvoorbeeld.be/files/photoshop.pdf
www.schoolvoorbeeld.be/film.pdf


Fotomontages op basis van schilderijen van Museum M te leuven.
Bekijk inspirerende beelden op
"Classical versus Modern"

en


Een uniek marketingconceptvoor een museum? Zin om mee een eventte organiseren? Kan jij en wil jij deelnemen aan dit project? Neem snel contact met ons op door je in te schrijven voor ons GOPO.
Neem contact op met irene.hermans@ucll.be



Stop de led met de lange pin in digitale output 13 en de korte pin in GND (er vlak naast).
Laad de onderstaande code op naar je bord.
void setup() {
// gebruik pin 13 van de digitale "output".
pinMode(13, OUTPUT);
}
void loop() {
//zet de voltage van pin 13 hoog (5V)
digitalWrite(13, HIGH);
//laat dit zo gedurende 1 seconde
delay(1000);
//zet de voltage van pin 13 laag (0V)
digitalWrite(13, LOW);
//laat dit zo gedurende 1 seconde
delay(1000);
}




/************************************************* * Public Constants *************************************************/ #define NOTE_B0 31 #define NOTE_C1 33 #define NOTE_CS1 35 #define NOTE_D1 37 #define NOTE_DS1 39 #define NOTE_E1 41 #define NOTE_F1 44 #define NOTE_FS1 46 #define NOTE_G1 49 #define NOTE_GS1 52 #define NOTE_A1 55 #define NOTE_AS1 58 #define NOTE_B1 62 #define NOTE_C2 65 #define NOTE_CS2 69 #define NOTE_D2 73 #define NOTE_DS2 78 #define NOTE_E2 82 #define NOTE_F2 87 #define NOTE_FS2 93 #define NOTE_G2 98 #define NOTE_GS2 104 #define NOTE_A2 110 #define NOTE_AS2 117 #define NOTE_B2 123 #define NOTE_C3 131 #define NOTE_CS3 139 #define NOTE_D3 147 #define NOTE_DS3 156 #define NOTE_E3 165 #define NOTE_F3 175 #define NOTE_FS3 185 #define NOTE_G3 196 #define NOTE_GS3 208 #define NOTE_A3 220 #define NOTE_AS3 233 #define NOTE_B3 247 #define NOTE_C4 262 #define NOTE_CS4 277 #define NOTE_D4 294 #define NOTE_DS4 311 #define NOTE_E4 330 #define NOTE_F4 349 #define NOTE_FS4 370 #define NOTE_G4 392 #define NOTE_GS4 415 #define NOTE_A4 440 #define NOTE_AS4 466 #define NOTE_B4 494 #define NOTE_C5 523 #define NOTE_CS5 554 #define NOTE_D5 587 #define NOTE_DS5 622 #define NOTE_E5 659 #define NOTE_F5 698 #define NOTE_FS5 740 #define NOTE_G5 784 #define NOTE_GS5 831 #define NOTE_A5 880 #define NOTE_AS5 932 #define NOTE_B5 988 #define NOTE_C6 1047 #define NOTE_CS6 1109 #define NOTE_D6 1175 #define NOTE_DS6 1245 #define NOTE_E6 1319 #define NOTE_F6 1397 #define NOTE_FS6 1480 #define NOTE_G6 1568 #define NOTE_GS6 1661 #define NOTE_A6 1760 #define NOTE_AS6 1865 #define NOTE_B6 1976 #define NOTE_C7 2093 #define NOTE_CS7 2217 #define NOTE_D7 2349 #define NOTE_DS7 2489 #define NOTE_E7 2637 #define NOTE_F7 2794 #define NOTE_FS7 2960 #define NOTE_G7 3136 #define NOTE_GS7 3322 #define NOTE_A7 3520 #define NOTE_AS7 3729 #define NOTE_B7 3951 #define NOTE_C8 4186 #define NOTE_CS8 4435 #define NOTE_D8 4699 #define NOTE_DS8 4978

#include "pitches.h"
void setup(){
}
void loop() {
tone(11,1047,500);
delay(1000);
tone(11,1175,500);
delay(1000);
tone(11,1319,500);
delay(1000);
tone(11,1047,500);
delay(1000);
}

Sluit het ledlampje aan op digitale pin 13 en "grond".
const int temperaturePin = 0;
void setup(){
// start communicatie met seriële poort
// Gemeten in bits per seconde: Baud 9600
Serial.begin(9600);
pinMode(13, OUTPUT);
}
void loop(){
//float = kommagetallen
float voltage, degreesC;
//we meten de exacte voltage met een afzonderlijke functie getVoltage()
// geeft waarde terug tussen 0 en 5 volt
voltage = getVoltage(temperaturePin);
//omzetten van die waarde in graden celsius
degreesC = (voltage - 0.5) * 100.0;
if(degreesC>22){
digitalWrite(13, HIGH);
}else{
digitalWrite(13, LOW);
}
Serial.print("voltage: ");
Serial.print(voltage);
Serial.print(" graden C: ");
Serial.print(degreesC);
Serial.println("");
delay(2000); // wacht 2 seconden
}
float getVoltage(int pin){
return (analogRead(pin) * 0.004882814);
}
Kies "Hulpmiddelen/Seriële monitor" in de werkbalk om de uitvoer te controleren.

 A morbid sense of humor:
A morbid sense of humor:
Een woensdagnamiddag in Brussel. Kaplan vertelt meer over zijn boek tijdens een voorstelling waarbij we hem enkel horen via een directe online verbinding en een presentatie...
Ook al was Kaplan niet fysisch aanwezig, zijn presentatie zoog meteen al mijn aandacht naar hem toe. Zijn interessegebieden vertonen heel veel raakvlakken met mijn professionele activiteiten: multimediale geschiedenis, digitale beeldbewerking en nieuwe technologieeÌn zoals augmented reality.
Door zijn innovatieve kijk op het historische en theoretische onderzoek van fotografie geldt professor Louis Kaplan als een internationaal erkende autoriteit. Hij publiceerde acht boeken waaronder het vlot leesbare en ronduit ludieke The Strange Case of William Mumler, Spirit Photographer 1. Voor de onderwerpen van zijn boeken put hij uit zeer diverse, maar meestel onderbelichte aspecten van de Europese en Noord-Amerikaanse visuele cultuur uit de negentiende en de twintigste eeuw, van spiritisme tot augmented reality.
Hij hing zijn presentatie tijdens de Photography Performing Humor-conferentie in Brussel op aan zijn nog te verschijnen boek Photography and Humour. 2 Kaplan introduceerde het publiek in zeer diverse vormen van fotografische humor. Ook in dit visuele medium is humor vaak verbonden met ernstige onderwerpen zoals de eigen identiteit, sociale toestanden en de dood. Van bij het ontstaan van de fotografie in de prille negentiende eeuw toonden fotografen een morbide gevoel voor humor, vandaar ook de titel van de presentatie. Meer dan bij de andere keynotes staafde Kaplan zijn betoog met een fascinerende reeks afbeeldingen. Zijn voorbeelden balanceerden tussen bijtende politieke satire en stereoscopische huiselijke komedies, tussen conceptuele humor in de kunst tot surrealistische zwarte humor. Hij putte rijkelijk uit het in 1898 verschenen Magic: Stage Illusions and scientific diversions including trick photographyvan Albert Hopkins 3. Hij toonde hierbij aan dat technieken van beeldmanipulatie zoals bekend uit softwaretools als Adobe Photoshop een rijk verleden kennen. Negentiende-eeuwse fotografen benutten technieken zoals maskers, multi exposure, montage en compositie die bij een hedendaagse doorwinterde Photoshopper in de digitale vingers zitten. Die prille vormen van beeldmanipulatie zoals het fotograferen voor een zwarte achtergrond of spiegels leverden morbide afbeeldingen van onthoofdingen op en geestverschijningen. Hier kon Kaplan terugvallen op zijn eerdere onderzoek en publicaties.
Kaplan putte voor zijn voorbeelden uit het werk van pioniers uit de fotografie als Hyppolyte Bayard, gerenommeerde fotografen als Jacques Henri Lartigue, Elliott Erwitt, Weegee, Cindy Sherman en Martin Parr, maar ook het werk van onbekende Photoshoppers. Het leverde een geestige, vaak absurde en soms hilarische reeks voorbeelden op waar Kaplan tussen door laveerde met een pittige anekdotische vertelstijl.
De vergankelijkheid een toekomst geven.
Oude familiefoto's vertellen een verhaal, even fragmentarisch als mijn herinnering. Foto's vormen dode bevroren momentopnames uit mijn eigen geschiedenis. Kan ik de verloren en gemiste momenten weer tot leven wekken?

And if they had the words
I could tell to you
To help you on the way down the road
I couldnât quote you no Dickens, Shelley or Keats âcause itâs all been said before
Make the best out of the bad just laugh it off
You didnât have to come here anyway
So remember, every picture tells a story donât it
(R. Stewart)
Maart 2016. Ik stond naast mijn vader toen hij zijn laatste woorden zei. Ik ga toch nog niet dood, zei hij wat bevreesd, en in zijn woorden klonk de zorg om alles en iedereen. Het klonk vreemd, de woorden gingen vluchtig en nu nog brandt dat laatste beeld op mijn ogen. In mijn hoofd speelden de verhalen van mijn vader en ikzelf. Zesenveertig jaar heb ik hem gekend, beleefd, gezien, heb ik de tijd gehad om verhalen te distilleren over hem en mij. We bouwden samen een verleden. Hij was er al toen ik er nog niet was, hij maakte deel uit van een verleden dat ik nooit heb gekend, waar ik enkel over heb gehoord of waar ik vergeelde foto's van heb gezien. Bij het opruimen van zijn kamer vond ik een stapel oude foto's van familieleden die ik nooit heb gekend, maar wel herken. Elk beeld vertelt zijn eigen verhaal, soms maar wat flarden. Vergeten familieverhalen, soms nog onduidelijk of verwarrend, het verleden ontsluit zich slechts fragmentarisch via deze beelden. Hoeveel beelden gingen verloren, hoeveel momenten zal ik nooit zien? Als historicus weet ik dat dit soort beelden geen geschiedenis maken, maar ze zijn niettemin een deel van mezelf, van mijn verleden, van wie ik ben en van wat mijn kind ooit zal zijn. Ik mis heel veel en ik heb heel veel gemist. Triljoenen beelden gingen verloren, elk mogelijk moment uit mijn en zijn verleden. Het verleden ging weg en als ik de verhalen niet vertel, dan betekenen de beelden niets meer, ijle beelden van een verdwenen tijd.
De dag na het overlijden van mijn vader maakte ik een kaartje als herinnering, een reeks
memento mori,voor iedereen die hem had gekend. Ik se
â All photographs are memento mori. To take a photograph is to participate in another personâs (or thingâs) mortality, vulnerability, mutability. Precisely by slicing out this moment and freezing it, all photographs testify to timeâs relentless melt.â
Een foto verhaalt één moment, één enkel frame, zoals een snede kaas uit een groot blok. Kate Morton omschreef fotografie in haar debuutroman The House at Rivertonals een ietwat ironische manier om dode momenten, die eigenlijk enkel mogen verder leven in de herinnering, te laten overleven:
âIt is a cruel, ironical art, photography. The dragging of captured moments into the future; moments that should have been allowed to be evaporate into the past; should exist only in memories, glimpsed through the fog of events that came after. Photographs force us to see people before their future weighed them down....â
De foto's die het kaartje haalden, waren zelden meer dan willekeurigedoor de fotograaf gekozen cadrages. De fotografen van dienst hadden geen artistieke ambities, de beelden zijn niet meer dan vernacular photographies. Toch ontstonden ze uit meer dan louter willekeur. Elk beeld vertolkte een verhaal dat net zoals het beeld zelf uit de werkelijkheid, uit het continuüm, was losgesneden en nu verder leefde. De fotograaf had het moment gedood en vastgelegd en elk beeld bracht een verhaal tot leven.
âTo photograph people is to violate them, by seeing them as they never see themselves, by having knowledge of them that they can never have; it turns people into objects that can be symbolically possessed. Just as a camera is a sublimation of the gun, to photograph someone is a subliminal murder - a soft murder, appropriate to a sad, frightened timeâ, schreef Susan Sontag.
Toch is elk beeld meer dan pure willekeur, het zijn zorgvuldig uitgekozen momenten. Ook al had de fotograaf geen artistieke pretenties, de fotograaf legde een magisch moment vast. Elk beeld was een toevallig, maar niettemin bewust gekozen moment. De Amerikaanse fotograaf Stephen Wilkes omschrijft dit proces als het vastleggen van magische momenten :
â It's my eye seeing very specific moments, I like to describe myself as a collector of magical moments."
Elke vernacularfoto vertolkt een verhaal, een beeld dat magische momenten en verhalen in leven houdt, ook al zijn de actoren er niet meer om ze te bevestigen of te ontkennen. Het maakt ons tot wie we zijn of tot wat we willen zijn.

â Photography is a medium that is famous for freezing time. The word snapshot suggests that a tiny slice of time is recorded for posterity⦠A photographic print is flat, and essentially is made of 2 dimensions: length and width. Yet through composition and lens focus we give a print depth⦠The best images are the ones which let you feel like you can step directly into the frame into a world which is on the other side.â
(Fong Qi Wei) 1
Een foto vormt een momentopname, een
dood moment, een
fractie van tijdop beeld vastgelegd. Fotograaf en kunstenaar Fong Qi Wei omschrijft fotografie als een manier om de tijd te bevriezen. De fotograaf se
Gordon Bell van Microsoft Research trachtte met zijn MyLifeBits-project zijn volledige geschiedenis vast te leggen met audio-, beeld-, tekst- en videomateriaal. Lifeloggingis de exacte benaming die de onderzoekers van Microsoft er voor in het leven geroepen hebben. Het is in hun ogen een enige manier om tot een Total Recallvan je persoonlijke verleden te komen. De vraag is natuurlijk of we dit wel willen. De SenseCam is een soort van webcam die je rond de hals kan dragen. Het toestel maakt automatisch, met behulp van bewegingssensoren, warmtedetectoren enz. foto's van je hele dag. Oorspronkelijk werd het ontwikkeld voor het helpen van Alzheimer-patieÌnten. Het bezorgt deze mensen een soort valse vorm van herinnering, elk vergeten moment wordt bewaard in een digitale databank.
Hoe lang duurt een moment? De meeste mensen ervaren een moment als iets wat ze bewust kunnen zien. Het bewust waarnemen van een beeld duurt ongeveer honderd milliseconden. Nemen we de tijd dan waar in stukjes of frames zoals een filmcamera dat doet? Maken onze hersenen van elk moment een afzonderlijke stillof foto die ze levenslang vastleggen in ons geheugen? Betekent dit dat onze hersenen de binnenkomende signalen van sensoren zoals de ogen en de oren bemonsteren (samplen) en de informatie discretiseren zoals bij digitalisering gebeurt? Het sleutelwoord bij digitaal is discretisatie in ruimte en tijd. Bij het digitaliseren van analoge beeldinformatie, plaatst een digitaal fototoestel een denkbeeldig raster over de fysieke wereld en meet de binnenkomende signalen op het moment dat de fotograaf klikt. Een sample of een monster van een digitale foto bestaat uit een verzameling van picture elements of pixels, de bemonstering gebeurt bij fotografie enkel geometrisch, in lengte en breedte, en niet doorheen de tijd zoals bij een audio- of filmopname. Een digitaal systeem meet eveneens de signaalniveaus (discretisatie van de signaalwaarden) zoals bijvoorbeeld de lichtintensiteit van een pixel. Het lijkt erop dat onze hersenen niet enkel momentopnames maken in een geometrisch perspectief, maar ze eveneens inhoudelijk verwerken. Ze koppelen beelden aan verhalen, geluiden en geuren. Het lijkt wat op de manier waarop sociale media gebruikers beelden laten taggenof er doorzoekbare informatie aan te koppelen. Wat Ingrid Hoelzl opmerkt over de evolutie van analoge naar digitale fotografie, kan dus in zekere mate ook gezegd worden over de manier waarop onze hersenen beelden verwerken: "The algorithmic image is no longer governed by geometric projection, but by algorithmic processing."(Softimage, 5).
Onderzoekers van de universiteit van Glasgow ontdekten dat ons brein de werkelijkheid niet ervaart als een continuüm. Net zoals bij digitalisering verdelen onze hersenen binnenkomende signalen in momentopnames. De resultaten verschenen in het vakblad Current Biology. Professor Gregor Thut van de universiteit van Glasgow zegt hierover: âRitmiek is inderdaad alomtegenwoordig, niet alleen in de hersenactiviteit, maar ook in de hersenfunctie. Voor de waarneming betekent dit dat, ondanks het âfeitâ dat we de wereld ervaren als een continuüm, we niet constant âmonstersâ nemen van de wereld, maar in discrete momentopnames, bepaald door de cycli van hersenritmes.âDe snelheid waarmee onze ogen de werkelijkheid bemonsteren, ligt veel hoger dan bij een fototoestel.
Wat bepaalt de lengte van het kortst mogelijke moment?Meten we hoe snel een mens bewust of onbewust een moment kan ervaren (een ogenblik) ofbestuderen we het kortst te registreren moment? Onderzoekers van de MIT Media Lab Camera Culture Group ontwikkelden onder leiding van Ramesh Raskar een camera die een biljoen beelden per seconde kan maken. Wanneer je de beelden in slow motion bekijkt, krijg je de werkelijkheid op een heel andere manier te zien. Hiermee zijn de MIT-wetenschappers er zelfs in geslaagd om de beweging van licht in slow motion vast te leggen. Ze brengen op die manier een nooit eerder waargenomen wereld tot leven met een fototoestel dat het kortst mogelijke moment vastlegt. Daarmee legt de camera echter nog niet de werkelijkheid vast:
â The camera does not capture the visual forms of an event, but instead creates the visual form of a photographic event. It depicts a moment th at never actually existed, and which has therefore never been perceived or recognized or photographed as such. The photograph does not reveal the optical unconscious, but rather the photographic uncanny: It shows what does not priory exits to the photographic event, that is, the photograph. The photograph is uncanny not because it reanimates the past, but because iet creates ghostly references.â (46)

A picture of you in your birthday suit,You sat in the sun on a hot afternoon.Picture book, your mama and your papa,and fat old uncle charlie out cruising with their friends.Picture book, a holiday in august, outside a bed and breakfast in sunny southend.Picture book, when you were just a baby,those days when you were happy, a long time ago.( R. Davies )
Fotografie biedt de mens een middel om het verleden/heden visueel te bewaren. Anders dan een tekst lijken foto's historici een objectiever houvast te bieden. Nochtans leggen ze slechts één verleden vast, bekeken vanuit het perspectief van de fotograaf die een kader legt over zijnheden. Millennia lang was de mens aangewezen op het gesproken verhaal. De komst van het schrift in het vierde millennium voor onze tijdrekening maakte het mogelijk om het verleden ook buiten het geheugen van de mens vast te leggen. Het waarheidsgehalte hing af van het standpunt van de schrijver, van zijn opmerkzaamheid, van zijn woordenschat en van tal van andere factoren. Misschien verzweeg hij dingen of verdraaide hij de werkelijkheid. Bovendien kon hij enkel noteren wat hij zelf met zijn beperkte gezichtsveld had waargenomen, wat anderen hem hadden verteld of wat hij had gelezen. Historici kennen het verleden slechts fragmentarisch. Elk geschiedenisboek vertelt maar een klein stukje en zelfs als we alle bekende feiten samenvoegen dan nog komen we niet tot een lappendeken dat het hele verleden bestrijkt. We missen letterlijk de geuren en de kleuren, de geluiden en de beelden.
Kan technologie het verleden in beeld brengen zonder fototoestel? Een digitale afbeelding bestaat uit een reeks pixels of beeldpunten, verdeeld over een geometrisch raster van horizontale rijen en verticale kolommen. Elk beeldpunt kan een bepaalde kleurwaarde aannemen. Jeffrey Thompson, assistent-professor en programmadirecteur in Visual Art & Technology aan het Stevens Institute of Technology in Hoboken, schreef in 2013 een stuk software dat willekeurig afbeeldingen genereert. Als je de software voldoende tijd geeft, creëert hij elke mogelijke afbeelding. In datzelfde jaar zette Thompson de tentoonstelling Every Possible Photographop waarin hij de mogelijkheden van zijn software demonstreerde:
âThis project investigates the idea of using computation to âuse upâ a piece of technology, in this case a digital camera. Using custom-written software (and a very long period of time), every possible photograph is generated, one at a time and in numerical order. The idea that extremely useless labor is interesting is central to this project (and the proposed project as well), as is the eschewing of the utility of data and its representation in traditional visualization work. Attempting to create every image a camera is essentially a time machine; somewhere in the set of images and alongside billions of âmeaninglessâ others are a photograph of me, a photograph of me if I didnât get a haircut last week, and a photograph of me with someone who I have never met.â
Indien de software een foto zou genereren van 400 bij 300 pixels, dan resulteert dit in 120 000 pixels per foto. De kwaliteit zou laag zijn, maar niettemin een herkenbaar beeld opleveren. Bij een kleurdiepte van 24 bit, zou de software een keuze hebben uit 16 777 215 kleuren per pixel. Op die manier kan de software achter het Every Possible Photograph-project elk denkbaar beeld uit het verleden of de toekomst genereren. Elk mogelijk beeld ontwikkelen zou niet alleen een computer met een enorme rekenkracht vereisen, maar bovendien zou de ontwikkeling (rendering) van alle beelden onwaarschijnlijk veel in beslag nemen. Thompson beperkte zich tot afbeeldingen van 15 bij 10 pixels en grijswaarden. Maar zelfs in dat geval zou het genereren van elke mogelijke combinatie 46 138 562 195 008 110 600 774 753 760 087 749 172 181 189 607 929 628 058 548 517 099 604 563 033 706 075 jaar duren.
 A single âphotographâ, number 657
2
A single âphotographâ, number 657
2
Every Possible Photographzou elke momentopname uit het verleden van mijn vader in beeld kunnen brengen. Maar de grootste uitdaging zou er uit bestaan om het werkelijke verleden van het fictieve verleden te scheiden. Immers, elk denkbaar verleden, elke denkbare toekomst is voor de visualisatiesoftware even waarschijnlijk. De software zou alle mogelijke wat als-scenario's tot leven brengen, elk mogelijk heden en verleden. Wat als-scenario's zijn voor de meeste historici niet meer dan leuke denkoefeningen, maar ze zijn misschien niet meer of minder waarschijnlijk dan werkelijke gebeurtenissen. Toen ik in 2012 mijn boek In geen tijdschreef, was ik lusteloos op zoek naar een rode draad die alle hoofdstukken aan elkaar zou rijgen. Mijn dochtertje keek bij toeval naar de Pixar-film "Brave". De verteller in de film reikte me de volgende woorden aan:
âAnderen zeggen dat de draden van het lot geweven worden als een kleed en dat iemands lot verstrengeld is met dat van vele anderen. We zijn allemaal op zoek naar het patroon of willen het veranderen.â
Met CGI (computer generated images) kunnen we elke gesponnen draad, elk potentieel moment uit het verleden vastleggen en ook elk denkbaar moment, ook al is het nooit effectief gebeurd. We kunnen van Hitler een menslievend figuur maken en de Holocaust annuleren, we kunnen de wereld bevrijden van de mens of de wereld totaal vernietigen. Elk denkbaar verleden, elke denkbare toekomst wordt mogelijk. Vastgelegd in foto's, beeld voor beeld. Allen even waarschijnlijk als onwaarschijnlijk. Ik had elke mogelijke vader kunnen hebben, niet volgens mijn DNA, maar wel dankzij Every Possible Photograph. Every picture tells a story,fictief of non-fictief.
Kris Merckx
1. Conveying the Passage of Time through Photography, (http://twistedsifter.com/2013/08/conveying-time-through-photography-fong-qi-wei/), Geraadpleegd op 6 juni 2016.
2. THOMPSON, J. A single âphotographâ, number 657 (http://jeffreythompson.org/every-possible-photograph.php), Geraadpleegd op 7 mei 2016.
De praktijk van fotomanipulatie.
Manipulatie is inherent aan fotografie en niet het gevolg van digitale fotografie of beeldbewerking. De hang naar objectiviteit in documentaire fotografie is een relatief recent gegeven. Weliswaar dient er een onderscheid gemaakt te worden tussen manipulatie en bedrog.

âTraditional photographs - the ones our culture has always put so much trust in - have never been âtrueâ in the first place. Photographers intervene in every photograph they make, whetherby orchestrating or directly interfering in the scene being imaged; by selecting, cropping, excluding, and in other ways making pictorial choices as they take the photograph; by enhancing, suppressing, and cropping the finished print in the darkroom; and, finally, by adding captions and other contextual elements to their image to anchor some potential meanings and discourage others.â 1 (G. Batchen)
Het begrip Photoshoppendraagt in onze tijd een erg negatieve lading. Digitale fotografie en beeldbewerking zouden fotografie van haar echtheid hebben ontdaan.
"It has often been argued that digital interventions undermine photography's supposed truthful status, and have thus come to herald the death of analog photograpy's most specific hallmark". 2
Nochtans ontstond manipulatie van beelden niet bij het verschijnen van digitale beeldbewerkingsprogramma's. In zekere zin dook het streven naar objectiviteit en echtheid in de fotografie pas relatief laat op. Het in scene zetten van beelden behoorde tot de normale gang van zaken. De vroege fotografen volgden de tradities uit de schilderkunst en de theaterkunst waarbij respectievelijk de portretkunst en de decorbouw tot voorbeeld dienden. In het laatste kwart van de 19e eeuw verscheen in de fotografie straight photographyop de voorgrond. Deze fotografen streefden naar een pure fotografie waarbij het documentaire en het vormelijke aspect het belangrijkst waren. Een foto mocht niet in scene worden gezet of gemanipuleerd. De gedetailleerde foto's die fotografen als Paul Strand en Edward Weston maakten, streefden naar objectiviteit.
Volgens Geoffrey Batchen is het een illusie te denken dat een foto de objectieve werkelijkheid kan weergeven. Elke fotograaf manipuleert in min of meerdere mate de foto's die maakt. Immers, elke fotograaf se
âAny familiarity with photographic history shows that manipulation is integral to photography. Over and above the cultural bias toward "Renaissance space" that provides the conceptual grounding of photography itself, there are the constraints of in-camera framing, lenses, lighting, and filtration. In printing an image, the selection of paper and other materials affects color or tonality, texture, and so forth. Furthermore, elements of the pictorial image can be suppressed or emphasized, and elements from other "frames" can be reproduced on or alongside them. And context, finally, is determining.â 3
Daarom geldt manipulatie volgens Van Gelder niet als een waardig criterium om het verschil tussen analoge en digitale fotografie te bepalen. Analoge fotografie verschaft de kijker geen echterbeeld van de werkelijkheid. 4 Door bepaalde elementen te benadrukken en andere weg te laten kan fotografie een onevenwicht te weeg brengen in wat de kijker als waarheid aanvaardt. Ritchen stelt
â Photography, even of the most realistic type, can articulate truths even though facts may be wrong and conversely, can also be quite wrong as to the essence of a situation despite getting the facts rightâ. 5
Dit geldt zowel voor analoge als voor digitale fotografie. De Amerikaanse filosoof Scott Walden begrijpt het wantrouwen in het waarheidsgehalte van digitale foto's:
âDigital images can also le a ve the veracity of our thoughts unscathed. But it will be much more difficult for the viewer to have confidence in such thoughts because it is much more complex to verify the degree of objective, mechanical creation of digital images than that op analog images.â 6
Hoelzl duidt de algoritmische verwerking in digitale fotografie en beeldbewerking als één van de belangrijkste verschilpunten met analoge fotografie 7

â On the subject of retouching photographic negatives, there are many conflicting opinions, and a great deal of nonsense has been uttered both for and against this operation; some perfectly competent photographers urging that a photograph is quite incomplete until it has been retouched, others asserting that when a negative leaves the dark room it is quite ready for the printer." 8
(R. Johnson, A.B. Chatwood, 1895)
âComposite photography consists in the fusion ot a certain number of individual portraits into a single one. This is effected by making the objects which are to be photographed pass in succession before the photographic apparatus, giving each of them a fraction of the long exposure, equal to such exposure expressed in seconds and divided by the number of the objects which are to be photographed.â 9
(A. Hopkins, 1898)

In het boek â Magic. Stage illusions and sci ent ific diversions including trick photographyâbeschreef Hopkins een reeks technieken voor het trukeren van afbeeldingen. Vele van de door hem beschreven vormen van beeldmanipulatie vonden hun weg naar de film. De speciale effecten in de films van filmpionier Georges Méliès waren er schatplichtig aan. De kijkers waren er zich in de meeste gevallen van bewust dat het ging om trucage. De maker had niet de bedoeling om zijn publiek iets wijs te maken of te bedriegen, maar wou verbazing wekken zoals een goochelaar dat deed op het podium. Anders gaat het wanneer de makers bewust de bedoeling hebben om de kijker te bedriegen. In de jaren 1920 raakten de Britse nichtjes Frances Griffith en Elsie Wright wereldberoemd toen ze foto's maakten van henzelf in de tuin omringd met elfjes. Experts verklaarden de foto's als echt. Het zou vijftig jaar duren vooraleer ze hun bedrog toegaven. Het gebruik van vervalste foto's om het eigen gelijk kracht bij te zetten, kent een lange traditie in de politiek en de oorlogsfotografie:
âThe use of faked photographs is a long-standing political trick, in the form both of photographs misappropriated or changed after they were produced and in ones set up for the camera. Before lithographyâ enabled newspapers to use photographs directly around 1880, photographs were at the mercy of the engravers who prepared the printing plates for reproduction. Even now, cropping and airbrushing are decisive methods of manipulating existing imagery, and set-up or staged ("restaged") images are always a possibility.â 10


"Every day, the internet generates trillions of images and videos (...). The volume of photos and videos generated in the past 30 days is bigger than all images dating back to the dawn of civilization. In the presence of massive volume, large variety and high velocity, programming machines to recognize all objects in the observed images seems to be an impossible task to carry out. However, the performance of computer vision can be enhanced substantially by big data." 11
(S. Liu, J. McGree, Z. Ge, Y. Xie)
Anders dan het algemeen overheersende denkbeeld is beeldmanipulatie geen gevolg van de digitalisering, beeldbewerkingssoftware betekende enkel een krachtige stimulans. Volgens Rosler is het succes van digitale beeldmanipulatie
âthe logical consequence of digital developments of a cultural imperative to create perfectly tricked pictures, rather than vice versa.â 12
De opkomst van digitale beeldmanipulatie roept ons op om de eigenheid van fotografie als visueel medium opnieuw in vraag te stellen, op dezelfde manier waarop de schilderkunst zichzelf in vraag diende te stellen bij het ontstaan van de fotografie. Zelfs de meest realistische portretschilderijen konden niet tippen aan het realisme van een foto. Schilderijen zijn gebaseerd op getekende lijnen en penseelstreken. Foto's bestaan uit een reeks microscopisch kleine belichte partikels of pixels waarvan de werkingerg lijkt op die van de retina in een menselijk oog. Zo vereist ook de opkomst van digitale fotografie en beeldmanipulatie dat het representatieve karakter van fotografie in vraag wordt gesteld.
Ingrid Hoelzl ziet in de overgang naar digitale fotografie twee belangrijke verschuivingen. In de eerste plaats ruimt het klassieke geometrische aspect van het 2D-beeld plaats voor de algoritmische verwerking van beelddata. Daarnaast maakt een beeld slechts onderdeel uit van een reusachtige databank:
â I n the digital age, computers process data, while the image is part of the database. As a tentative view of networked databases, the image is continuously updated and refreshed.â 13
De menselijke retina reageert gevoeliger op helderheid dan op kleuren. Het menselijk brein heeft weinig oogvoor tintverschillen. Wanneer een mens naar een blauwe lucht kijkt, merkt hij niet de duizenden tinten blauw die een beeldchip wel kan registreren. Het JPG-algoritme laat daarom heel wat kleurverschillen weg. Eenvoudig voorgesteld: een jpeg verdeelt een afbeelding in een raster waarbinnen gemiddelde waardes worden gemeten. Veel variatie in kleur wordt weggelaten. Hoe meer verschillen weggelaten worden, hoe groter de compressie. Hoe kleiner de cellen in het raster, hoe meer kleurverschillen het algoritme bewaart en hoe lager de compressie. Dit algoritme dat in de meeste digitale toestellen de facto is ingebed, manipuleert op die manier reeds het beeld dat de beeldchip van het fototoestel registreert.
Een digitale afbeelding bestaat uit een eindig aantal rijen en kolommen. Elke cel van die matrix vormt een pixel en die pixel kan, afhankelijk van de gebruikte hardware tussen de 2 en de ettelijke miljoenen kleurwaardes aannemen. Software maakt het mogelijk elke afzonderlijke pixel te bewerken, te verwijderen of te vervangen. Hiervoor hebben softwareontwikkelaars gebruiksvriendelijke bewerkingsinterfaces gebouwd. Naast het digitaal retoucheren van fotografische afbeeldingen, kan de gebruiker afbeeldingen in composities of collages samenvoegen. De eigenheid van digitale afbeeldingen maakt het anderzijds ook mogelijk om nieuwe afbeeldingen te genereren. In zo'n geval spreekt men van CGI of computer generated images.
Het insluiten van camera's in mobiele telefoons, tabletcomputers en laptops heeft ertoe geleid dat het maken van foto's niet alleen veel goedkoper is geworden, maar dat de stap om een foto te maken is geminimaliseerd. Dankzij social media is het delen van foto's een fluitje van een cent. Zoals Hoelzl stelt, maakt deze gigantische hoeveelheid beeldbestanden deel uit van een gigantische databank van genetwerkte gegevens: big data. De term âbig dataâ duidt niet op een computertechniek, maar slaat op de gigantische hoeveelheid digitale informatie die wereldwijd beschikbaar is. In 2016 zullen datacenters (plaatsen waar internetservers staan opgesteld) wereldwijd 16000 ha oppervlak innemen. De gezamenlijke datacapaciteit is dus enorm en naar schatting is op dit moment slechts 0.5% van die gegevens geanalyseerd. Datascientists hopen hiervan binnen enkele jaren tijd tot 33% te taggen en analyseren. Vooral het analyseren van afbeeldingsdata maakte op technologisch vlak rasse schreden voorwaarts. Robuuste, schaalbare en zelflerende algoritmes voor het ophalen, indexeren, organiseren van visuele informatie zijn in voortdurende ontwikkeling. Slimme algoritmes herkennen objecten in afbeeldingen en kunnen die koppelen aan zoekalgoritmes. Intelligente bewakingscamera's herkennen mensen en hun respectieve interesses en eventueel verdachte gedragingen.

Japanse onderzoekers slaagden er in 2008 in om op basis van een fMRI-scan van de hersenen beeldmateriaal uit menselijke hersenen te reconstrueren. Het onderzoek naar visual image reconstruction from brain activity gaat door aan verschillende onderzoekscentra en men bereikt op dit moment al onvoorstelbare resultaten. Bij sommige computerwetenschappers rijst het vermoeden dat de werkelijkheid slechts een virtuele simulatie is, een verzameling van gemanipuleerde visuele gegevens. De simulatiehypothese stelt dat de zichtbare realiteit niet echt is, maar dat we leven in een computersimulatie. De âgesimuleerdenâ (wij mensen) zijn zich er totaal niet van bewust. Dit idee vormt de basis achter SF-films zoals The Matrix. Volgens de Britse computerdeskundige Nick Bostrom zijn er argumenten om aan te nemen dat dit wel degelijk het geval is. De fotograaf, noch de softwaregebruiker gelden dan als de manipulator. Zij zijn zelf het slachtoffer van een volledig gemanipuleerde en virtuele omgeving. Meer nog, misschien maken ze zelf wel deel uit van die visuele illusie.
1. G. BATCHEN, "Phantasm: Digital Imaging and the Death of Photography", Aperture,136 (1994), 48.
2. H. VAN GELDER, H. WESTGEEST, Photography theory in historical perspective,Chichester, 2012, 23.
3. M. ROSLER, Image Simulations, Computer Manipulations: Some Considerations, (http://www.artic.edu/~pcarroll/rosler.html), Geraadpleegd op 5 juni 2016.
4. VAN GELDER, Photography theory,31
5. F. RITCHEN ,âWhat is Magnum? â, Our Time: The World as Seen by Magnum Photographers,(New York: The American Federation of Arts in association with W.W. Norton & Company, 1989), 422.
6. S. WALDEN, Photography and philosophy: Essays on the pencil of nature, Malden, 2008, 108-110.
7. I. HOELZL, R. MARIE, Softimage, towards a new theory of the digital images, Chicago, 2015, XX.
8. R. JOHNSON, A.B. CHATWOOD, Photography artistic and scientific, Londen, 1895, 116.
9. A. HOPKINS, Magic. Stage illusions and sci ent ific diversions including trick photography, New York, 1898, 495.
10. M. ROSLER, Image Simulations, Computer Manipulations: Some Considerations, (http://www.artic.edu/~pcarroll/rosler.html), Geraadpleegd op 5 juni 2016.
11. S. LIU, J. MCGREE, Z. Ge, Y. XIE, Computational and statistical methods for analysing big data with applications, Londen, 2016, 58.
12. .M. ROSLER, Image Simulations, Computer Manipulations: Some Considerations, (http://www.artic.edu/~pcarroll/rosler.html), Geraadpleegd op 5 juni 2016.
13.. I. HOELZL, R. MARIE, Softimage, towards a new theory of the digital images, Chicago, 2015, XVIII.
Mijn studenten kijken altijd wat ongelovig, maar vooral ook nieuwsgierig als ze te weten komen dat ik zowel met geschiedenis als met informatica bezig ben. Voor mezelf is dat niet zo vreemd. Informatica bedrijven is informatie structureren, catalogiseren, vergelijken, indelen, opzoeken, doorzoeken, filteren ... kortom, dingen waarover ook de heuristische methodes van een historicus handelen. Het ultieme streefdoel als leraar is jongeren leren omgaan met informatie, ze leren filteren. Maar dat is natuurlijk makkelijker gezegd dan gedaan.
Leren betekent ook informatie bestendigen in het geheugen. Ruwweg kunnen we als mens op twee manieren informatie leren en opslaan. Declaratieve herinneringengaan via de kortetermijnbuffer naar onze hersenen. Het betreft in dit geval semantische herinneringen, zoals begrippen en feiten, en episodische herinneringen, die gekoppeld zijn aan een bepaalde tijd en ruimte. Dit soort informatie raakt het snelst vergeten. Niet-declaratieve herinneringengaan niet via de kortetermijnbuffer en lijken door onze hersenen meer te worden bestendigd. Hierin onderscheiden we drie vormen van leren: motorisch leren verloopt via de kleine hersenen, perceptueel leren via de neocortex en gewoontevorming via de basale ganglia.
De langetermijnopslag, kortom de âharde schijfâ of het geheugen van onze hersenen, ligt in de neocortex en voor een stuk in de hippocampus, in het zogenaamde "zoogdierenbrein". Mensen met geheugenproblemen zoals dementie âvergetenâ de namen van hun kinderen, maar kunnen meestal wel nog fietsen of koken. Het lijkt erop dat aangeleerde stappenplannen beter geconsolideerd worden dan pure feitenkennis. Ook al hebben computers niet meteen last van dementie, toch onderscheiden we ook hier die dualiteit tussen pure feitenkennis (de opslag van informatie) en het uitvoeren van programmaâs .

Afbeelding: 19e eeuwse muziekdoos.
â(...) Nadat ik Herons tekst grondig had gelezen, had ik niet de minste twijfel over zijn intentie. Het is duidelijk dat hij zijn robot had ontworpen om hem te kunnen programmeren en om hem in het theater voor verschillende effecten te gebruiken. Op een bepaald punt beschrijft hij zelfs hoe je ingewikkeld gedrag moet programmeren.â
Net zoals in moderne programmeertalen slaagde Heron er ook in om een âtimerâ-functie in te bouwen. Daarvoor plakte hij met was een stuk van het touw vast aan de as. Het zakkende gewicht trok het was stilaan los. Als het touw eenmaal was losgekomen, begon de as weer te roteren. Je zou de instructies voor Herons robot kunnen uitschrijven met een eenvoudige programmeertaal, zoals de programmeertaal die (als een gratis alternatief) voor Lego® Mindstorms- robots werd ontwikkeld.
task main(){
OnFwd(OUT_A,75);
OnFwd(OUT_B,100);
Wait(3000);
}

Het automatische theater van Heronreed volkomen zelfstandig het podium van het theater op. Daar stopte het en toonde een toneelstuk van mechanische poppen, die eveneens door een mechanisme van pinnen, gewichten, touwen, assen, tandwielen en hefbomen werden aangedreven. Het theater was voorzien van decorwissels en geluidseffecten. Door op een bepaald moment een sleuf open te trekken vielen loden ballen op een trom, wat het geluid van donder simuleerde.
De ongeziene genialiteit die hij aan de dag legde bij het programmeren van zijn automatische theaters doet vermoeden dat ze slechts een stap waren in een lange traditie van programmeerbare machines. Dat blijkt ook uit zijn teksten. Heron klaagt er uitdrukkelijk over dat schrijvers die voor hem leefden niet duidelijk genoeg waren in hun boeken over automaten. Hij verwijst ook expliciet naar het thans verdwenen boek van Philo van Byzantiumover automatische theaters. Ook de werken van Aristoteles bevatten referenties aan automaten, en zelfs in de Ilias van Homeroslijken sommige passages automaten ter sprake te brengen.
Moderne software heeft met andere woorden oeroude wortels.
Het heeft er dus alle schijn van dat automaten een onafgebroken traditie van overerving kennen, startend bij Philo van Byzantium over Heron, via de Arabische ingenieur Al-Jazarien Leonardo da Vincinaar de programmeerbare weefgetouwen van Jacquard. Moderne software heeft met andere woorden oeroude wortels.
Kris Merckx - Uit het boek: "Niet van gisteren".
http://www.nietvangisteren.be
lorem ipsum

Je hoort het wel vaker. De computer kan geen âopen vragenâ interpreteren, âgesloten oefeningenâ wel. Een stuk software kan perfect kruiswoordraadsels, invuloefeningen, combinatie-oefeningen en dies meer verbeteren (nadat een gebruiker ze heeft ingevuld), maar open vragen zijn een ander paar mouwen. De computer weet niet veel raad met vragen als âWaarom probeerde België zich los te maken van Nederland in 1830 (en is het nog gelukt ook)?â
Natural Language Processing of NLPprobeert die taalkundige softwareproblemen op te lossen. Het kent al een lange ontwikkelingsgeschiedenis, maar heeft nog een hele weg af te leggen. We proberen in dit artikel uit te leggen hoe NLP-toepassingen zoals Google Translate werken. Misschien kijk je achteraf met ogen vol verwondering naar die gekke vertalingen die soms (vaak) wel eens opduiken in Google Translate. Geloof je me niet? Lees dan even verder en leer de grote struikelblokken van het softwarematig begrijpen van menselijke talen kennen.
Beeld je de volgende oefening in:
Op 6 ......................... vieren we de verjaardag van â¦...........................
Zie ginds komt de ......................... uit ............................ weer aan.
We kunnen een stuk software schrijven dat dit soort oefeningen perfect kan verbeteren. We schrijven het zo dat ook andere zinnen kunnen ingevoerd worden. Een docent/leraar zou op de volgende manier een oefening kunnen aanmaken die door de software automatisch wordt omgezet in een invuloefening:
Op 6 <antwoord>december</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas</antwoord>
De software weet dat hij alle woorden tussen de markering â<antwoord></antwoord>â moet verbergen. Bovendien kan hij zelf tellen hoeveel vragen er zijn. In de eerste zin moeten twee woorden worden ingevuld. De oefening staat dus op 2 punten. Maar hier duikt meteen een probleem op. Wat als de student/leerling i.p.v. december gewoon een 12 invoert, of i.p.v. Sinterklaas, âde sintâ? Dit kan je als docent toch onmogelijk fout rekenen?
Heel wat programma's lossen dit op door aan de persoon die de oefening samenstelt te vragen alle mogelijke antwoorden in te voeren. In ons geval zou het er dan als volgt kunnen uitzien:
Op 6 <antwoord>december/12</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas/de sint</antwoord>
De leraar voert hier alle mogelijke antwoorden in, telkens gescheiden door een schuine streep. Maar ook dan zijn de problemen niet helemaal van de baan. Want wat moet je als docent doen met een leerling met dyslexie die â demecberâ schrijft of â sntriklaasâ? Ook die antwoorden moeten goedgekeurd worden. Uiteraard niet voor iedereen, enkel voor leerlingen met een schrijf/taalprobleem. Het zou niet zinvol zijn om alle mogelijke schrijffouten vooraf in te voeren. Bovendien zouden leerlingen zonder taalproblemen dan rijkelijk beloond worden.
Vaak gaat men ervan uit dat software niet in de mogelijkheid zou verkeren om hier een echte oplossing voor te bieden. NLP of Natural Language Processing kan echter heel wat van deze beperkingen opvangen.

NLP combineert elementen uit de wetenschap, de taalkunde en het domein van Artificiële Intelligentie (AI). Twee belangrijke domeinen waarop NLP zich toespitst zijn
Alan Turinglegde de basis voor NLP met zijn beroemde Turingtestwaarbij een mens en een machine op afstand in vraag-antwoord-stijl met elkaar communiceren. Als de machine de mens kan overtuigen dat hij âeveneens een mensâ is, dan evenaart de machine in Turings ogen de menselijke intelligentie. De computer slaagt in de test als hij in meer dan 30% van de tijd voor een mens wordt aanzien.
Joseph Weizenbaum ontwikkelde tussen 1964 en 1966 ELIZA, de eerste beroemd geworden âchatbotâ. ELIZA simuleerde een psychotherapeut, een goed uitgangspunt om in vraag-antwoordstijl te werken. Omdat de kennis van ELIZA erg beperkt was, antwoordde de âchatbotâ vaak met open vragen zoals âWaarom zeg je dat je hoofdpijn hebt?â. De supercomputer Eugene Goostman slaagde in juni 2014 voor de test door het âbreinâ van een 13-jarige te simuleren.
Om een machine (computer, software...) taalte laten begrijpen, moet ze ook de betekenis van een tekst of zin kunnen achterhalen. Wanneer een kind taal leert, vertaalt het simultaan de werkelijkheid naar taal en omgekeerd. Een dorp bevat straten en huizen, een huis bevat kamers, kamers bevatten meubels enz. Woorden en begrippen hebben relaties en staan in verband met elkaar... Woorden en begrippen vormen netwerken, interfereren met elkaar enz. In hun hoofd vormen en herkennen kinderen stapsgewijs al die relaties en begrippenkaders... ze krijgen een beeld van de wereld en van de werkelijkheid: een ontologie. Vanaf de jaren 1970 zagen programmeurs in dat het nodig was om ook voor NLP zulke âontologieënâ te ontwikkelen. De ârelatiesâ en âbegrippenkadersâ uit de echte wereld moesten vertaald worden naar gegevens die door een computer konden begrepen worden. Voorbeelden van zulke âontologieënâ zijn ondermeer MARGIE, SAM en PAM... Ze leidden tot nieuwe chatbots zoals Parry en Jabberwacky.
Deze manier van werken had tot gevolg dat in de jaren 1980 de meeste NLP-systemen bestonden uit eindeloze reeksen regeltjes, tot verregaande schematisering van taal. Vanuit softwarecode gezien leidde dit tot eindeloze âif-elseâ-structuren. Je kent het wel: âAls (if) je braaf bent, krijg je een koekje, anders (else) een stokje.âIn de werkelijkheidzit er veel meer variatie. Het is mogelijk dat het kind anders altijd heel braaf is en nu één keertje stout. Neem je dan het vieruurtje af? In de werkelijkheid verloopt niet alles zwart (1) â wit (0), het is niet altijd zus of zo. Als je 4 tekorten hebt op je rapport is de kans groot dat je mama boos is, tenzij ze weet dat je heel erg je best hebt gedaan. In de echte wereld wegen we voortdurend af, volgen we niet altijd stricte regels, werken we volgens waarschijnlijkheden en statistische kansen.
Heel wat nieuwe NLP-systemen zouden zich gaan baseren op zulke statistische modellen. Die ârevolutieâ binnen de NLP-wereld was ook een gevolg van de beperkte rekenkracht van de toenmalige generatie computersystemen. Gokken ging nu eenmaal sneller en makkelijker dan eindeloze reeksen âifâ- en âelseâ-structuren te doorlopen. Ook de taaltheorieën van Noam Chomsky, de Amerikaanse taalkundige, die grammaticale gelijkenissen tussen talen zocht, eerder dan verschillen, vormden een rijke inspiratiebron.
Zulke statistische systemen werken veel beter in het geval van âonverwachte invoerâ van de gebruiker ( vb. sniterklaas i.p.v. Sinterklaas). In de echte wereld zijn afwijkingen en fouten immers niet ongewoon, integendeel. Vooral op het vlak van âvertalingenâ bieden de statistische technieken succes. Veel vertaalprogramma's die gebaseerd waren (en soms nog zijn) op woordenlijsten (een soort vertalende woordenboeken) liepen al snel tegen hun grenzen aan. Je kan immers geen zinnen vertalen door de individuele woorden te vertalen, maar door kleine brokjes data te vertalen en hieruit ook te âlerenâ. Statistische systemen zijn echter ook niet heiligmakend (denk aan Google Translate). Recent ligt de focus op een combinatie van beide technieken: de âharde regeltjesâ-weg en de statistische techniek.
Het mag duidelijk zijn dat we ondanks het aanvankelijke optimisme in de jaren 1960 nog een hele weg moeten afleggen vooraleer machines menselijke talen begrijpen en er mee kunnen communiceren. Toch staan de ontwikkelingen niet stil. Bereikt de machine dan echt âkunstmatige intelligentieâ zoals Alan Turing stelde? Vreemd genoeg verandert de betekenis van AI (arti f i c ial intelligence)bij elke nieuwe vooruitgang. Zo werd âschakenâ lange tijd als het toppunt van menselijke intelligentie gezien. Toen de IBM-computer Deep Bluede wereldkampioen schaken Garry Kasparov versloeg, verloor schaken plots veel van zijn allure. De volgende uitdaging kwam er aan: computers zouden nooit creatief kunnen antwoorden op âopenâ vraagstellingen. In 2010 ging IBM's supercomputer Watsonde uitdaging aan en won: hij versloeg met glans de âall-time-greatest human Jeopardy champions, Ken Jennings en Brad Rutterâ 1 . De Jeopardyquiz stelt open vragen over alle domeinen van de menselijke cultuur. De vragen bevatten tal van woordspelingen en hints, maar zelden een duidelijke vraagstelling.
Op tal van terreinen die vroeger als uniek voor de menselijke intelligentie werden gezien, steekt de machine zijn menselijke tegenspeler voorbij. Machines zullen nooit gevoelens hebben of bewustzijn. Maar wat betekent dit precies?
De hond slaapt in zijn mandje. Jacky is heel erg lief. Als ik thuis kom, komt hij al kwispelstaartend naar me toegelopen. Waar blijft hij vandaag? Weet jij het? Ik ben zo bang dat hij weggelopen is.
Als menselijke lezer snap je meteen waarover dit korte tekstje gaat. Hoe kunnen we een machine leren om deze tekst te begrijpen? Tussen mens en machine is er in dit geval al meteen een immens verschil. Een kind leert al snel een visueel beeld van een hond te koppelen aan het begrip âhondâ en de bijhorende geluiden. Denk maar aan de mama's en de papa's die vragen: âEn, hoe doetde hond? Nee, niet miauw.â Het taalmechanismein het hoofd van het kind koppelt aan de hond bepaalde acties zoals blaffen, lopen, kwispelstaarten, maar ook onderdelen zoals staart, poten, tong... Een heel kader, onderdeel van de âwereldontologieâ in het hoofd van het kind. Maar hoe vertalenwe die taalverwerking naar een computer? Oeps, dat is wat anders.
Laat ons eerst eens de tekst scheiden in zijn onderdelen: zinnen ( sentence breaking). Dat kan eenvoudig door te zoeken naar leestekens zoals punten, vraagtekens of uitroeptekens. Dit werkt perfect voor heel wat talen, maar niet voor pakweg Arabisch, Chinees of Japans, want daar is het gebruik van leestekens onbekend. Vervolgens kunnen we de zinnen splitsen in hun diverse woorden ( word segmentation), maar dat werkt al evenmin voor de genoemde talen: Arabisch kent bijvoorbeeld geen door spaties onderscheiden woorden. Daar bepaalt het uitzicht van een bepaald karakter (letter) of het gaat om het begin, het midden of het einde van een woord.
Zinnen bepalen of ze iets meedelen of eerder iets vragen (het vraagteken), en vragenop hun beurt kunnen open of gesloten (ja of neen, if of else, 1 of 0) zijn. De soort zinnen wordt bepaald door de âdiscourse analysisâ. De machine kijkt vervolgens naar de individuele woorden en probeert die te herleiden tot hun basis of stam in een proces dat âstemmingâ en âmorphological segmentationâ heet. In een taal als het Engels is dit een relatief eenvoudig proces:
openis de âstamâ van open, opens, opening, opened...
In talen zoals het Turks is dit een uiterst moeizame techniek. De stam is niet noodzakelijk hetzelfde als de morfologische âwortelâ van het woord. Meestal volstaat het dat verwante woorden dezelfde stam bevatten. Heel wat zoekmachines behandelen woorden met dezelfde stam als synoniemen om de zoekterm enigszins uit te breiden (conflatie). Googlegebruikt âstemmingâ sinds 2003. Voordien zou de zoekterm âvisâ niet âvissenâ of âgevistâ opgeleverd hebben.
Dit leidt soms tot foute resultaten. De machine kan teveel resultaten leveren (overstemming) zoals wanneer je âuniversiteitâ zoekt en ook âuniversumâ krijgt. In dit geval behandelt de machine beide woorden door hun gemeenschappelijke stam als synoniemen. In andere gevallen krijg je te weinig zoekresultaten (understemming).
Bij woorden zoekt het NLP-systeem niet alleen naar de stam, maar bovendien ook naar de woordsoort: gaat het om een adjectief of een zelfstandig naamwoord? Bovendien kunnen zelfstandige naamwoorden ook eigennamen zijn.
Jackyis een hond.
Deze techniek van ânamed entity recognitionâ werkt simpelweg door naar hoofdletters te kijken. Maar ook dit levert problemen op. Bij het begin van een zin schrijf je steevast een hoofdletter. In het Duits krijgen dan weer alle naamwoorden een hoofdletter.
Jackyist ein Hund.
En in het Engels schrijf je ook een hoofdletter als je het over jezelf hebt:
I, Iwanna be your dog.
De woordsoort wordt vaak bijgehouden in een soort lexicon, een soort lijst waarin op basis van de stam en eventuele voor- en achtervoegsels de woordsoort wordt bepaald ( Part-of-speech tagging). Maar eenvoudig is dit niet. Immers, afhankelijk van de zin kan een woord iets compleet anders betekenen:
Ik speel met de balop het bal.
Je merkt het al. De betekenis zit niet in het woord alleen, maar ook in zijn relatie met andere woorden: homoniemen (w ord sense disambiguation). De volgende zin klinkt afhankelijk van tegen wie (je docent) of wat (een eik) je het zegt helemaal anders, maar een NLP-systeem heeft het er moeilijk mee:
Je bent een eikel.
Via de techniek van â n atural language understandingâ probeert een NLP-systeem logica te vinden in korte fragmenten tekst. Welke adjectieven horen bij zelfstandige naamwoorden ( conference resolution)? Wat zijn de onderlinge relaties tussen objecten in een zin ( r elationship extraction)?
Op die manier probeert een NLP-systeem stilaan de zin te âparsenâ, een stamboom te maken van een zin en tenslotte van het hele verhaal.
âJe bent een eikel,âzei ik tegen de directeur .Ik was woedend.Hij werd door mijn uitspraak eveneens razend.
Deze zin verklapt hoe beide partijen zich voelen. Een NLP-systeem kan op basis van de betekenis van woorden en de frequentie waarmee ze voorkomen, raden wat het gevoel is dat uit een tekst spreekt: sentiment analysis . Je kan het zelf uittesten op https://semantria.com/.

Fouten laten herkennen door een machine vraagt geen âhogereâ intelligentie.

Een basisvoorbeeld van âtokenizationâ: van elk woord wordt bepaald of het alfabetisch, numeriek of symbolisch is:

Een voorbeeld van âtaggingâ waarbij van elk woord de woordsoort wordt opgegeven op basis van een âlexiconâ (een woordenlijst):
Tekstbegrip kan dan voor digitale systemen nog relatief moeilijk zijn, toch zijn steeds meer artikels niet meer door mensen geschreven. Google kocht Jetpac, een app die op basis van image recognition-algoritmes automatisch stadsgidsen genereert. Associated Press laat duizenden artikels schrijven door robotschrijvers. Betekent dit dat het einde van de âmenselijke journalistâ in zicht is? 1
Het onderstaande artikel werd door een robotjournalist geschreven:
Aerie Pharmaceuticals Inc. (AERI) on Tuesday reported a loss of $13.1 million in its third quarter. The Research Triangle Park, North Carolina-based company said it had a loss of 54 cents per share. Losses, adjusted for stock option expense, came to 44 cents per share.
Het artikel voldoet aan de vereisten voor dit soort artikels: het is correct en gedetailleerd. Uiteraard moet je je bij een robotjournalist niet een humanoïde robot voorstellen die op een toetsenbord teksten zit in te tikken. Het gaat om een stuk software dat ânatuurlijke taalâ produceert. Auteur van dienst is in dit geval WordSmithvan de softwareproducent Automated Insights. In 2013 produceerde WordSmith wereldwijd 300 miljoen nieuwsverslagen voor diverse klanten, meer dan alle âmenselijkeâ journalisten samen en vooral veel goedkoper...
Volgens Automated Insightskomen de jobs van echte journalisten niet in gevaar:
âWeâre producing articles that never would have existed in the first place,â he says. âAP was doing 300 corporate-earnings stories per quarter; theyâre now doing about 4,440. So 4,100 of these stories would not exist without Wordsmith.â
âThe computer handles the who, what, where and when, and humans are freed up to ask why and how.â
De LA Times zet Quakebot in om geautomatiseerd artikels af te leveren op basis van data van de US Geological Survey (aarbevingen). Inleving, gevoel, medelevenâ¦. zijn vreemd bij dit soort artikels, maar dat is voor "objectieve" verslaggeving ook niet nodig. âCreatief schrijven" ligt voorlopig nog buiten de mogelijkheden, want de algoritmes voeden zich met gestandaardiseerde informatie, een beetje te vergelijken met gestructureerde data in een rekenbladprogramma. Een van de mogelijke pistes om meer menselijke "warmte" in een tekst te steken is door de data aan te vullen met informatie geleverd door sensoren. Shazam is een bekend voorbeeld van een stuk software dat op basis van geluidsherkenning over 'semi-'menselijke intelligentie lijkt te beschikken. Googles Jetpac gaat in Instagramafbeeldingen op zoek naar "tags" die verwijzen naar menselijke ervaringen en cultuur. Op die manier zoekt en vindt Jetpac de leukste of hipste plaatsen.
Simon Colton is professor in "computational creativity" aan de Universiteit van Londen. Hij begeleidt het "What-If Machine"-project, een initiatief van de EU om de grenzen van softwarematige creativiteit af te tasten. Hij vertelt over die pogingen:
âTo me these projects [such as Wordsmith] are straightforward data visualisations. (â¦) Instead of pie charts and graphs they do words, and they miss various aspects needed for a good read. I tell people not to worry about their creative jobs being threatened by automation because of what I call âthe humanity gapâ. Even if software was good at wit, humour and writing style, it would not be human. If you want human insight, youâre not going to get it from a computer any time soon.â
Vaak hoor je dat Wikipedia-informatie onbetrouwbaar is. Nochtans zijn een massa artikels niet meer door menselijke auteurs afgeleverd maar door software-algoritmes. De meest bekende Wikibot luistert naar de naam Lsjbot, geprogrammeerd door de Zweed Sverker Johansson. Lsjbot schraapt informatie van betrouwbare bronnen en schrijft korte artikels over onderwerpen gerelateerd met dieren. Per dag levert de bot ongeveer 10 000 artikels af. In totaal zouden ongeveer 8.5% van de artikels van de (Zweedse) Wikipedia geschreven zijn door Lsjbot.
Wikipedia zette voor het eerst een bot in in 2002. Die "Rambot" leverde per dag duizenden artikels op over zo wat elk(e) dorp, stad of staat van de Verenigde Staten en ook van een aantal andere landen. Een robot onder de gepaste naam Asteroids schraapte data van de NASA en leverde artikels over⦠asteroïden. Op dit moment zijn er meer dan duizend verschillende Wikibots aan het werk: ze verbeteren teksten en tegenstrijdigheden⦠De meest actieve is Cydebot die meer dan 4.5 miljoen aanpassingen aanbracht. 2
Toch getuigt de techniek voor het geautomatiseerd schrijven van artikels niet altijd van âkunstmatige intelligentieâ. Quakebot gebruikt bijvoorbeeld door mensen opgestelde sjablonen en vult die met vooraf verzamelde en gestructureerd bewaarde data over aardbevingen. Het eindresultaat klinkt als een door mensen geschreven artikel, en dat is het voor een groot deel natuurlijk ook. Maar de robot doet in wezen niet veel meer dan het vullen van sjablonen met gestructureerde data. Andere ontwikkelaars, zoals Narrative Science proberen robotjournalisme naar een ander niveau te tillen. Zij pogen de software zelf te laten uitmaken waarover de data gaan en op basis daarvan âcontentâ te laten genereren. De software beslist in dit geval zelf hoe de inhoud moet klinken.
 In het volgende hoofdstuk behandelen we OCR, een techniek om een gescande of gekopieerde tekst (uit afbeeldingen dus) te converteren naar bewerkbare tekst. Dat is relatief gezien â
peanutsâ in vergelijking met NLP.
In het volgende hoofdstuk behandelen we OCR, een techniek om een gescande of gekopieerde tekst (uit afbeeldingen dus) te converteren naar bewerkbare tekst. Dat is relatief gezien â
peanutsâ in vergelijking met NLP.
Vooraleer machines vlekkeloos in menselijke talen kunnen communiceren, is er nog een hele weg af te leggen. Het draait niet enkel om de semantiek.In de Studio 100-reeks ROX praat de gelijknamige auto vlekkeloos met de andere (menselijke) personages. Hij herkent en interpreteert hun vragen en antwoorden en reageert er vaak laconiek op. Onze vriend âROXâ combineert het beste op het vlak van NLP met speech recognition, speech segmentationen speech processingen als kers op de taart natural language generation.
Het verstaan van gesproken taal (speech recognition) is nog een aardig stuk moeilijker dan het lezen of interpreteren van gedrukte tekst omdat er in gesproken tekst nauwelijks pauzes zijn tussen woorden. Ook letters vloeien onhoorbaar in elkaar over. Het verdelen van een uitspraakin afzonderlijke woorden (speech segmentation) is vreselijk moeilijk te programmeren. Natural language generation, het genereren van taal in geluidsvorm, is daarentegen al aardig ingeburgerd in bijvoorbeeld GPS-systemen. De software kan in dat geval gebruik maken van vooraf opgenomen geluid (afzonderlijke woorden of zinnen) dat het tot de gewenste zinnen samenvoegt. Dat is echter nog heel wat anders dan het kunstmatig âtoon per toonâ genereren van spraak (speech synthesis).
 In
machine translationkomen alle toeters en bellen van NLP-systemen en
natural language generationsamen. Zinvolle vertalingen laten gebeuren door een machine is dus allesbehalve evident. Het vraagt niet alleen begrip van beide talen, maar ook het betekenisvol begrijpen en converteren van het ene bekenissysteem (taal) naar het andere (een andere taal). Een voorbeeld: In het Chinees plaatst een spreker geen âtijdâ in zijn zin. Je kan dus niet aan de persoonsvorm zien wanneer de actie zich heeft afgespeeld. Tijd heeft in het Chinees geen belang wanneer je schrijft of spreekt, een volledig andere manier van âdenkenâ dan sprekers van Indo-Europese talen. Allesbehalve eenvoudig dus om te vertalen van pakweg het Chinees naar het Nederlands of omgekeerd. Denk dus zeker nog eens na wanneer mensen spotten met de vertalingen van bijvoorbeeld
Google Translate.
In
machine translationkomen alle toeters en bellen van NLP-systemen en
natural language generationsamen. Zinvolle vertalingen laten gebeuren door een machine is dus allesbehalve evident. Het vraagt niet alleen begrip van beide talen, maar ook het betekenisvol begrijpen en converteren van het ene bekenissysteem (taal) naar het andere (een andere taal). Een voorbeeld: In het Chinees plaatst een spreker geen âtijdâ in zijn zin. Je kan dus niet aan de persoonsvorm zien wanneer de actie zich heeft afgespeeld. Tijd heeft in het Chinees geen belang wanneer je schrijft of spreekt, een volledig andere manier van âdenkenâ dan sprekers van Indo-Europese talen. Allesbehalve eenvoudig dus om te vertalen van pakweg het Chinees naar het Nederlands of omgekeerd. Denk dus zeker nog eens na wanneer mensen spotten met de vertalingen van bijvoorbeeld
Google Translate.
Kris Merckx, 2015.
âRISE OF THE ROBOT JOURNALISTâ, ( http://www.slow-journalism.com/rise-of-the-robot-journalist), Geraadpleegd op 19 oktober 2015.
DUBE, R., "Could programs live Wiki bot ever produce all internet content?", (http://www.makeuseof.com/tag/could-wiki-bot-produce-all-content/), 2014, Geraadpleegd op 19 oktober 2015.
"Computer denkt voor het eerst als mens in Turing Testâ, http://www.automatiseringgids.nl/nieuws/2014/24/computer-denkt-voor-het-eerst-als-mens-in-turing-test, Geraadpleegd op 23 september 2014.
Bostrom, N. Superintelligence. Paths, dangers, strategies, Oxford, 2014.
 De Antwerpse wereldtentoonstelling van 1894 als ambigu spektakel van de moderniteit
De Antwerpse wereldtentoonstelling van 1894 als ambigu spektakel van de moderniteitIn de film The Matrix komt het hoofdpersonage vrij snel te weten dat de wereld waarin hij leeft niet echt is. Alles en iedereen blijkt gesimuleerd door een gigantische machine die de levensenergie van mensen benut als een soort serieel geschakelde biologische batterij. De menselijke ervaringen blijken het resultaat van ingenieuze software die data invoert in de hersenen van de miljoenen aan de machine gekoppelde mensen. De Britse computerwetenschapper Nick Bostrom heeft die simulatiehypothese op levensvatbaarheid getest. Hij heeft een reeks voorwaarden uitgeschreven om na te gaan of zo'n digitale onderdompeling inderdaad mogelijk is of niet reeds het geval is. Immersieve technieken zijn in de digitale wereld alomtegenwoordig.
1
Computersimulaties, 3D-games, virtual reality, augmented reality, MMORPG's⦠gelden als de belangrijkste vormen van immersieve technieken waarbij de grenzen tussen de werkelijkheid en de digitale representatie vervagen.
2
In het artikel
A
historical
comparison
between
world
exhibitions
and
the
webvergelijkt Berteke Waaldijk
3
de overeenkomsten tussen wereldtentoonstellingen in de negentiende eeuw en digitale representaties op het web en in games. Volgens Waaldijk schakel(d)en de bezoekers in beide immersieve omgevingen voortdurend heen en weer tussen immersie en persoonlijke controle. De keuzevrijheid van de bezoeker staat centraal in deze visie. In hun artikel over de Antwerpse wereldtentoonstelling van 1894 benadrukken Bram Van Oostveldt en Stijn Bussels het
spanningsveld
tussen
vervreemding
en
spektake
l.
4
Vanuit dit standpunt heeft de â
moderniteit
iedere
vorm
van
authentiek
leven
vervangen
door
een
constante
stroom
van
beeldenâ.
5
Volgens de klassieke marxistische geschiedschrijving is vervreemding een proces waarbij de mens geen invloed of controle kan uitoefenen op de (of op zijn) ontwikkeling. Zo'n proces veronderstelt dat er ooit iets heeft bestaan als een niet-vervreemde toestand, een situatie in het verleden waarin de burger niet vervreemd was van zijn eigen arbeid. De representatie van Oud-Antwerpen toonde die
idealeniet-vervreemde toestand en bood een â
welbehagen
dat
voor
een
belangrijk
deel
(lag)
in
het
verdoezelen
van
negentiende-eeuwse
sociale
spanninge
nâ.
6
De moderniteit was een breukervaring en de continuïteit van tradities die Oud-Antwerpen representeerde, moest de vervreemding ten opzichte van diezelfde tradities bezweren. De tentoonstelling en de diverse representaties verschaften volgens de auteurs aan de bezoekers de illusie dat ze weerstand konden bieden aan het geweld van de moderniteit. Door de strategieën van immersie zouden de bezoekers zich â
volledig
opgenome
nâ wanen â
in
het
gerepresenteerd
eâ.
7
 Waaldijk treedt die stelling van aliënatie niet bij. Vervreemding veronderstelt immers een ontkoppeling van een oorspronkelijke essentie. De overeenkomsten tussen de vormen van immersie bij wereldtentoonstellingen en bij moderne digitale technieken doen nog meer vragen rijzen over het concept van vervreemding dat Van Oostveldt en Bussels aanhangen. Zoals Thomas Decreus het terecht stelt â
als
die
essentie
wegvalt,
verdwijnt
ook
de
maatstaf
om
het
vervreemde
van
het
authentieke
te
onderscheiden
en
worden
beide
noties
nietszeggen
dâ.
8
Een moderne gamer die opgroeit met immersieve speltechnieken en bijvoorbeeld opgaat in een spel over de middeleeuwen, voelt zich niet vervreemd van die
authentieketoestand. Vervreemding veronderstelt immers een vorm van gemis. Het onderdompelen in een representatie blijft bovendien niet beperkt tot de immersie tijdens wereldtentoonstellingen of in digitale omgevingen. Een lezer van een boek kan evenzeer opgaan in het
Waaldijk treedt die stelling van aliënatie niet bij. Vervreemding veronderstelt immers een ontkoppeling van een oorspronkelijke essentie. De overeenkomsten tussen de vormen van immersie bij wereldtentoonstellingen en bij moderne digitale technieken doen nog meer vragen rijzen over het concept van vervreemding dat Van Oostveldt en Bussels aanhangen. Zoals Thomas Decreus het terecht stelt â
als
die
essentie
wegvalt,
verdwijnt
ook
de
maatstaf
om
het
vervreemde
van
het
authentieke
te
onderscheiden
en
worden
beide
noties
nietszeggen
dâ.
8
Een moderne gamer die opgroeit met immersieve speltechnieken en bijvoorbeeld opgaat in een spel over de middeleeuwen, voelt zich niet vervreemd van die
authentieketoestand. Vervreemding veronderstelt immers een vorm van gemis. Het onderdompelen in een representatie blijft bovendien niet beperkt tot de immersie tijdens wereldtentoonstellingen of in digitale omgevingen. Een lezer van een boek kan evenzeer opgaan in het
verhaal. Net zoals in digitale omgevingen waren de bezoekers van wereldtentoonstellingen zowel verbaasd door de technische hoogstandjes als door datgene dat gerepresenteerd werd/wordt. Bezoekers schakelen snel heen en weer tussen immersie (immersion) en afstand nemen (distancing). 9 In een computergame is de bezoeker ondergedompeld in zijn rol van held op zoek naar overwinning en succes. Maar simultaan is hij zich ook bewust van de regels van het spel en de strategieën die de ontwikkelaar heeft geprogrammeerd. Gamers schakelen bliksemsnel heen en weer tussen immersie en distancing. Ze beschikken over vrijheid en controle.
De geschiedkundige vergelijking tussen het web en wereldtentoonstellingen maakt het mogelijk een beter inzicht te krijgen in de relatie tussen beide bewustzijnsvormen.
10
Websitebezoekers volgen niet slaafs de commerciële belangen van de ondernemers achter de toepassingen. Hyperlinks maken het mogelijk voortdurend keuzes te maken, afstand te nemen. Volgens Waaldijk beschikte de bezoeker van een wereldtentoonstelling net zoals een hedendaagse websitebezoeker over de vrijheid om te kiezen tussen wat hij (en ook
zijzoals meteen blijkt) zelf belangrijk vond.
 Volgens Hobsbawm waren wereldtentoonstellingen een van de eerste vormen van massatoerisme.
11
Anders dan bij een lm of theatervoorstelling was een bezoek aan een wereldtentoonstelling geen lineaire ervaring. De bezoeker kon schakelen tussen de meerdere representaties, maakte zijn eigen keuzes net zoals bij hypertekst op het web. Waaldijk stelt dat bezoekers van wereldtentoonstellingen dankbaar en veelvuldig van die vrijheid gebruik maakten.
12
Ze gaven anderen advies bij het maken van hun keuze. Het doel was niet enkel de bezoeker onder te dompelen. Minstens even belangrijk waren puur vermaak en zelfs educatie. Commercie was een essentieel onderdeel van een wereldtentoonstelling, net zoals dat nu het geval is bij websites, maar was niet de enige dimensie. De gebruikers schakelden heen en weer tussen hun rol van
vrijeburger en die van
vrije
consumen
t. Op een wereldtentoonstelling kreeg een bezoeker een beeld van waar zijn producten vandaan kwamen. Lauren Rabinovitz ziet wereldtentoonstellingen als de eerste publieke plaatsen waar vrouwen konden kiezen, kijken en inspecteren. De nieuwe rol van de vrouw als consument in de entertainmentindustrie vormde op die manier een cruciale stap in de emancipatie.
13
Volgens Hobsbawm waren wereldtentoonstellingen een van de eerste vormen van massatoerisme.
11
Anders dan bij een lm of theatervoorstelling was een bezoek aan een wereldtentoonstelling geen lineaire ervaring. De bezoeker kon schakelen tussen de meerdere representaties, maakte zijn eigen keuzes net zoals bij hypertekst op het web. Waaldijk stelt dat bezoekers van wereldtentoonstellingen dankbaar en veelvuldig van die vrijheid gebruik maakten.
12
Ze gaven anderen advies bij het maken van hun keuze. Het doel was niet enkel de bezoeker onder te dompelen. Minstens even belangrijk waren puur vermaak en zelfs educatie. Commercie was een essentieel onderdeel van een wereldtentoonstelling, net zoals dat nu het geval is bij websites, maar was niet de enige dimensie. De gebruikers schakelden heen en weer tussen hun rol van
vrijeburger en die van
vrije
consumen
t. Op een wereldtentoonstelling kreeg een bezoeker een beeld van waar zijn producten vandaan kwamen. Lauren Rabinovitz ziet wereldtentoonstellingen als de eerste publieke plaatsen waar vrouwen konden kiezen, kijken en inspecteren. De nieuwe rol van de vrouw als consument in de entertainmentindustrie vormde op die manier een cruciale stap in de emancipatie.
13
De overvloed van indrukken wekte verwarring op en dompelde de bezoeker onder, maar toonde paradoxaal genoeg eveneens een gevoel van afstand en controle. De bezoeker had de vrijheid om keuzes te maken. De bezoeker was geen willoos vervreemd element in een gesimuleerde omgeving, maar had een gevoel van controlevrijheid waar hij ook dankbaar gebruik van maakte.
1. BOSTROM, N., S u p e rin t e lli g e n c e : P a t h s , D a n g e r s , S t r a t e g i e s, Oxford, 2014.
2. MERCKX, K., Au g m e n t e d r e a li t y . C o m b in ee r d e v ir t u e l e m e t d e e c h t e w e r e l d, Amsterdam, 2011.
3. WAALDIJK, B. T h e d e s i g n o f w o r l d c i t i z e n s hi p . A hi s t o ri c a l c o m p a r i s o n b e t w ee n w o rl d e x hi b i t i o n s a n d t h e w e b(Digital material. Tracing new media in everyday life and technology), Amsterdam, 2009.
5. ibid., 6.
6. ibid., 16.
7. bid., 6.
8. DECREUS, T., P o s t - m a r x i s m e e n v e r v r ee m d in g .
11. Ibid., 114.
12. Ibid., 115.
13. Ibid., 115.
14. Ibid., 116.
15. Ibid., 117.
BOSTROM, N., S u p e rin t e lli g e n c e : P a t h s , D a n g e r s , S t r a t e g i e s, Oxford, 2014.
DECREUS, T.,
P
o
s
t
-
m
a
r
x
i
s
m
e
e
n
v
e
r
v
r
ee
m
d
in
g
:
ee
n
o
n
m
og
e
lij
k
e
c
o
m
b
in
a
t
i
e
?(https://thomasdecreus.wordpress.com/2013/10/25/post-marxisme-en-vervreemding-een-onmogelijke-combinatie/), Geraadpleegd op 4 januari 2016.
WAALDIJK, B.
T
h
e
d
e
s
i
g
n
o
f
w
o
rl
d
c
i
t
i
z
e
n
s
hi
p
.
A
hi
s
t
o
ri
c
a
l
c
o
m
p
a
ri
s
o
n
b
e
t
w
ee
n
w
o
rl
d
e
x
hi
b
i
t
i
o
n
s
a
n
d
t
h
e
w
e
b(Digital material. Tracing new media in everyday life and technology), Amsterdam, 2009.
Een computer kan met behulp van software een heleboel taken automatiseren om de mens werk uit handen te nemen en vooral de benodigde (werk)tijd te verkorten. Toch beseffen velen nog steeds niet hoe ze dat precies moeten doen. De zoek-en-vervangopdracht in een tekstverwerkingsprogramma is daar een simpel voorbeeld van. In heel wat software kunnen steeds weerkerende taken met behulp van zogenaamde macroâs geautomatiseerd worden. Je voert een aantal taken uit terwijl de computer de uitgevoerde opdrachten stapsgewijs registreert. Nadien kan hij zelfstandig die taak herhalen. De lijst met instructies is vastgelegd in het geheugen van de computer. In automaten zitten de instructies eveneens in de machine.
Tijdens mijn lessen steek ik mijn bewondering voor Leonardo da Vinciniet onder stoelen of banken. Elke kans die zich voordoet om het over hem te hebben neem ik te baat. Iedereen kent Leonardo, al was het maar omdat hij de beroemde Mona Lisa heeft geschilderd.
 Leonardo da Vinci was niet alleen schilder, maar ook ingenieur en beeldhouwer. Hij las gretig de vertalingen van Heron en Vitruvius, en bestudeerde de verschillende onderdelen van de machines. Hij noemde ze de âelementenâ of âorganenâ van de machines. Door die onderdelen op allerlei manieren te combineren kon je in zijn ogen een oneindig aantal machines bedenken en bouwen. Wanneer je de werken van Da Vinci bekijkt, doen ze vaak denken aan de handleidingen uit dozen Lego® Technics. In zijn teksten beschreef hij welke soorten schroeven, tandwielen, vliegwielen, kogellagers, kettingen, veren, katrollen enzovoort er bestaan en hoe je ze maakt. Hij voorzag zijn teksten van uitgebreide technische tekeningen in perspectief. Zelf ontwierp hij een hele reeks machines: oorlogstuig zoals mortieren en tanks, baggerschepen, vliegtuigen, een helikopter, een duikpak, een hydraulische zaag ... Hij observeerde ook nauwlettend de vlucht van vogels en de werking van hun vleugels en veren. Leonardo ontwierp op basis daarvan tal van (zweef)vliegtuigen, die hij zelfs voorzag van schokdempers om bij de landing het âvliegtuigâ niet te beschadigen. Velen denken dat hij prototypes van die geniale vondsten zelf heeft uitgetest. Toch is het grootste deel van zijn uitvindingen nooit in praktijk gebracht. Een van de meest verbazingwekkende afbeeldingen uit de beschrijvingen van Leonardo da Vinci is die van een fiets. De fiets zoals we hem nu kennen, werd pas uitgevonden aan het einde van de 19e eeuw.
Leonardo da Vinci was niet alleen schilder, maar ook ingenieur en beeldhouwer. Hij las gretig de vertalingen van Heron en Vitruvius, en bestudeerde de verschillende onderdelen van de machines. Hij noemde ze de âelementenâ of âorganenâ van de machines. Door die onderdelen op allerlei manieren te combineren kon je in zijn ogen een oneindig aantal machines bedenken en bouwen. Wanneer je de werken van Da Vinci bekijkt, doen ze vaak denken aan de handleidingen uit dozen Lego® Technics. In zijn teksten beschreef hij welke soorten schroeven, tandwielen, vliegwielen, kogellagers, kettingen, veren, katrollen enzovoort er bestaan en hoe je ze maakt. Hij voorzag zijn teksten van uitgebreide technische tekeningen in perspectief. Zelf ontwierp hij een hele reeks machines: oorlogstuig zoals mortieren en tanks, baggerschepen, vliegtuigen, een helikopter, een duikpak, een hydraulische zaag ... Hij observeerde ook nauwlettend de vlucht van vogels en de werking van hun vleugels en veren. Leonardo ontwierp op basis daarvan tal van (zweef)vliegtuigen, die hij zelfs voorzag van schokdempers om bij de landing het âvliegtuigâ niet te beschadigen. Velen denken dat hij prototypes van die geniale vondsten zelf heeft uitgetest. Toch is het grootste deel van zijn uitvindingen nooit in praktijk gebracht. Een van de meest verbazingwekkende afbeeldingen uit de beschrijvingen van Leonardo da Vinci is die van een fiets. De fiets zoals we hem nu kennen, werd pas uitgevonden aan het einde van de 19e eeuw.
In de Codex Atlanticus, een bundel tekeningen en teksten van Leonardo die vervaardigd zijn tussen 1479 en 1519, âstaatâ echter een tekening van een fiets met spaken, tandwiel, ketting, stuur enzovoort. Dit zou betekenen dat de fiets niet in Frankrijk of Duitsland werd uitgevonden, maar driehonderd jaar eerder in ItalieÌ, door de uitvinder aller uitvinders: Leonardo da Vinci. Recent onderzoek zou echter aantonen dat de fiets helemaal niet door Leonardo of een van zijn leerlingen werd getekend, maar pas veel later bij de restauratie van de âtekstenâ is toegevoegd. Oorspronkelijk stonden er wel een aantal onderdelen van een voertuig dat sterk op een fiets lijkt, maar geen frame. Het is niet duidelijk wie de vervalsing heeft gemaakt. Sommige Leonardo- specialisten blijven echter vast geloven in de echtheid van het ontwerp.
In 1550 schreef Giorgio Vasari (1511â1574) in zijn boek over het leven van de belangrijkste Italiaanse kunstenaars:
âToen Leonardo da Vinci in Milaan was, kwam de koning van Frankrijk op bezoek. Hij vroeg hem iets speciaals te doen. Da Vinci ging aan de slag en presenteerde hem een leeuw die een paar stapjes zette en zijn borstkas opende, waar tal van lelies uit tevoorschijn kwamen.â
De Amerikaanse robotexpert Mark Rosheim bestudeerde de Codex Atlanticus van Da Vinci in de hoop sporen te vinden van die robotleeuw. Hij is ervan overtuigd dat Da Vinci de leeuw op een mechanisch programmeerbaar wagentje had geiÌnstalleerd. Een veermechanisme deed wielen draaien, die op hun beurt kleinere wielen in beweging zetten. Die stuurden houten armen aan, waaraan een soort schaarmechanisme was bevestigd. Door de armen volgens een vastgelegd plan te laten bewegen kon het karretje rijden en ook draaien.

Leonardo was niet de enige die vruchtbaar gebruikmaakte van de kennis van automaten die via vertalingen van klassieke en hellenistische werken doorsijpelde. AbuÌ al-âIz Ibn IsmaÌâiÌl ibn al-RazaÌz al-JazariÌof kortweg Al-Jazari voor de vrienden (1136â1206) werd genoemd naar zijn geboorteplaats Al-Jazira (tussen Tigris en Eufraat). Hij werkte als astronoom, wetenschapper, wiskundige en ingenieur aan het paleis van Diyarbakır, die heerste over Oost-AnatolieÌ. Over het leven van Al-Jazari is niet veel bekend, maar gelukkig bleef zijn KitaÌb fiÌ maârifat al-hiyal al-handasiyya(Het boek der kennis van ingenieuze mechanische apparaten) bewaard. Het bestaat uit een zestal hoofdstukken die handelen over mechanica en techniek: water- en tijdkaarsen, apparaten die trucs verrichten, hydraulische automaten en meetinstrumenten, fonteinen, muziekautomaten, hijsmachines enzovoort. Al-Jazari was duidelijk op de hoogte van de vondsten en mechanische onderdelen van de hellenistische technici. Hij vermeldde de krukas, het echappement, de waterhijsmachines, de dubbele pomp ... Het is niet altijd duidelijk in welke mate hij zelf aanpassingen heeft aangebracht. In zijn werk vinden we ook beschrijvingen van gesegmenteerde versnellingen, tijdkaarsen en klokken die met gewichten en waterkracht werden aangedreven. Zijn bekende olifantenklok lijkt de voorloper van onze koekoeksklok.
Afbeelding: 18e eeuwse automaat
 De eerste die een soortgelijk programmeerbaar systeem inzette voor industrieel gebruik was de Fransman
Joseph Marie Jacquard(1752â1834). Hij ontwierp in 1801 een weefgetouw dat werd aangestuurd door ponskaarten. Hij baseerde zich voor zijn werk op de eerdere uitvindingen van onder anderen
Basile Bouchon, Jacques Vaucanson en Jean Falcon.
De eerste die een soortgelijk programmeerbaar systeem inzette voor industrieel gebruik was de Fransman
Joseph Marie Jacquard(1752â1834). Hij ontwierp in 1801 een weefgetouw dat werd aangestuurd door ponskaarten. Hij baseerde zich voor zijn werk op de eerdere uitvindingen van onder anderen
Basile Bouchon, Jacques Vaucanson en Jean Falcon. Basile Bouchon, zoon van een orgelbouwer, bedacht al in 1725 een manier om een weefgetouw aan te sturen met een geperforeerde rol papier. Bouchons vader maakte cilinders met pinnen voor orgels. Om de pinnen op de juiste plaatsen aan te brengen in de cilinder, tekende hij eerst een patroon op een kartonnen plaat. Die plaat draaide hij vervolgens om de cilinder waardoor hij precies wist waar hij de pinnen in de cilinder moest slaan. Basile meende dat het handiger zou zijn de kartonnen platen zelf te gebruiken. Het was Jacquard die het systeem als eerste succesvol wist te implementeren.
 Het
ponskaartsysteemzien we in de 19e eeuw ook opduiken in muziekdozen en pianolaâs. Ponskaarten werkten op een vergelijkbare manier als pin- of kamsystemen. In het geval van muziekdozen kon door de gaatjes lucht van een blaasbalg ontsnappen of er konden pinnetjes door schieten die instructies gaven aan de rest van het mechanisme. Bij Jacquard sprongen pinnen op door de openingen in de ponskaarten en lieten het weefgetouw een bepaald patroon weven. Het grootste voordeel van een ponssysteem was dat je veel meer instructies achter elkaar kon laten uitvoeren door de machine. Bij een cilindersysteem met pinnen of kammen was je beperkt door de omtrek van de cilinder. Ponsplaten kon je oprollen of opvouwen en door het mechanisme laten schuiven bij het uitvoeren van het programma. De wevers van Lyon vreesden voor hun werk en verbrandden het weefgetouw in 1808, zo vertelt het verhaal. Blind protest tegen een niet te stuiten innovatie. Maar dit verhaal klopt niet. Van die brand is helemaal geen sprake geweest. Het verhaal duikt voor het eerst op aanvang 19e eeuw.
Het
ponskaartsysteemzien we in de 19e eeuw ook opduiken in muziekdozen en pianolaâs. Ponskaarten werkten op een vergelijkbare manier als pin- of kamsystemen. In het geval van muziekdozen kon door de gaatjes lucht van een blaasbalg ontsnappen of er konden pinnetjes door schieten die instructies gaven aan de rest van het mechanisme. Bij Jacquard sprongen pinnen op door de openingen in de ponskaarten en lieten het weefgetouw een bepaald patroon weven. Het grootste voordeel van een ponssysteem was dat je veel meer instructies achter elkaar kon laten uitvoeren door de machine. Bij een cilindersysteem met pinnen of kammen was je beperkt door de omtrek van de cilinder. Ponsplaten kon je oprollen of opvouwen en door het mechanisme laten schuiven bij het uitvoeren van het programma. De wevers van Lyon vreesden voor hun werk en verbrandden het weefgetouw in 1808, zo vertelt het verhaal. Blind protest tegen een niet te stuiten innovatie. Maar dit verhaal klopt niet. Van die brand is helemaal geen sprake geweest. Het verhaal duikt voor het eerst op aanvang 19e eeuw. Al snel zag men ook op andere vlakken van de samenleving het nut van een ponskaartsysteem. Je kon op een ponskaart allerlei soorten informatie in gecodeerde vorm opslaan en het geautomatiseerd laten uitlezen. Charles Babbage(1791â 1871) tekende plannen voor een analytische rekenmachine en voorzag de invoer van ponskaarten. Zijn plannen betekenden een serieuze stap voorwaarts in de ontwikkeling van een rekenmachine. Eerder bouwde de Fransman Blaise Pascal (1623â1662) een mechanische rekenmachine, maar die was nooit een succes geworden. Ook de machine van Babbage kwam niet veel verder dan de ontwerptafel.
Kris Merckx - Uit het boek "Niet van gisteren", http://www.nietvangisteren.be
Tijdens deze lessenreeks ontwikkel je het prototype van de interface van een softwareservice. Dat is een mond vol :-). Een interface is de "laag" waarmee een computersysteem communiceert met de "buitenwereld". Dit kan een temperatuursensor of microfoon zijn, maar ook een scherm of muis. In onze lessen ligt de focus op de interactie tussen mens en "machine" (een USER INTERFACE).
De diverse interfaces voor "human machine interaction" komen aan bod. De hele geschiedenis van interfaces passeert de revue: CLI, GUI, NUI, AR, VR...
Je vormt een groep. De lector geeft je een opdracht ( https://www.schoolvoorbeeld.be/nodig/ui-opdrachten.pdf ). Overleg hoe je dit wil aanpassen. Begin met een brainstorm. Zet je ideeën op papier.
Nadat je feedback hebt gekregen van de lectoren, kan je starten met het ontwerpen van de USER INTERFACE voor je applicatie. Hiervoor kan je gebruik maken van Adobe XD. Dat programma kan je gratis downloaden.
Waar moet je rekening mee houden als je een "USER INTERFACE" bouwt? Waar moet je op letten? Storytelling: gebruik herkenbaarheid en storytelling bij een pitch.
Waar moet je rekening mee houden bij UX-design? Bekijk de presentatie op Presentatie "Soorten interfaces & UX-design" én lees zeker het bijhorende hoofdstuk in de cursus (Lees zeker het volledige deel over UI- en UX-design/interfaces in https://www.schoolvoorbeeld.be/nodig/smartboek.pdf).
Film over "huisstijl" en UX-design: heb je nog te goed (uitleg over huisstijlen, lettertypes, logo-ontwerp, kleurpaletten, UX-design...)
Op zoek naar een handige tool voor het bouwen van "mockups" en/of interfaces? Pencil is een gratis en open source tool met een massa mogelijkheden. Adobe XD komt uit de stal van Photoshop. Het heeft een heel uitgebreide toolset voor het bouwen van een interface-prototype en heeft ook heel wat presentatiemogelijkheden.
Installeer Adobe XD en/of Pencil voor het uitvoeren van de opdracht rond interface-ontwerp.
"Pencil is built for the purpose of providing a free and open-source GUI prototyping tool that people can easily install and use to create mockups in popular desktop platforms."
Andere (commerciële) tools:
Mijn persoonlijke website: www.ardeco.be
De website bij het boek Niet van Gisteren: www.nietvangisteren.be
Linkedin: https://www.linkedin.com/in/kris-merckx-3a791b36/
Een overzicht van mijn uitgaven: http://www.schoolvoorbeeld.be/boeken/
Als je programmeert, moet je je de taal van de computer eigen maken... binaire code. Dat is niet evident! Daarom zijn er tussenliggende programmeertalen ontwikkeld die voldoende duidelijk zijn voor de mens, maar ook voor de machine.
Presentatie van deze lesTijdens de lessen gebruiken we de teksteditor Brackets en het FTP-programma Cyberduck.

Een website bouw je in HTML. HTML is geen programmeertaal. Je bepaalt ermee welke onderdelen je webpagina bevat: titels, alinea's... Met HTML kan je ook links leggen naar andere pagina's en bestanden.
Start met HTML

Op een website worden inhoud en opmaak in afzonderlijke bestanden opgeslagen.
Waarom zo ingewikkeld doen?
Wel, het maakt het werk er een pak eenvoudiger op...
Cascading Style Sheets... webpagina's maak je op met een afzonderlijk bestand, een CSS-bestand. Hierin bepaal je hoe de webpagina-elementen er moeten uitzien. Het grootste voordeel is dat al die stijlkenmerken in een apart bestand worden bewaard. Als je dit bestand wijzigt, verandert automatisch de opmaak van alle daaraan gekoppelde webpagina's.

Wie een website publiceert, wil natuurlijk dat zijn site goed gevonden wordt door de zoekmachines. Hoe optimaliseer je je website voor zoekmachines en sociale mediasites?
SEO gaat niet over het manipuleren van de zoekresultaten. Het is het structureren en groeperen van informatie op zoân manier dat het voor de zoekmachines duidelijk is waarover je website gaat. SEO is geen zoekmachine-spam. Het kunstmatig manipuleren van de zoekmachines is niet alleen geen duurzame aanpak, het zal ook niet resulteren in conversies. En dat is uiteindelijk waarover het gaat. (Bron: https://wijs.be/nl/diensten/traffic-en-conversieoptimalisatie/seo)
Het begrip SEO staat voor âSearch Engine Optimizationâ . Het is niet één bepaalde techniek, maar een geheel van manieren om je webpagina's beter toegankelijk te maken voor zoekmachines. De nummer één van de zoekmachines blijft Google. Als je je webpagina's gestructureerd opbouwt, met keurige en semantische HTML, dan zal Google beter begrijpen waarover je pagina gaat.
Zo is een <article> voor Google duidelijker dan wanneer je voor hetzelfde onderdeel een <div>-element zou gebruiken. Het HTML-element article vertelt immers al dat het gaat om een "artikel" (dat kan natuurijk zowel een nieuwsbericht als een winkelartikel zijn).
Een zoekrobot zoekt niet op het moment dat jij iets zoekt op internet. Google stuurt "zoekrobots" uit die voortdurend nieuwe of bestaande webpagina's "lezen" en indexeren. Zoekrobots zijn stukjes software die de HTML-code van webpagina's uitlezen en proberen uit te vissen waarover de inhoud gaat. Met SEO-data kan je het werk van een zoekrobot vergemakkelijken.
Naast het proberen begrijpen van de inhoud van een webpagina, gaat een zoekrobot in de HTML-code ook op zoek naar "links". Als de robot een link vindt, dan zal de zoekrobot ook die link gaan verkennen. Op die manier "indexeert" Google voortdurend het world wide web.
Wanneer jij iets zoekt in Google, dan tovert Google voor jou resultaten op uit die gigantische inhoudstafel die in een enorme databank is opgeslagen. De zoekmachine bouwt op dat moment bliksemsnel een HTML-pagina met (hopelijk relevante) zoekresultaten.
Metatags stop je in het <head>-gedeelte van je webpagina. Belangrijk is vooral het geven van een zinvolle "title" aan je webpagina.
Een foute "title":
<title>Welkom op mijn site</title>
De title vertelt best iets over het onderwerp van je site, over de inhoud van de betrokken pagina, en misschien is het ook zinvol om er de locatie in te vermelden:
<title>Restaurant Belgische Keuken - Parijsstraat Leuven</title>
Een tweede bijzonder belangrijk onderdeel is de "omschrijving/beschrijving". Naast de title komt die "description" in de zoekresultaten van Google terecht. Bekijk het onderstaande voorbeeld. De "blauwe" title is gebaseerde op de <title> van de betrokken webpagina. De "zwarte" tekst die Google toont is (over het algemeen) gebaseerd op de meta-tag "description".

Op https://webcode.tools/meta-tags-generator kan je geautomatiseerd metatags aanmaken voor elk van je webpagina's.
Open Graph is bedacht door Facebook in 2010. Dit werd gedaan om een betere integratie tussen websites en Facebook te bewerkstelligen. In de praktijk kwam het er op neer dat links van websites die gepost werden op Facebook zogenoemde ârich graphsâ konden worden. Een andere uitleg is dat je als website hiermee een zekere mate van controle krijgt op hoe je er op Facebook uit ziet.âMaak geautomatiseerd OG-tags aan voor al je webpagina's op https://webcode.tools/open-graph-generator.
Een voorbeeld. Als iemand een link van een website plaatst in zijn of haar status op Facebook dan verschijnt er automatisch een soort kaartje. Vaak zie je hierin een afbeelding, een titel, een omschrijving en een link. Ook bij LinkedIn, Google+ en Twitter gebeurt dit. Deze gegevens kun je zelf beïnvloeden en min of meer âdicterenâ aan sociale netwerken. Kortom: je kunt het âkaartjeâ zelf invullen.
(Bron: http://www.42bis.nl/2015/02/facebooks-open-graph-wat-het-en-wat-kun-je-er-mee/)
Sociale media gaan niet "actief" op zoek naar webinhouden zoals zoekmachines dit doen. Open Graph-tags zijn echter belangrijk wanneer iemand een webpagina of link deelt op sociale media. Dankzij OG-tags, kan de webontwikkelaar bepalen welke tekstjes, titels en foto's moeten verschijnen, als iemand een webpagina of webinhoud deelt.
Google gooit sites die niet of moeilijk mobiel toegankelijk zijn, achteruit in de zoekresultaten. Je hebt er dus alle belang bij je site "responsive" te maken. Om dit proces te vereenvoudigen, kan je gebruik maken van een CSS-framework dat je het grootste deel van dit werk uit handen neemt.
Tijdens de lessen gebruiken we hiervoor cssbib.css ( https://www.schoolvoorbeeld.be/css/cssbib.css), dat deels gebaseerd is op skeleton.css ( http://getskeleton.com/), maar met een hele reeks uitbreidingen.
Daarnaast moet je een afzonderlijke regel toevoegen aan je webpagina die je site mobiel-gebruiksvriendelijk maakt. Voeg de volgende regel toe aan de <head>-sectie van je pagina:
<meta name="viewport" content="width=device-width, initial-scale=1.0">
Met JSON-LD voeg je gestructureerde gegevens toe aan je pagina. Die informatie is niet zichtbaar voor de eindgebruiker, tenzij hij/zij de broncode van de pagina bestudeert. Zoekmachines zoals Google, begrijpen dankzij JSON-LD echter veel beter waarover de inhoud van je pagina gaat. Uiteraard moeten de JSON-LD-gegevens ook effectief overeenkomen met de werkelijke (zichtbare) inhoud van je pagina.
Een voorbeeld:
<script type="application/ld+json"> {
"@context": "http://schema.org/",
"@type": "Event",
"name": "Rock Werchter", "description": "Het bekendste Belgische rockfestival.",
"startDate": "2018/30/06",
"endDate": "2018/07/04",
"location": {
"@type": "Place",
"name": "Werchter",
"address": {
"streetAddress": "Festivalterrein",
"addressLocality": "Werchter",
"addressRegion": "Vlaams-Brabant"
}
}
} </script>
Maak geautomatiseerd JSON-LD-gegevens aan: https://webcode.tools/json-ld-generator/event
Door bepaalde informatie zoals bijvoorbeeld bedrijfsvermeldingen, beoordelingen, contactgegevens, evenementen, recensies, recepten, reviews, prijsindicaties, productspecificaties enz. met deze standaarden te beschrijven, worden ze gemakkelijker door Google herkend en kunnen deze data als rich snippets verschijnen in de zoekresultaten.
(Bron: https://www.siteoptimo.com/wat-is/microdata/)
Een voorbeeld:
<address itemscope itemtype="http://data-vocabulary.org/Organization">
<span itemprop="name">Nettuts+</span>
Postal Address:
<span itemprop="address" itemscope
itemtype="http://data-vocabulary.org/Address">
<span itemprop="street-address">PO Box 21177</span>,
<span itemprop="locality">Melbourne</span>,
<span itemprop="region">Victoria</span>,
<span itemprop="country-name">Australia</span>.
</span>
<span itemprop="geo" itemscope itemtype="http://www.data-vocabulary.org/Geo/">
Latitude: <span itemprop="latitude">37.49 S </span>
Longitude: <span itemprop="longitude">144.58 E</span>
</span>
Phone: <span itemprop="tel">+61 (0) 3 9023 0074</span>
<a href="http://net.tutsplus.com/" itemprop="url">Nettuts+ | Web development tutorials, from beginner to advanced.</a>.
</address>
Maak geautomatiseerd microdata aan op https://webcode.tools/microdata-generator
Een aantal belangrijke tips:
- Vervang je links niet door aanklikbare afbeeldingen.
- Voeg "title" en "alt"-attributen toe aan je afbeeldingen.
- Geef je pagina's of "virtuele" mappen duidelijke namen.
- Gebruik HTML5-elementen.
Zoekrobots zoals Google gebruiken AI (lees: patroonherkenning) om de inhoud van je teksten, foto's en video's... te "begrijpen". Als je wil uittesten wat Google allemaal kan op het vlak van "beeldherkenning", klik dan eens op de volgende link
lorem ipsum
Werkend voorbeeld: https://www.schoolvoorbeeld.be/websites/plugins/newspaper.php
Met de NewsPaper-plugin kan je een reeks artikels verbergen en via een selectielijst (een vervolgkeuzelijst) die weer één voor één lezen. Dat maakt de inhoud van je pagina's minder zwaar. Het opsplitsen en verbergen van de informatie op je webpagina, maakt het voor bezoekers eveneens gebruiksvriendelijker.

<script src="https://code.jquery.com/jquery-3.2.1.min.js" integrity="sha256-hwg4gsxgFZhOsEEamdOYGBf13FyQuiTwlAQgxVSNgt4=" crossorigin="anonymous"></script>
Plak deze link onder die van jQuery, allebei in de <head>-sectie van de pagina waarin je het effect wil bereiken.
<script src="https://www.schoolvoorbeeld.be/js/jslibnew.js?v7"></script>
Maak in je HTML-pagina een onderdeel dat een aantal <article>-elementen bevat.
Bijvoorbeeld:
<section class="newspaper">
<article>
<h3>Titel van dit artikel</h3>
<p>Inhoud van dit artikel.
</article>
<article>
<h3>Titel van dit artikel</h3>
<p>Inhoud van dit artikel.
</article>
<article>
<h3>Titel van dit artikel</h3>
<p>Inhoud van dit artikel.
</article>
</section>
We hebben aan het element de CSS-klasse "newspaper" gegeven, maar dat mag je uiteraard zelf beslissen. Het hoeft ook geen <section>-element te zijn, het mag ook gewoon gaan om een <div>.
<script>
$(document).ready(function(){
$(".newspaper").newspaper();
});
</script>
Klaar is kees... Je kan alles natuurlijk ook nog wat "vormgeven" met CSS.
Standaard gaat de plugin op zoek naar <article>-elementen. Wil je andere elementen zichtbaar en onzichtbaar maken, dan moet je de opties van de plugin wijzigen. Standaard neemt de plugin het eerste <h3>-element dat hij in het <article> vindt, als titel voor de selectielijst. Ook dat kan je wijzigen. Als de plugin geen titel vindt, dan nummert hij de lijst.
<script>
$(document).ready(function(){
$(".newspaper").newspaper({
element: "div",
title:"h1",
text: "Kies het gewenste artikel"
});
});
</script>
| Optie | Doel | Waarde | Standaard |
element |
Standaard zoekt de plugin <article>-elementen. Je kan dit vervangen door een ander element. | p, div, li... | article |
title |
Standaard zoekt de plugin naar de eerste <h3> in elk "artikel". Je kan die waarde veranderen. | h1, h2, h4... | h3 |
text |
De titel van de vervolgkeuzelijst. | Een tekst tussen aanhalingstekens. | "Kies een artikel" |


1. Link het javascriptbestand.
Absolute pad:
icarosp/ui/crowl.modals/jq.crowl.modal.js
2. Voeg een link toe waarmee je het venster wil openen:
<a href="inhoudvenster.html" class="OpenWin">Open</a>
Andere mogelijkheden:
<p data-content="Deze inhoud moet in het venster getoond worden" class="OpenWin">Inhoud van de alinea waarop kan geklikt worden.</p>
3. Voeg het javascript toe:
$(".OpenWin").jqCrowlModal();
4. Bepaal het uitzicht van het venster:
$(".OpenWin").jqCrowlModal({
width:"80vw",
height:"80vh",
background:"white",
animation:"bigEntrance",
roundedCorners: "4px",
shadow:true
});
Voor alle animatieklassen:
Animatie-effecten in Crowl
5. Bepaal wanneer het venster moet opengaan:
$(".OpenWin").jqCrowlModal({
events: "click contextmenu"
});Standaard opent een venster bij een klik of rechtsklik op het element. Je kan meerdere events tegelijk opnemen, gescheiden door een spatie.
6. Bepaal waar het venster moet opengaan:
$(".OpenWin").jqCrowlModal({
location: "centercenter"
});topleft, topcenter, topright
centerleft, centercenter, centerright
bottomleft, bottomcenter, bottomright
mouseleft, mousetop, mouseright, mousebottom
elementleft, elementtop, elementright, elementbottom
* en **:
de optie bubble:true zal een pijtlje in het venster weergeven, afhankelijk van de positie van het venster.

7. Knoppen
$(".OpenWin").jqCrowlModal({
buttons: {
closemodal: false /*default*/,
submit: true /*default*/,
cancel: false /*default*/
},
buttontext: {
submit: "OK",
cancel: "ANNULEER"
},
onSubmit: function(){
/*Uw code*/
},
onCancel: function(){
/*Uw code*/
},
onClose: function(){
/*Uw code*/
}
});
Overlay:
overlay (boolean)
overlaybg (string: HTML-color)
Triggerelement

1. Via een HREF-attribuut bij een link. Dit kan een "externe pagina" zijn of een onderdeel uit de pagina zelf (met een bepaalde id).
<a href="inhoudvenster.html" class="OpenWin">Open</a>
<a href="#inhoud" class="OpenWin">Open</a>
Wanneer geen HREF-attribuut is voorzien, kijkt het script naar een data-content-attribuut.
2. Via een data-content-attribuut:
<p data-content="Deze inhoud moet in het venster getoond worden" class="OpenWin>
Inhoud van de alinea waarop kan geklikt worden.
</p>
Wanneer geen HREF- en geen data-content-attribuut is voorzien, moet de content via javascript worden ingesteld. Zoniet zal er geen venster weergegeven worden.
4. Via javascript:
De tekst kan rechtstreeks geplaatst worden:
$(".OpenWin").jqCrowlModal({
width:"80vw",
height:"80vh",
content: "Dit is de tekst"
});
$(".OpenWin").jqCrowlModal({
width:"80vw",
height:"80vh",
content: "url:inhoud.html"
});
Drie parameters:
1. De boodschap.
2. De positie op het scherm.
3. De weergavetijd in milliseconden.
CrowlWarning("Dit is de allerlaatste keer!", "topright", 2000);

Parameters:
1. De boodschap.
2. Een functie die moet uitgevoerd worden na de bevestiging.
CrowlConfirm("U stort uw spaargeld onmiddellijk op mijn rekening", function(){
alert("Te laat");
});

Twee parameters:
1. De boodschap.
2. Positie op het scherm.
CrowlNotification("Wat uitleg over het gebruik", "bottomleft");
U kan tooltips weergeven bij een element.

Parameters:
1. Het attribuut van het element waaruit u de inhoud wil ophalen.
2. De muispositie waar de tooltip moet verschijnen.
$("a").jqCrowlTooltips("title", "mouseleft");
Tijdens de les kreeg je een introductie over:
Deze vragen moet je goed begrijpen voor je examen. De antwoorden vind je in de presentatie, in de cursus of op internet.
De presentatie over "programmeren" vind je hier https://www.schoolvoorbeeld.be/icarosp/home/files/programmeren.pdf
Tijdens een eerste reeks lessen leren de studenten dat het begrip "computer" in onze tijd een zeer ruim begrip is. Het beperkt zich niet tot de klassieke "desktop" en "laptop", zelfs niet tot de tablet of de smartphone. Stilaan is heel onze omgeving doordrenkt van "smart" toestellen.
De studenten leren waar we overal kleine computers in aantreffen: televisie, auto, domotica...De studenten gaan aan de slag met een Arduino-ontwikkelbord. Het is de bedoeling dat ze op basis een stuk bestaande C-code (C is nog steeds de belangrijkste programmeertaal ter wereld) aanpassen en een temperatuursensor bouwen. Daarnaast bouwen ze een toepassing met een ledlicht waarmee ze in "morsecode" een signaal moeten uitsturen.



De studenten verwerken zelf hun theorie (hoofdstuk in de handleiding) tijdens het uitvoeren van de groepsopdracht.
De uitleg van de opdracht vind je hier: https://www.schoolvoorbeeld.be/Multimedia/4-Interfaces
De studenten krijgen instructies over het bouwen van een huisstijl voor een interface, het ontwikkelen van een logo en kleurschema, over het bouwen van een "goede" presentatie.
Ze presenteren hun "app" in de aula in aanwezigheid van een
extern jurylid (Dirk Remmerie van communicatiebureau Xpair Communication)
De studenten beoordelen elkaar via een door de lector gebouwd formulier: https://www.schoolvoorbeeld.be/Multimedia/Feedback-interface
Op die pagina vind je ook de werkstukken van de studenten.
Korte presentatie en hoofdstuk in de handleiding.
Samen met de lector (via beamer) bouwen de studenten hun eerste programmacode in de programmeertaal Processing (een afgeleide van JAVA). De broncode van deze les is online beschikbaar op https://www.schoolvoorbeeld.be/Multimedia/Processing
De bedoeling is dat de studenten minimaal 2 aanpassingen/uibreidingen aan de code toevoegen. Hiervoor kunnen ze een beroep doen op de lector of op online informatie.
Multimedia, grafische vormgeving, film, informatie, IT, ICT, videobewerking, videomontage, animatie, beeldbewerking, compositing, huisstijlen, webdesign, programmeren, visualiseren... het komt allemaal wel aan bod.
De materie is echter zo ruim dat we onmogelijk alles kunnen aanbieden en aanleren. Bovendien zijn de mogelijkheden enorm uitgebreid. Je kan niet zeggen: "Nu kan ik het". Je zal blijvend moeten evolueren en studeren...
Naast de theorie- en praktijklessen en de groepsopdrachten... volg je ook een individueel traject. Hieronder vind je uitgestippeld wat er van je verwacht wordt.
https://www.schoolvoorbeeld.be/Multimedia/Progressietraject
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Deze nieuwe versie van de film is veel beter dan de eerste versie. De geluidsopname (stem) kon beter, maar de uitleg is duidelijk en ok.
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Leuk in beeld gebracht. Vooral ook fijn dat jullie zelf de technieken uitgeprobeerd hebben. De inleiding vind ik wat lang duren, maar is op zich al een animatievorm. Enkel de uitleg over tekenfilm loopt wat mank.
Een flipbook werkt niet zoals een tekenfilm. Bij een tekenfilm tekenen de animatoren niet alles in één laag.
Alle onderdelen van een "scene" worden afzonderlijk getekend.Een flipbook is in veel gevallen een stukje tekenfilm dat werd afgedrukt.
ONTBREEKT: hoe worden tekenfilms gemaakt. Het concept van "lagen".
Bekijk de
presentatie:
Deel 6: Film en animatie. Studeer ook de uitleg in het
handboek:
http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Zeer sterk. Visualisaties, uitleg... zeer goed. Jullie leggen subliem uit hoe een OS werkt en wat het is.
Kleine bemerking: het OS van Apple heet niet "Apple", maar "Mac OS X".
ONTBREEKT: Eventueel hadden jullie nog wat over zeer oude/grote OS kunnen spreken zoals UNIX.
Bekijk de
presentatie:
Deel 1: Computerarchitectuur. Studeer ook de uitleg in het
handboek:
http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
LEES ZEKER OOK DE FEEDBACK HIERONDER:
De uitleg over het doel van een interface is ok. Maar toch wel wat bemerkingen .
De animatiefiguurtjes zijn leuk, maar niet functioneel. Wat doen ze in dit filmpje? Een wasmachine heeft inderdaad een interface, maar niet noodzakelijk een elektronische of digitale. Bovendien hebben de toestellen die jullie bij het begin tonen weinig te maken met een NUI of STAG. Jullie gebruiken die termen zonder ze uit te leggen. Het lijkt erop als je het filmpje bekijkt, dat enkel een smartphone een goed voorbeeld is van interfaces.
Jammer dat een van de meest uitgebreide hoofdstukken van het handboek zo'n "magere" behandeling krijgt. Bekijk voor het examen zeker grondig het corresponderende hoofdstuk en deze presentatie Deel 2: Soorten interfaces & UX-designONBREEKT:
Bekijk de
presentatie:
Deel 2: Soorten interfaces & UX-design. Studeer ook de uitleg in het
handboek:
http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
De onderstaande vragen moet je kunnen beantwoorden om uw examen goed te kunnen oplossen. De antwoorden vind je in de cursus. Zorg ervoor dat je volledige antwoorden formuleert en een vlot doorlopend verhaal vertelt. Toon dat je de leerstof begrijpt, geef voorbeelden, wees grondig en volledig.
OPGELET: de uitleg in de presentaties is lang niet voldoende als achtergrond voor je examen. Zorg voor een zinvol begrijpelijk antwoord op alle vragen.
DOWNLOAD DIT OVERZICHT ALS PDF
Computerarchitectuur https://www.schoolvoorbeeld.be/icarosp/home/docs/architectuur.pdf
Embedded/elektronica https://www.schoolvoorbeeld.be/icarosp/home/docs/deel1.pdf
Smart technology https://www.schoolvoorbeeld.be/icarosp/home/docs/bigdata.pdf
Handboek (deel 1) http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen in dit deel?
Begrippen verklaren en uitleggen:
Interfaces: https://www.schoolvoorbeeld.be/icarosp/home/docs/deel2.pdf
Programmeren: https://www.schoolvoorbeeld.be/icarosp/home/files/programmeren.pdf
Handboek (deel 2) http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen na dit deel?
Begrippen verklaren en uitleggen:
Film: Operating systems
Presentatie: https://www.schoolvoorbeeld.be/icarosp/home/docs/bigdata.pdf
Handboek (deel 3): http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen na dit deel?
Begrippen verklaren en uitleggen:
Deel 5: niet te studeren
Film Audio/geluid
Presentatie: https://www.schoolvoorbeeld.be/icarosp/home/files/animatie.pdf
Handboek (deel 3): http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen na dit deel?
Begrippen verklaren en uitleggen:
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Jullie leggen uit wat het verschil is tussen digitaal en analoog, maar niet hoe je van analoog naar digitaal gaat. De animatie is niet meer dan een automatische slideshow, maar er zit niet echt animatie in. De kijker moet voortdurend tekst lezen. Jullie gebruiken nergens afbeeldingen om het geheel te verduidelijken. Een zwaar gemiste kans.
Bekijk de presentatie: Deel 1: Digitale en elektronische verwerkingssystemen. Studeer ook de uitleg in het handboek:LEES ZEKER OOK DE FEEDBACK HIERONDER:
Een aantal animaties zijn mooi en de meeste uitleg klopt ook (in grote lijnen). Toch bemerk ik eveneens een aantal minpuntjes.
Presentatie frontend en backend
Frontend en backend? Wat is dat allemaal. Bekijk het onderstaande filmpje.
Een krant is een mooi voorbeeld om uit te leggen hoe een databankgestuurde website nu precies werkt. We gebruiken HLN.be als een voorbeeld.
Elk artikel in deze online krant, bevat een aantal terugkerende elementen. De belangrijkste structuuronderdelen heb ik naast de foto opgesomd.

Bron: https://www.hln.be/de-krant/aannemer-licht-gezinnen-op-voor-honderdduizenden-euro-s~a74fc6fc/
Je zou in een rekenbladprogramma als LibreOffice Calc of MS Excel een lijst kunnen maken met deze gegevens van een "aantal" artikels die je op HLN.be vindt.
Het zou er zo kunnen uitzien:

Een databank is echter veel meer dan enkel maar een rekenblad. In een databank bewaar je gegevens evenzeer in rijen en kolommen. Een databank kan echter hele reeksen tabellen bevatten die je eveneens met elkaar kan koppelen. Het wordt duidelijk in de volgende stap.
Een relationele databank heeft niets te maken met een datingsite. Alhoewel ze voor een datingsite vermoedelijk ook wel een relationele databank zullen gebruiken om de profielen van de gebruikers met elkaar in verbinding te brengen. Ik gebruik nog steeds het voorbeeld van de krant om duidelijk te maken wat een databank nu precies is.
Net zoals in het rekenblad bewaren we de gegevens in een "tabel". Data die "meerdere" keren kunnen voorkomen, zoals de naam van de auteur, nemen we echter niet op. Dit doen we op een "andere manier".
Ik geef Engelstalige veldnamen aan de kolommen. Niet omdat dit moet, maar omdat het wat de gewoonte is. Waarom ik niet gewoon "date" en "time" gebruik, leg ik later nog wel uit. Je merkt dat ik geen "veldnaam" geef aan de eerste en de laatste kolom en dat het veld "author" ontbreekt.
| ... | title | articledate | articletime | cover | content | ... |
| ... | Sinterklaas komt om het leven | 05/12/2018 | 06/12/2018 10:22:10 | images/sint.jpg | Op 5 december viel Sinterklaas van een dak. Hij kwam hierbij om het leven... | ... |
| ... | Trump laat haar kleuren | 03/01/2019 | 04/01/2079 11:10:20 | images/kuif.jpg | Trump gaat voortaan door het leven met bruin haar... | ... |
| ... | ... | ... | ... | ... |
|
... |
Omdat een auteur meerdere artikels kan schrijven, en we van elke auteur eveneens wat informatie willen bewaren (zoals zijn/haar naam, e-mailadres enz.), maken we voor de auteurs een afzonderlijke tabel aan.
Achteraf gaan we de tabel "articles" linken aan de tabel "authors".
| id | name | |
| 1 | Joske Janssens | joske.janssens@leukekrant.be |
| 2 | Louisa Peeters | louisa.peeters@leukekrant.be |
| 3 | Achmed Birandouni | achmed.birandouni@leukekrant.be |
Je merkt dat elke rij in de tabel "authors" een kolom met de naam "id" heeft gekregen. Dit "id" is een uniek nummer. Elke keer je aan de tabel een rij toevoegt, wordt dit id met één verhoogt. Als je een rij verwijdert, behouden de andere rijen hun nummer. Als je rij met id 2 zou verwijderen, zal rij 3 gewoon het id "3" blijven houden.
We noemen de eerste kolom van de tabel "articles" eveneens id. Ook deze kolom heeft de hierboven beschreven kenmerken. Je merkt dat de laatste kolom de benaming "authorid" heeft gekregen.
| id | title | articledate | articletime | cover | content | authorid |
| 1 | Sinterklaas komt om het leven | 05/12/2018 | 06/12/2018 10:22:10 | images/sint.jpg | Op 5 december viel Sinterklaas van een dak. Hij kwam hierbij om het leven... | 1 |
| 2 | Trump laat haar kleuren | 03/01/2019 | 04/01/2079 11:10:20 | images/kuif.jpg | Trump gaat voortaan door het leven met bruin haar... | 3 |
| ... | ... | ... | ... | ... |
|
... |
Het artikel met id 1 heeft als authorid 1, artikel met id 2 krijgt als authorid 3. D.w.z. dat "Sinterklaas komt om het leven" geschreven is door Joske Janssens. Het artikel over Trump is dan weer geschreven door de auteur met id "3" oftewel Achmed Birandouni.
De meeste hostingmaatschappijen bieden standaard MySQLaan als databanksoftware. De hierboven beschreven tabellen, kan je aanmaken in een databank op je hostingpakket. Als een hostingmaatschappij MySQL aanbiedt, dan kan je de databank over het albemeen beheren via een online tool met de naam PHPMyAdmin. De interface schrikt op het eerste zicht wat af. Maar toch is het vrij makkelijk om de twee tabellen hier boven in PHPMyAdmin aan te maken.
Opgelet: Niet iedereen kan de databank openen en bekijken. Je moet over een gebruikersnaam en wachtwoord beschikken om tabellen te kunnen aanmaken. Die kan je zelf instellen in je persoonlijke hostingaccount.
In PHPMyAdmin maak je een nieuwe tabel aan door aan de linkerkant op "Nieuw" te klikken.

Je kan het aantal benodigde kolommen invoeren en een naam geven aan de tabel.
Bij "Naam" voer je de naam in van de kolom. Bij "type" bepaal je welk type informatie je in die kolom wil opslaan.

Een ID (de eerste kolom in onze beide tabellen) krijgt als "type" int. Een int of integer is een positief geheel getal (een natuurlijk getal). Je vinkt ook de optie "AI" aan (staat voor "auto increment" om de waarde automatish te laten verhogen. Vervolgens krijg je het onderstaande venster te zien. Klik op "Starten".

Velden zoals "title" en "content" (in de tabel "articles") en "name" en "email" (in de tabel "authors") krijgen als type "text" , "mediumtext" of "longtext" (afhankelijk van de hoeveelheid data die je per veld wil bewaren. Als je de optie "Leeg" aanvinkt, dan geef je aan dat het veld niet "moet" ingevuld worden, dat het ook leeg mag blijven.
Voor "articledate" kozen we als naam niet simpelweg voor "date" omdat dit problemen zou kunnen opleveren. Date en time... zijn wat men noemt " gereserveerde woorden", woorden die MySQL intern gebruikt om bepaalde types van data aan te duiden. Net zoals "text" en "integer" ook interne benamingen zijn. Die gebruik je dus best nooit als veldnaam.
Voor articledate kiezen we als type "date", voor "articletime" se
Voor dat veld stellen we een standaardwaarde in. Opgelet: als je een standaardwaarde (in dit geval timestamp) kiest, dan mag je de optie "leeg" niet aanvinken.

Via de tab "invoegen" kan je informatie aan elke tabel toevoegen. De bedoeling is dat we hiervoor achteraf een invoerformulier aan onze site toevoegen. Op die manier moet de "journalist" niet rechtstreeks in PHPMyAdmin aan de slag. Hij/zij kan via een eenvoudig invoerformulier (na wachtwoordtoegang) informatie toevoegen aan de tabellen.
Tijd voor automatisering. In een volgende stap genereren we automatisch een HTML-pagina met de inhoud van de tabel "articles".
In de vorige les hebben we een databank aangemaakt in MySQL. Het is de bedoeling dat we de data die in de tabel "articles" en "authors" zitten, gaan weergeven in een webpagina. Om de databankgegevens om te zetten in webpagina's gebruiken we een tussenliggende taal: PHP.
PHP is de tussenliggende taal of de middleware.
PHP kan op diverse manieren met een databank spreken:
1. Create : inhouden in de databank wegschrijven (bewaren)
2. Read : inhouden uit de databank lezen en weergeven (omzetten in HTML of wat anders)
3. Update : aanpassen van data in de databank (bijvoorbeeld als er een foutje in staat)
4. Delete : verwijderen van gegevens uit de databank.
PHP werkt op de server. Dat wil zeggen dat de code die je schrijft in PHP niet meer zichtbaar is in de browser van de websitebezoeker.

In deze les lezen we de gegevens die in de tabel "articles" staat uit, en zetten we die om in een HTML-pagina. In deze tabel bewaarde ik ondertussen (via PHPMyAdmin) de volgende gestructureerde gegevens:

Ik wil hiervoor de volgende structuur krijgen in mijn HTML-pagina. Je kan dit gerust het HTML-sjabloonnoemen:
<article> <h1>TITEL VAN DE RIJ</h1> <img src="AFBEELDING"/> <p>INHOUD VAN DE RIJ</p> </article>
Van je hostingprovider of via je hostingprovider krijg je de gegevens van je databank: het adres (host), de naam van de databank, de gebruikersnaam en het wachtwoord. Die gegevens heb je nodig om je databank te kunnen openen.
Je maakt nu een nieuw bestand in de map van je website met de naam read.php.
In je teksteditor plak je de onderstaande code.
<%NOTHING%?php
$servername = "ADRES of HOST";
$username = "GEBRUIKERSNAAM";
$password = "WACHTWOORD";
$dbname = "DATABANKNAAM";
// Maak de verbinding
$conn = new mysqli($servername, $username, $password, $dbname);
// Controleer de verbinding
if ($conn->connect_error) {
//breek de code hier af als de verbinding mislukt
die("Verbinding met de databank is mislukt: " . $conn->connect_error);
}
//se%NOTHING%lecteer alle rijen van de tabel 'articles'
$sql = "sel%NOTHING%ect * FROM articles";
//bewaar het resultaat van de zoekopdracht
$result = $conn->query($sql);
//als het aantal rijen groter is dan 0, zet de rijen dan om in HTML
if ($result->num_rows > 0) {
// maak een "loop" door alle rijen
while($row = $result->fetch_assoc()) {
//hier sluiten we de PHP-code even af om rechtstreeks HTML te kunnen schrijven
?>
<article>
<h1><?echo $row["title"];?></h1>
<img src="<?echo $row['cover'];?>"/>
<p><?echo $row["content"];?></p>
<sub><?echo $row["articledate"];?></sub>
</article>
<?
}
} else {
//Er staan geen artikels/rijen in de databank
echo "Geen artikels gevonden in de databank";
}
$conn->close();
?>
Als je de pagina nu opent in de browser, krijg je de output te zien in HTML. Bekijk je de broncode van je webpagina in de browser, dan zal je merken dat de PHP-code niet meer zichtbaar is.
De PHP-code hierboven is gebaseerd op codevoorbeelden van w3schools.com
In de les heb je de basis van CSS geleerd. Je hebt gezien hoe je elementen kan opmaken en hoe je ervoor kan zorgen dat bepaalde afbeeldingen links, en andere rechts worden uitgelijnd.
Bekijk de code van het HTML- en het CSS-bestand op deze pagina.
De bedoeling is dat je het HTML-bestand en het CSS-bestand zodanig aanpast dat een "article"-element de ene keer een witte tekst met zwarte achtergrond heeft, de andere keer een zwarte tekst met witte achtergrond.
TIP: je hebt hiervoor de volgende stijleigenschappen nodig.
color: white;
background-color:black ;
(of omgekeerd)
1. Download het ZIP-bestand hieronder. Pak het uit en pas het aan.
2. Meld je aan op www.schoolvoorbeeld.be/task
3. Maak een nieuwe map aan met de naam "oefening1".
4. Upload in die map je aangepaste bestanden.
Er bestaan heel wat CSS-frameworks. Tot de bekendste behoren Bootstrap en Materialize. Maar het zijn lang niet de enige. Een CSS-framework bestaat uit een CSS-bestand dat je in de meeste gevallen gratis mag gebruiken voor je site. Een CSS-framework bevat al een hele reeks klassen om je webpagina's makkelijk te kunnen vormgeven.
Voor de lessen webdesign basis heb ik een aangepaste versie van het Skeleton-frameworkgeschreven. Hiermee kan je je site makkelijk indelen in rijen en kolommen, iets wat bijzonder moeilijk is als je dit zelf zou gaan doen in CSS. Bovendien houdt Skeleton (of zoals wij het noemen "CSSBIB") rekening met mobiele toestellen. Hierdoor maak je je site in een wip "responsive".
Naast het CSS-framework dat op deze pagina uit de doeken wordt gedaan, heb je vaak nog wat extra zaken nodig om je site "responsive" en "mobile-first" te maken. Problemen met de mobiele weergave? Klik dan op de volgende link:
Responsive webpagina's, mobile first
1. CSSBIB gebruiken
Link het CSS-bestand aan je webpagina.
Voeg in de <head>-sectie van je document de volgende regel toe:
<link rel="stylesheet" href=""> Tussen de aanhalingstekens achter href, tik je het adres van het CSS-bestand:
https://www.schoolvoorbeeld.be/css/cssbib.css
De resulterende regel ziet eruit als volgt:
<link rel="stylesheet" href="https://www.schoolvoorbeeld.be/css/cssbib.css"> Met CSSBIB kan je snel rijen en kolommen maken. Op mobiele toestellen gaan de kolommen netjes onder elkaar staan.
<div class="row"> </div> Elke rij beschikt over twaalf cellen/kolommen. Je kan die groeperen om een pagina in kolommen onder te verdelen.
Opgelet: je eindtotaal moet altijd 12 zijn.
In het onderstaande voorbeeld verdelen we de rij in drie gelijke kolommen.
<div class="row">
<div class="four columns">
Inhoud eerste kolom
</div>
<div class="four columns">
Inhoud tweede kolom
</div>
<div class="four columns">
Inhoud derde kolom
</div>
</div> De indeling zou er als volgt uitzien:

Uiteraard kan je ook andere combinaties maken:




Je bepaalt op die manier zelf hoe je je webpagina wil opbouwen. Uiteraard kan je meerdere rijen met meerdere combinaties van kolommen onder elkaar in de pagina toevoegen. Als je aan een site voor jezelf of voor een klant begint, kan je eerst een draadmodel van je pagina uittekenen. Vervolgens is het heel makkelijk om in html dat draadmodel te bouwen.
Bekijk het draadmodel. Hoeveel rijen en kolommen (per rij) zou je nodig hebben om deze indeling te bouwen in HTML?

Het is soms handig dat een rij de volledige breedte van je browservenster in beslag neemt, bijvoorbeeld als je in een rij een bannerafbeelding wil plaatsen. Als je in een rij een tekst plaatst, worden de tekstregels echter zeer "breed" op een heel breed scherm zoals bij een Apple iMac. Daarom kan het zinvol zijn om een rij of een groep rijen te beperken in breedte.
Een "container" die de breedte van de rijen beperkt tot een normale "laptopweergave":
<div class="container">
<div class="row">
</div>
</div><div class="container-max">
<div class="row"></div>
</div>Je kan door het toevoegen van een klasse bepalen hoe breed je afbeelding moet zijn en waar ze moet staan.
| CSS-klasse | Doel |
| left | Foto staat links |
| right | Foto staat rechts |
| image100, imagefull, stretch | Foto neemt 100% van de breedte van de "parent" in (het element waar de foto zich in bevindt). |
| image50, imagehalf | Foto neemt 50% van de breedte van de "parent" in (het element waar de foto zich in bevindt). |
| imagethird | De foto neemt ongeveer een derde in van de "parent" (het element waar de foto zich in bevindt). |
Voorbeeld:
<img src="images/foto.jpg" class="imagehalf left"/>Een foto is een blokelement, een "rechthoek". Ook andere elementen zoals bijvoorbeeld <div> en <article> zijn blokelementen. Aan al deze blokelementen kan je afgeronde hoeken geven of een schaduw.
Met de klasse "shadow" geef je een element een schaduweffect. Opgelet: dit werkt niet bij tekstelementen!
<div class="shadow"></div>Met de klasse "dropshadow" geef je foto's een schaduweffect.
<img src="images/foto.jpg" class="dropshadow"/><img src="images/mijnfoto.jpg" class="roundcorners"/>Aan afbeeldingen kan je filters toevoegen voor drie gebeurtenissen:
â bij het openen van de pagina
â wanneer de muis over de afbeelding beweegt
â wanneer de gebruiker op de afbeelding klikt
| Wat? | Filterklasse | Klasse voor muisover | Klasse voor "klik" |
| grijstinten | bw | bwOnMouseOver | bwOnClick |
| contrast | contrast | contrastOnMouseOver | contrastOnClick |
| sepia | sepia | sepiaOnMouseOver | sepiaOnClick |
| negatief | invert, negative | invertOnMouseOver | invertOnClick |
| zacht vervagen | softblur | softblurOnMouseOver | softblurOnClick |
| sterk vervagen | strongblur | strongblurOnMouseOver | strongblurOnClick |
Voorbeeld:
<img src="images/cat.jpg" class="bw invertOnMouseOver sepiaOnClick"/>"Spin" en "fade" vormen 2 afzonderlijke filters voor een muis-over-effect:
Voorbeeld:
<img src="images/foto.jpg" class="spin"/>
<img src="images/foto.jpg" class="fade"/>Een masker is een techniek om bepaalde gebieden van een afbeelding te "verbergen". Zo kan je een afbeelding achter de volgende "vormen" (CSS-klassen) maskeren: textballoon, star, message, circle, fadetop, fadingcircle.
<img src="images/cat.jpg" class="textballoon"/>
<img src="images/cat.jpg" class="star"/>
<img src="images/cat.jpg" class="message"/>
<img src="images/cat.jpg" class="circle"/>
<img src="images/cat.jpg" class="fadetop"/>
<img src="images/cat.jpg" class="fadingcircle"/>


Met de klasse âtextshadowâ geef je een element een schaduweffect.
<h3 class=âtextshadowâ>Hier komt mijn titel</h3>Een masker op een titel kan een bijzonder mooi effect opleveren. Dit houdt in dat de tekstkleur vervangen wordt door een uitsnede van de foto.
HTML-code:
<h1 class="textmask" id="titelmasker">HIER KOMT DE SLOGAN</h1>CSS-code:
#titelmasker{
background-image:url(images/cat.jpg);
}Zoals je (vermoedelijk, hopelijk :-) ) weet kan je afbeelding met behulp van de stijlregel "float" links of rechts langs een tekst uitlijnen. Uitlijning volgt steeds het rechthoekige kader van de afbeelding of het HTML-element waarop je een "float" hebt toegepast. Het is echter ook mogelijk om tekst cirkelvormig rond een afbeelding te laten vloeien.

De HTML-code:
<p><img src="images/cat.jpg" class="floatcircle imagethird"/>De Palm Desertbands werden
lokaal bekend door veelvuldige optredens in bars en partijen, maar vooral in en rond de
geïsoleerde woestijngebieden en steden van de Coachella Valley. De instrumenten en
versterkers werden aangedreven door een generator. Met name de band Kyuss is bekend
geworden door de "generator parties". Plekken waar de feesten werden gehouden waren
vooral 'The Nudist Colony' (Desert Hot Springs/Yucca Valley), 'The Iron Door' (Indio Hills),
'Shot Gun Flats' (Sky Valley), 'Mecca Banks' (Afwateringssysteem in Mecca)...</p>Aan de vormgeving van je site begin je niet zo maar. Op basis van het CSS-frameworkbouw je vanaf volgende les de startpagina op.

Maak tegen volgende les op papier een draadmodel van hoe je startpagina er zal uitzien. Je uploadt een foto van dat draadmodel in je map via www.schoolvoorbeeld.be/task. Maak een map aan met de naam "oefening2" en plaats daarin een foto of PDF van je draadmodel.
Breng het originele document volgende les ook mee.


In de vorige les heb je geleerd hoe je artikels uit een MySQL-databank kan weergeven in een webpagina. De PHP-code op de server zet de rijen uit de tabel om in stukjes HTML-code. In deze les leg ik uit hoe je gegevens kan filteren uit de tabel. D.w.z. je wil net alles tonen, maar slechts bepaalde artikels die voldoen aan jouw zoekopdracht.

We starten met de code van de vorige les.
<!DOCTYPE html>
<html lang="nl">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="https://www.schoolvoorbeeld.be/css/cssbib.css">
<title>Paginatitel</title>
</head>
<body>
<div class="container">
<div class="row">
<div class="twelve columns">
<%NOTHING%?php
include "config.php";
// Maak verbinding
$conn = new mysqli($servername, $username, $password, $dbname);
// Controleer verbinding
if ($conn->connect_error) {
die("Verbinding met databank is mislukt: " . $conn->connect_error);
}
$sql = "se%NOTHING%lect * from articles";
$result = $conn->query($sql);
if ($result->num_rows > 0) {
// output data of each row
while($row = $result->fetch_assoc()) {
?>
<article>
<h3><%NOTHING%?echo $_row["title"];?></h3>
<p><%NOTHING%?echo $_row["content"];?></p>
</article>
<%NOTHING%?PHP
}
} else {
echo "Geen artikels gevonden in de databank";
}
$conn->close();
?>
</div>
</div>
</div>
</body>
</html> Het is heel normaal dat de PHP-code alle artikels omzet in HTML. We vragen immers om alle artikels uit de tabel "articles" op te halen:
se%NOTHING%lect * from articlesWe willen nu echter gaan filteren op de resultaten. Stel dat ik enkel de artikels wil waarbij het woord "sint" in de titel voorkomt:
se%NOTHING%lect * from articles where title like '%sint%'Het woord sint staat niet enkel tussen twee weglatingstekens, maar ook tussen twee %-tekens. Die duiden aan dat er voor en achter het woord sint al andere tekens mogen staan.
Indien je artikels zou willen zoeken waarvan de titels beginnen met "sint", dan zou je het volgende doen:
se%NOTHING%lect * from articles where title like 'sint%'se%NOTHING%lect * from articles where title = 'sint'se%NOTHING%lect * from articles where rubriek = 'sport'se%NOTHING%lect * from articles where title like '%sint%' or content like '%sint%'se%NOTHING%lect * from adressen where postcode=3300 and naam like '%janssens%'Uiteraard is een SQL-query pas echt zinvol als de eindgebruiker specifieke zoekopdrachten naar de server kan versturen.
Als een websitebezoeker (een "client") via zijn browser (de clientbrowser of useragent) een pagina opvraagt, dan vraagt hij/zij de server in feite om een HTML-pagina op te sturen die bepaalde informatie bevat. De server stuurt vervolgens de webpagina terug (niet via de postbode).
We spreken in dit geval van een GET-request. De gebruiker of client wil INFORMATIE "KRIJGEN" (to get). Het adres dat je in de adresbalk van je browser invoert is dan de GET-REQUEST.

Je kan echter via de adresbalk nog extra informatie of zoekopdrachten mee verzenden. Dit doe je op de volgende manier:
ADRES VAN DE WEBPAGINA ? ZOEKNAAM = ZOEKOPDRACHT
Bijvoorbeeld: www.schoolvoorbeeld.be/websites/studenten/student/zoek.php?q=sint
Om ervoor te zorgen dat onze PHP-pagina die verzonden waarde ook kan ontvangen, moeten we de PHP-code van zoek.php enigszins aanpassen:
$q = $_GET["q"];
$sql = "se%NOTHING%lect * from articles where title like '%$q%'"; 1. We versturen een zoekterm met de benaming "q" naar de server.
2. We sturen eveneens een waarde mee voor die zoekterm: q=sint
3. In de PHP-pagina op de server kunnen we die verzonden waarde opvragen met $_GET["q"]
4. Die "ontvangen waarde" stoppen we in een PHP-variabele (een soort tijdelijk doosje) met de naam $q.
5. Samengevat zien stap 3 en 4 er zo uit: $q = $_GET["q"];
6. Vervolgens passen we onze SQL-opdracht aan, zoals je hier boven kan zien.
Uiteraard kan je aan de bezoekers van je website moeilijk zeggen:
"Als je achter het adres in de adresbalk een ? tikt met daarachter "q=" en daar achter je zoekterm, dan kan je zoeken op deze site."
De gebruiker kan de zoekterm invoeren in een "zoekveld". Hij/zij klikt op een knop met het opschrift "zoek" en krijgt meteen het resultaat terug in HTML-code.
Voeg onder <body> de volgende code toe:
<form>
<input type="text" name="q"/>
<button>ZOEK</button>
</form>Eén punt is heel erg belangrijk. Het invoerveld moet een attribuut "name" krijgen. De waarde van dat attribuut moet dezelfde zijn als de te ontvangen waarde op de server. Klinkt dit als Chinees?
Wel, op de server ontvang je een variabele met de naam "q" ($_GET["q"]). We moeten zorgen dat het formulierveld hier dus ook name="q" krijgt.
Als je een zoekterm invoert en op "zoek" klikt, krijg je meteen ook het gewenste resultaat. Je zal de verzonden query ook zien verschijnen in de adresbalk:

Volgende les bouwen een formulier om gegevens toe te voegen aan de databank... Dan wordt het pas echt cool.
Eén vraag is van cruciaal belang. Wil jij (of je klant) de site zelf kunnen beheren? Is het belangrijk dat je/hij/zij regelmatig zelf aanpassingen kan doen?
Als je zelf de aanpassingen niet kan doen, moet je voor elke wijziging een beroep doen op de "webmaster". Die webmaster kan daar kosten voor in rekening brengen.
Als je een website zelf wil beheren, heb je een "CMS"-systeem nodig. Dat is een stuk software op je hostingpakket dat het toelaat om je site (van een eenvoudige "blog" tot een webshop) zelf aan te passen.
Belangrijk: De meeste "webmasters" doen heel weinig zelf. Ze installeren (vaak met één enkele muisklik) een CMS-systeem (zoals WordPress) op je hostingpakket. Op die manier heb je vaak sowieso al een CMS, zonder dat je het zelf beseft.
De bekendste CMS-systemen zijn WordPress, Drupal (een Belgisch product), Joomla en Magento.
Een CMS-systeem biedt tal van voordelen:
Voorbeeld: Een CMS-installatie in het "loginpanel" van de webmaster:

Probeer zoveel mogelijk de controle te behouden: domeinnaam, hostingpakket, CMS... Maak duidelijke afspraken met je webmaster. Een CMS zoals WordPress hoef evenmin veel geld te kosten. De webmaster moet je enkel betalen voor haar/zijn uren werk, niet voor de software zelf.
Aan een CMS zijn op zich niet echt nadelen verbonden. Maar als een webmaster gebruik maakt (soms zonder dat je het zelf weet) van een systeem als WordPress of Drupal, is hij zelf niet altijd in staat om aanpassingen aan het systeem te doen. Niet elke webmaster heeft immers voldoende "skills" om zo'n systemen aan te passen op maat. Je krijgt dus niet altijd precies wat je zelf wil.
Vermits een CMS-systeem open source is (de code is leesbaar beschikbaar op het internet), zijn veiligheidslekken snel bekend. Een webmaster moet het CMS-systeem daarom regelmatig updaten.
Als je gewend bent om te werken met kantoorprogramma's zoals teksverwerkers (MS Word, LibreOffice...) en presentatieprogramma's (zoals MS Powerpoint, Apple Keynote...), dan ben je gewend om teksten en foto's en vormgeving samen te voegen in één bestand. Als je een bestand van je tekstverwerker doorstuurt naar vrienden, dan ben je er zo goed als zeker van dat de foto's die je aan het document hebt toegevoegd, nog steeds in dat document zitten als de bestemmeling het bestand opent. Enkel de lettertypes kunnen wat problemen geven.
Bij een website werkt het net iets anders. Een website bestaat uit een reeks afzonderlijke bestanden en een reeks mappen.
Op de afbeelding hieronder zie je een voorbeeld:

Ook al toont een webpagina afbeeldingen tussen de tekst, de afbeeldingen zijn steeds gelinkt. Ze staan extern, meestal in een afzonderlijke map (in dit geval de map 'images'). Als je een webpagina opent in een browser, dan weet de browser dat hij die foto's moet gaan zoeken in de map op de webserver.
Stel dat je domeinnaam www.blabla.be is, dan zal het adres van de afbeelding www.blabla.be/images/banner.jpg zijn. Zo zie je dat het adres dat in je browserbalk verschijnt, ook effectief een mappenstructuur weergeeft (images/banner.jpg).
Ook video's of kaarten die in een webpagina getoond worden, staan niet "echt" in de webpagina. Ze worden "ingesloten", zoals je een foto achter een frame steekt in een kader. Kaarten komen vaak van Google Maps of OpenStreetMaps, films van YouTube of VIMEO...
Webpagina's staan altijd in de basismap en eindigen op de uitgang .html, zoals een Worddocument eindigt op .doc of .docx. De opmaak van een webpagina (kleuren, lettertypes, afmetingen, posities...) staat beschreven in afzonderlijke documenten met de uitgang .css (in het voorbeeld style.css in de map style).
Een voorbeeld van CSS-code uit een stijlbestand:

De reden waarom stijlinformatie in een afzonderlijk document staat, is eigenlijk heel logisch. Als de eigenaar van een site de stijl van zijn/haar site wil aanpassen, dan moet hij/zij enkel dit ene stijldocument wijzigen. De site verandert dan meteen van uiterlijk zonder dat de inhouden opnieuw moeten ingevoerd worden.
Dankzij CSS kan de stijl van zeer grote sites in één oogwenk aangepast worden. De webmaster past het stijldocument aan en heel de site, of die nu één of 10 miljoen webpagina's bevat, verandert meteen van uitzicht.
Om die reden kan een site of online app zoals Facebook of Instagram er na een nachtje slapen plots volledig ander uitzien. Als een bedrijf zoals Facebook het CSS-bestand van hun site aanpassen, dan veranderen automatisch alle miljoenen profielen van uitzicht. Stel je voor dat je de huisstijl zou willen wijzigen in duizend Worddocumenten, dan zou je wel even wat tijd nodig hebben.
Als je een website of webpagina in je browser opvraagt of via een zoekmachine als Google opzoekt, dan stuurt de webserver waarop die pagina "staat", je een reeks bestanden door: HTML- en CSS-bestanden (zie hierboven) en eventueel afbeeldingen en andere bestanden.
Je browser krijgt al die onderdelen toe en bouwt met behulp van het stijldocument (het CSS-bestand) de hele site op in het browservenster.
Je kan het perfect vergelijken met een IKEA-zelfbouwpakket. IKEA (de server) stuurt je één of meer kartonnen dozen. Jij (de browser) opent die dozen en bouwt met behulp van de handleiding (CSS) de planken en schroeven (HTML, foto's, films...) op tot een kast (de zichtbare webpagina).
Naast HTML en CSS is er nog een derde "taal" van cruciaal belang in moderne websites: JAVASCRIPT. Dit is een echte "programmeertaal". Vergelijk het nogmaals met een IKEA-kast. Bij een kast kan achteraf ook deuren en schuiven open- en dichtdoen. De "gebruiker" kan "interactief" met de kast omgaan.
Op een website zullen op die manier slideshows, accordeon-effecten enz. met behulp van javascript worden geprogrammeerd. De webmaster kan code schrijven (of in veel gevallen gewoon ergens downloaden) om interactieve effecten aan de site toe te voegen.
SAMENGEVAT: DE FRONTEND (wat we van een site zien in de browser) WORDT GEBOUWD MET EEN COMBINATIE VAN DRIE TALEN: HTML, CSS en JAVASCRIPT.
Een "echte" webmaster zal een site in code bouwen in een teksteditor. Opgelet: een teksteditor is nog wat anders dan een tekstverwerker. Je kan er niet visueel pagina's in samenstellen. Je tikt code in in HTML of CSS of javascript. Je moet dus wel weten wat je aan het doen bent en hoe je dit moet doen.
De HTML-code van een webpagina in een teksteditor:

%COPYRIGHT%
Velen menen goed te zijn in het combineren van kleuren. Door Instagram en de camerafunctionaliteit denken veel mensen een krak te zijn in fotografie. Toch moet je voor de ontwikkeling van een website over heel veel grafische vaardigheden beschikken die verder gaan dan wat aangeboren talent of het gebruik van digitale tools.
Zo vertelde een student me ooit goed te zijn in Photoshop, maar in feite ging het over het gebruik van filters in Instagram.
Naast het ontwerpen of "vormgeven" van een site ( webdesign ), komt er ook webontwikkeling (programmeren) aan te pas. Een aantal skills zijn onontbeerlijk:
Kortom: een website opbouwen en de vormgeving... is niet weggelegd voor beginners. Grafische vormgeving, webdesign en ook webontwikkeling... vragen zeer veel vaardigheden en vooral ook veel ervaring.
Grotere websites zoals blogs, nieuwssites, bedrijfssites, webshops... vragen andere oplossingen. Het is dan niet meer efficiënt om bijvoorbeeld voor elk product dat je op een site wil tonen, een afzonderlijke webpagina te maken in een teksteditor.
De artikels die op de pagina's verschijnen, worden gestructureerd opgeslagen in een databank. De webontwikkelaar programmeert in een of andere programmeertaal (bijvoorbeeld PHP) een stuk code dat de databank kan openen en lezen. De software doet meer dan enkel de databank openen. De code genereert op basis van de databankinhouden automatisch webpagina's (in HTML).
Hoe werkt zo'n systeem? Bekijk het in onderstaand filmpje:
De eigenaar van de site of iemand van haar/zijn bedrijf (één of meerdere teamleden) kunnen de inhouden van de site zelf toevoegen via een online systeem, zo'n beetje zoals je in Facebook reacties post, maar dan met meer mogelijkheden.
Zo'n systeem bestempelen we als een CMS, een content management system. Alle informatie die aan de site wordt toegevoegd, blijft op de server bewaard in een databank. De server maakt automatisch de webpagina's die de bezoeker wil bekijken.
Hieronder een voorbeeld van het CMS-systeem achter deze site waarin ik deze tekst nu aan het intikken ben :-)

Zo'n systeem waarbij er heel wat automatisch gebeurt op de "achtergrond" (op de webserver) vormt de basis van heel veel websites, maar ook van webapplicaties zoals social media (Facebook, Instagram...), reissites (booking.com...), online bankieren... enz.
Voor zulke backendtoepassingen worden in veel gevallen bestaande CMS-systemen (zie ook vorige pagina) zoals WordPress of Joomla ingezet. Heel vaak is er echter nood aan gespecialiseerd maatwerk waarbij één of meerdere webontwikkelaars nodig zijn.
Cursus backendontwikkelingRaad een bedrijf niet te snel een webshop aan. Er zitten zeer veel addertjes (en zelfs serieuze slangen) onder het gras:
Wat als je webshop online een paar schoenen verkoopt en je verkoopt hetzelfde paar ook "offline" in je winkel? Hoe los je dat probleem op?
Nadelen en problemen:Google verwacht dat elke site zonder problemen mobiel kan bekeken worden. En als Google dat zegt, dan kunnen we niet anders dan "luisteren", want Google is de grootste en belangrijkste zoekmachine in de westerse wereld.
Dit kan je makkelijk zelf uittesten door je browservenster te versmallen of de site op een smartphone te bezoeken.
Afbeelding: De site www.cultuurreizen.be op laptop en op smartphone.

Wacht niet tot je site kant-en-klaar online staat. Je moet evenmin een "extra" of afzonderlijke site bouwen. Een webmaster die op een slimme manier gebruikmaakt van CSS, heeft aan mobiele ondersteuning nog relatief weinig werk. De nieuwste vormen van webdesign zorgen ervoor dat je site meteen "responsive" reageert. D.w.z. dat je site zich ogenblikkelijk aanpast aan het scherm waarop hij wordt weergegeven.
Google controleert of een site mobile-first is (of een site in de eerste plaats gericht is op mobiele toestellen). Als dit niet het geval is, gaat je site naar beneden in de zoekresultaten. Dat wil je als eigenaar van een website natuurlijk niet.
Google voert die controle natuurlijk niet "manueel" uit (met echte mensen). De zoekmachine gebruikt hiervoor software die de broncode van je webpagina's (de HTML-code) uitleest.
In hoofdzaak gaat die software op zoek naar één regeltje code. Je kan zelf controleren of die regel aanwezig is. Als dat niet het geval is, kan je aan de webmaster de tip geven om die regel toe te voegen.
Hoe ga je te werk?

Lees ook de volgende stap:
Seo voor beginners en niet-techneuten
%COPYRIGHT%
Over SEO heb je ongetwijfeld al veel gehoord. Voor de webmaster betekent dit dat hij/zij door aanpassingen aan de HTML-code de site beter begrijpbaar maakt voor zoekmachines. In boeken of online tutorials over SEO lees je doorgaans dezelfde tips op het vlak van SEO. Maar in veel gevallen lees of hoor je weinig over nieuwe manieren om je pagina's beter te laten scoren.
Zoekmachineoptimalisatie (Engels: search engine optimization of SEO) houdt in dat je door aanpassingen aan de HTML-code van je webpagina's, aan zoekmachines duidelijker kan maken waarover je webpagina gaat.
Een zoekmachine zoekt niet op het moment dat je een zoekopdracht ingeeft. Google maakt voortdurend een index van het ganse wereldwijde web. Hiervoor zet het bedrijf zoekrobots in. Dat zijn geen Star Wars-achtige robots, maar stukken software die websites bezoeken.
Je kan op heel eenvoudige wijze controleren hoe vaak je site is opgenomen in de Google-index/databank:
Tik de volgende zoekopdracht in in Google:

Als je één les hebt gekregen over SEO in je studieloopbaan, dan heb je ongetwijfeld al gehoord over metatags. Dat zijn stukjes HTML-code die je site beter begrijpbaar maken voor Google.
Je kan zelf controleren of die in een site of webpagina aanwezig zijn. Zet hiervoor de volgende stappen:
Bovenaan in de code moet je een regeltje vinden dat begint met <title> en eindigt met </title>. Die regel is essentieel. Die regel verschijnt immers ook in Google bij de zoekresultaten.
De regel in de HTML-code:

De titel in de zoekresultaten van Google:

De title-tag moet voor elke webpagina van je site anders zijn! Anders zou Google kunnen denken dat alle pagina's over hetzelfde onderwerp gaan.
Vaak hoor je dat de metatag "keywords" heel belangrijk is. De meeste zoekmachines houden er echter relatief weinig rekening mee omdat webmasters er vaak misbruik van gemaakt hebben om hun site beter te laten scoren. De metatag "description" is veel belangrijker. Vaak gebruikt Google die omschrijving om als tekstje in de zoekresultaten weer te geven.
De tags "author", "description" en "keywords" voor de website www.uitdenaad.be:

De tekst die als "content" bij de tag met de "name" "description" is ingevoerd (zie foto hierboven), verschijnt als tekst in de zoekresultaten bij Google. M.a.w. Google gebruikt de tekst die je zelf hebt ingesteld.
De site www.uitdenaad.be in Google:

Net zoals de title-tag, moet de description-metatag voor al je webpagina's verschillen. Anders meent Google dat al je pagina's over hetzelfde gaan.
Op https://webcode.tools/meta-tags-generator kan je metatags en title-tags genereren voor al je webpagina's.
Een slimme webmaster voegt aan een site ook OG-tags toe. Sociale mediasites zoals Facebook, Twitter en Linkedin, gebruiken deze informatie als jijzelf of iemand anders één van je webpagina's deelt op hun site.
Met zulke OG (open graph)-tags kan je bijvoorbeeld instellen welke foto in facebook moet verschijnen als iemand één van je webpagina's deelt:
De OG-tags voor de site www.uitdenaad.be:

Het resultaat als je deze pagina deelt op Facebook:

Op https://webcode.tools/open-graph-generator kan je zelf OG-tags genereren voor elk type informatie.
Een straffe uitspraak de titel hierboven, maar dan weet ik tenminste dat je dit even zal lezen. Als je als bedrijf een website hebt en daarnaast een afzonderlijke facebook-pagina of -groep, dan houd je de mensen weg van je site. Het is alsof één tijdens een uitzending de boodschap zou tonen om naar VTM te kijjken. Snap je?
Bovendien ben je dezelfde informatie meerdere malen online aan het publiceren. Vaak versturen bedrijven ook nog eens een nieuwsbrief, waarin nogmaals de zelfde informatie is opgenomen.
Om die reden geef ik graag de volgende tips voor het gebruik van sociale media:
Tips voor het verzenden van nieuwsbrieven:
De meest geavanceerde manier om elk onderdeel van je pagina begrijpelijk te maken voor een "domme" zoekmachine, is door het toevoegen van JSON-LD-data. Dat zijn eveneens stukjes code in de bron van de webpagina die je site leesbaarder maken voor een zoekmachine.
Hieronder een voorbeeldje:

In het codevoorbeeld in de bovenstaande afbeelding zie je adresgegevens voor het bedrijf achter de website en een soort "schema" over de werking van de site zelf. Voor elk soort gegevens bestaat er wel een bepaald informatieschema. Op
https://webcode.tools/json-ld-generator vind je een tool waarmee je voor je eigen site JSON-LD-code kan genereren. Je kan zo'n blokjes code dus ook zelf maken en aan je webmaster bezorgen.
In een robots.txt-bestand op de website kan de webmaster bepalen welke bestanden en/of mappen een zoekmachine al dan niet mag bekijken en opnemen in de index. Hoe dit precies werkt, hoef je niet meteen te weten, maar Google vindt het wel fijn als er effectief zo'n bestand bestaat.
Controleer of er een robots.txt-bestand bestaat. Controleer of het bestand bestaat voor je eigen site door de domeinnaam in te voeren in de adresbalk van je browser (opgelet: niet in het zoekvenster van Google!), gevolgd door /robots.txt. Samengevat moet het er ongeveer als volgt uitzien:
www.domeinnaam.tld/robots.txt
Een sitemap is een bestand op een website waarin een lijst met alle links naar de diverse webpagina's van je site zijn opgenomen. Vaak heet dit bestand sitemap.xml of sitemap.php. Ook hier hoef je niet te weten hoe dit in zijn werk gaat, maar het is wel belangrijk dat je site zo'n bestand bevat. Google kan zo makkelijker zien welke pagina's je site allemaal bevat.
Controleer of het bestand bestaat voor je eigen site door de domeinnaam in te voeren in de adresbalk van je browser (opgelet: niet in het zoekvenster van Google!), gevolgd door /sitemap.xml of /sitemap.php. Samengevat moet het er ongeveer als volgt uitzien:
www.domeinnaam.tld/sitemap.xml
%COPYRIGHT%
Bekijk de presentatie voor de studenten "marketing multimedia": Open het PDF-bestand
Bekijk de "beginners"presentatie: Open het PDF bestand
Een site beoordelen:
sitebeoordelen.pdfWij ontving en inderdaad ook wel een aangifteformulier, maar vermits wij dat vorige jaren niet apart hadden ingevuld, gingen wij er van uit dat dit ook nu niet nodig was.
Wij hebben net als Ria elk ook kinderen ten laste en de grond wordt volledig gebruikt voor landbouwdoeleinden (zoals aangegeven op de aanvraag tot vrijstelling).
De vrijstelling betreft toch de grond en kan volgens ons onmogelijk slechts gelden voor één van de drie eigenaars en niet voor de twee andere.

Het gebruik van een databank en PHP voor het automatiseren van webinhouden, wordt pas echt zinvol als je op een gebruiksvriendelijke manier inhouden kan toevoegen aan de databank. Uiteraard kan je dit via PHPMyAdmin, de databankbeheersoftware (geschreven in PHP) die op de meeste hostingpakketten standaard al aanwezig is. Maar in PHPMyAdmin laat je de eindgebruiker best geen inhouden toevoegen.
In deze les maken we een HTML-formulier waarin de eindgebruiker de benodigde informatie kan invoeren. Het formulier bevat een "verzend"knop. Wanneer de gebruiker daarop klikt, stuurt hij/zij de inhoud van het formulier naar een PHP-bestand op de server. Dat bestand zal de verzonden informatie uitlezen en invoegen in de juiste kolommen in de tabel (articles) in de databank.

1. Een HTML-formulier
2. Een PHP-bestand dat de verzonden informatie bewaart.
Een vrij volledige handleiding voor het bouwen van formulieren vind je via deze link: https://www.w3schools.com/html/html_forms.asp
We zorgen ervoor dat het HTML-formulier de structuur van de databanktabel volgt. Zo ziet onze tabel eruit in PHPMyAdmin:

We starten vanuit het HTML-sjabloon dat je via een link in de menubalk vindt. Daaraan voegen we een FORMULIER toe.
<div class="container">
<div class="row">
<div class="twelve columns">
<form method="post" action="save.php">
<div>
<input type="text" placeholder="Voer hier een titel in" name="title"/>
</div>
<div>
<label>Voer hier een datum in:</label>
<input type="date" name="articledate"/>
</div>
<div>
<label>Voer hier de tekst van het artikel in:</label>
<textarea name="content"></textarea>
</div>
<div>
<input type="text" id="cover" name="cover" placeholder="adres van de afbeelding"/>
</div>
<div>
<button id="bewaar">Bewaar</button>
</div>
</form>
</div>
</div>
</div>Met een <input>-element maken we een invoerveld in onze webpagina. Elke "input" krijgt ook een "name"-attribuut. We nemen hiervoor telkens de "kolomnaam" van de tabel in de databank. In de tabel "articles" in onze databank vinden we bijvoorbeeld de kolommen "title", "articledate" en "cover"... We gebruiken exact dezelfde benamingen voor de invoervelden van ons formulier.
Je kan aan een <input>-element ook een type-attribuut geven. Standaard is het type "text" als je tenminste tekst als invoer verwacht. Het type "date" tovert een datumse%NOTHING%lectorvenster tevoorschijn als je in het datumveld klikt (in de browser).

De kolom "content" in onze databanktabel verwacht veel tekst. Een klein invoerveld maakt invoer van tekst moeilijk. Daarom kiezen we in dit geval voor een <textarea>-element. Aan dit element geef je eveneens een "name"-attribuut.
Heel wat CMS-systemen vervangen een standaard <textarea>-element door een WYSIWYG-editor, zodat de eindgebruiker net zoals in een tekstverwerker inhouden kan toevoegen.
De functionaliteit van zo'n editor bouw je hoofdzakelijk in de "frontend" met javascript. Via deze link vind je mijn Crowl Mini Editor (een wat minimale versie van de volledige editor die in mijn CMS zit, maar perfect bruikbaar voor jouw opdrachten.
Een website moet op alle toestellen bekeken kunnen worden: smartphones, tablets, laptops, iMacs enz. Als je een lettertype kiest voor je site, moet je er dus ook één kiezen dat op al die toestellen standaard geïnstalleerd is. Dat is minder vanzelfsprekend dan gedacht. Het is best mogelijk dat je een heel mooi lettertype op je computer hebt staan, maar andere mensen hebben dit niet noodzakelijk op hun computer staan. Soms wordt een lettertype samen met bepaalde software geïnstalleerd. De kans dat anderen dit hebben, wordt dan nog kleiner.
Om die reden kan je op websites niet zo maar elk lettertype dat je wenst, gebruiken. Sommige lettertypes mag je zelfs niet online gebruiken omdat het auteursrecht dit niet toestaat.
In CSS bepaal je het lettertype voor een HTML-element met de instructie "font-family". De teksteditor Adobe Brackets toont dan meteen een lijst van alle beschikbare lettertypes voor online gebruik:

De belangrijkste types die we hier uit zullen gebruiken, zijn
| TYPE | UITZICHT | VOORBEELD |
| serif | Lettertype met "voetjes" | Times New Roman |
| sans-serif | Lettertype zonder "voetjes" | Arial, Helvetica |
| monospace | Elke letter krijgt evenveel ruimte (een i is niet even breed als een l, maar krijgt links en rechts witruimte bij zodat elke letter evenveel ruimte in beslag neemt). | Courier |
De lettertypekeuze is dus zeer beperkt. Een "serif"-lettertype zoals Times New Roman, geeft je site een klassieker, traditioneler uiterlijk, een sans-serif oogt frisser.
Als je de aan je body-element de volgende stijlregel toekent, dan kies de browser het standaard "sans-serif"-lettertype dat op het computersysteem aanwezig is (Arial, helvetica....):
font-family:sans-serif;Je kan de browser echter ook suggesties doen:
font-family: 'Avenir Next', helvetica, Arial, sans-serif;Je merkt dat 'Avenir Next' tussen weglatingstekens (of aanhalingstekens) staat. Dat moet je doen als de naam van het lettertype uit meerdere woorden bestaat.
In onze PHP-applicatie kunnen we vanuit onze code vier verschillende opdrachten uitvoeren in de databank:
Afhankelijk van de bedoeling van je applicatie, lijkt het beperken van bepaalde mogelijkheden voor bepaalde gebruikers niet slecht... Ben je niet mee? Een paar voorbeelden:
- - In een blogsysteem mag elke bezoeker wel de artikels lezen, maar niet iedereen mag artikels toevoegen of verwijderen.
- - In een online shop kunnen mensen wel producten toevoegen aan een winkelmand (een "update" van het aantal producten in de databank), maar hij/zij mag geen producten uit de winkel verwijderen of er nieuwe producten aan toevoegen.
- - Op Facebook kan iedereen zijn eigen berichten aanpassen en verwijderen. Maar je kan geen berichten van anderen verwijderen

%PAUZE%
%PAUZE%
%PAUZE%
%PAUZE%
Crowl biedt een open source versie (MIT-licentie) aan van het CMS. Deze versie verschilt grondig van de professionele versie. Crowl::Toddler en Crowl::Master zijn twee zelfstandige producten. Enkel het concept van het werken met artikels en "groepen" van artikels blijft behouden.
Doelpubliek is de webmaster die graag de volledige controle heeft over haar/zijn HTML- en CSS-sjablonen, maar toch aan de klant de mogelijkheid wil bieden om de inhouden van de webpagina's aan te passen.
De webmaster moet 7 stappen zetten:
NIEUWE HANDLEIDINGEN
Gebruik om het even welk HTML-sjabloon (bijvoorbeeld van html5up.net of schrijf er zelf één. Upload je site via FTP in de "root"map.
De basismap van je site kan er dan als volgt uitzien:

In het CMS kan jij of de klant teksten (artikels) toevoegen.
De webmaster kan die artikels nu weergeven in elke gewenste webpagina.
Eén stap is belangrijk: pagina's waarin je artikels wil weergeven, moeten de extensie php hebben. Als je startpagina bijvoorbeeld index.html heet, dan moet je die nu hernoemen naar index.php enz.
Om het gebruik van Crowl::Toddler zo eenvoudig mogelijk te houden, heb ik "abstractie" gemaakt van heel wat PHP-code die je normalerwijze zou moeten schrijven om een databank uit te lezen.
Hierdoor kan je je meer toespitsen op wat je goed kent als webmaster nl. html en css.
1. Voeg de volgende regels toe bovenaan in je webpagina's (opgelet: enkel aan bestanden met de extensie PHP).
<?PHP
include "cms/config.php";
include "cms/io/db.php";
?>2. Bedoeling is dat we één of meerdere artikels uit de databank gaan "opvragen" en die in een HTML-sjabloon (template) gaan plakken. Stel je voor dat we de titel van elk artikel willen weergeven als een <h1> en de tekst (content) als een <p>, dan zouden we de onderstaande code kunnen schrijven.
<?PHP
$template = '
<h1><ct:title/></h1>
<p><ct:content/></h1>
';
?>3. Bedoeling is dat we nu in onze databanktabel een zoekopdracht uitvoeren.
<?PHP
$weergave = new JOURNALIST("se%NOTHING%lect * from articles");
$weergave->PASTE($template);
?>4. De artikels die beantwoorden aan jouw zoekopdracht (se%NOTHING%lect * from articles) worden nu weergegeven in je pagina.
www.schoolvoorbeeld.be/crowlcms/
Donwnload een formulier en een PHP-verzendscript:
Een content-beheersysteemof contentmanagementsysteemis een softwaretoepassing, meestal een webapplicatie, die het mogelijk maakt dat mensen eenvoudig, zonder veel technische kennis, documenten en gegevens op internetkunnen publiceren ( contentmanagement). Als afkorting wordt ook wel CMSgebruikt, naar het Engelse content management system(inhoudbeheersysteem). Een functionaliteit van een CMS is dat gegevens zonder lay-out (als platte tekst) kunnen worden ingevoerd, terwijl de gegevens worden gepresenteerd aan bezoekers met een lay-out door toepassing van sjablonen. Een CMS is vooral van belang voor websiteswaarvan de inhoud regelmatig aanpassing behoeft, en de inhoud in een vaste lay-out wordt gepresenteerd aan bezoekers. De meeste grote bedrijven gebruiken voor hun website tegenwoordig een CMS. Een bekende variatie op het CMS is bijvoorbeeld de weblog.
Naast bovenstaande betekenis van content management (ook wel web content management) wordt de term ook gebruikt voor de bredere variant, enterprise content management(ECM).
Een webmanagerkan voor de invulling van een CMS-website zorgen.
Een CMS bestaat ten minste uit de volgende onderdelen:
Daarnaast kunnen er andere onderdelen zijn:
Een CMS kan worden gebouwd voor een specifieke toepassing, maar er zijn ook generieke CMS'en beschikbaar. Een aantal daarvan is onder een opensourcelicentiegepubliceerd. Deze open source-oplossingen zijn volgens onderzoek voor 77% een goed alternatief [1] voor closed source-oplossing.
Enkele contentmanagementsystemen zijn:
Overgenomen van "
https://nl.wikipedia.org/w/index.php?title=Contentmanagementsysteem&oldid=51219523"
Opgelet: dit schema is niet volledig!

Databankgestuurde websites zijn voor zoekmachines niet altijd even toegankelijk. Dit komt omdat de pagina's niet altijd "echt bestaan", zoals bij een statische HTML-site. Als je een klassieke website bouwt met HTML, dan staat er in de map op server voor elke pagina ook effectief een HTML-bestand.
Bij databankgestuurde websites is dit niet altijd het geval. Stel dat je een site hebt met een zoekformulier, dan wordt de HTML-pagina pas opgebouwd (met behulp van bijvoorbeeld PHP) op het moment dat een gebruiker een zoekterm intikt. Zoals je weet, vraag je dan niet enkel een "bestand" op, maar eveneens een "zoekterm" (query).
Bijvoorbeeld: zoek.php?q=hond
Met een .htaccess-bestand is het mogelijk om zulke "slechtogende" links om te zetten in een meer leesbare waargave.
Bijvoorbeeld: zoek/hond
De techniek om adressen te gaan "herschrijven" tot een meer leesbare weergave, noem je "URL REWRITING".
Je kan een .htaccess niet zonder meer offline aanmaken. Dit komt er immers op neer om een bestand te maken waarvan de naam begint met een ".". Op een Mac OS-systeem is dat enkel weggelegd voor "verborgen bestanden". Als je een .htaccess-bestand aanmaakt op een Mac, zal het m.a.w. niet meer te zien zijn.
Je kan het "offline" aanmaken door het bijvoorbeeld htaccess.txt te noemen. Je plaatst het vervolgens op FTP en je wijzigt daar de naam naar .htaccess.

Met een .htaccess-bestand kan je heel wat bereiken naast URL rewriting:
Opgelet: Een .htaccess-bestand bewerken, is niet meteen weggelegd voor newbies. Een fout in dat bestand, kan je hele site doen vastlopen. Maar anderzijds kan je problemen ook snel oplossen door het bestand leeg te maken of het gewoon te verwijderen.
Als een pagina "contact.php" heet, bijvoorbeeld, dan kan je nu in je HTML-code nu <a href="contact">Ga naar contact</a> invoeren ipv <a href="contact.php">Ga naar contact</a>.
RewriteEngine On
RewriteCond %{REQUEST_FILENAME} !-f
RewriteRule ^([^\.]+)$ $1.php [NC,L] Het is eveneens mogelijk om een map te beveiligen met wachtwoordtoegang.
Opgelet: Hiervoor moet je nog een tweede bestand aanmaken nl. .htpasswd
AuthType Basic
AuthName "Password Protected Area"
AuthUserFile .htpasswd
Require valid-userEen voorbeeld:
test:dGRkPurkuWmW21. Download dit PDF-bestand: https://www.schoolvoorbeeld.be/nodig/scenarios.pdf
2. Vorm een groep van 3 tot 4 personen.
3. De lector geeft aan elke groep een scenario uit het PDF-bestand.
4. Gedurende 3 lesweken werk je in groep het concept van het toegewezen scenario uit.
5. Maak een document en presentatie waarmee je de klant probeert te overtuigen om met jou in zee te gaan. Werk ook een offerte uit waarin je al een relatief nauwkeurige prijsberekening maakt.
6. Tot slot kom je je projectvoorstel of concept verdedigen voor de rest van de groep. Het publiek (je medestudenten en lectoren) zijn op dat moment jouw "potentiële" klanten. Probeer hen te overtuigen.
Deze opdracht staat op 40 punten.
Wat moet je ontwikkelen:
Al je informatie bundel je in een document dat je als een PDF-bestand inlevert. Dat PDF-bestand beantwoordt eveneens aan de huisstijl. De teksten zijn foutloos geschreven. Let op voor plagiaat.
Op het moment van presentatie lever je je plan in in één exemplaar. Je stelt het plan voor met een presentatie. Lees hiervoor grondig de presentatietips. Het is de bedoeling dat je de "potentiële" klanten overtuigt om voor jouw app te kiezen.
https://www.schoolvoorbeeld.be/Multimedia/Verdieping/400
https://www.schoolvoorbeeld.be/Multimedia/Verdieping/402
Kris Merckx & Dave Seré
Ik ben onderweg. Het is zaterdagavond en in het halfduister van de wintermaand rijd ik met de auto, mijn dochter naast me, weer huiswaarts van een schermwedstrijd. We praten wat over de voorbije wedstrijden, over wat we straks gaan eten, over de weg zelf die ik ook vroeger al nam toen zij er nog niet was.
Haar tijdlijn nam een vertrekpunt in 2006, als het startpunt van een lijnstuk uit het vak wiskunde. Een eendimensionaal vertrekpunt van een tijdlijn die zich uitstrekt tot een, voorlopig en hopelijk nog ver in de toekomst gelegen, eindpunt. De huidige halfrechte eindigt dan en blijkt, net zoals het quasi alle levende wezens, maar ook immateriële dingen vergaat, niet meer dan een lijnstuk. Een lijnstuk op een fundament van een universele relatieve tijd die gezien de tweede wet van de thermodynamica niet meer is dan een toename van de entropie van het complexe systeem waarin wij leven. Noem het aarde, universum of hoe je maar wil.

We naderen het kruispunt van de weg die van Grez-Doiceau naar Jodoigne loopt, een zeer gevaarlijk punt. Ik bedenk dat elke onachtzaamheid van mezelf of van een andere âactorâ op die weg, kan leiden tot een dodelijk ongeval waarbij één of meerdere levens worden verwoest. Een slechte statistische inschatting van één of meer neuronen in mijn brein of één van die andere breinen die een toevallig op dat punt in ruimte en tijd aanwezige auto besturen, kan het eindpunt betekenen van één of meer tijdlijnen. Hoeveel toevalstreffers maak je mee om op die manier niet dood te zijn na je eerste rit op de openbare weg?
De tijdlijnen die we in het vak geschiedenis hanteren, zijn eenvoudige lijnstukken die eindigen in het ânuâ. Dat nu ligt niet vast, want het schuift voortdurend met ons mee. Het beginpunt ligt al evenmin vast omdat niemand exact kan stellen wat het precieze begin was. Bovendien hanteert niet iedereen een zelfde beginpunt. Nemen we het begin van de menselijke soort (en welke soort dan?) of nemen we het ontstaan van het heelal als startpunt? Op die rechte van de tijd die schijnbaar ook geen eindpunt heeft, bakenen historici kunstmatig tijdvakken af (lijnstukken) waarvan de begrenzing al even onzeker is als voor discussie vatbaar.
Een rechte, zo leert wiskunde ons, is een lijn die zich uitstrekt van een oneindig beginpunt tot een oneindig eindpunt, en enkel begrensd door haar eigen dimensie, de lengte. Een lijnstuk is een afgebakend gedeelte op een rechte.
Jaren geleden leerde ik werken met het softwareprogramma Macromedia (thans Adobe) Flash. Het doel van dit programma was om interactieve animaties te bouwen. Interactieve software biedt de gebruiker steevast een werkruimte aan, waaraan hij zijn input of inhoud kan toevoegen. In een tekstverwerker start de gebruiker over het algemeen met een A4-blad, dat afhankelijk van de tekst, kan uitbreiden tot een bestand met meerdere A4-vellen. De inhoud bepaalt het aantal vellen papier dat nodig is als je het document wil afdrukken.
Flash hanteerde het concept van een âstageâ, een virtuele toneelruimte, waaraan de gebruiker objecten kan toevoegen. Je kan een rode bal op het scherm plaatsen die doorheen de tijd, van de ene kant van het beeldscherm naar de andere kant rolt, om maar een voorbeeld te geven. Maar je kan ook een poppetje tekenen dat uit meerdere objecten bestaat. Elk onderdeel van zoân poppetje (armen, benen, hoofd, lijfâ¦) herkent een âparentâ object. Als je de arm doorheen de tijd animeert, dan zal ook de positie van de romp en de andere arm wijzigen. Als je de benen laat bewegen om het mannetje van links naar rechts over het scherm te laten lopen, dan beweegt ook het âparentâ element ârompâ mee. Uiteraard bewegen ook de armen mee, omdat zij op hun beurt âchildâ-objecten van het âparentâ-element romp zijn.
Stel dat we het mannetje in een auto steken, dan kan je ook de auto laten bewegen. De tijdlijn van de auto is niet meer dezelfde als die van het mannetje. Elk object, maar ook de âstageâ in zijn geheel had op die manier zijn eigen tijdlijn waar de ontwikkelaar/animator zijn ding mee kon doen. Maar een tijdlijn kon ook ondergeschikt zijn aan de tijdlijn van een bovenliggend, âparentâ object.
Ik haal dit voorbeeld uit de softwarewereld, maar het is voortdurend en overal herkenbaar in de waarneembare wereld. Zelf had ik de trigger van Flash nodig, om de verstrekkende gevolgen ervan in te zien voor ons menselijk concept van geschiedenis en tijd.
Als ik me beweeg, dan beweeg ik me ten opzichte van een referentiepunt. Dat referentiepunt is eveneens relatief. Is het mijn trein of de trein op het spoor ernaast die zich in beweging heeft gezet? De enige manier om dat met zekerheid vast te stellen is door mijn ogen te fixeren op het stationsgebouw. Het station lijkt het perfecte coördinatenstelsel waartegen ik mijn positie kan afwegen. Uiteindelijk ben ook ik in beweging, net als het station, de stad en de hele wereld. De aarde draait op het moment dat ik op de treinzetel zit rustig door terwijl ze simultaan met een naar menselijke maatstaven immense snelheid bezig is aan haar omloop rond de zon. Ook het zonnestelsel met de zon en die hele roterende rimram erbij staat op dat moment niet stil. Ondertussen wordt het heelal weer een stuk groter en dat doet het nog altijd. Welke x- of y-positie kan ik gebruiken om de plaats van de aarde te bepalen? Welk verschil is er tussen de positie van de aarde op het moment dat ik meer dan twintig jaar geleden in de trein zat op weg naar huis en de positie van de aarde in het heelal op het moment dat ik dit neerschrijf of dat je deze tekst leest? Zelfs al zou ik de plaats van de aarde op identiek dezelfde dag en hetzelfde tijdstip meten met de zon als uitgangspunt, dan nog zou de positie âbinnen de ruimteâ nooit meer dezelfde zijn, want ook de positie van het melkwegstelsel in de lokale cluster en die van de cluster in een nog grotere supercluster in het heelal en zelfs de grootte van het heelal zijn ondertussen gewijzigd. Einstein ontkende het idee van een absolute tijd en ruimte om die reden.
Onze eigen tijdlijn of rechte heeft geen absolute ruimte of geen vast referentiekader waartegen we onze persoonlijke geschiedenis kunnen afwegen. Geschiedenis is geen rechte waarop we meerdere lijnstukken afbakenen voor elke âactorâ op de âstageâ. De menselijke geschiedenis is een complexe verzameling van tijdlijnen die elkaar schijnbaar onwillekeurig kunnen beïnvloeden. Universeel lijkt dat de pijl van de tijd altijd in één richting wijst. De tweede wet van de thermodynamica koppelt tijd aan de toename van entropie of omgekeerd, afhankelijk van het perspectief waaruit je dit bekijkt.
Op quantummechanische schaal lijkt alles omkeerbaar. Als je met een camera de beweging van elementaire deeltjes rond een atoomkern zou filmen en die film achterstevoren afspeelt, dan zal niemand weten of de film nu voor- of achteruit loopt. Doe hetzelfde met een filmopname van een terroristische aanslag, en niemand zal verwachten dat dit omkeerbaar is. Een historicus bestudeert het verleden, de omgekeerde richting van de tijd. Dat net zoân onderzoeksobject fundamentele problemen oplevert voor de waarheidsgetrouwe reconstructie, lijkt bijzonder klaar.
Meer nog, het waarheidsgetrouw herstellen of reconstrueren van het verleden, zelfs als dat beperkt blijft tot de menselijke historie, is fundamenteel onmogelijk omdat dit vraagt om, ook al is het dan maar op papier, het omkeren van entropie.
 Wat is entropie? Niets in de klassieke fysica zegt dat de tijd vooruit moet lopen. De natuurwetten die heel het reilen en zeilen van de kosmos regelen, werken immers even goed in de ene richting als in de andere. Waarom zie je dan nooit iemand eerst geboren worden, jonger worden en weer in de moederschoot eindigen? De Amerikaanse theoretische fysicus en kosmoloog Sean Carroll schrijft:
Wat is entropie? Niets in de klassieke fysica zegt dat de tijd vooruit moet lopen. De natuurwetten die heel het reilen en zeilen van de kosmos regelen, werken immers even goed in de ene richting als in de andere. Waarom zie je dan nooit iemand eerst geboren worden, jonger worden en weer in de moederschoot eindigen? De Amerikaanse theoretische fysicus en kosmoloog Sean Carroll schrijft:
(...) langzamerhand nemen steeds meer kosmologen het probleem waar de pijl van de tijd ons voor stelt serieus. Die pijl is gemakkelijk waar te nemen â alles wat u hoeft te doen is een wolkje melk in uw koffie te gieten. Terwijl u een slokje neemt, moet u er eens bij stilstaan hoe die simpele handeling ons helemaal terugvoert naar het begin van ons waarneembaar heelal â en misschien nog wel veel verder.
Carroll heeft het over entropie. Als je koffie en melk mengt in je kopje, dan beschik je over heel wat manieren om de moleculen van koffie en melk zodanig te mengen tot beide volledig in elkaar zijn vermengd (grote entropie). Je beschikt echter over zeer weinig manieren om de koffie en de melk zodanig te verdelen dat ze perfect gescheiden blijven van elkaar (kleine entropie). We zouden dus kunnen stellen dat entropie (de graad van wanorde in een gesloten systeem) de neiging heeft om in de loop der tijd toe te nemen.
In een gesloten systeem zoals een kopje koffie neemt de mate van wanorde toe naargelang de tijd vordert. Hier geldt de tweede hoofdwet van de thermodynamica: bij een omkeerbaar proces is de entropietoename gelijk aan de toegevoegde warmte gedeeld door de absolute temperatuur. Zoân systeem is dus altijd omkeerbaar. Probleem is dat de klassieke fysica altijd vertrekt van herhaalbare en vooral meetbare situaties. Dan kan je niet anders dan een gesloten systeem gebruiken. De chaostheorie stelt echter dat elementen in een wanordelijk instabiel systeem de neiging hebben om zich opnieuw te organiseren in een hogere orde.
Omdat geschiedenis als wetenschap, het verleden van de mens en zijn interactie met tijd en ruimte bestudeert, stuit het hier op fundamentele problemen. Elke historicus zal de vraag krijgen om zijn onderzoek te beperken tot een afgebakend onderwerp in tijd en ruimte. Hij moet m.a.w. een referentiekader opstellen, een soort van gesloten systeem hanteren waartoe hij zijn onderzoek beperkt. Om een vooropgestelde hypothese op waarheidsgetrouwheid te controleren, zal hij data-artefacten, zogenaamde historische bronnen of documenten, raadplegen om een bepaald âfeitâ of punt in het verleden te reconstrueren.
De geschiedwetenschap poogt zich op die manier een experimenteel karakter aan te meten, maar ondervindt al meteen dat ze het verleden niet kan herhalenin een referentiekader. Het gesloten systeem waarvan hij het verleden bestudeert, heeft ondertussen een hogere entropie. Hij kan wel achterhalen, om een eenvoudig voorbeeld aan te halen , dat de inhoud van het kopje dat voor je staat vermoedelijk het gevolg is van een vermenging van melk en koffie en wellicht ook aantonen dat de verhouding van het ene element vermoedelijk groter was dan verhouding van het andere element. Maar âgeschiedenisâ, een bepaalde momentane historische toestand, is zelden het resultaat van het combineren van eenvoudige ingrediënten. Geschiedwetenschap moet immers rekening houden met individuele tijdlijnen van alle actoren in het historische spel en hun onderlinge interactie.
Kris Merckx - 24 januari 2019
Op welke manieren laat jij zelf allemaal sporen achter op internet. Overloop een normale dag uit je leven. Waar laat je digitale sporen achter? Op welke momenten word je niet ergens geregistreerd?
Maak een lijst in XLS van sporen die je vandaag vermoedelijk al hebt achtergelaten.
Welke sporen laat ieder van ons achter? We mailen, posten op sociale media, maken bestanden op onze computer. Al die digitale activiteit laat sporen achter. Van sommige sporen zijn we ons bewust, van andere heel wat minder. In winkelstraten hangen, al dan niet slimme, cameraâs die onze bewegingen registreren op zoek naar verdacht gedrag. Ze registreren niet alleen, maar bewaren hun gegevens ook voor eventuele latere analyse.
Langs steenwegen en snelwegen installeert de overheid steeds meer cameraâs voor trajectcontrole. Iedereen is een potentiële verkeersovertreder en dat zullen we geweten hebben. Waar worden al deze data bewaard en hoe gaat dit precies in zijn werk? Wat gebeurt er met al deze data? Wie heeft die data in handen? Hoeveel data produceren we op één enkele dag?
Open het lesbestand: bigdata.pdf

ghjhdfghfgh
Het is altijd goed te weten waarover je aan het praten bent. Een computer. Iedereen heeft er wel een. Maar probeer het begrip even te definiëren.
Euh⦠het is een toestel met een scherm, muis, toetsenbord en binnenin zitten een harde schijf, een moederbord, RAM-geheugen, een grafische kaart.
Zoân definitie zegt bijzonder weinig over de functionaliteit van het toestel. Wat betekent het concept âcomputerâ. Het woord âcomputerâ is afgeleid van het Engelse werkwoord âto computeâ wat berekenenbetekent. Nochtans kan een hedendaagse computer doorgaans wel wat meer dan een rekenmachine. Een computer voert berekeningen uit. In één seconde vaak meer dan wat je zelf in je hele leven zou uitrekenen als je iets moet tellen. Je leert later nog wat een computer dan zo al allemaal berekent.
Laat ons even kijken naar wat een computer allemaal kan en doet:
Maar al die kenmerken gelden lang niet voor alle toestellen die wij als een âcomputerâ beschouwen. Zo kan je auto een computersysteem bevatten met één enkele taak. Een âcomputerâ in je auto zal bijvoorbeeld wel bepaalde functies in je auto controleren, maar zal daarom niet noodzakelijk uitvoer tonen.
A computer is a machine or device that performs processes, calculations and operations based on instructions provided by a software or hardware program. It is designed to execute applications and provides a variety of solutions by combining integrated hardware and software components.â¨â¨ (Bron: www.technopedia.com )
Het lijkt niet zo eenvoudig om een duidelijke definitie van het begrip âcomputerâ op te stellen. Zelfs de bovenstaande definitie is niet helemaal volledig. Immers, als in deze definitie âmachineâ en âdeviceâ vervangt door organism, dan blijkt dit ook voor een groot stuk te kloppen voor levende wezens.
A living organism is a biological system that performs processes, calculations and operations based on instructions provided by its DNA, genes, epigenes... It executes tasks and provides a variety of solutions by combining integrated biological organs and brain tissue
Om precies te begrijpen wat het begrip âcomputerâ betekent, moeten we zoân toestel zien in het kader van de volledige technologische evolutie.
Technologie (en dus ook âcomputersâ) is in hoofdzaak bedoeld om bepaalde taken van de mens makkelijker te maken. Het is nu eenmaal eenvoudiger om met een hamer een spijker in de muur te slaan, dan met je blote vuist. Handenarbeid, maar vooral repetitieve taken kunnen makkelijk geautomatiseerd worden. Automatisering is niet nieuw. De eerste vormen van automatisering in de industrie zijn al minstens een paar eeuwen oud. De eerste industrie die in grote mate werd geautomatiseerd was de textnielnijverheid. Niet verwonderlijk werd de ponskaart, de verre voorloper van opslagmedia zoals CDâs, het eerst op industriële wijze gebruikt bij weefgetouwen.

Een automaat voert een reeks stappen na elkaar uit. Steeds in dezelfde volgorde. Het toestel volgt hierbij een vast programma (doe eerst dit, daarna datâ¦). We kunnen zoân programma ook een recept of algoritme noemen. Sommige automaten doen altijd exact hetzelfde programma. Andere toestellen kan je gedeeltelijk of geheel herprogrammeren.
<FOTO MUZIEKDOOSJE>
<FOTO ORGEL BEIAARD= HERPROGRAMMEERBAAR>
Automatisering (toestellen die een reeks stappen na elkaar kunnen âafwerkenâ) en machines die berekeningen uitvoeren (âcomputersâ) zijn zeer oud. Dit soort van herprogrammeerbare automaten bestond reeds in de Klassieke Oudheid. Mensen als Heron van Alexandrië (eerste eeuw na Christus) bouwden al herprogrammeerbare toestellen.
<FOTO HERON>
Robots in autofabrieken zijn bijzonder beperkt in wat ze kunnen. Ze voeren altijd datzelfde strakke schema uit. Je kan een robot die geprogrammeerd is om deuren aan een autocarrosserie te bevestigen, niet inzetten om chocoladerepen in dozen te steken, bijvoorbeeld. Zulke robots zijn niet âintelligentâ, ze voeren een strak algoritme uit. Eventueel kan je wel gedeeltelijk herprogrammeren om met andere automodellen te werken. Dan pas je een aantal parameters aan waardoor de grijparmen zich net iets anders gedragen.
Een computer werkt in wezen net iets anders. Een computer ontvangt instructies of invoer en berekent op basis van die invoer een eindresultaat. Een eenvoudig voorbeeld is een klok. Je stelt met een aantal draaiknopjes de wijzers in (invoer) en je verwacht dat de klok je op elk gewenst tijdstip in de toekomst (zo lang de klok nog voldoende âenergieâ heeft) het correcte tijdstip geeft (output). Tussen die âinvoerâ en âuitvoerâ zit er een ingewikkeld mechanisme van radertjes. Om van invoer naar de correcte uitvoer te gaan, ligt in het mechanisme van de klok eveneens een programma vast. Als de klokkenbouwer zijn werk niet goed doet, toont de wijzerplaat (de ouput-interface) de foute tijd.
Klokken en klokken met meerdere wijzerplaten als âoutputâ zijn de oudst bekende voorbeelden van computers. De computer van Antikythera werd opgevist uit de Egeïsche Zee en is meer dan 2200 jaar oud.
<FOTO ANTIKYTHERA>
Natuurlijk staat een klok een groot stuk verder in de technologische evolutie dan een hamer. Een hamer maakt handenarbeid lichter, maar zowel de energie als besturing liggen nog steeds bij de mens. Een klok of automaat of robot⦠nemen ook de stuurfunctie over. De besturing, het uitvoeren van de juiste stappen, is vastgelegd in een mechanisme of in een programma.
Een lichtschakelaar bijvoorbeeld, heeft geen eigen stuurfunctie. Je moet er zelf nog op drukken om beter te kunnen zien in het donker. Een domoticasysteem dat je verlichting zelf inschakelt als het donker wordt, bevat wel een zeker stuurfunctie. Het gebruikt input van een lichtsensor om de juiste âoutputâ (lampen al dan niet inschakelen) te geven.
De laptop die voor je neus staat of je smartphone zijn âcomputersâ die heel wat taken op zich nemen. Met een smartphone kan je niet alleen bellen, maar dat hoeft ook niet meer uitleg. Zulke toestellen hebben meerdere functies (multi-purpose) en kunnen vaak ook meerdere taken tegelijk uitvoeren. Je kan bijvoorbeeld tegelijk informatie opzoeken op het world wide weg en tegelijkertijd je scriptie schrijven, terwijl het toestel ook nog muziek afspeelt via Spotify. Je zal wel al gemerkt hebben dat je computer wel erg traag kan worden als je te veel taken tegelijk uitvoert.
Sommige computers voeren echter slechts één bepaalde taak uit. Waarom dit zo is, lees in het volgende onderdeel.
Elke classificatie van computers is vaag. Computers zijn lang niet allemaal digitaal, zoals vele mensen nu wel denken. De oudste computers (zie vorige deel) waren âanaloogâ en âmechanischâ. In de loop van de twintigste eeuw kwamen de eerste elektronische computers. Wat de begrippen âanaloogâ, âelektronischâ en âdigitaalâ nu precies betekenen, kom je verderop te weten.
Je kan computers indelen naargelang hun hardware, snelheid, grootte, kost, functionaliteitâ¦
Een kort overzicht van diverse computersystemen uit onze tijd:
Supercomputerskosten bijzonder veel geld. De kost wordt in grote mate bepaald door de rekenkracht. Dit soort systemen worden ingezet voor simulaties (bijvoorbeeld weerfenomenen) en wetenschappelijk onderzoek. Mainframesystemenduiken op bij zeer grote bedrijven en banken voor ondermeer het verwerken van banktransacties. Een mainframesysteem kan jarenlang ongestoord doorwerken en onderhoud kan worden verricht terwijl het systeem gewoon doordraait. Supercomputers en mainframesystemen hebben eveneens een besturingssysteem nodig. Ze werken doorgaans op een UNIX- of LINUX-besturingssysteem. Je zal geen supercomputer of mainframesysteem tegenkomen dat werkt op Windows of Mac OS.
S erverszijn een wat vreemde eend in de bijt. Je kan immers elke computer omtoveren in een server. Een server is een soort van centrale computer waarmee je verbinding kan maken. Uiteraard zijn die heel erg belangrijk in onze tijd. Op webservers plaatsen webmasters hun websites. Maar servers zijn ook noodzakelijk voor quasi alle andere vormen van internetcommunicatie waarmee meerdere toestellen met elkaar verbindingen proberen te leggen.
W orkstationszijn krachtige computersystemen die bijvoorbeeld in de film- of muziekindustrie worden gebruikt om film te monteren of 3D-beelden te renderen. Meestal gaat het hier om krachtige varianten van de systemen die ook gewone consumenten gebruiken, maar uitgerust met speciale toetsenborden en meerdere monitoren.
De PC/Microcomputer, n otebooks en laptopszitten in het marketingsegment van de gewone consument, net zoals handhelds (tablets, kleine spelconsoles) en mobiles (smartphones).
E mbedded systemenzijn een laatste niet te onderschatten segment. Het aantal embedded computersystemen neemt exponentieel toe. Vooral omdat deze toestellen stilaan ook veelvuldig worden aangesloten op het internet. Men spreekt in dit geval van het IoT (internet of things).
In de les bouw je samen met de lector een programma in Processing. We doen dit stapsgewijs.
Belangrijke begrippen die je leert kennen en moet begrijpen na de les:
Je bouwt samen met de lector de code. Daarna ga je zelf aan de slag. Je breidt de basiscode verder uit met meer functionaliteit. Je uitbreiding(en) moeten gebruik maken van de volgende mogelijkheden:
Uiteraard staat het je vrij om nog andere opties en mogelijkheden toe te voegen.
Je bewaart je code en je uploadt het PDE-bestand via Toledo.
 Concepten van data & analytics
Concepten van data & analyticsWe werken met data,
maar hebben geen idee
hoe data werken.
tekstbestanden, gestructureerde bestanden, databanken...
 4. Leren van data
4. Leren van dataAlgoritmes
Data-analyse
Machine learning en deep learning
Predictive analysis
Data visualiseren
 Databanken
DatabankenEen databank is een manier om data op een gestructureerde manier te bewaren. Dit maakt het mogelijk om gegevens snel terug te kunnen vinden.
De cursustekst over databanken vind je hier:
https://www.schoolvoorbeeld.be/nodig/data/databanken.pdf
Op een computer kan je door de VR-ruimte navigeren met je muis of met de pijltjestoetsen. Rechts onderaan vind je een VR-knop om over te schakelen naar volledig scherm.

In principe ben jij het centrum van de "ruimte".
Jij (de kijker) bevindt je op positie x=0, y=0, z=0. Het horizontale vlak geeft de X-waarde weer, het verticale vlak de Y-positie. Evenwijdig met de kijkrichting bevindt zich het Z-vlak.
In VR kijk je in theorie door een virtuele camera. Standaard komt de positie van de camera overeen met de kijkrichting van de gebruiker. Je kan de camera net zoals een echte camera ook "roteren" over zijn 3 assen.
Wanneer de gebruiker een VR-bril draagt, komt de kijkrichting overeen met die van de VR-bril. Je kan de positie van de camera wijzigen door aan de scene een camera toe te voegen.
<a-camera position="0 3 -13"></a-camera>
1. Voeg de volgende twee regels toe aan de head van alle webpagina's waarin je icoontjes wil gebruiken.
<link rel="stylesheet" href="https://maxst.icons8.com/vue-static/landings/line-awesome/line-awesome/1.3.0/css/line-awesome.min.css">3. Klik op het gewenste icoontje.
2. Ga naar https://icons8.com/line-awesome
3. Klik op het gewenste icoontje.
4. Een popup verschijnt.

5. Kopieer het stukje HTML-code onderaan het popupvenster.
6. Plak de gekopieerde code op de gewenste plaats in het body-element van je webpagina.
 Servomotor aansturen met Arduino (voor wie nog wat meer wil, niet verplicht...)
Servomotor aansturen met Arduino (voor wie nog wat meer wil, niet verplicht...)Sluit uw kabels rechtstreeks aan op de ingangen van de servomotor.
Plak de volgende code in de IDE:
#include <Servo.h>
Servo myservo;
int pos = 0;
void setup() {
myservo.attach(9);
pinMode(13, OUTPUT);
}
void loop() {
for (pos = 0; pos <= 180; pos += 1) { // goes from 0 degrees to 180 degrees
// in steps of 1 degree
digitalWrite(13, HIGH);
myservo.write(pos); // tell servo to go to position in variable 'pos'
delay(15); // waits 15ms for the servo to reach the position
}
for (pos = 180; pos >= 0; pos -= 1) { // goes from 180 degrees to 0 degrees
myservo.write(pos); // tell servo to go to position in variable 'pos'
delay(15); // waits 15ms for the servo to reach the position
digitalWrite(13, LOW);
}
}Hoe maak je teken- en animatiefilm?
OPGELET: als de film te "lage kwaliteit" heeft, klik dan op het tandwieltje rechts onderaan in de film. Kies de hoogste resolutie
Animatietechnieken:
COURSE COMPLETE
Web pages are built in the HTML language. That language gives structure to pure text data.
A number of larger online platforms also offer other output formats than just HTML. For example, you can extract data from Wikipedia in the form of JSON data. This is especially useful if you want to develop your own software that uses data from other websites. In some cases this is free, in other cases you have to pay for such a service. After payment you will receive an authentication key that you must include in your programming code.
To retrieve the data, it is often sufficient to build a URL correctly. The technique to request information in standardized and / or structured formats is called REST (Representational state transfer).
Watch the movie to see how you have to start with the exercises.
To be able to use REST in a handy way, you need to know how a URL of a web page is structured. In many cases you can perform a search in the underlying database via the URL.
If you search for "ucll" in Google and press the search button, the following URL will appear in the address bar:
After the domain name www.google.be/follows the webpage or web service with the name "search" and a question mark. If you look closely at everything that appears behind the question mark, you will see key and value pairs separated by an "&" sign.
The following key-value pairs are of interest to us:
| Key | Value |
| oq | ucll |
| q | ucll |
| ... | ... |
We can now prepare links ourselves:
https://www.google.be/search?q=YOURQUERY
You will notice that that link works perfectly, without all those other parameters from the previous link. Cool, we used the Google Search Engine REST API to generate custom search results.
Base URL: https://www.googleapis.com/books/v1/volumes?
| Key | Value |
| q | a search term (string or string) |
| maxResults
|
The number of results you want to get (integer) |
| startIndex
|
the point from where you want to start (integer) |
Example: https://www.googleapis.com/books/v1/volumes?q=Kris%20Merckx%20in%20geen%20tijd&maxResults=1&startIndex=0
Example of a "book service" built with the Google Books API:
https://www.drukhier.be/booksprint/apps/biblio/bib.php?search=Kris+Merckx+in+geen+tijd

Base URL: http://nl.wikipedia.org/w/api.php?
| Key | Valye |
| action | query |
| list | search |
| srsearch
|
your search term (string) |
| format | jsonfm ... |
Example: http://nl.wikipedia.org/w/api.php?action=query&list=search&srsearch=Charles Darwin&format=jsonfm
Base URL: https://nominatim.openstreetmap.org/search?
| Key | Value |
| format | html, xml, json, jsonv2, geojson, geocodejson
|
| street | house number street name |
| city | municipality |
| county | county name |
| state | state |
| country | country |
| postalcode | postal code |
| q | your search term (string) |
Example: https://nominatim.openstreetmap.org/search?format=geocodejson&street=77%20Processieweg&city=Hakendover&postalcode=3300
1. The order of the keys in the construction of the URL is of no importance.
2. Not all keys are required. However, some are necessary. You will notice that by playing around with it.
You already received the assignment in PDF. Upload your exercises in Toledo.
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis. (Source: https://en.wikipedia.org/wiki/Web_scraping)
VIDEO WILL FOLLOW
Kris Merckx - 2020
Een computer kan met behulp van software een heleboel taken automatiseren om de mens werk uit handen te nemen en vooral de benodigde (werk)tijd te verkorten. Toch beseffen velen nog steeds niet hoe ze dat precies moeten doen. De zoek-en-vervangopdracht in een tekstverwerkingsprogramma is daar een simpel voorbeeld van. In heel wat software kunnen steeds weerkerende taken met behulp van zogenaamde macroâs geautomatiseerd worden. Je voert een aantal taken uit terwijl de computer de uitgevoerde opdrachten stapsgewijs registreert. Nadien kan hij zelfstandig die taak herhalen. De lijst met instructies is vastgelegd in het geheugen van de computer. In automaten zitten de instructies eveneens in de machine.
De kennis van het bouwen van klokken en automaten ging niet volledig verloren in de middeleeuwen. Meer nog, heel wat kerken en kathedralen zijn uitgerust met op 'pinmechanismen' gebaseerde automaten. De kennis die Heron demonstreerde met zijn automatische theaters, was dus zeker niet verloren gegaan. Klokken, automaten, muziekdozen... Ze kenden een gemeenschappelijke evolutie en kruisbestuiving die rechtstreeks een invloed zou uitoefenen op de moderne computer- en robottechnologie.
In de loop van de eeuwen werden mechanische muziekapparaten ontwikkeld in opdracht van en voor de rijkere klassen (adel en geestelijkheid). De geschiedenis van de mechanische muziek is nauw verbonden met die van de klok en automatische poppen en beelden. In het Engels maakt men een onderscheid tussen de woorden clocken timepiece. Clockverwijst altijd naar het mechanische geluid dat het uurwerk produceert, terwijl een timepiecewel het tijdstip aangeeft, maar hierbij geen geluid laat horen.
Zowel in de moslimwereld als in het christelijke Westen waren klokken essentieel in de godsdienst beleving. Ze gaven aan wanneer de momenten van gebed en bezinning waren aangebroken. De historische bronnen zijn niet altijd volledig en vaak worden uitvindingen onterecht toegeschreven aan een bepaalde persoon of zelfs regio.
Het mag duidelijk zijn dat de ingenieurs in het Oosten en het Westen te rade zijn gegaan bij de klassieke voorbeelden, en soms eigen toevoegingen hebben gedaan. Bovendien werd niet altijd een strikt onderscheid gemaakt tussen klokken, automaten en mechanische muziekinstrumenten.
In wezen vinden we in de muziekdozen twee verschillende, maar toch op elkaar lijkende technieken:
Beide worden aan het draaien gebracht, waarbij ofwel de pinnen ofwel de gaten instructies doorgeven aan de rest van het mechanisme. Zonder twijfel is de cilinder met pinnen de oudste vorm voor het mechanisch doorgeven van instructies, zoals het produceren of reproduceren van muziek. Heron van Alexandrië (eerste eeuw na Chr.) maakte er al gebruik van.
Voor het oudst bekende door cilinders aangestuurde mechanische muziekinstrument moeten we naar het Bagdad van de 9e eeuw. De drie gebroeders Ahmad, Muhammad en Hasan bin Musa ibn Shakir, beter bekend als de BanÅ« MÅ«sÄ(zonen van Mozes, naar de naam van hun vader), waren in opdracht van de Abassidische kalief al-Maâmun actief in de astronomische observatoria van Bagdad en in het zogenaamde Huis van de Wijsheid (Bayt al-Hikma). Naar verluidt stuurden ze boodschappers naar onder meer Byzantium om op zoek te gaan naar originele of gekopieerde klassieke teksten over wetenschap en techniek. Muhammad zou zelf ook naar Byzantium zijn gereisd. Maandelijks betaalden ze meer dan 500 dinar aan een groep vertalers die de overgebrachte klassieke werken omzetten in het Arabisch.
...
In opdracht van de kalief verifieerden ze de door Eratosthenes berekende omtrek van de aarde, wat bewijst dat ze niet alleen goed onderlegd waren in de astronomie, maar ook in de wiskunde. De meeste bekendheid verwierven ze echter door hun boek KitÄb Al-Hiyal (Het boek van ingenieuze apparaten). Heel wat toestellen in dit boek zijn duidelijk geïnspireerd op de ontwerpen van onder meer Heron van Alexandrië, Philo van Byzantium en oudere Perzische, Indiase of misschien zelfs Chinese uitvindingen.
Toch hebben de broers overduidelijk hun eigen stempel gedrukt en veel ingenieuze toevoegingen bedacht. Het verschil zat hem in het gebruik van onder andere automatische zwengels, ventielen en conische kleppen als automatische reguleersystemen. Als geen ander wisten ze om te gaan met kleine variaties in aerostatische en hydrostatische druk om net dat doel te bereiken dat ze voor ogen hadden.
Een voor ons uitgangspunt belangrijk apparaat in de KitÄb Al-Hiyal is de automatische fluitspeler. Het toestel vindt zijn voorlopers overduidelijk in het werk van de Alexandrijnse ingenieurs Ktesibios, Heron en Philo van Byzantium. Velen zien de automatische door waterkracht aangedreven fluitspeler van de Musa-broers als het eerste programmeerbare muziekinstrument. Door de uitgebreide beschrijving van het uiterlijk en de werking weten we dat het toestel ook echt heeft gefunctioneerd en dat het niet zomaar gaat om een legende. Het zou ons te ver leiden als we de volledige werking van het toestel hier zouden uitleggen, maar we beperken ons tot het meest essentiële onderdeel: de programmeerbare trommel of cilinder om de melodie vast te leggen of weer te geven.

Door een fluit werd een constante luchttoevoer geblazen. Net zoals bij een blokfluit was hun automatische fluit voorzien van openingen voor de diverse âvingerzettingenâ. Dempers sloten de openingen van de fluit luchtdicht af. De dempers waren op hun beurt bevestigd aan houten armpjes of lichters. Een groot tandwiel werd in beweging gebracht door een constante waterstroom. Dat zette op zijn beurt een kleiner tandwiel in beweging dat een trommel of cilinder liet roteren. Op de cilinder waren vermoedelijk houten pinnen aangebracht die tijdens het roteren de armpjes of lichters naar beneden drukten, waardoor de dempers van een of meerdere openingen werden opgelicht, de lucht kon ontsnappen en de melodie weerklonk. Het spreekt voor zich dat de snelheid van de watertoevoer bepalend was voor de snelheid van het afspelen van de muziek. Ze voorzagen in hun beschrijving ook de mogelijkheid om de hele constructie te verbergen in een standbeeld van een fluitspeler, waarbij de vingers werden benut als lichters en de trommel werd verstopt in de mouw.
Een nog veel grotere uitdaging was het vastleggen van de melodie. Ook daarbij gingen ze uiterst inventief te werk. Hun beschrijving om de vingerzettingen van een echte fluitspeler te registeren en die melodie op de cilinder over te zetten, is niet alleen zeer duidelijk maar vooral ook onwaarschijnlijk ingenieus! De Musa-broers lieten zich hier duidelijk inspireren door de houten, met was bestreken bordjes die de leerlingen van de basisschool van Byzantium als schrijftabletjes gebruikten. Ze bestreken een houten of messing cilinder met zwarte was. Een constructie van lichters werd aan één zijde aan de vingers van een echte fluitspeler bevestigd.
Aan de andere kant hechte men er stiften aan die boven de met was bestreken trommel hingen. Wanneer de fluitspeler zijn melodie speelde, tekenden de stiften in de was van de roterende trommel een patroon telkens als de fluitspeler zijn vingers oplichtte. Zo verkregen ze een nagenoeg perfecte weergave van de melodie in de waslaag. Gelijkenissen met de eerste fonograaf met wassen cilinders van Edison zijn hier niet uit de lucht gegrepen! Uiteraard moesten ze dit patroon dan nog overzetten op een kleinere cilinder.
Niet alle onderdelen of uitbreidingen van de automatische fluitspeler zijn even goed uitgewerkt, maar de broers zagen duidelijk een massa mogelijkheden. Zo bedachten ze dat het mogelijk moest zijn om de cilinder opzij te laten schuiven nadat een melodie afgespeeld was. Dat wilden ze bereiken door de trommel met een touw vast te maken aan een vlotter. Door op het juiste moment een watervat met sifon te laten leeglopen, kon de zakkende vlotter de trommel opzijtrekken en vervangen door een andere.
In Toledo wekte de waterklok van al-Zarqali in de 11e eeuw verbazing en ontzag. In de 12e eeuw bouwde de ingenieur Badi al-Zaman al-Jazarieen tot de verbeelding sprekende waterklok in de vorm van een Indische olifant met op zijn rug Chinese draken, een feniks en allerlei Arabische figuren. Hij beschreef de klok uitgebreid in zijn Kitab fi maârifat al-hiyal al-handasiyya (Boek der kennis van mechanische toestellen).
...
Net zoals de BanÅ« MÅ«sÄ liet hij zich inspireren door klassieke voorbeelden. In het christelijke Praag werd de astronomische klok in de 14e eeuw uitgerust met een reeks âautomatenâ. In Europa waren vooral de Lage Landen en Zuid-Duitsland toonaangevend. Samen met zijn vader verhuisde de klokkenmaker Nicholas Vallin (1558â1603) in de jaren 1580 vanuit Rijsel (Lille) naar Engeland. Het British Museum bewaart nog steeds een prachtexemplaar van een muzikale kamerklok van zijn hand. Het toestel heeft een wijzerplaat met wijzers voor uren en minuten. Elk kwartier speelt de klok een ander stukje muziek op de dertien bellen die bovenaan bevestigd zijn. Naar klassiek voorbeeld wordt de klok aangedreven door gewichten.
De Alexandrijnse ingenieur Ktesibios rustte in de derde eeuw voor Christus zijn waterklokken al uit met zingende vogels. De automatenbouwers van de 18e eeuw wilden hun vogels niet alleen laten zingen, maar vooral ook levensecht maken. Beroemd is de mechanische eend van Jacques de Vaucanson (1709â1782), die kon eten, drinken en... uitwerpselen produceren. De Londense juwelier en goudsmid James Cox (1723â1800) liet zich door de juiste mensen omringen om zijn ongebreidelde fantasie in de realiteit om te zetten. Zijn roem bezorgde hem klanten in oost en west. In 1772 opende hij een eigen museum, de Spring Gardens, waar hij zijn automaten onderbracht. Om de kosten van deze wel erg dure operatie te drukken organiseerde hij loterijen in Londen en Dublin. In de collectie van het Hermitagemuseum in Sint-Petersburg bevindt zich nog steeds de Peacock Clock, een prachtige automaat van Cox bestaande uit onder meer een mechanische pauw, haan en uil en een wijzerplaat verstopt in een paddenstoel. De automaat is nog steeds het pronkstuk van het museum en bovendien de enige nog resterende 18e-eeuwse automaat.
Om ruimte te besparen verving Antoine Favre-Salomon (1734â1820), een klokkenmaker uit Geneve, in 1796 de belletjes door een kam met voorgestemde metalen noten. Daardoor konden uurwerkmakers mechanische muziektoestellen inbouwen in veel kleinere toestellen. Zijn stadsgenoot Isaac Daniel Piguet (1775â1841) zou vier jaar later de cilinder vervangen door een horizontaal geplaatste schijf met pinnen. Nauwelijks elf jaar later nam de productie van muziekdozen ongeveer 10% in van de Zwitserse export, waarmee ze de verkoop van uurwerken en kant ruim voorbijstak. Voor het eerst bereikten de muziekdozen een groter publiek.

En wat met Leonardo die zo wat overal opduikt en vaak wordt afgeschilderd als het grote genie van de renaissance?
Leonardo da Vinci was niet alleen schilder, maar ook ingenieur en beeldhouwer. Hij las gretig de vertalingen van Heron en Vitruvius, en bestudeerde de verschillende onderdelen van de machines. Hij noemde ze de âelementenâ of âorganenâ van de machines. Door die onderdelen op allerlei manieren te combineren kon je in zijn ogen een oneindig aantal machines bedenken en bouwen. Wanneer je de werken van Da Vinci bekijkt, doen ze vaak denken aan de handleidingen uit dozen Lego® Technics.
Modulair ontwerp, zoals dat tegenwoordig ook opduikt bij het zogenaamde object-georiënteerde programmeren, duikt dus ook al in zijn geschriften op.
In zijn teksten beschreef hij welke soorten schroeven, tandwielen, vliegwielen, kogellagers, kettingen, veren, katrollen enzovoort er bestaan en hoe je ze maakt. Hij voorzag zijn teksten van uitgebreide technische tekeningen in perspectief. Zelf ontwierp hij een hele reeks machines: oorlogstuig zoals mortieren en tanks, baggerschepen, vliegtuigen, een helikopter, een duikpak, een hydraulische zaag... Velen denken dat hij prototypes van die geniale vondsten zelf heeft uitgetest. Toch is het grootste deel van zijn uitvindingen nooit in praktijk gebracht.

Leonardo da Vinci was ervan overtuigd dat de natuur geen levende wezens kan laten bewegen zonder daarbij gebruik te maken van âmechanische onderdelenâ. Daarom voerde hij in het geheim dissecties uit op lijken om de werking van de menselijke organen en spieren te bestuderen. Uit wat hij leerde, raakte hij ervan overtuigd dat het mogelijk moest zijn om organen of werkende organismen na te bouwen. Eeuwen voordat ze opnieuw werd ontdekt, vond hij aderverkalking en de oorzaak ervan. Door het nauwkeurig bestuderen van botten en spieren slaagde hij erin om de eerste ârobotsâ te bouwen die zich âzelfstandigâ konden bewegen.
In 1550 schreef Giorgio Vasari (1511â1574) in zijn boek over het leven van de belangrijkste Italiaanse kunstenaars:
"Toen Leonardo da Vinci in Milaan was, kwam de koning van Frankrijk op bezoek. Hij vroeg hem iets speciaals te doen. Da Vinci ging aan de slag en presenteerde hem een leeuw die een paar stapjes zette en zijn borstkas opende, waar tal van lelies uit tevoorschijn kwamen."
De Amerikaanse robotexpert Mark Rosheim bestudeerde de Codex Atlanticus van Da Vinci in de hoop sporen te vinden van die robotleeuw. Hij is ervan overtuigd dat Da Vinci de leeuw op een mechanisch programmeerbaar wagentje had geiÌnstalleerd. Een veermechanisme deed wielen draaien, die op hun beurt kleinere wielen in beweging zetten. Die stuurden houten armen aan, waaraan een soort schaarmechanisme was bevestigd. Door de armen volgens een vastgelegd plan te laten bewegen kon het karretje rijden en ook draaien.
Leonardo was niet de enige die vruchtbaar gebruikmaakte van de kennis van automaten die via vertalingen van klassieke en hellenistische werken doorsijpelde. Gedurende de middeleeuwen, die vaak als een donkere periode zonder vooruitgang worden afgeschilderd, kenden automaten en klokken een sterke ontwikkeling. Leonardo is dus niet het grote genie die het programmeren van robots heeft bedacht. Hij kon buigen op een grote traditie in Europa, een traditie die haar oorsprong vond in het Egyptische Alexandrië van de oudheid.

Basile Bouchon, zoon van een orgelbouwer, bedacht al in 1725 een manier om een weefgetouw aan te sturen met een geperforeerde rol papier. Bouchons vader maakte cilinders met pinnen voor orgels. Om de pinnen op de juiste plaatsen aan te brengen in de cilinder, tekende hij eerst een patroon op een kartonnen plaat. Die plaat draaide hij vervolgens om de cilinder waardoor hij precies wist waar hij de pinnen in de cilinder moest slaan. Basile meende dat het handiger zou zijn de kartonnen platen zelf te gebruiken. Het was Jacquard die het systeem als eerste succesvol wist te implementeren.

Het
ponskaartsysteemzien we in de 19e eeuw ook opduiken in muziekdozen en pianolaâs. Ponskaarten werkten op een vergelijkbare manier als pin- of kamsystemen. In het geval van muziekdozen kon door de gaatjes lucht van een blaasbalg ontsnappen of er konden pinnetjes door schieten die instructies gaven aan de rest van het mechanisme. Bij Jacquard sprongen pinnen op door de openingen in de ponskaarten en lieten het weefgetouw een bepaald patroon weven. Het grootste voordeel van een ponssysteem was dat je veel meer instructies achter elkaar kon laten uitvoeren door de machine. Bij een cilindersysteem met pinnen of kammen was je beperkt door de omtrek van de cilinder. Ponsplaten kon je oprollen of opvouwen en door het mechanisme laten schuiven bij het uitvoeren van het programma. De wevers van Lyon vreesden voor hun werk en verbrandden het weefgetouw in 1808, zo vertelt het verhaal. Blind protest tegen een niet te stuiten innovatie. Maar dit verhaal klopt niet. Van die brand is helemaal geen sprake geweest. Het verhaal duikt voor het eerst op aanvang 19e eeuw.
Al snel zag men ook op andere vlakken van de samenleving het nut van een ponskaartsysteem. Je kon op een ponskaart allerlei soorten informatie in gecodeerde vorm opslaan en het geautomatiseerd laten uitlezen. Charles Babbage(1791â 1871) tekende plannen voor een analytische rekenmachine en voorzag de invoer van ponskaarten. Zijn plannen betekenden een serieuze stap voorwaarts in de ontwikkeling van een rekenmachine. Eerder bouwde de Fransman Blaise Pascal (1623â1662) een mechanische rekenmachine, maar die was nooit een succes geworden. Ook de machine van Babbage kwam niet veel verder dan de ontwerptafel.
De computer met ponskaarten van Babbage baande via bedrijven als IBM zijn weg naar de moderne industrie. Die veroveringstocht kwam nog niet tot zijn einde.
Zo lijkt dit verhaal rond. Mijn ontdekkingstocht naar de oorsprong van computertechnologie, robotica, programmeren en automatisering, begon op de zolder bij mijn ouders. Het bracht ons tot het Alexandrië van de Klassieke Oudheid. Misschien een woordje meer over dit Silicon Valley van de Klassieke Oudheid.
Elk bestaand digitaal afbeeldingsformaat valt wel te "converteren" met XNview.
Je kan XNview downloaden via www.xnview.com
HTML is geen programmeertaal, maar een markeertaal waarmee je het begin en einde van elk element in een tekst aanduidt.
Met WOBBEL oefen je online in HTML, CSS en javascript.
De eerste typemachine gebruikte een klavier van een piano als toetsenbord.
Voor de eerste keer in de geschiedenis werden knappe jonge vrouwen ingezet in de reclame. De typemachine richtte zich ook op vrouwen. Het bood vrouwen een uitgelezen kans om buitenshuis te gaan werken.
Volg ook de navigatiestructuur van deze website. De verschillende onderdelen vind je daar ook als HTML-pagina's terug.
1. Hoe werkt het web?Download de volledige cursus (nieuwe hoofdstukken): Download
Download een ZIP-bestand met afbeeldingen van 'mensen' en '3D-objecten': Download
Download een ZIP-bestand met afbeeldingen van 'alfakanaal':
Download
Voorbeeld van een affiche-ontwerp in Adobe Photoshop.
Onderdelen die aan bod komen:
Heb je het moeilijk om het gezegde van een zin te herkennen? Dit programmaatje helpt je door samen met jou, stap voor stap, het gezegde te zoeken.
Opgelet: het programma is nog niet helemaal klaar, maar je kan het wel al perfect gebruiken. Start...
test blog 2
Hier komt de tekst van het artikel.
Onze industriële garagepoorten bestaan uit standaard panelen die volledig op maat van uw bedrijf worden gemaakt. Zo kan u uw poort laten maken in verschillende kleuren zodat u deze volledig kan afstemmen op de huisstijl van uw bedrijf. U heeft mogelijkheid om een deur en/of kijkvenster in de poort te integreren om zo de functionaliteit van uw industriële garagepoort te vergroten.
Al onze producten voldoen aan de laatste Europese richtlijnen.
MIBA-poorten
Vanaf komend weekend is het Engels Plein opnieuw afgesloten voor doorgaand verkeer
Vanaf komend weekend is het Engels Plein opnieuw afgesloten voor doorgaand verkeer. Het verkeer aan de Vaartkom rijdt dan naast het water, aan de kant van het Engels Plein.De parking van het gebouw Van der Elst blijft bereikbaar via het Engels Plein, vanaf de Kolonel Begaultlaan. Tot eind april werkt de aannemer het Engels Plein af met een voetpad aan het parkeergebouw (voor de winkel), een houten speelveld en bomen. In augustus wordt het voetpad aan het parkeergebouw afgewerkt. Het Engels Plein gaat in september definitief opnieuw open.
Bron: Stad Leuven
Leuven Bears heeft voor het eerst dit kalenderjaar een competitiepartij kunnen winnen.
Leuven Bears heeft voor het eerst dit kalenderjaar een competitiepartij kunnen winnen. De ploeg van coach Van Meerbeeck was sterker dan Brussels (82-74). In de rangschikking blijven de Leuvenaars ondanks hun vierde zege van het seizoen de houder van de rode lantaarn.
De eerste helft was niet veel soeps. Beide ploegen klungelden er op los waardoor het wel spannend bleef (15-17). Bohacik zorgde voor de eerste uitschieter (28-24) maar kon niet vermijden dat de hoofdstedelijken met een kleine voorsprong de rust in doken (ruststand: 36-39). Na de pauze trokken Westrol en Lasisi de partij naar zich toe (52-45). Brussels begaf nog niet en vocht terug tot 55-55. Daarna was het weer Lasisi die zijn ploeg op sleeptouw nam (73-67). In tegenstelling tot de voorbije duels hielden de Bears het hoofd koel en wonnen voor het eerst sinds 20 december 2014. Deroover ontbrak omwille van een buikblessure.
De Leuvense handelaars zijn niet blij met de carnavalsstoet die traditioneel op zaterdag door de stad trekt. Toch haasten de handelaars zich om te stellen dat ze niet tegen carnaval zijn in Leuven. Integendeel, ze verwelkomen de kleurrijke stoet met open armen maar dan wel op zondag.
Hier komt de inleiding.
Wetenschappelijke studies bewijzen dat BioSil fijne lijntjes en rimpels helpt te verminderen, de elasticiteit van de huid verhoogt, het haarvolume en de sterkte van het haar en nagels verbetert, en helpt bij het behoud van sterke botten en soepele gewrichten.
BioSil: de wetenschappelijke doorbraak voor je huid, haar, nagels en botten
Met krill beschikken we over omega-3 van topkwaliteit.
Krillolie heeft een aantal grote voordelen ten opzichte van visolie:
Magic Krill is de ideale omegamix als aanvulling op de westerse voeding, kortom het allerbeste voor jouw gezondheid!
Een aantal kilo's teveel? Een Bourgondische periode achter de rug? Bereik opnieuw je silhouet van je dromen op een veilige en gezonde manier. Bevat enkel natuurlijke ingrediënten.
Prijs: € 48
Je hebt resultaat bereikt met Slimming A en je wil verder? Bereik absoluut je silhouet van je dromen op een veilige en gezonde manier. Bevat enkel natuurlijke ingrediënten.
Prijs: € 48
Reinigende en voedende spons voor de gevoelige huid. Deze spons mag ook gebruikt worden voor baby's.
Reinigende en voedende spons voor het hele lichaam. De Green Tea spons zal je huid zachter en gladder maken.
antioxidant, maakt de huid zachter, gladder en subtieler
verbetert cel-regeneratie, goed tegen acné, wegwerken van mee-eters
voor de gevoelige huid, puur de vitaminen en mineralen van de Konjac plant
krachtig antioxidant, tegen vrije-radicalen, + 40 jaar
tegen vette huid, tegen tieneracne break-outs, tieners
tegen eczeem en dermatitis, tegen acne en vlekken, combinatie huid
huid verzachten en elastisch maken, voorkomt vlekken of pigmentatie, herstellen en voeden van de huid
krachtig antioxidant, anti-veroudering, verbetering collageen
voor de gevoelige huid, verstevigen van de huid, anti-rimpel
verzacht en hydrateert, beschermt tegen vervuiling, voor droge huid
Ben je minder energiek? Iets prikkelbaarder? Een zwaar gevoel?
Minder goede stoelgang? Dan is je organisme wellicht vervuild.
Door verkeerde voeding, stress, tijdsdruk, opgekropte emoties zijn vitale organen als lever, blaas, nieren, maag en darmen overbelast. Hou je lichaam gezond met regelmatige ontgiftingskuren.
Een inwendige zuivering die werkt. Je voelt het verschil.
Prijs: € 29
Deze zachte en huidvriendelijke reiniging zuivert de huid in de diepte, zonder het gebruik van schurende deeltjes. De zuiverende reiniging, verfijnt de huid, verwijdert onzuiverheden en bereid de huid voor op het liftende masker.
Evenwaardig aan meest gerenommeerde schoonheidsinstituten, zorgt het liftend masker voor een âhervormingâ van de gezichtscontouren in slechts enkele minuten terwijl het de huid hydrateert en beschermd. Een krachtige lifting en micro-circulatie activator. Liftend masker brengt u een gevoel van blijvende huidverjonging bij elk gebruik.
Speciaal ontwikkeld voor gebruik na het liftend masker. Het serum hersteld, kalmeert en hydrateert voor een stralende teint. De anti-rimpel ingrediënten werken in de diepte en hebben een blijvend effect op rimpels en fijne lijntjes.
De verschillende anti-verouderingsingrediënten werken bij iedere aanbreng geleidelijk op elkaar in en zorgen week na week voor een diep en blijvend anti-verouderingseffect.
Hier komt de inleiding.
Hier komt de tekst van het a
rtikel.
Hier komt de inleiding.
P
our lâassurance maison nous nâavons que trouvez 4 use cases. Cela pourrait donc signifier que lâIoT dans ce type dâassurance est encore dans une phase dâintroduction.
Exemple de use case: Dans les états unis lâassureur Western Property & Casualty Insurance offre une réduction de prime pour lâassurance maison quand un smart-thermostat est acheté et installé par un installateur avec certificat INCERT. Un exemple dâun objet connecté qui fera en sorte quâune réduction de prime sera appliquée est le smart-thermostat Nest de Google. Nest Protect est non seulement un détecteur de fumé mais aussi un détecteur de CO qui vous appelle sur votre smartphone dès quâil détecte de la fumé, ou un taux haut de carbone. Il vous prévient avant que de grands accidents peuvent arriver. Le but de cette action de Western Property & Casualty insurance est que le client achète sont smart-thermostat lui-même (pour le Nest Protect câest un prix de $129) et ensuite prouve a son assurance quâelle a été installé par un installateur avec certificat INCERT. De cette façon le client obtiendra une réduction et lâassureur aura diminué le risque dâincendie ou dâintoxication CO.
Hier komt de inleiding.
P
our lâassurance maison nous nâavons que trouvez 4 use cases. Cela pourrait donc signifier que lâIoT dans ce type dâassurance est encore dans une phase dâintroduction.
Exemple de use case: Dans les états unis lâassureur Western Property & Casualty Insurance offre une réduction de prime pour lâassurance maison quand un smart-thermostat est acheté et installé par un installateur avec certificat INCERT. Un exemple dâun objet connecté qui fera en sorte quâune réduction de prime sera appliquée est le smart-thermostat Nest de Google. Nest Protect est non seulement un détecteur de fumé mais aussi un détecteur de CO qui vous appelle sur votre smartphone dès quâil détecte de la fumé, ou un taux haut de carbone. Il vous prévient avant que de grands accidents peuvent arriver. Le but de cette action de Western Property & Casualty insurance est que le client achète sont smart-thermostat lui-même (pour le Nest Protect câest un prix de $129) et ensuite prouve a son assurance quâelle a été installé par un installateur avec certificat INCERT. De cette façon le client obtiendra une réduction et lâassureur aura diminué le risque dâincendie ou dâintoxication CO.
Hier komt de inleiding.
Hier komt de tekst van het artikel.
Zo bouw je nieuwe webpagina's in Architext.
Het bewerken van de inhoud van webpagina's in Architext.
Je kan op verschillende manieren afbeeldingen toevoegen aan een pagina.
Een afbeelding kan je snel vervangen door er op te klikken. Bekijk de stappen 7 en 8 hier boven.
30 jan
In 2015 schreef ik aan de KULeuven een paper met als titel âDe functie en betekenis van dierensymboliek in de berichtgeving rond de Tiense Furie (1635) â. Op zich een vreemde titel voor wie niet zo veel af weet van het verleden van de âzoeteâ stad. Het behandelt de berichtgeving rond de Tiense Furie, waarin zo goed als de hele stad werd vernield in de blinde oorlog tussen Nederland en Frankrijk aan de ene kant, Spanje aan de andere kant. Godsdienst werd ook toen âgebruiktâ om politieke belangen te dienen, een visie die vaak omgedraaid wordt en dan heet het godsdienstoorlog.
De vernietigende brand van de Furie had niet alleen de stad in puin gelegd, maar ook de binnen de muren opgeslagen voorraad graan was in de vlammen opgegaan, waardoor Frederik-Hendrik zijn leger niet meer van het benodigde voedsel kon voorzien. De Tiense Furie en het nieuws over de plunderingen en baldadigheden hadden een afschrikkend effect op de wijde omgeving. Een aantal Franse soldaten deserteerden door het uitblijven van soldij en het gebrek aan voedsel. Een poging om nog snel Leuven te bezetten, mislukte hierdoor. De hoop van de Republiek om de katholieken in het zuiden voor zich te winnen, ging door de berichtgeving over de verkrachtingen, de martelingen en de verwoestende brand voorgoed verloren.
In prenten uit die tijd vertolkten tekenaars de gevoelens van de strijdende partijen en van Tienen zelf. EeÌn van de prenten toont een zicht op de stad Tienen. Op een rots, symbool voor onverzettelijkheid, staat een haan die de waakzaamheid uitbeeldt. Uit de rots steken twee armen. Een slang slingert rond de rechterarm die een spiegel vasthoudt. De spiegel symboliseert zelfkennis. De slang verpersoonlijkt hier niet het kwaad uit het boek Genesis, maar de voorzichtigheid. Het schaap op het wapenschild van Tienen dook op na de Tiense Furie en stond bijna letterlijk voor de vermoorde (geofferde) onschuld. Het beeld van de schapen maakt nog steeds deel uit van de symboliek van de stad Tienen.
In vergelijking met andere Brabantse steden kent Tienen zo goed als geen gebouwen meer die dateren van voor de zeventiende eeuw. Het Burgerhuis Ark van NoeÌ in de gelijknamige Ark van NoeÌstraat zou eÌeÌn van de enige huizen zijn die de brand van 1635 zou hebben overleefd. Hieraan zou het gebouw ook zijn naam te danken hebben. Plaatsnaamkundige Paul Kempeneers toonde echter aan dat hiervoor geen historisch bewijs te vinden is. Een ander gebouw van voor de Furie zou het verkommerde Sint-Jansgasthuisin de Gasthuismolenstraat zijn.
Het mag dan ook vreemd heten dat de Tiense politici tot op heden,
ondanks talloze beloftes, en aangekondigde verbouwingen (de stellingen voor het gebouw zijn ondertussen zelf reeds aan restauratie toe) niets ondernemen om dit stuk van het stedelijk verleden te conserveren. De berichten over âI love Tienenâ die de sociale media sinds een paar weken opvrolijken, getuigen wel van een hernieuwd voornemen om de verkommerde stad te herleven⦠iets wat we vaker horen bij het begin van een nieuw jaar. Simultaan duiken echter persberichten op over het aanpakken van de leegstand en verkrotting.
Het oude vergeten Sint-Jansgasthuis dient daarbij opnieuw als coverbeeld
. Boetes op leegstand zullen verhoogd worden om dit probleem aan te pakken.
Was dit gebouw niet eigendom van de gemeente zelf? Hoe zit dat dan met die boete?
Het verleden mag geld opleveren, maar geen kosten? Het voelt vreemd dat politici in al die jaren van goede voornemens hun beloftes niet nakomen en echt werk maken van een degelijke conservatie. Ook hier lijkt, jammer genoeg, het
kortetermijndenkente primeren. Het lijkt een kroniek van een aangekondigde dood. In âThe History Manifestoâ schreven de historici Jo Guldi en David Armitage:
âA spectre is haunting our time: the spectre of the short term.We live in a moment of accelerating crisisthat is characterisedby the shortage of long-term thinking.â
Voor wie echt een hart heeft voor Tienen en dit letterlijk zichtbaar maakt door een sticker op de jas te plakken, laat dit dan ook wat dieper gaan. Kijk in het hart van uw eigen stad, naar het verleden dat er achter ligt. Kijk als waakzame hanen in de spieghel historiael, voorbij de oppervlakkigheid van een opgeplakt hart, vooraleer de Furie van het kortetermijndenken uw laatste resten verleden ontneemt. Aan de dames en heren politici die blaken van goede voornemens: schep duidelijkheid, toon daadkracht. Laat het niet bij denken alleen, maar durf nu eindelijk te doen.
Kris Merckx
In Architext bouw je een site door een nieuwe bundel aan te maken. Een "bundel" of "site" is eigenlijk een soort van rubriek. Vergelijk het met een krant. Een krant bevat meerdere rubrieken en elke rubriek behandelt een bepaald thema.
Wanneer je dus een Nederlandstalige en een Franstalige site wil, bouw je gewoon 2 bundels.
AR_code laat je toe om heel snel speciale code in te voeren in je HTML. Voor de nerds onder de gebruikers: custom tags
<fbcomments>Aantal</fbcomments>
<fbrecommend>item</fbrecommend>
<fbshare>item</fbshare>
<fblikeposts>item</fblikeposts>
<fblike>item</fblike>
<fbfollow>item</fbfollow>
<here></here>
<ar_url></ar_url>
<hier></hier>
<ar_thissite></ar_thissite>
<site></site>
<ar_license></ar_license>
<ar_author></ar_author>
<google>zoekterm</google>
<yt>zoekterm</yt>
<nlwiki>zoekterm</nlwiki>
<enwiki></enwiki>zoekterm
<gmap>plaats</gmap>
<ar_systemname></ar_systemname>
Iedereen kent wel het getal pi. Minder bekend is het Griekse getal PHI voor de gulden snede. Reeds in de Oudheid bestond het geloof dat alles wiskundig verklaarbaar was, of beter gezegd, "meetbaar", in de vorm van getallen of verhoudingen van getallen. Alles was uit te drukken in verhoudingen tussen die getallen, ratio's. De meest perfecte ratio was terug te vinden in de Gulden Snede, waarin vormen zich met een ratio van circa 1.6 tot elkaar verhouden.
Bron: STRATEN, M., Tien verdwenen dagen, 2012.
`1/2 + sqrt(5)/2 = (1+sqrt(5))/2 = phi`
De vierkantswortel van 5 bedraagt ongeveer 2,236068. De Gulden Snede is dan ongeveer `(1+2.236068)/2 = 3.236068/2 = 1,618034`.
Phi is een irrationaal getal, want vreemd genoeg kan je zeggen dat
Dit zou je eveneens als volgt kunnen omschrijven:
In het artikel "rekenen van rechts naar links" kom je te weten hoe we rekenen met machten en posities.
Wij rekenen met het decimale of tiendelige talstelsel omdat we tien vingers hebben. Er bestaan echter ook andere getalsystemen, zoals het 16-delige of hexadecimale talstelsel. Daarvoor hebben we dus 16 verschillende cijfers voor nodig. In het tiendelige talstelsel gebruiken we de tien Arabische cijfers (en de van oorsprong Indische 0). We gebruiken de cijfers 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. Tien verschillende cijfers of SYMBOLEN.
Vermits de positie van het cijfer in het getal de waarde verhoogt, kunnen we voor het hexadecimale stelsel dus niet simpel verder gaan met 10, 11, 12 enz.
Om tot 16 verschillende symbolen te komen, gebruiken we in het hexadecimale stelsel voor de overige symbolen letters. Zo komen we eveneens tot 16 verschillende tekens:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F
A=10, B=11, C=12, D=13, E=14, F=15
|
Cijfer
|
F | F |
|
Positie
|
1 | |
|
Waarde
|
15*16
1=240
|
15 * 16
=15
|
Het getal FF komt dus overeen met de waarde 255 in het decimale talstelsel. In kleursystemen gebruikt men vaak hexadecimale waardes. De kleur #FFFFFF staat voor FF waarde rood, FF waarde groen, FF waarde blauw. Als we die waardes "mengen", krijgen we wit. De waarde 00 rood, 00 groen, 00 blauw geeft zwart. Er zit namelijk geen enkele kleur in.
| RGB | R | G | B | Resultaat |
| #000000 | 00 | 00 | 00 |
|
| #FF0000 | FF | 00 | 00 |
|
| #00FF00 | 00 | FF | 00 |
|
| #0000FF | 00 | 00 | FF |
blauw
|
Bij RGB-waardes moet je het hexadecimale getal dus eerst opsplitsen in groepjes van 2 en niet de totale waarde berekenen. Door een getal met twee posities te nemen in het hexadecimale talstelsel, kan je voor elke kleur 256 verschillende combinaties bekomen.
In totaal kan je met het RGB-systeem op die manier (met enkel 6 symbolen!)
256
3 = 256 * 256 * 256 = 16 777 216kleurcombinaties samenstellen.
Bron afbeelding:
https://en.wikipedia.org/wiki/RGB_color_model#/media/File:RGB_illumination.jpg
Copyright: Kris Merckx -
http://www.ardeco.be- 2015
Copyright: Kris Merckx 2015
Dit boek start met deel 0. In programmeertalenis het eerste element in een reeks objecten nooit gewoon 1, maar element 0. In menselijke taal zouden we dit deel de inleiding noemen, maar toch is het belangrijk dat je net deze inleiding even leest. Hiernaast zie je een afbeelding, een soort cirkel, een voorstelling van het IPOS-modelwaarover je meteen meer leest.
In dit boek probeer ik je digitale systemen beter te leren begrijpen. Je leert meer over hun werking, over hun mogelijkheden en beperkingen en over de uitdagingen voor de toekomst. Je zal interactief leren door te doen en te ervaren.
Wat is een computersysteem eigenlijk en hoe werkt het? Nee, we gaan niet uitleggen wat een harde schijf is en waarvoor RAM-geheugen dient... dat weet je ondertussen ook al wel. Maar we gaan even een heel klein beetje de filosofische tour op. Als je alle computersystemen op een hoop gooit, wat hebben ze dan gemeenschappelijk?
Meestal komt dan het zogenaamde IPOS-modelom de hoek kijken: Input â Processing â Output â Storage.
1. Onder inputverstaan we alle soorten informatie die je in zo'n toestel propt: tekst, foto's, film, muziek... Hiervoor heb je een reeks invoerapparaten nodig: een toetsenbord, een webcam, een USB-kabel, een SD-kaart, een scanner, muis, microfoon of zelfs gewoon een andere computer. Een computersysteem kan ook zelf op zoek gaan naar invoerdata, zoals dat bij BIG DATA wel eens gebeurt.
2. Het toestel zal met die informatie iets gaan doen. In een aantal gevallen vind er een conversieslag plaats, een vertaling van analoge informatie naar digitale informatie (hier leer je nog over). Die verwerking of â processingâ kan gebeuren tijdens de invoer of achteraf als de computergebruiker die input wil bewerken. Als je een tekst intikt in een tekstverwerker gebeurt de input en verwerking simultaan. Wanneer je een foto bewerkt in een beeldbewerkingsprogramma, dan gebeurt de verwerking meestal achteraf.
3. Om dit mogelijk te maken moet het computersysteem ook in staat zijn de ingevoerde data te bewaren ( storage).
4. Een computersysteem zal de gebruiker feedbackgeven. Dat kan in realtime door bijvoorbeeld te zeggen dat er iets fout is gegaan, door een bevestiging te vragen enz. Een programma kan ook feedback geven aan zichzelf: als dit gebeurt, dan doe ik dat, in het andere geval... In zo'n geval spreken we van âopen loopâ-feedback. Wanneer de gebruiker op één of andere manier moet bevestigen of iets doen, dan spreken we van âclosed loopâ-feedback.
5. Maar de bedoeling is meestal dat de computer toont wat het resultaat van die bewerking is. In veel gevallen ziet de gebruiker het resultaat meteen op een scherm. Je ziet meteen het eindresultaat: what you see, is what you get ( WYSIWYG). Ook nadien kan je de bewaarde en verwerkte data nog âbekijkenâ door het bestand te openen, af te drukken, te posten op een website enz. Inderdaad, dat is wat we met outputbedoelen.
Bron:
http://www.bbc.co.uk/schools/gcsebitesize/design/resistantmaterials/processystemsrev1.shtml
In wezen is een computersysteem voor een deel gebouwd naar hoe we onze âeigenâ werking als mens zien. Je ondergaat heel wat âinvloedenâ van je omgeving, van het weer tot die giftige sneer van een opmerking die de docent je gaf tijdens de les omdat je even niet aan het opletten was. Je hoort, ziet, proeft, voelt... en je registreert (INPUT via ondermeer âsensorenâ), je selecteert waar je mee bezig wil zijn (je favoriete APPS) of moet zijn (standaard PROCESSEN), je verwerkt het (soms krijg je het niet verwerkt en CRASH je letterlijk). Je zegt soms dat het allemaal een beetje te veel is of dat je geen twee dingen tegelijk kan (te weinig RAM-geheugen, MULTITASKING). Je onthoudt ook zaken, dat kan gaan over pure herinneringen aan gebeurtenissen in je leven, verplichte leerstof, ervaringen (kortom FILES en FOLDERS). Sommige dingen heb je niet geleerd, je doet ze automatisch zoals bijvoorbeeld ademen (BIOS, OPERATING SYSTEM). Maar je leert ook dingen doen: je kan fietsen, koffie maken, schrijven (PROGRAMMA's, SOFTWARE, APPS). En uiteindelijk geef ook jij feedback: je kan boos zijn om wat men je aandoet of net heel blij of gelukkig (FEEDBACK). Of je kan een alarminstallatie installeren omdat er werd ingebroken (FEEDBACK = nieuwe SOFTWARE). Je gaat naar school om nieuwe dingen te leren doen (APPS) om later werk te vinden (PROCESSING).
Uiteraard stemt dit niet overeen met de werkelijkheid van wat het is om een mens te zijn. Een mens is geen computer en herinneringen werken volledig anders dan "files". Het helpt enkel om de werking van een systeem beter te vatten.
Onderstaand artikel uit Cursus multimedia (K. Merckx)
Computers, laptops, tablets, smartphones, internet of things... Hoe maken we die digitale en elektronische wereld bevattelijk? Er is meer onder de zon dan de strijd tussen Microsoft en Apple of Android en iOS. In dit hoofdstuk leer je je weg te vinden in wat digitaal en elektronisch nu eigenlijk is. Hoe verhouden de diverse toestellen zich tot elkaar? Wat is het verschil tussen de boordcomputer in je auto en je laptop? Is je TV ook een computer als je ermee op internet kan?
Je zal een stap voor zijn op de meerderheid van het grote publiek dat zulke toestellen wel massaal gebruikt, maar eigenlijk niet goed weet hoe die werken en nog veel minder hoe je zo'n toestellen zelf op maat kan bouwen. Wat leeft er allemaal in die âdigitale wereldâ? Wat is het verschil of de verhouding tussen analoog en digitaal, tussen elektronica en computers, tussen computers en microcontrollers, tussen embedded systemen en firmware, tussen hardware en software? Volg je nog? Ok, laat het ons een even allemaal op een rijtje zetten. Opgelet: we staan niet stil bij klassieke computers of televisietoestellen of diverse âmerkenâ.
Een computer(de hardware), of het nu gaat om een klassiek desktop-onding, een tablet, smartphone of een laptop, bestaat uit een hoop onderdelen. Je vindt er een processor in, een tijdelijk werkgeheugen (RAM), een opslagmedium (harde schijf, SSD, SD...), invoerapparaten (muis, touchscreen, toetsenbord...) en ook een outputsysteem (bestanden, scherm, webserver...). Al die diverse toestellen doen in wezen niet zo'n aardig verschillende dingen. Ze verwerken invoer en tonen en/of bewaren de uitvoer. Dat heb je op de schoolbanken geleerd. Ze kunnen niet zonder âsoftwareâ, de ongrijpbare programma's die ergens virtueel zijn âgeïnstalleerdâ als digitale gegevens op een opslagmedium. De softwaregeeft onder de vorm van âbinaireâ code instructies aan de toestellen, verwerkt de invoer en presenteert de uitvoer.
Software bestaat op diverse niveaus:
1. een basissysteem (bios, uefi) dat de contacten tussen alle onderdelen regelt,
2. een besturingssysteem (zoals Android, iOS, Linux, Mac OS X, UNIX, Windows...)
3. of gewoon software met een heel specifieke taak (zoals GIMP, MS Word of... Processing).
Maar er bestaan ook andere verschijningsvormen die men gemakshalve eveneens aanduidt met de naam âcomputerâ, maar in wezen niet helemaal voldoen aan de definitie hier boven. Een microcontroller is zo'n âcomputerâ. Men gebruikt een microcontroller of microprocessor om elektronische apparatuur te besturen. Heel wat moderne apparaten bevatten zo'n microcontroller: een magnetron, een auto, een wasmachine, sommige telefoons...
Er bestaan ook kruisbestuivingentussen beide. De immens populaire Raspberry Piis daar een voorbeeld van.
Ongetwijfeld heb je op het vlak van âconsumentenelektronicaâ al gehoord over â embedded systemenâ en â firmwareâ. Een embedded system (ingebed of geïntegreerd systeem) is heel vaak gebaseerd op een microcontroller (met een microprocessor en/of DSP of 'digital signal processor') of op een SoC (System on a chip). Het vervult een bepaalde functie binnen een groter mechanisch of elektrisch systeem.In een koelkast kan het de temperatuur regelen, in een wasmachine regelt het de functie van alle âprogramma-instellingenâ, in je auto zorgt het voor alle foutmeldingen die op je dashboard verschijnen, maar ook voor alle andere digitale informatie, voor het aansturen van bepaalde onderdelen van je motor enz.
Vroeger bestonden regelsystemenhoofdzakelijk uit mechanische en later elektronische onderdelen. Nu neemt de in een âmicrocontrollerâ geïntegreerde software veel van die taken over. Een microcontroller integreert hardware en software. Er zit geen âharde schijfâ in waarop de software manueel kan geïnstalleerd worden, vaak zit de software geïntegreerd in de hardware, als vrijwel niet te wijzigen programma's. Soms kan de ingesloten software geüpdated worden, dan spreekt men van â firmwareâ.
Zo'n integratie biedt tal van voordelen in vergelijking met een âcomputerâ.
Nadeel is dat de functionaliteit heel beperkt is. Je kan bijvoorbeeld geen tekstverwerker installeren in je koelkast of videomontagesoftware in je auto.
Het Leuvense IT-bedrijf EASICS ontwikkelde de beeldherkenningshardware waarmee de sorteermachines van de Belgische firma BEST zijn uitgerust.De hardware van EASICS herkent tegen een onwaarschijnlijk hoog tempo âongewensteâ elementen tussen bijvoorbeeld razendsnel voorbij rollende frieten, krenten, garnalen, spijkers of wat dan ook en activeert een luchtdrukstraal die het ongewenste element wegspuit. Een âmultifunctioneleâ computer, hoe krachtig en snel ook, zou er niet in slagen om die taak zo snel af te handelen. Omdat de programmacode in de chip is gecodeerd, verloopt de verwerking hier onwaarschijnlijk snel.
Even bekeken volgens et IPO-model: input = beeld van camera, processing = herkennen van ongewenste elementen, output en feedback = verwijderen van ongewenst element.
Vaak worden embedded systemen met één bepaald doel voor ogen ontwikkeld, zijn ze heel âgespecialiseerdâ, maar je kan ook herbruikbare microcontrollersontwikkelen... en dan zitten we bij de Arduinoaan het juiste adres als âstartersmodelâ.
Een eigenhandig gebouwde smartphone op basis van een Arduino-microcontroller.
Een âembedded systeemâ bevat een sensorgedeeltedat informatie uit de werkelijkheid kan registreren. In een tweede fase kan het die informatie digitaliseren. Die digitale informatie moet verwerkt worden door de âmicroprocessorâ of de firmware. In een laatste fase zal een â actuatorâ bepaalde onderdelen aansturen of zorgen voor zichtbare of hoorbare output.
Naast de term âmicrocontrollerâ en âembedded systemâ duikt ook wel eens de term âsystem on a chipâ (SoC)op. Een SoC (met een C wel te begrijpen), integreert alle componenten van een computer en/of elektronisch systeem op één enkele chip. SoC's worden veelvuldig toegepast in de markt van mobiele consumentenelektronica. Een âembedded systeemâ bevat vaak een SoC.
Oeps, waar ligt dan de grens tussen een âmicrocontrollerâ en een âSoCâ? De term âSystem on a chipâ is in dat geval niet de beste keuze geweest. Immers, een âmicrocontrollerâ is vaak pas echt gebaseerd op één enkele chip, waardoor het beschikbare RAM-geheugen vaak onder de 100 kb blijft. Een SoC bevat vaak een veel snellere processor met meer werkgeheugen waardoor het in staat is om een besturingssystemen zoals Linux te draaien. Het is dus niet altijd echt één chip, want een SoC maakt vaak gebruik van externe geheugenchips (SD-kaartje, RAM...). Een modern besturingssysteem, hoe compact ook, heeft wel wat meer nodig dan 100 kb. Het begrip SoC verwijst dus eerder naar een zeer sterke integratie van de chips, waardoor kleinere systemen mogelijk worden.
Waarom zou je met zulke toestellen aan de slag gaan of er tijd in steken, want in wezen zijn ze veel trager dan een standaard âcomputerâ of zelfs een goedkope smartphone? Embedded systemen en microcontrollers zijn aan een ware veroveringstocht bezig. Wellicht hoorde je de term âinternet of thingsâal eens vallen. Ruwweg houdt dit in dat stilaan elk huishoudelijk toestel, maar ook auto's, bewakingscamera'sen domoticasystemenzulke embedded systemen aan boord hebben. Wanneer je al die dingen (things) aansluit op het internet, krijg je een allesomvattend netwerk van digitaal verbonden toestellen: het internet of things. We stellen ons hier even geen vragen over de gevolgen en gevaren voor de privacy en de ethiek.
Kortom, embedded systemen, SoC's en microcontrollers zijn niet meer weg te denken uit de wereld van vandaag en morgen. Be prepared!Wees voorbereid, want wie het kent, kan er zijn voordeel uit halen en zich behoeden voor al te grote 'schendingen' van zijn vrijheid en privacy. Hoe meer je erover weet, hoe beter je er mee kan omgaan, hoe beter je het systeem kan âhackenâ (=uit elkaar halen en begrijpen).
De fysieke wereld waarin wij leven gedraagt zich
analoog. Natuurkundige fenomenen zoals licht, geluid, temperatuur ... kunnen voortdurend wijzigen. Een
elektronisch apparaat
zet signalen uit de omgeving (geluid, licht, warmte ...) om in elektrische signalen (spanningen, stromen ...). Net zoals een foto-elektrische cel licht omzet in een elektrisch signaal, zet een microfoon drukgolven in de lucht om in een veranderlijke elektrische spanning.
Een computer is een elektronisch systeem, maar niet elk elektronisch systeem is een computer;Een televisietoestel verwerkt net zoals een computer een binnenkomend signaal met behulp van elektronische onderdelen en toont die op het scherm. Maar dit betekent daarom nog niet dat een televisietoestel dan ook een "digitaal" systeem is; Digitale systemen verwerken alle invoer met behulp van binaire code.
Zonder dat we het zelf goed en wel beseffen worden we omringd door sensoren. Je vindt ze in je mobiele telefoons (camera, microfoon, accelerometer ...), het toetsenbord en de muis van je computer, de thermostaat van de verwarming, in automatische lampen, het scherm van een tabletcomputer ... Als je na een nachtje stappen aan de kant wordt gezet door de politie, vind je ze zelfs in de alcoholtester (een chemische sensor). Omdat de opgewekte elektrische signalen vaak te zwak zijn om bruikbaar te zijn, bevat veel elektronica ingebouwde of aangesloten versterkers. Analoog houdt in dat de informatie als een continue golf of âstroomâ wordt opgeslagen. Zoals je weet, bestaat geluid in werkelijkheid uit een reeks voortdurende trillingen in de lucht, een golf met andere woorden. Bij een microfoon brengen de trillingen van de lucht een membraan 1 in beweging. Deze beweging wordt omgezet in een veranderlijk elektrisch signaal, dat opgeslagen kan worden op magneetbanden. Analoog betekent dus ânaar analogie met de werkelijkheidâ. Analoge signalen zijn erg onderhevig aan storingen of interferenties van bijvoorbeeld andere apparaten.
Actuatorenvormen een ander onderdeel van een elektronisch systeem: zij zetten elektrische signalen om in andere signalen zoals mechanische kracht, geluid ... Een luidspreker is een bekend voorbeeld van een actuator. Hij laat de lucht trillen door eerst zelf te trillen. Zo zet een elektrische motor elektriciteit om in een mechanische beweging, een lamp en een beeldscherm zetten elektrische energie om in licht enzovoort.
Naast de invoer via sensoren en de uitvoer via actuatoren voert de elektronica zelf een aantal berekeningen, algoritmes of programmaâs uit op de binnenkomende signalen. Elektronica kan naar analogie met de werkelijkheid het elektrische signaal continue bewaren, zoals dit bijvoorbeeld met geluid op een magneetband gebeurt. Toch kunnen hier wat fouten of afwijkingen optreden. Als je destijds een audiocassette te lang op een warm dashboard liet liggen, merkte je het aan de geluidskwaliteit!
Een klassieke audiocassette bewaarde geluid analoog op een magneetband .
Elektronisch is nog wat anders dan digitaal , ook al hoor je de termen weleens door elkaar gebruiken. Het sleutelwoord bij digitaal is â discretisatie â in ruimte en tijd.Wanneer we analoge informatie digitaliseren, plaatsen we een denkbeeldig raster over de fysieke wereld en meten we de binnenkomende signalen enkel op bepaalde tijdstippen, meestal op vaste intervallen. Dit gebeurt doorgaans zeer snel, want anders zouden we veel âinformatieâ missen. Discretisatie in ruimte en tijd heet in het vakjargon ook wel bemonstering, maar is vooral bekend onder de Engelse benaming âsamplingâ. Een sample of een monster van een beeld noemen we een âpicture elementâ of âpixelâ. Een digitaal systeem meet ook de signaalniveaus (discretisatie van de signaalwaarden), zoals de lichtintensiteit van een pixel.
Bij het bouwen van zoân systeem moeten er vooraf afsprakengemaakt worden. Bij een afbeelding kan dit gaan om de hoeveelheid pixels die men horizontaal of verticaal wil meten, bij geluid over het aantal metingen per seconde. Een audio-cd bevat bijvoorbeeld 44100 samples of metingen per seconde (sample rate van 44.100 Hertz = 44,1 kHz). Elke sample of meting wordt uitgedrukt als een getal tussen 0 en een vooraf bepaalde maximale waarde. Hoe hoger die waarde, hoe groter het bereik en hoe nauwkeuriger het signaal kan worden gemeten en weergegeven. Wanneer we licht meten met slechts twee lichtintensiteitswaarden, bevat ons eindresultaat enkel wit of zwart.
Simpel gezegd werkt een elektronisch of digitaal toestel op basis van elektriciteit en die kent ruwweg maar twee toestanden: aan (1) of uit (0). Het lijkt dus op het eerste gezicht niet zo eenvoudig om getallen hoger dan de waarde 1 te meten of te bewaren in een digitale omgeving. Daarom maken digitale systemen gebruik van het binaire stelsel, een tweetallig getalsysteem dat alle getallen weergeeft met de symbolen 0 en 1.
Een binair cijfer of bit (binary digit) kan dus slechts twee vormen aannemen: een 0 of een 1. Een binair getal noemen we anders naargelang het bereik. Zo noemen we een getal van 8 bits een byte. Wij leren op school letterlijk tellen op onze vingers (digitus in het Latijn) en we gebruiken daarom niet voor niets een tiendelig of decimaal talstelsel. Daarom is het ook even wennen als we met binaire getallen aan het tellen gaan. Je leert meer over binaire getallen via deze link.
Een bereik van 8 bits geeft 2 tot macht 8 (256) mogelijke waarden. Een audio-cd heeft een bereik van 16 bits of 32.768 mogelijke waarden. Deze vorm van discretisatie beiÌnvloedt in sterke mate de kwaliteit. Hoe lager het aantal beschikbare bits of hoe trager het bemonsteren gebeurt, hoe lager de kwaliteit. Een te hoog bereik is echter evenmin zinvol. Het menselijk oor kan de extra kwaliteit toch niet altijd waarnemen.
Daarom probeert men vaak een gulden middenweg te vinden tussen kwaliteit en âbeperkingenâ,zoals opslagcapaciteit en doorvoersnelheid (bijvoorbeeld de snelheid van de internetverbinding). In onze tijd worden digitale gegevens ook opgeslagen en voor langere tijd bewaard.
Hoe gaat dit fysisch precies in zijn werk en welke voordelen biedt deze manier van opslaan? In een digitaal systeem bestaat elke waarde uit een reeks bitjes, die elk afzonderlijk slechts 2 geldige waarden kennen, namelijk 0 of 1. In een elektronische schakeling kunnen we dit zien als een verschil tussen bijvoorbeeld 0 en 1,8 Volt, op een cd als een minuscuul putje of net geen, op een harde schijf als een klein gebiedje dat al dan niet gemagnetiseerd is, op een flash-geheugenkaartje als een pakketje elektronen (elektrische lading) dat wordt vastgehouden in een transistor ...
Samengevat betekent âdigitaalâ dus dat we de informatie bewaren als een reeks binaire getallen.Een geluidsgolf kunnen we bijvoorbeeld weergeven als een reeks getallen met een bepaalde grootte. Als we die getallen op een grafiek zetten, zien we de oorspronkelijke golf weer verschijnen. Digitale informatie wordt altijd met binaire en niet met decimale getallen weergegeven. In het binaire stelsel wordt elk getal voorgesteld als een combinatie van nullen en enen. Binaire getallen zijn uitermate geschikt om door elektrische schakelingen of bedrading te sturen omdat die enkel maar een aan-toestand (1) en uit-toestand (0) herkennen. In een analoog systeem kan elke gewenste waarde tussen een bepaalde ondergrens en bovengrens worden voorgesteld.
Als er ruisoptreedt door bijvoorbeeld slijtage op een magneetband of een elektromagnetische storing, kan het oorspronkelijk signaal niet meer onderscheiden worden van de ruis. De ruis die er achteraf bijgekomen is, heeft de oorspronkelijke signaalniveaus immers aangetast. Ook in een digitaal systeem kan ruis optreden. Een kras in een optische schijf zoals een cd kan putjes minder diep maken of elektromagnetische storingen kunnen bepaalde zones op een harde schijf demagnetiseren. Toch kan over het algemeen het oorspronkelijke niveau hersteld worden (als de storing niet te groot is) omdat elke bit slechts twee geldige waarden heeft: het is ofwel 1 ofwel 0 en daaruit moet het systeem zelf kiezen. Een kras kan bij wijze van spreken van 0 een 0,3 maken, maar die waarde ligt dichter bij de 0 dan bij de 1. Enkel een 0,5 zou een twijfelgeval kunnen worden. Als de schade door slijtage, ruis of storingen dus niet te groot is, kan een digitaal systeem de oorspronkelijke informatie of kwaliteit volledig herstellen. Maar zelfs in het geval van grote schade kan men door codeertechnieken (het uitrekenen van bepaalde controlegetallen over groepen van bits) de fouten toch nog herstellen (uiteraard binnen bepaalde grenzen). Sommige systemen maken gebruik van symbolen die meer dan twee waarden kunnen aannemen, waarbij eÌeÌn geheugencel 2 of 3 bit aan informatie kan bevatten. Dit soort transistors houden pakketjes elektronen van 4 of 8 verschillende (nominale) groottes vast. Zulke systemen zullen echter sneller falen bij kleine storingen of ruis. Toepassingen die een hoge betrouwbaarheid vereisen (zoals medische implantaten of ruimtevaart) zullen daarom 1 bit-cellen gebruiken. Digitalisering biedt nog tal van andere voordelen. Zodra een signaal is gedigitaliseerd, kan het makkelijk bewerkt en aangepast worden. Voor het toepassen van een filter op een afbeelding hebben we bijvoorbeeld niet langer een speciaal onderdeel of toestel nodig, dit kan met een computerprogramma. Dezelfde geheugendragers kunnen gebruikt worden om verschillende vormen van informatie te bewaren: fotoâs, tekst, muziek, beeld, programmaâs â¦
Pulsbreedtemodulatie (PWM of pulse width modulation)is het begrip als het gaat om het omzetten van digitale signalen naar analoge signalen. Cool, echt een begrip om mee uit te pakken aan de toog van je stamcafé, maar je kan best toch zorgen dat je dan tenminste weet waarover je het hebt. Zeker als die onbekende man op de hoek van de toog een ingenieur blijkt te zijn. Ben je er klaar voor?
Stel dat je dit boek nu niet zou lezen, maar dat je naar de audioversie ervan zou luisteren, dan zou het geluid van mijn opgenomen stem de lucht laten trillen. De luchtdeeltjes zouden als een voortdurend wijzigende golf je oren bereiken, met steeds wisselende pieken en dalen: een analoog geluidssignaal, naar âanalogieâ met de werkelijkheid. Nochtans werkt die luispreker op basis van elektrische signalen die nu eens uit en dan weer aan kunnen staan. Ofwel stuur je een pulsje stroom, ofwel niet, want elektriciteit beweegt nu eenmaal niet zoals een golf zeewater. Het is het een of het ander bij elektriciteit. De stroom staat aan of uit, 1 of 0. Hoe kan je dan met elektrische stroom een geluidsgolf genereren, een motor zachter laten draaien, een LED-licht dimmen?
Je kent het antwoord al, met PWM! Maar hoe gaat dit nu in zijn werk?Met PWM moduleren we de stroom. We schakelen bliksemsnel tussen 5V en 0V. Stel dat je de voltage de helft van de tijd instelt op 5V en de helft van de tijd op 0V dan krijg je een gemiddelde stroom van 5V of een âduty cycleâ van 50%. Laat je de stroom 10% van de tijd op 5V staan, dan krijg je gemiddeld 0.5V. Als je op deze manier een motor aanstuurt, zal de motor langzamer draaien bij een lagere duty cycle. De motor krijgt dan wel zijn maximale spanning, maar niet continu. M.a.w. als je de schakelaar continu aan laat staan, zal je motor constant snel draaien, je LED-licht continu âfelâ branden. Als je snel aan en uit pulst, zal de motor zachter beginnen draaien en je licht dimmen.
Het binaire talstelsel werd âbedachtâ door de wiskundige en filosoof Gottfried Wilhelm Leibniz (1646â 1716), een tijdgenoot van het onovertroffen genie Isaac Newton (1643â1727). In zijn tijd zag niemand het nut in van zoân binair talstelsel en hij zelf gebruikte het vermoedelijk enkel in filosofische discussies over godsdienst: de 1 zou daarbij staan voor het bestaan van God en de 0 voor de afwezigheid van God. Andere vondsten van Leibniz, zoals het âis gelijk aanâ-teken (=) of de dubbele punt bij delingen (:), raakten wel ingeburgerd. Het binaire getalsysteem werd in de eerste helft van de 20e eeuw dankbaar opgevist voor gebruik in de eerste digitale computers.
Ook al was het binaire talstelsel nog niet uitgevonden, toch bestond het âdigitaalâ programmeren van machines al veel langer. Heron van Alexandrië bouwde tweeduizend jaar geleden automatische theaters met gewichten, touwen, assen en pinnen. Aan het ene uiteinde van het touw bevestigde hij een gewicht, dat hij boven op een met tarwekorrels gevulde cilinder plaatste. Door een sleufje onder in de cilinder open te trekken, vloeiden de korrels weg. Hierdoor begon het gewicht met enige vertraging te zakken. Aan de andere kant hingen twee touwen. Elke touw was rond een afzonderlijke as (de linker en de rechter vooras) gewikkeld. In beide assen waren op gelijkmatige afstanden gaten geboord. Het zakkende gewicht trok niet alleen aan de touwen, maar liet de beide assen ook draaien. De machine kon eenvoudig geprogrammeerd worden door in de gaten pinnen te plaatsen. Als je een touw rond een bepaalde pin liet teruglopen, kon je een van beide assen op elk gewenst moment in de andere richting laten roteren. Net zoals in moderne programmeertalen slaagde Heron er ook in om een âtimerâ-functie in te bouwen. Hiervoor plakte hij met was een stuk van het touw vast aan de as. Het zakkende gewicht trok het was stilaan los. Als het touw eenmaal was losgekomen, begon de as weer te roteren.
Je zou de instructies voor Herons robot kunnen uitschrijven in de code voor Lego® Mindstorms- robots:
task main(){
OnFwd(OUT_A,75);
OnFwd(OUT_B,100);
Wait(3000);
}
De OnFwd-instructie laat de motor naar keuze (A of B) vooruitbewegen. De Wait-instructie laat het toestel voor een bepaalde duur (milliseconden) halt houden. Uiteraard schreef Heron geen programmeerinstructies. Ze waren vastgelegd in zijn machine, maar op zoân manier dat je het toestel kon herprogrammeren door de pinnen te verplaatsen. Het programma werd âopgeslagenâ in de assen met wat we binaire instructies zouden kunnen noemen. Een pin staat voor een 1, een gat zonder pin voor een 0 (of omgekeerd). Het automatische theater van Heron reed volkomen zelfstandig het podium van het theater op. Daar stopte het en toonde een toneelstuk van mechanische poppen, die eveneens door een mechanisme van pinnen, gewichten, touwen, assen, tandwielen en hefbomen werden aangedreven. Het theater was voorzien van decorwissels en geluidseffecten. Door op een bepaald moment een sleuf open te trekken, vielen loden ballen op een trom, wat het geluid van donder simuleerde.
Wellicht bestond de techniek voor het programmeren van toestellen al langer en heeft Heron het niet zelf bedacht. De techniek om toestellen te programmeren dook ook op bij Islamgeleerden, in middeleeuwse klokken, bij Leonardo da Vinci. In de 18e eeuw paste men de techniek enigszins aan door de cilinders met pinnen te vervangen door kaarten met gaten (ponskaarten). Men begon ze in te zetten voor het automatisch weven van kleren in weefgetouwen (Jacquard). De techniek van de ponskaart als middel om gegevens of programma-instructies te bewaren, bleef in gebruik als opslagmedium voor computers tot in de jaren 1980.
Een ponskaart voor de opslag van geprogrammeerde muziek (19e eeuw).
1.4 Microcontrollers en SoC's voor doe-het-zelvers
De Arduino is niet enkel een microcontroller. Het is een speciaal ontworpen bord voor het programmeren en het maken van âprototypesâ met Atmel-microcontrollers. Als je er al eentje hebt aangeschaft, zal je ondertussen wel weten dat het goedkoop is. Voor een kleine 25 euro haal je een Arduino UNO in huis. Bovendien is het aardig makkelijk om mee te werken. Je sluit het via USB aan op je computer. Arduino-programma's schrijf je met een gratis stuk software. (http://arduino.cc/en/Main/Software).
De Arduino krijgt stroom via een USB-verbinding, maar kan ook los van de computer functioneren via een netadapter of batterijen. De Arduino meldt zich bij uw computer aan als een âvirtuele seriële poortâ. Als je code schrijft, kan je ze met een eenvoudige klik op de knop uploaden naar de Arduino. De standaard Arduino beschikt over 32 KB flashgeheugen om je code te bewaren. Dat is niet veel, maar ruim voldoende voor de meeste projecten.
Een Arduino telt 13 digitale en 6 analoge pins om externe hardware en sensoren aan te sluiten. Voor wie wat meer thuis is in de elektronicawereld: het bord heeft ook een ICSP-connector waarmee je de Arduino rechtstreeks als een serieel toestel kan aanspreken. Via deze poort kan je de Arduino âherstartenâ (bootload) wanneer de chip niet meer met je computer wil âsprekenâ.
Afhankelijk van het project dat je wilt bouwen, kan je extra bordjes, sensoren of uitvoerapparaten op de Arduino aansluiten of in de pins âklikkenâ. Wanneer je een gewenst onderdeel aankoopt, vind je op de website van de fabrikant over het algemeen het schema voor het bouwen van de hardware-applicatie en de benodigde code. Controleer dit vooraf zodat je niet voor ongewenste verrassingen komt te staan. Houd er ook rekening mee dat je voor sommige modules met een soldeerbout overweg moet kunnen.
|
Sensoren |
Gyroscoop, accelerometer, ultrasone sensor, GPS, IR-afstandssensor, verstelbare IR-sensor, bewegingssensor |
|---|---|
|
Shields |
Wifi, Ethernet, Motor, Color LCD, AM&FMÂontvanger, VoiceBox (voice en sound synthesizer), Musical Intrument, Audio Player, Joystick, Xbee |
|
Modules en adapters |
Voide recognition, radiocommunicatie, Xbee, Bluetooth, WiichunkÂadapter, SDÂ lezer, Power over ethernetÂmodule, GSMÂmodule |
Wiring is de naam van een hardwareproject, een soort broertje of zusje voor Arduino. Meer informatie vind je op . Net zoals Arduino is Wiring een open-source
elektronica prototyping platform. Wat open source is, leer je in een later hoofdstuk.
Je kan er op heel eenvoudige manier een âprototypeâ van een programmeerbare elektronische schakeling mee bouwen.
De Raspberry Pi is een minicomputer (ook wel een singleboardcomputer genoemd) met een ARM-processor die ook dienst kan doen als microcontroller voor kleine elektronicaprojecten. Vermits het een gewone computer is, kan je er ook randapparatuur zoals een muis en toetsenbord (via USB), een microfoon, luidspreker of beeldscherm (TV via HDMI) op aansluiten. Een hele rits Linux-distributies (maar ook bijvoorbeeld Risc OS en Plan 9) zijn geschikt om op de Pi geïnstalleerd te worden. Het toestel kan ingezet worden als fileserver, NAS, mailserver... Voor een kleine 50 euro koop je een Raspberry Pi wat mede heeft bijgedragen tot zijn gigantische succes.
Een Raspberry Pi met een Linuxbesturingssysteem via HDMI aangesloten op een televisie.
Processorfabrikant Intel keek al snel met groeiend ongenoegen naar het succes van de op een ARM-processor gebouwde Raspberry Pi. Daarom lanceerde het bedrijf zijn eigen minicomputer aan onder de naam Intel Galileo. Het toestel draait op de energiezuinige Quark x1000-SoC.
Omdat de Raspberry Pi ook kan gebruikt worden voor elektronicaprojecten zag Intel de Arduino als een nuttige bongenoot in de zijn "oorlog" tegen het ARM-geweld. De Galileo is daarom niet alleen compatibel met zijn "Pentium Instruction Set Architecture", maar ook met de Arduino-bibliotheken en IDE.
Wie toch zijn eigen elektronica wil âprogrammerenâ en samenstellen zonder één letter code te schrijven of met kabels of soldeerbouten aan de slag te moeten gaan, moet zeker eens kijken naar Little bits. Met de eenvoud van Lego bouw je met Little bits coole elektronicaprojecten. Je klikt de diverse onderdelen poepsimpel via kleine magneetjes aan elkaar en klaar is kees.
Audacity: Tijdens de les digitaliseren we audio met het open sourceprogramma Audacity ( www.audacityteam.org). We bekijken hoe het audiosignaal er in digitale vorm uitziet.
Adobe Photoshop / GIMP:We zetten een foto om in zwart-wit en verlagen het aantal pixels drastisch. We bekijken hoe discretisatie aan het werk is gegaan.
http://www.ardeco.be/sirk/screen.html:Pixelweergave met een raster. Hoe stuur je boodschappen door in binair formaat?
Tijdens de les kan een student nota's nemen in de cursus. Dit lukt enkel als de beheerder die mogelijkheid heeft voorzien . Op dit moment kan je nota's nemen, markeringen toevoegen, tekst verwijderen, tekst plakken, afbeeldingen slepen en afdrukken.
De toepassing onthoudt op dit moment je aanpassingen niet. Je kan wel de notities naar je eigen e-mailadres mailen, maar in heel wat mailprogramma's gaan de ingeleurde markeringen verloren. Vetgedrukt, onderstreept, schuin en doorstreept, evenals tekstuele aanpassingen blijven in mail wel bewaard.
1. Ga naar de gewenste pagina.
2. Klik op het knopje links op het beeldscherm.
3. Klik op de knop "Neem notities".
4. Boven de tekst verschijnen de knoppen "Druk pagina af" en "Verzend".
3. Klik in de tekst om aanpassingen aan te brengen. Opgelet: enkel jij ziet deze aanpassingen, anderen niet.
4. Het opmaakmenu verschijnt enkel als je een stuk tekst selecteert.
5. Je kan ook afbeeldingen van je computer naar het artikel slepen, tekst plakken uit andere toepassingen (zoals MS Word, Excel, webpagina's...)
6. Als je klaar bent, kan je de pagina met notities afdrukken.
In dit deel bestuderen we hoe digitale systemen zoals computers informatie verwerken. Begrijpen ze die informatie ook? Wat doet een computer met gesproken of geschreven taal? Wat betekent gezichtsherkenning precies? Zijn computers intelligent of lijken ze dat alleen maar? Hoe kan het dat een computer een foto kan weergeven of âonthoudenâ? Weet hij echt wat er op een foto staat?
Wat vormt de hersenen van de computer? Waardoor kan hij die gegevens verwerken? Zullen computers en andere digitale systemen de mens ooit voorbijsteken in intelligentie? Hoe ver staan die toestellen al op het vlak van KI (of AI)?
We kijken ook verder dan de interface tussen mens en machine. Hoe verwerkt een digitaal systeem al die binnenkomende signalen, de invoer van de gebruiker, hoe genereert hij diverse soorten feedback en output?
Als je een tekst invoert op je computer of een tekst publiceert op internet, weet je zelf waarover die tekst gaat. Computers kennen de inhoud niet, of beter gezegd, ze begrijpen absoluut niet waarover je het hebt. Ze snappen de betekenis niet. Voor een computer of stuk software is een tekst niet meer dan een reeks karakters die op hun beurt nog eens worden vertaald in bits (nullen en enen, je weet wel).
Wanneer een docent je op een examen een vraag stelt, dan kan je daar in het beste geval vlot op antwoorden. Je begrijpt de vraag, maakt in je hoofd de juiste analogie en vergelijkingen en je kan de inhoud simultaan vertalen in je eigen woorden. Je leert het niet uit je hoofd en je rammelt het niet woord voor woord betekenisloos af. Dat zou je natuurlijk kunnen doen, maar een docent verwacht dat je intrinsiek verbanden kan leggen, de betekenis snapt.
Wanneer je in de zoekmachine Google de zoekterm âhaarâ invoert, dan moet je niet meteen verwachten dat Google het dichtstbijzijnde kapsalon op het scherm tovert. âHaarâ heeft meerdere betekenissen (vb. een bezittelijk voornaamwoord). Meer nog, je voert zoektermen in omdat je beseft dat Google nog minder raad zou weten met de vraag âWat is het dichtstbijzijnde kapsalon?â Google herkent geen natuurlijke taal, zoals zo goed als geen enkel softwareprogramma eigenlijk. Daarom moet je ook niet lachen met Google Translate als hij geschifte vertalingen oplevert. Het is eerder verbazingwekkend te noemen wat âGoogle Translateâ wel kan.
Google en andere zoekmachines snappen totaal niet waarover de inhoud van die miljarden webpagina's op het wereldwijde web gaat.
âHallo wereldâ... De eerste applicatie die een programmeur in wording schrijft, levert als uitvoer steevast deze regel op. Nochtans begrijpt het programma zelf niet wat het aan het zeggen is. Of dit nu âHello worldâ of âVandaag eten we friet en banaanâ is. De programmeur schrijft het programma in een programmeertaal, maar die is geheel anders opgebouwd dan menselijke talen.
Je hoort het wel vaker. De computer kan geen âopen vragenâ interpreteren, âgesloten oefeningenâ wel. Een stuk software kan perfect kruiswoordraadsels, invuloefeningen, combinatie-oefeningen en dies meer verbeteren, maar open vragen zijn een ander paar mouwen. De computer weet niet veel raad met vragen als âWaarom probeerde België zich los te maken van Nederland in 1830 (en is het nog gelukt ook)?â
Beeld je de volgende oefening in:
Op 6 ......................... vieren we de verjaardag van â¦...........................
Zie ginds komt de ......................... uit ............................ weer aan.
We kunnen een stuk software schrijven dat dit soort oefeningen perfect kan verbeteren. We schrijven het zo dat ook andere zinnen kunnen ingevoerd worden. Een docent/leraar zou op de volgende manier een oefening kunnen aanmaken die door de software automatisch wordt omgezet in een invuloefening:
Op 6 <antwoord>december</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas</antwoord>
De software weet dat hij alle woorden tussen de markering â<antwoord></antwoord>â moet verbergen. Bovendien kan hij zelf tellen hoeveel vragen er zijn. In de eerste zin moeten twee woorden worden ingevuld. De oefening staat dus op 2 punten. Maar hier duikt meteen een probleem op. Wat als de student/leerling i.p.v. december gewoon een 12 invoert, of i.p.v. Sinterklaas, âde sintâ? Dit kan je als docent toch onmogelijk fout rekenen?
Heel wat programma's lossen dit op door aan de gebruiker te vragen meerdere mogelijke antwoorden in te voeren. In ons geval zou het er dan als volgt kunnen uitzien:
Op 6 <antwoord>december/12</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas/de sint</antwoord>
Maar ook dan zijn de problemen niet helemaal van de baan. Want wat moet je als docent doen met een leerling met dyslexie die â demecberâ schrijft of â sntriklaasâ? Ook die antwoorden moeten goedgekeurd worden. Uiteraard niet voor iedereen, enkel voor leerlingen met een schrijf/taalprobleem. Het zou niet zinvol zijn om alle mogelijke schrijffouten vooraf in te voeren. Bovendien zouden leerlingen zonder taalproblemen dan rijkelijk beloond worden.
Vaak worden zulke softwarematige âproblemenâ ervaren alsof software niet in de mogelijkheid zou verkeren om hier een echte oplossing voor te bieden. NLP of Natural Language Processing 1 kan echter heel wat van deze beperkingen opvangen.
NLP combineert elementen uit de wetenschap, de taalkunde en het domein van Artificiële Intelligentie (AI). Twee belangrijke domeinen waarop NLP zich toespitst zijn
het afleiden van betekenis uit menselijke (natuurlijke) talen en
het genereren van ânatuurlijke taalâ (denk aan Google Translate).
Alan Turinglegde de basis voor NLP met zijn beroemde Turingtestwaarbij een mens en een machine op afstand in vraag-antwoord-stijl met elkaar communiceren. Als de machine de mens kan overtuigen dat hij âeveneens een mensâ is, dan evenaart de machine in Turings ogen de menselijke intelligentie. De computer slaagt in de test als hij in meer dan 30% van de tijd voor een mens wordt aanzien.
Joseph Weizenbaum ontwikkelde tussen 1964 en 1966 ELIZA, de eerste beroemd geworden âchatbotâ. ELIZA simuleerde een psychotherapeut, een goed uitgangspunt om in vraag-antwoordstijl te werken. Omdat de kennis van ELIZA erg beperkt was, antwoordde de âchatbotâ vaak met open vragen zoals âWaarom zeg je dat je hoofdpijn hebt?â.
De supercomputer Eugene Goostman slaagde in juni 2014 voor de test door het âbreinâ van een 13-jarige te simuleren. 2
Om een machine (computer, software...) taalte laten begrijpen, moet ze ook de betekenis van een tekst of zin kunnen achterhalen.
Wanneer een kind taal leert, vertaalt het simultaan de werkelijkheid naar taal en omgekeerd. Een dorp bevat straten en huizen, een huis bevat kamers, kamers bevatten meubels enz.
Woorden en begrippen hebben relaties en staan in verband met elkaar... Woorden en begrippen vormen netwerken, interfereren met elkaar enz. In hun hoofd vormen en herkennen kinderen stapsgewijs al die relaties en begrippenkaders... ze krijgen een beeld van de wereld en van de werkelijkheid: een ontologie.
Vanaf de jaren 1970 zagen programmeurs in dat het nodig was om ook voor NLP zulke âontologieënâ te ontwikkelen. De ârelatiesâ en âbegrippenkadersâ uit de echte wereld moesten vertaald worden naar gegevens die door een computer konden begrepen worden.Voorbeelden van zulke âontologieënâ zijn ondermeer MARGIE, SAM en PAM... Ze leidden tot nieuwe chatbots zoals Parry en Jabberwacky 3 .
Deze manier van werken had tot gevolg dat in de jaren 1980 de meeste NLP-systemen bestonden uit eindeloze reeksen regeltjes, tot verregaande schematisering van taal. Vanuit softwarecode gezien leidde dit tot eindeloze âif-elseâ-structuren. Je kent het wel: âAls (if) je braaf bent, krijg je een koekje, anders (else) een stokje.âIn de werkelijkheidzit er veel meer variatie. Het is mogelijk dat het kind anders altijd heel braaf is en nu één keertje stout. Neem je dan het vieruurtje af?
In de werkelijkheid verloopt niet alles zwart (1) â wit (0), het is niet altijd zus of zo. Als je 4 tekorten hebt op je rapport is de kans groot dat je mama boos is, tenzij ze weet dat je heel erg je best hebt gedaan. In de echte wereld wegen we voortdurend af, volgen we niet altijd stricte regels, werken we volgens waarschijnlijkheden en statistische kansen.
Heel wat nieuwe NLP-systemen zouden zich gaan baseren op zulke statistische modellen. Die ârevolutieâ binnen de NLP-wereld was ook een gevolg van de beperkte rekenkracht van de toenmalige generatie computersystemen. Gokken ging nu eenmaal sneller en makkelijker dan eindeloze reeksen âifâ- en âelseâ-structuren te doorlopen. Ook de taaltheorieën van Noam Chomsky, de Amerikaanse taalkundige, die grammaticale gelijkenissen tussen talen zocht, eerder dan verschillen, vormden een rijke inspiratiebron.
Zulke statistische systemen werken veel beter in het geval van âonverwachte invoerâ van de gebruiker ( vb. sniterklaas i.p.v. Sinterklaas). In de echte wereld zijn afwijkingen en fouten immers niet ongewoon, integendeel. Vooral op het vlak van âvertalingenâ bieden de statistische technieken succes. Veel vertaalprogramma's die gebaseerd waren (en soms nog zijn) op woordenlijsten (een soort vertalende woordenboeken) liepen al snel tegen hun grenzen aan. Je kan immers geen zinnen vertalen door de individuele woorden te vertalen, maar door kleine brokjes data te vertalen en hieruit ook te âlerenâ.
Statistische systemen zijn echter ook niet heiligmakend (denk aan Google Translate). Recent ligt de focus op een combinatie van beide technieken: de âharde regeltjesâ-weg en de statistische techniek.
Het mag duidelijk zijn dat we ondanks het aanvankelijke optimisme in de jaren 1960 nog een hele weg moeten afleggen vooraleer machines menselijke talen begrijpen en er mee kunnen communiceren. Toch staan de ontwikkelingen niet stil. Bereikt de machine dan echt âkunstmatige intelligentieâ zoals Alan Turing stelde? Vreemd genoeg verandert de betekenis van AI (articifial intelligence)bij elke nieuwe vooruitgang. Zo werd âschakenâ lange tijd als het toppunt van menselijke intelligentie gezien. Toen de IBM-computer Deep Bluede wereldkampioen schaken Garry Kasparov versloeg, verloor schaken plots veel van zijn allure. De volgende uitdaging kwam er aan: computers zouden nooit creatief kunnen antwoorden op âopenâ vraagstellingen. In 2010 ging IBM's supercomputer Watsonde uitdaging aan en won: hij versloeg met glans de âall-time-greatest human Jeopardy champions, Ken Jennings en Brad Rutterâ 4 . De Jeopardyquiz stelt open vragen over alle domeinen van de menselijke cultuur. De vragen bevatten tal van woordspelingen en hints, maar zelden een duidelijke vraagstelling.
Op tal van terreinen die vroeger als uniek voor de menselijke intelligentie werden gezien, steekt de machine zijn menselijke tegenspeler voorbij. Machines zullen nooit gevoelens hebben of bewustzijn. Maar wat betekent dit precies?
Lees het kleine verhaaltje hieronder:
De hond slaapt in zijn mandje. Jacky is heel erg lief. Als ik thuis kom, komt hij al kwispelstaartend naar me toegelopen. Waar blijft hij vandaag? Weet jij het? Ik ben zo bang dat hij weggelopen is.
Als menselijke lezer snap je meteen waarover dit korte tekstje gaat. Hoe kunnen we een machine leren om deze tekst te begrijpen? Tussen mens en machine is er in dit geval al meteen een immens verschil. Een kind leert al snel een visueel beeld van een hond te koppelen aan het begrip âhondâ en de bijhorende geluiden. Denk maar aan de mama's en de papa's die vragen: âEn, hoe doetde hond? Nee, niet miauw.â
Het taalmechanismein het hoofd van het kind koppelt aan de hond bepaalde acties zoals blaffen, lopen, kwispelstaarten, maar ook onderdelen zoals staart, poten, tong... Een heel kader, onderdeel van de âwereldontologieâ in het hoofd van het kind.
Maar hoe vertalenwe die taalverwerking naar een computer? Oeps, dat is wat anders.
Laat ons eerst eens de tekst scheiden in zijn onderdelen: zinnen ( sentence breaking). Dat kan eenvoudig door te zoeken naar leestekens zoals punten, vraagtekens of uitroeptekens. Dit werkt perfect voor heel wat talen, maar niet voor pakweg Arabisch, Chinees of Japans, want daar is het gebruik van leestekens onbekend. Vervolgens kunnen we de zinnen splitsen in hun diverse woorden ( word segmentation), maar dat werkt al evenmin voor de genoemde talen: Arabisch kent bijvoorbeeld geen door spaties onderscheiden woorden. Daar bepaalt het uitzicht van een bepaald karakter (letter) of het gaat om het begin, het midden of het einde van een woord.
Zinnen bepalen of ze iets meedelen of eerder iets vragen (het vraagteken), en vragenop hun beurt kunnen open of gesloten (ja of neen, if of else, 1 of 0) zijn. De soort zinnen wordt bepaald door de âdiscourse analysisâ. De machine kijkt vervolgens naar de individuele woorden en probeert die te herleiden tot hun basis of stam in een proces dat âstemmingâ en âmorphological segmentationâ heet. In een taal als het Engels is dit een relatief eenvoudig proces:
openis de âstamâ van open, opens, opening, opened...
In talen zoals het Turks is dit een uiterst moeizame techniek. De stam is niet noodzakelijk hetzelfde als de morfologische âwortelâ van het woord. Meestal volstaat het dat verwante woorden dezelfde stam bevatten. Heel wat zoekmachines behandelen woorden met dezelfde stam als synoniemen om de zoekterm enigszins uit te breiden (conflatie).
Googlegebruikt âstemmingâ sinds 2003.
Voordien zou de zoekterm âvisâ niet âvissenâ of âgevistâ opgeleverd hebben.
Dit leidt soms tot foute resultaten. De machine kan teveel resultaten leveren (overstemming) zoals wanneer je âuniversiteitâ zoekt en ook âuniversumâ krijgt. In dit geval behandelt de machine beide woorden door hun gemeenschappelijke stam als synoniemen. In andere gevallen krijg je te weinig zoekresultaten (understemming).
Bij woorden zoekt het NLP-systeem niet alleen naar de stam, maar bovendien ook naar de woordsoort: gaat het om een adjectief of een zelfstandig naamwoord? Bovendien kunnen zelfstandige naamwoorden ook eigennamen zijn.
Jackyis een hond.
Deze techniek van ânamed entity recognitionâ werkt simpelweg door naar hoofdletters te kijken. Maar ook dit levert problemen op. Bij het begin van een zin schrijf je steevast een hoofdletter. In het Duits krijgen dan weer alle naamwoorden een hoofdletter.
Jackyist ein Hund.
En in het Engels schrijf je ook een hoofdletter als je het over jezelf hebt:
Iwanna be your dog.
De woordsoort wordt vaak bijgehouden in een soort lexicon, een soort lijst waarin op basis van de stam en eventuele voor- en achtervoegsels de woordsoort wordt bepaald (
Part-of-speech tagging). Maar eenvoudig is dit niet. Immers, afhankelijk van de zin kan een woord iets compleet anders betekenen:
Ik speel met de balop het bal.
Je merkt het al. De betekenis zit niet in het woord alleen, maar ook in zijn relatie met andere woorden: homoniemen (w
ord sense disambiguation). De volgende zin klinkt afhankelijk van tegen wie (je docent) of wat (een eik) je het zegt helemaal anders, maar een NLP-systeem heeft het er moeilijk mee:
Je bent een eikel.
Via de techniek van â
n
atural language understandingâ probeert een NLP-systeem logica te vinden in korte fragmenten tekst. Welke adjectieven horen bij zelfstandige naamwoorden (
conference resolution)? Wat zijn de onderlinge relaties tussen objecten in een zin (
r
elationship extraction)?
Op die manier probeert een NLP-systeem stilaan de zin te âparsenâ, een stamboom te maken van een zin en tenslotte van het hele verhaal.
âJe bent een eikel,âzei ik tegen de directeur .Ik was woedend.Hij werd door mijn uitspraak eveneens razend.
Deze zin verklapt hoe beide partijen zich voelen. Een NLP-systeem kan op basis van de betekenis van woorden en de frequentie waarmee ze voorkomen, raden wat het gevoel is dat uit een tekst spreekt:
sentiment analysis
. Je kan het zelf uittesten op
https://semantria.com/.
Fouten laten herkennen door een machine vraagt geen âhogereâ intelligentie.
Een basisvoorbeeld van âtokenizationâ: van elk woord wordt bepaald of het alfabetisch, numeriek of symbolisch is:
Een voorbeeld van âtaggingâ waarbij van elk woord de woordsoort wordt opgegeven op basis van een âlexiconâ (een woordenlijst):
In het volgende hoofdstuk behandelen we OCR, een techniek om een gescande of gekopieerde tekst (uit afbeeldingen dus) te converteren naar bewerkbare tekst. Dat is relatief gezien â
peanutsâ in vergelijking met NLP.
Vooraleer machines vlekkeloos in menselijke talen kunnen communiceren, is er nog een hele weg af te leggen. Het draait niet enkel om de semantiek.In de Studio 100-reeks ROX praat de gelijknamige auto vlekkeloos met de andere (menselijke) personages. Hij herkent en interpreteert hun vragen en antwoorden en reageert er vaak laconiek op. Onze vriend âROXâ combineert het beste op het vlak van NLP met speech recognition, speech segmentationen speech processingen als kers op de taart natural language generation.
Het verstaan van gesproken taal (speech recognition) is nog een aardig stuk moeilijker dan het lezen of interpreteren van gedrukte tekst omdat er in gesproken tekst nauwelijks pauzes zijn tussen woorden. Ook letters vloeien onhoorbaar in elkaar over. Het verdelen van een uitspraakin afzonderlijke woorden (speech segmentation) is vreselijk moeilijk te programmeren. Natural language generation, het genereren van taal in geluidsvorm, is daarentegen al aardig ingeburgerd in bijvoorbeeld GPS-systemen. De software kan in dat geval gebruik maken van vooraf opgenomen geluid (afzonderlijke woorden of zinnen) dat het tot de gewenste zinnen samenvoegt. Dat is echter nog heel wat anders dan het kunstmatig âtoon per toonâ genereren van spraak (speech synthesis).
Lees het volgende deel: Deel 3b: Afbeeldingen digitaliseren
1Opgelet: Natural Language Processing is niet hetzelfde als Neuro Linguïstisch Programmeren (http://nl.wikipedia.org/wiki/Neurolingu%C3%AFstisch_programmeren
2"Computer denkt voor het eerst als mens in Turing Testâ, http://www.automatiseringgids.nl/nieuws/2014/24/computer-denkt-voor-het-eerst-als-mens-in-turing-test, Geraadpleegd op 23 september 2014.
4Bostrom, N. Superintelligence. Paths, dangers, strategies, Oxford, 2014.
Bron afbeelding: Kris Merckx -
www.ardeco.be
Ongetwijfeld ken je het pentagram, de vijfpuntige ster die vaak in verhalen en teksten over hekserij en magie opduikt. Het pentagram beantwoordt op verschillende manieren aan de verhouding van de gulden snede.
| `a/b=phi` | `b/c=phi`
|
`c/d=phi`
|
Prachtige voorbeelden van de relatie tussen Fibonaccireeksen en de gulden snede vind je in de natuur.
Bron: http://io9.com/5985588/15-uncanny-examples-of-the-golden-ratio-in-nature
Bron:
http://io9.com/5985588/15-uncanny-examples-of-the-golden-ratio-in-nature
In het Parthenon, de tempel gewijd aan de godin Athena op de Akropolis in Athene, is die "gulden verhouding" terug te vinden. Het vooraanzicht is 1,6 keer breder dan de hoogte. De zuilen zijn 1,6 keer langer dan de te ondersteunen bovenkant.
Esthetische ontwerpen wekken de perceptie dat ze eenvoudiger in gebruik en dus gebruiksvriendelijker zijn, ook al is dit niet automatisch zo. Esthetische ontwerpen nodigen meer uit tot een positieve attitude. Mensen zijn ook toegeeflijker en toleranter tegenover ontwerpfouten als het ontwerp er esthetisch goed uitziet. Een mooi interface-ontwerp werkt als katalysator voor de creativiteit en probleemoplossend denken. Minder esthetische ontwerpen, verstikken de creativiteit. Esthetische ontwerpen worden sneller geaccepteerd, en wekken de indruk dat ze gebruiksvriendelijker zijn. Uiteraard blijft âschoonheidâ en âesthetiekâ een zeer subjectief gegeven, maar de perceptie is op dit vlak moeilijk te wijzigen. Denk aan het idee dat veel Applegebruikers hebben over de producten van hun favoriete merk. Wie aan Apple denkt, denkt aan mooi design, gebruiksvriendelijkheid, eenvoud in gebruik, stabiliteit... ook al klopt dat niet altijd. Voor concurrenten is het bijzonder moeilijk om die perceptie voor de eigen productlijn op te wekken.
âOver kleuren en smaken valt niet te discussiërenâ zegt het spreekwoord. Nochtans klopt dit niet helemaal. Je kan twee kleuren die op het eerste zicht met elkaar âvloekenâ bij elkaar plaatsen als dat uw smaak is. Maar wanneer je er andere kleuren of tinten bij betrekt, gaat die stelling niet meer op. Passende kleurcombinaties kan je wiskundig berekenen. Niet alle kleuren of tinten passen bij elkaar. Op paletton.com kan je passende kleurpaletten berekenenen voor je eigen ontwerpen.
Consistentie van stijl en kleur maken een systeem meer helder en bruikbaar.
Oeps, dit lijkt wel een stukje wiskunde en dat is het ook. Fibonaccireeksen (oneerbiedig ook wel eens âkonijnenreeksenâ genoemd naar het voortplantingsgedrag waarmee deze dieren worden vereenzelvigd) komen in de natuur heel vaak voor. In een Fibonaccireeks is elk volgend getal de som van de twee voorgaande getallen
Fibonaccireeksen duiken op in de natuur, maar ook in de vormgeving.
Vaak gebruikt men Fibonaccireeks in nauw verband met de zogenaamde Gulden Snede, één van de invloedrijkste patronen in wiskunde en vormgeving. Bij de Gulden Snede snijdt men een rechthoek zodanig in twee delen dat (⦠lees nu even heel aandachtigâ¦) het grootste deel en het kleinste deel zich net zo verhouden als het grootste deel tov. de ganse rechthoek. Euh???? Je merkt het al in het bovenstaande voorbeeld. In de rechthoek hebben we een vierkant afgezonder van 8 bij 8 ruitjes en eentje van 5 bij 8 ruitjes. Je kan die kleinste rechthoek opnieuw gaan indelen zodat je (net zoals in een Fibonaccireeks) opnieuw een gelijkaardige verhouding verkrijgt.
Plaats je een passer op het scheidingspunt tussen twee vierhoeken en trek je een kwartcirkel, dan bekom je een soort van spiraalvorm. De Gulden Snede duikt op in de natuur en reeds in de Oudheid gebruikten kunstenaar het in de architectuur en de kunst.
De Gulden Snede bereken je op de volgende manier: a : b = (a+b) : a (waarbij a en b de verhouding zijn van de brede en de lange zijde). De verhouding tussen a en b heet het Gulden Getal en uitgedrukt met de Griekse letter PHI (opgelet: niet PI of 3,14...)
Is het een voorbeeld van onze onbewuste voorkeur voor esthetiek en verhoudingen?
In de architectuur en vormgeving dook vooral sinds de twintigste eeuw de idee op dat esthetiek ondergeschikt is aan de functie. Functies zijn inderdaad minder subjectief dan esthetische overwegingen. Toch heeft het voorgaande al duidelijk aangeduid dat esthetiek niet onbelangrijk is. Als ontwerper kies je niet tussen vorm en functie. De vorm kan best wel afgestemd zijn op de functie. De functionaliteit mag niet verloren gaan achter het uitzicht.
e.
Symmetrie wordt altijd als schoon ervaren. We onderscheiden drie vormen van symmetrie
Weerspiegeling,
rotatie,
translatie
Symmetrie in webdesign.
3
Leesbaarheid gaat verder dan enkel het kunnen lezen van een aanwezige tekst. De informatie moet vlot opgenomen worden en bestendigen in het geheugen en de herinnering van de eindgebruiker. Informatie in welke vorm ook (teksten, afbeeldingen, artikels, invulformulieren...) kunnen zo gepresenteerd worden dat de informatie vlotter toegankelijk is en de gebruiker meteen een duidelijk overzicht krijgt.
Referenties
KNIGHT, K., "Symmetry in Design: Concepts, Tips and Examples", (http://sixrevisions.com/web_design/symmetry-design/), Geraadpleegd op 9 september 2015.
"Welk lettertype gebruik ik het best?", (http://www.wallacesanders.be/veelgestelde-vragen/welk-lettertype-gebruik-ik-het-best/), Geraadpleegd op 10 september 2015.
Dit bestand is auteursrechtelijk beschermd. Gebruik het enkel voor studiedoeleinden.
Rechtenvrije films en foto's: www.pixabay.com
Transparante PNG-afbeeldingen: www.stickpng.com
Geluid en muziek: https://freemusicarchive.org/
Lees eerst Soorten interfaces
UX-design staat voor User Experience design. Bij het ontwikkelen van digitale interfaces moet men uitgaan van een âUser centered design processâ. De ontwikkelaar(s) moeten verschillende factoren tegen elkaar afwegen:
User Centered Design Process
User needs
Business needs
Bij het ontwikkelen van een interface komt heel wat kijken:
visual design
information architecture
user interface design
usability
Bekijk zeker eens dit filmpje: https://www.youtube.com/watch?v=Ovj4hFxko7c
De ontwikkelaar bevindt zich op het knooppunt tussen het digitale systeem en de eindgebruiker. Aan de kant van de machine moet hij kennis hebben van grafisch ontwerp, besturingssysteem, programmeertalen en ontwikkelomgevingen. Aan de menselijke kant komen grafisch ontwerp, communicatietheorie, taal, sociale wetenschappen, psychologie, emoties... om de hoek kijken. Daarom is het ontwerp van een HCI (Human Computer Interface) zelden het werk van één persoon.
In dit deel bekijken we niet zo zeer hoe je een interactieve interface ontwerpt, want daarvoor moet je doorgaans al aardig wat kunnen programmeren. We bekijken echter een aantal universele ontwerpprincipes, die niet enkel gelden voor HC-interfaces, maar voor elk product dat een bedieningsinterface nodig heeft, en bij uitbreiding voor nagenoeg elk ontwerp (product, affiche...) dat je ooit zal maken of bedenken. De tips die je in dit onderdeel leest, zijn niet altijd âwetenschappelijkâ bewezen, maar in veel gevallen eerder âgood practiceâ. Hanteer ze bij het ontwerp van presentaties, websites, producten, affiches, logo's, reclamefolders. Uiteraard bespreken we onderstaande tips vooral in het kader van HC-interfaces.
Tip: Met de open source tool Pencil ( http://pencil.evolus.vn/) kan je snel een GUI prototypen. Dat wil zeggen dat je er een interface mee kan bouwen van hoe een programma of GUI voor een applicatie er volgens jou zou moeten uitzien.
Arduino en Little bits uit het vorige deel zijn voorbeelden van modulair ontwerp. Ook desktopcomputers en in wezen elke âthuisâcomputer, zijn voorbeelden van modulair ontwerp. Wie wat overweg kan met computeronderdelen kan zijn eigen toestel modulair samenstellen. Een externe harde schijf, een USB-stick, een printer/scanner... kan je beschouwen als afzonderlijke modules. Ook in moderne programmeertalen (zogenaamde object-georiënteerde talen) werken modulair, met klein herbruikbare stukjes code. Software en apps op tabletcomputers en smartphones kan je beschouwen als apart te installeren modules. Een modulair ontwerp maakt het voor de gebruiker mogelijk om zijn digitaal systeem uit te breiden of te wijzigen.
Applehardware (iPhone, iPad) is vaak bewust heel beperkt modulair. Je kan de opslagcapaciteit niet eigenhandig uitbreiden, je bent als gebruiker beperkt bij het aansluiten van randapparatuur. Nochtans is ook de âbinnenkantâ van pakweg een iMac heel erg modulair opgebouwd (www.ifixit.com).
Modulariteit betekent echter niet automatisch dat we een systeem of een interface onbeperkt kunnen schalen. Iets wat functioneert op kleine schaal werkt bijvoorbeeld niet noodzakelijk op een grote schaal. Een touchscreeninterface werkt fijn op een smartphone of een tablet, maar op een computer met een groot beeldscherm is het niet meteen een gebruiksvriendelijke interface. Een toetsenbord werkt handig op een laptop of computer, maar is behoorlijk onhandig op een mobiele telefoon.
Toegankelijkheid blijft niet beperkt tot een systeem bruikbaar maken voor mensen met een beperking. Iedere gebruiker heeft baat bij een toegankelijk systeem. Een interface dient zo ontworpen te worden dat hij vlot toegankelijk is voor iedereen. Bedieningsgemak en eenvoud in gebruik zijn belangrijke normen. Een goed ontworpen interface zorgt ervoor dat gebruikers zo min mogelijk fouten kunnen maken.
Toegankelijkheid en gebruiksvriendelijkheid hangen af van een heleboel factoren.
Een gebruikersinterface moet eerst de lagere behoeften van de gebruiker bevredigen, daarna pas de hogere. We hebben het hier uiteraard niet over voedselvoorziening, maar over de functionaliteit van een digitaal systeem. Een tekstverwerker bijvoorbeeld moet in eerste instantie de mogelijkheid bieden om tekst in te voeren, tekstopmaak, het toevoegen van tabellen en afbeeldingen zijn hogere behoeften.
Hierin volgt een ontwerper de behoeftepiramide.
|
Functionaliteit |
Bepaalde functies mogelijk maken. |
|---|---|
|
Betrouwbaarheid |
Een videorecorder moet echt opnemen als je op de ârecordâ-knop drukt. |
|
Gebruiksgemak |
Je kan dingen makkelijk doen. |
|
Bekwaamheid |
Je kan dingen beter doen dan voordien. |
|
Creativiteit |
Alle behoeften zijn bevredigd. Indien je dit niveau bereikt, verkrijg je van de gebruikers soms een loyaliteit met cultachtige status (vb. Apple) |
Bij het ontwerp kies je niet tussen flexibiliteit (veel mogelijkheden) en gebruiksgemak. Je moet zelf afwegen welk onderdeel voor jouw ontwerp of interface het meest doorweegt. Een flexibel ontwerp biedt de gebruiker meer mogelijkheden, maar is minder efficiënt.
Een vaak gemaakte fout is veronderstellen dat flexibiliteit boven gebruiksgemaak gaat. Een PC is bijvoorbeeld heel flexibel, maar moeilijker aan te leren en te bedienen dan een smartphone. Bij een PC zijn veel mogelijkheden bij aankoop nog onbekend. Een student die de richting multimedia start, heeft geen idee waarvoor hij/zijn zijn toestel een paar maand later allemaal zal gebruikt hebben. De verkoper/ontwerper moet in dit geval anticiperen op het toekomstig gebruik. Als het publiek inzicht heeft in wat het wil, heeft specialisatie voorkeur. Voor iemand die klaar en duidelijk weet dathij enkel af en toe wat wil surfen op het internet, volstaat een tabletcomputes. Wie niet precies weet waarvoor hij een computer allemaal zal inzetten, mikt op flexibiliteit.
Flexibiliteit betekent echter niet dat we gebruiksgemak uit het oog moeten verliezen. Eenvoud in gebruik heeft steeds de voorkeur boven complexiteit. Volg het KISS-principe ( keep it simple and smoothof keep it simple and stupid). Twijfel je bij het ontwerp van een interface tussen een simpele oplossing en een meer complexe omdat die bijvoorbeeld intelligenter overkomt, kies dan steevast voor de simpele (de regel van âOckhams scheermesâ).
c. Mapping:
Als een gevolg overeenkomt met de verwachting dan zit de mappinggoed. Wanneer een knop of een reeks acties of commando's in een digitaal systeem precies leidt tot wat de gebruiker verwacht, dan zit het gebruiksgemak goed. Plaats de bedieningsonderdelen (knoppen, sliders...) zodanig dat mensen weten wat er zal gebeuren als ze er gebruik van maken.
d. Prestaties
Het is niet omdat iets beter âpresteertâ, dat de voorkeur van de gebruiker daarnaar uitgaat.
e . H erkenning boven herinnering:
In de eerste computerinterfaces gaf de gebruiker commando's via een tekstinterface. Je moest de instructies of commando's goed onthouden om de computer te vertellen wat je precies wou doen. In een GUI zitten commando's achter knoppen verstopt. Dat maakt het gebruik veel eenvoudiger. De gebruiker âherkentâ de commando's en hoeft ze niet meer te onthouden. Houd hier rekening mee wanneer je een interface bouwt. Wanneer de gebruiker te veel stappen moet onthouden, zal hij sneller geneigd zijn hulp in te roepen. Maak de gebruiker desnoods bij elke stap duidelijk wat de volgende stap is. De in besturingssystemen aanwezige API's maken het voor programmeurs mogelijk om herkenbare dialoogvenster op te roepen vanuit hun eigen software. Maak zelf ook gebruik van herkenbare symbolen en de plaats waar je ze geeft op het computerscherm. Hoe herkenbaarder, hoe groter het gebruiksgemak.
a. G epercipieerd gebruiksgemak:
Esthetische ontwerpen wekken de perceptie dat ze eenvoudiger in gebruik en dus gebruiksvriendelijker zijn, ook al is dit niet automatisch zo. Esthetische ontwerpen nodigen meer uit tot een positieve attitude. Mensen zijn ook toegeeflijker en toleranter tegenover ontwerpfouten als het ontwerp er esthetisch goed uitziet. Een mooi interface-ontwerp werkt als katalysator voor de creativiteit en probleemoplossend denken. Minder esthetische ontwerpen, verstikken de creativiteit. Esthetische ontwerpen worden sneller geaccepteerd, en wekken de indruk dat ze gebruiksvriendelijker zijn. Uiteraard blijft âschoonheidâ en âesthetiekâ een zeer subjectief gegeven, maar de perceptie is op dit vlak moeilijk te wijzigen. Denk aan het idee dat veel Apple-gebruikers hebben over de producten van hun favoriete merk. Wie aan Apple denkt, denkt aan mooi design, gebruiksvriendelijkheid, eenvoud in gebruik, stabiliteit... ook al klopt dat niet altijd. Voor concurrenten is het bijzonder moeilijk om die perceptie voor de eigen productlijn op te wekken.
b. Kleuren:
âOver kleuren en smaken valt niet te discussiërenâ zegt het spreekwoord. Nochtans klopt dit niet helemaal. Je kan twee kleuren die op het eerste zicht met elkaar âvloekenâ bij elkaar plaatsen als dat uw smaak is. Maar wanneer je er andere kleuren of tinten bij betrekt, gaat die stelling niet meer op. Passende kleurcombinaties kan je wiskundig berekenen. Niet alle kleuren of tinten passen bij elkaar. Op paletton.com kan je passende kleurpaletten berekenen voor je eigen ontwerpen.
Consistentie van stijl en kleur maken een systeem meer helder en bruikbaar.
c. Fibonaccireeksen en de Gulden Snede
Oeps, dit lijkt wel een stukje wiskunde en dat is het ook. Fibonaccireeksen (oneerbiedig ook wel eens âkonijnenreeksenâ genoemd naar het voortplantingsgedrag waarmee deze dieren worden vereenzelvigd) komen in de natuur heel vaak voor. In een Fibonaccireeks is elk volgend getal de som van de twee voorgaande getallen. Fibonaccireeksen duiken op in de natuur, maar ook in de vormgeving ( Gulden snede ).
Vaak gebruikt men Fibonaccireeks in nauw verband met de zogenaamde Gulden Snede, één van de invloedrijkste patronen in wiskunde en vormgeving. Bij de Gulden Snede snijdt men een rechthoek zodanig in twee delen dat (â¦
lees nu even heel aandachtigâ¦) het grootste deel en het kleinste deel zich net zo verhouden als het grootste deel tov. de ganse rechthoek. Euh???? Je merkt het al in het bovenstaande voorbeeld. In de rechthoek hebben we een vierkant afgezonderd van 8 bij 8 ruitjes en eentje van 5 bij 8 ruitjes. Je kan die kleinste rechthoek opnieuw gaan indelen zodat je (net zoals in een Fibonaccireeks) opnieuw een gelijkaardige verhouding verkrijgt.
Plaats je een passer op het scheidingspunt tussen twee vierhoeken en trek je een kwartcirkel, dan bekom je een soort van spiraalvorm. De Gulden Snede duikt op in de natuur en reeds in de Oudheid gebruikten kunstenaar het in de architectuur en de kunst.
De Gulden Snede bereken je op de volgende manier: `a : b = (a+b) : a` (waarbij a en b de verhouding zijn van de brede en de lange zijde). De verhouding tussen a en b heet het Gulden Getal en uitgedrukt met de Griekse letter PHI (opgelet: niet PI of 3,14...)
Is het een voorbeeld van onze onbewuste voorkeur voor esthetiek en verhoudingen? Lees meer over de Gulden snede en Fibonacci:
Gulden snede
d. Vorm volgt functie:
In de architectuur en vormgeving dook vooral sinds de twintigste eeuw de idee op dat esthetiek ondergeschikt is aan de functie. Functies zijn inderdaad minder subjectief dan esthetische overwegingen. Toch heeft het voorgaande al duidelijk aangeduid dat esthetiek niet onbelangrijk is. Als ontwerper kies je niet vorm en functie. De vorm kan best wel afgestemd zijn op de functie. De functionaliteit mag niet verloren gaan achter het uitzicht.
e. Symmetrie:
Symmetrie wordt altijd als schoon ervaren. We onderscheiden drie vormen van symmetrie
Weerspiegeling,
rotatie,
translatie
Translatie-symmetrie in een gridsysteem voor websites. 1
Rotatie-symmetrie 2
Symmetrie in webdesign.
3
Een interface/ontwerp moet vlot leesbaar zijn. Het letterbeeld, het gekozen lettertype, de lettergrootte kunnen de leesbaarheid bevorderen of kraken. In doorlopende tekst gebruik je een vlot leesbaar lettertype. Schreefloze letters zijn vlotter leesbaar voor dyslectici, maar uiteindelijk haalt iedereen er voordeel uit.
Bron 4
Leesbaarheid gaat verder dan enkel het kunnen lezen van een aanwezige tekst. De informatie moet vlot opgenomen worden en bestendigen in het geheugen en de herinnering van de eindgebruiker. Informatie in welke vorm ook (teksten, afbeeldingen, artikels, invulformulieren...) kunnen zo gepresenteerd worden dat de informatie vlotter toegankelijk is en de gebruiker meteen een duidelijk overzicht krijgt.
a. Hiërarchie:De zichtbaarheid kan erg verbeteren door hiërarchische verbanden te visualiseren. Die techniek is zeer effectief om de structuur en de toegankelijkheid te te bestendigen in het geheugen van de gebruiker. Dit kan op diverse manieren met boomstructuren, netstructuren, trapstructuren, lagen...

b
. Chunking:Splits de informatie die je aanbiedt op in kleine eenheden. Mensen kunnen 5 tot 7 onderdelen vlotjes onthouden. Om die reden vind je in dit cursusboek 7 delen en vaak 5 tot 7 subonderdelen.
c. Beeldende representatie: gebruik van pictogrammen en afbeeldingen
Bron afbeelding
5: Schermiconen op het bureaublad van de Xerox Star, de opvolger van de Xerox Alto (1981).
De meeste GUI's maken veelvuldig gebruik van pictogrammen. De metrointerface van Microsoft Windows is daar tendele van afgestapt. Het gebruik van schermpictogrammen als symbolische links naar bepaalde programma's of bestanden is reeds aanwezig van bij de eerste âgraphical user interfacesâ voor de Xerox Alto-computer in de vroeger jaren 1970.
Men onderscheidt in interfacedesign verschillende soorten pictogrammen:
â vergelijkbare pictogrammen: tekeningen die lijken op een handeling, object of concept.
â voorbeeldpictogrammen: dingen die geassocieerd worden met een handeling (vb. hangslot voor beveiliging).
â symbolische pictogrammen: afbeeldingen van een handeling op eenhoger abstractieniveau.
â weinig of geen verwantschap (vb. een schelp in SmartSchool om naar je puntenboek te gaan).
â
Een beeld zegt meer dan duizend woorden,â is een veel gehoorde uitspraak, maar klopt slechts ten dele. Men doelt dan op het zogenaamde visuele geheugen, maar er is weinig wetenschappelijk bewijs voor het bestaan van iets als een âvisueelâ of âauditiefâ geheugen. Uiteraard geldt ook hier âherkenning boven herinneringâ, maar meer afbeeldingen leiden niet noodzakelijk tot een âbetere herinneringâ.In het ontwerp van user interfaces en presentatie gaat de voorkeur uit naar een
combinatie van tekst en afbeelding.
d . S tapsgewijze informatieverstrekking (progressive disclosure):
De complexiteit van een toepassing kan aardig verlagen door de informatie niet alleen in kleine onderdelen (chunks) op te splitsen, maar ze ook stapsgewijs te verstrekken. Een slideshow, 'lees meer'-knop, uitklapmenu's, leerpaden (in bijvoorbeeld e-learningomgevingen), tabbladen... verhogen op die manier eveneens het leerrendement.
e. Nabijheid en similariteit:
Gebruikers ervaren elementen die dicht bij elkaar liggen als gerelateerd, en elementen die elkaar overlappen als âgemeenschappelijkâ. Knoppen die op elkaar gelijken, lijken eerder bij elkaar te horen. Hoe dicht bepaalde elementen bij elkaar staan, bepaalt dus in sterke mate hoe ze door de gebruiker ervaren worden. Zorg ervoor dat benamingen vlak bij elementen staan en niet in afzonderlijke âlegendaâ (zoals bijvoorbeeld bij grafieken in MS Excel).
f. V an Restorff-effect:
Welke momenten uit je schooltijd heb je het best onthouden? Niet zo zeer de leerstof, maar vooral de anekdotes. Opvallende dingen onhoud je nu eenmaal beter dan gewone dingen. Dat heet het âVan Restorffâ-effect. Wil je elementen benadrukken, zorg dan dat ze opvallen. Gebruik eventueel ongewone beelden, speel met het tekstbeeld...
g . S eriële positie-effect:
Gebruikers onthouden items aan het begin van een lijst (of het nu gaat om een reeks slides in de presentatie, een lijst met knoppen...) het best, die in het midden het minst. Naar het einde van de lijst toe, blijven items weer beter in het geheugen hangen.. Dit recentheidseffectgeldt vooral bij een auditieve lijst.
h. Signaal-ruisverhouding:
Houd een interface of voorstelling overzichtelijk, en overlaadt ze niet met te veel beeld of animatie. Alles wat de ontvanger te veel afleidt van de eigenlijke boodschap vormt ruis. Een goede interface zorgt voor betere communicatie met de eindgebruiker. Richt je daarom op het âsignaalâ en beperk de âruisâ.
Ik bestel om 19 uur 's avonds treintickets op de website van de NMBS. Vooraleer ik de bestelling kan uitvoeren, moet ik de gebruiksvoorwaarden, die ik uiteraard niet lees, goedkeuren. Ik wil vooral dat dit snel is afgehandeld. Dat verwacht je ook van de gebruikersinterface. De betaling verloopt via een externe site en even later krijg ik in mijn mailde bestelde tickets in PDF-formaat. Wanneer ik ze afdruk, blijkt dat ik de (zo goed als) voorbije dag als afreisdatum heb ingesteld. Er zit niets anders op dan de tickets nogmaals aan te kopen en, inderdaad, nogmaals 65 euro te betalen. Ik meld mijn fout aan de online support van de NMBS, maar krijg nooit antwoord en het geld wordt ook niet terugbetaald. Als gebruiker ben ik bestraft voor mijn onoplettendheid en vooral omdat ik snel wou zijn. Nergens heeft de site me gewaarschuwd dat het wel vreemd is dat ik tickets bestel voor een dag die zo goed als afgelopen is. Nochtans is het nogal waanzinnig om tickets met toegang tot het pretpark Plopsaland de Panne te bestellen als het pretpark al een uur is gesloten. Het foutief betaalde bedrag krijg ik niet terug omdat ik âakkoordâ ben gegaan met de gebruiksvoorwaarden. Toegegeven, mijn fout, maar ook: welkom in de wereld van slecht interface-design en gebrek aan feedback. De support achter de digitale omgeving hult zich in stilzwijgen. In de echte fysieke wereld zouden zulke vormen van âbestraffingâ als bijzonder onrechtvaardig ervaren worden.
Een goede UI moet deze vormen van âdigitale onrechtvaardigheidâ voorkomen door gerichte foutcontroles in te bouwen.
a. B evestigingsprocedure:
Door bevestiging te vragen, kunnen onopzettelijke en ondoordachte handelingen voorkomen worden. Overdrijf hier echter niet in, want anders krijgen gebruikers het âben je hier wel zeker vanâ-gevoel. Verificatie is enkel noodzakelijk indien het beslissingen nadien niet meer kunnen aangepast worden. In het bovenstaande NMBS-voorbeeld had de site kunnen vragen: âU staat op het punt tickets te bestellen voor een dag die bijna afgelopen is. Bent u hier zeker van?â
b. Restricties:
Door
stapsgewijze informatieverstrekkingkan het aantal potentiële fouten tot een minimum herleiden. Zulke
f
ysieke restricties(begrenzingen, paden) laten de gebruiker toe bepaalde functies enkel binnen een bepaalde zone uit te voeren.
Daarnaast kan je het foutief gedrag van eindgebruikers voorkomen door een reeks p s ychologische restricties:
â symbolen: waarschuwing, icoontjes, pictogrammen kunnen gebruikersgedrag beïnvloeden
â conventies: rood is gevaar, geel is waarschuwing
â
mapping: welke handelingen zijn mogelijk? De zichtbaarheid, het uiterlijk, de plaatsing van de interface-elementen... spelen hier een rol.
c . G arbage in, garbage out:
Als je fouten kan invoeren, krijg je foute output (vb. in veld van postcode: niet invullen of geen cijfer invoeren). Foutcontrole voorkomt foute output. Als UI-ontwerper moet je voorkomen dat troepwordt ingevoerd. In webpagina's gebeurt op basis van âreguliere expressiesâ (zie 5.3.1) een controle op invoer van gebruikers in formuliervelden.
d. De wet van Fitts en inspanningsbelasting
Hoe verder een doel verwijderd is, hoe langer het duurt om het te bereiken. Hoe sneller de beweging en hoe kleiner het doel, hoe groter de foutenmarge (door snelheid en accuraatheid). Het menu dat tevoorschijn komt als je op de rechtermuisknop drukt staat meteen bij het doel. Die beperkt het aantal potentiële fouten bij de invoer of bewerking van gegevens. Hier geldt eveneens de inspanningsbelasting:
e . O perante conditionering:
Operante conditionering is een techniek om gewenst gedrag positief te bevestigen/belonen en ongewenst gedrag te bestraffen. Het duikt vaak op in leeromgevingen (e-learning) en games. Men hanteert bij UI-design drie methodes: positieve en negatieve bekrachtiging, bestraffing (vb. volgend level of game over).
a . W et van Hick en controle van de functionaliteit
![]() Hoe meer opties een gebruiker krijgt, hoe langer de benodigde tijd om een beslissing te nemen (wet van Hick). Dit wil niet zeggen dat je de mogelijkheden van een interface volledig moet afbouwen en de mensen enkel voorzien van een simplistische interface met nagenoeg geen mogelijkheden. Heel wat software begrenst de mogelijkheden afhankelijk van de kennis en de ervaring van de gebruikers. De gebruiker krijgt dan via een knop toegang tot een aantal
geavanceerdeopties. In games vorderen gebruikers stapsgewijs doorheen verschillende niveaus (levels).
Hoe meer opties een gebruiker krijgt, hoe langer de benodigde tijd om een beslissing te nemen (wet van Hick). Dit wil niet zeggen dat je de mogelijkheden van een interface volledig moet afbouwen en de mensen enkel voorzien van een simplistische interface met nagenoeg geen mogelijkheden. Heel wat software begrenst de mogelijkheden afhankelijk van de kennis en de ervaring van de gebruikers. De gebruiker krijgt dan via een knop toegang tot een aantal
geavanceerdeopties. In games vorderen gebruikers stapsgewijs doorheen verschillende niveaus (levels).
b. 80/20-regel:
Gebruikers benutten volgens schatting 80% van de werktijd slechts 20% van de functies in een UI. Bij het ontwerp van een interface moet je je dan ook richten op die 20%. Niet-kritische functies die behoren tot de 80%, beperk je tot een minimum of je gooit ze helemaal weg. Ondermeer om die reden zit bij software veel functionaliteit verborgen achter uitklapmenu's.
Herkenning gaat boven herinnering, Een herkenbare âomgevingâ verhoogt de gebruiksvriendelijkheid.
a. Affordance en skeuomorfisme
Afbeelding: Skeuomorfisme in Apple Garageband.
De fysieke eigenschappen van een object of omgeving (bijvoorbeeld een interface) beïnvloeden het functioneren ervan. Dat klinkt nogal ingewikkeld, maar een paar voorbeelden maken veel duidelijk. Een deur nodigt uit om een kamer te betreden, een raam biedt die functie ook, maar is hiervoor minder âuitnodigendâ (tenzij je een inbreker zou zijn natuurlijk). Die vorm van âuitnodigingâ noemt men
affordance. Als de affordance van een object om omgeving goed overeenkomt met de bedoelde functie, dan verhoogt het gebruiksgemak en de doelmatigheid van de prestaties. Een deur met een âklinkâ nodigt uit om aan te trekken, niet om tegen te duwen. Als je de klink vervangt door een vlakke metalen plaat, weet de gebruiker meteen dat hij/zij tegen de deur moet duwen om binnen te komen. De affordance zit op dat moment zeer goed.
Bij het ontwerp van software-interfaces gebruikt men vaak afbeeldingen van fysieke objecten om de functie van de interface-elementen te verduidelijken. Het programma Garageband van Apple gebruikt bijvoorbeeld herkenbare knoppen van gitaarversterkers om de affordance te verhogen. Die techniek waarbij men afbeeldingen van bestaande toestellen of onderdelen ervan gebruikt binnen een andere omgeving, heet skeuomorfisme. Het beperkt zich zeker niet tot software alleen. Het nabootsen van materialen in meubels of bij interieurdesign, is eveneens een vorm van skeuomorfisme. Bij software is het de bedoeling dat zogenaamde "skeuomorphs" de herkenbaarheid en het gebruiksgemak verhogen. In wezen kan je heel wat "metaforen" die men bij het ontwerpen van interfaces gebruikt, skeuomorfismen noemen: de prullenmand, het bureaublad. De graad waarin een ontwerper de overeenkomst met fysieke objecten doorvoert kan echter meer of minder prominent zijn. Steve Jobs en Apple-ontwerper Scott Forstall waren grote voorstanders van skeuomorfisch ontwerp. Na de dood van Steve Jobs en het ontslag van Forstall, kreeg John Ive, een groot tegenstander van skeuomorfisme, de leiding over de "look and feel" van iOS7. Dit verklaart de plotse ommekeer in de Apple-interface van een sterk aanwezig skeuomorfisme naar een meer vlakke stijl in de aard van Microsofts "metro"stijl. Tegenstanders van skeuomorfisme argumenteren dat skeuomorfisme enkel een "overgangsfase" was:
"Now recall what skeumorphism really is: itâs a transitional design to aid us over the bridge from old ways of doing something to the new way. But now almost all adults have crossed over that bridge. Future smartphone sales are going to be either replacement phones or to the young just entering the marketplace. And those latter wonât have any clue at all about those old ways of doing things. Who currently under the age of 20 will ever see a Rolodex outside a museum (or their grandparentsâ study)?"(Tim Worstal) 1
Toch wil dit geenszins zeggen dat hiermee elke overeenkomst met âfysiekeâ objecten of omgevingen overboord wordt gegooid.
b. Metaforen
Hoe sterk tegenstanders van skeuomorfisme ook hun best doen, een digitale interface blijft op één of andere manier wel steeds schatplichtig aan zijn analoge voorgangers. We spreken nog steeds van een bureaublad of desktop, ook al ervaart lang niet iedereen dit meer als een digitale versie van een âechtâ bureaublad. Een map (Engels: folder) heet nog steeds een map. Een âprullenmandâ blijft nog steeds aanwezig in zo goed als elke GUI. In heel wat applicaties blijven ontwikkelaars zich bedienen van metaforen en analogieën met âanaloge voorgangersâ. Adobe Photoshop gebruikt net zoals een massa andere digitale beeldbewerkingsapplicaties virtuele âlagenâ waarmee je als gebruiker composities kan samenstellen, net zoals tekenfilmmakers vroeger elk beeld opbouwden door afzonderlijke figuren op celluloidlagen boven elkaar te plaatsen. De tijdlijn in videomontagesoftware is nog steeds een virtuele weergave van een klassiek filmspoor. Adobe Flash noemt zijn werkgebied de âsceneâ en objecten kan je bewaren in de âlibraryâ. Gelijkenissen en metaforen zorgen voor herkenbaarheid en dat is misschien maar goed ook.
c. Mimicry
In de natuur bootsen wandelende takken een echte âtakâ na om zich te verbergen voor hun vijanden. Op dezelfde manier bootsen interface-ontwikkelaars fysische objecten of hun functionaliteit na om de herkenbaarheid te verhogen. Een klassiek telefoontoestel en zelfs een iPhone bootst in zijn toetsenbord het toetsenbord van een rekenmachine na. Die nabootsing kan op drie niveaus gebeuren:
|
het uiterlijk lijkt op iets anders |
pictogram van een map |
|
het ontwerp gedraagt zich zoals iets anders |
een robot die zich beweegt zoals een insect |
|
het ontwerp werkt zoals iets anders |
toetsenbord van een rekenmachine bij een oude Nokia-GSM. |
Een goed en herkenbaar verhaal, een pittige anekdote, een pakkend emotioneel verhaal... zorgt voor een gevoel van herkenbaarheid. Bij de presentatie van een product, een film of animatie, een presentatie trekt een sterk verhaal de aandacht van de gebruiker. Bij User Interface- of User Experience-design kan storytelling op nog een andere manier ter hulp schieten.
Het ontwerp bepaalt hoe gebruikers (mensen) het eindproduct ervaren. Dit gebeurt op verschillende niveaus en vertaalt zich in drie vormen van ontwerp: 2
|
Visceral design |
we houden automatisch van bepaalde dingen (knappe mensen, symmetrie...) en voelen ons afgestoten van andere (spinnen, rot vlees...). Dit niveau bepaalt onze eerste relatie met een ontwerp. |
We kiezen er bewust voor om âbangâ te zijn als we naar een griezelfilm gaan kijken. |
|
Behavioral Design |
Hoe werkt het product? De look and feel, gebruiksvriendelijkheid... |
Hoe ervaren we de film? |
|
Reflective Design |
Welke waarde kennen we aan het product toe na het eerste gebruik. |
We weten dat de vampieren niet echt bestaan en ons (zeker niet vanuit de film) lastig kunnen vallen. |
Bij het ontwerp van een product, dienst, interface... moeten we terdege rekening houden met die drie niveaus. Hoe de eindgebruiker de interface of het product emotioneel aanvoelt, bepaalt mee het succes van het ontwerp. Bij UX-design werken professionals met heel verschillende achtergronden samen aan één project. Er moet rekening gehouden worden met grafisch ontwerp, technische mogelijkheden en beperkingen, commerciële overwegingen enz. Het is niet eenvoudig om in zo'n samenwerkingsverband de eindgebruiker centraal te stellen. De eindgebruiker is het âExperience Themeâ (Cindy Chastain), de hoofdrolspeler van het UX-ontwerp. Zonder zo'n leidraad kan er wel een product afgeleverd worden, maar dan blijft het een verhaal zonder doel, of beter gezegd een verhaal zonder rode draad.
Oef, dit klinkt allemaal nogal ijl en wellicht denk je, wat moet ik hiermee? Nochtans is het niet zo vreemd dat het uiteindelijke doel van een ontwerp een eindgebruiker (en liefst meer dan één is). Ongetwijfeld heb je al een beeld voor ogen van het doelpubliek. Door fictieve personages met al even fictieve, maar potentieel mogelijke, verhalen te verzinnen voor de ontwerpronde, krijgt ieder lid van het ontwerpteam een duidelijk beeld van wat het uiteindelijke doel van het ontwerp is. Ieder lid van het team kan op die manier het oorspronkelijke doel en de strategie voor ogen houden, ongeacht zijn/haar taak of achtergrond. Elk lid van het ontwerpteam kan zich hierdoor inleven in de eindgebruiker.
1.
1KNIGHT, K., "Symmetry in Design: Concepts, Tips and Examples", (http://sixrevisions.com/web_design/symmetry-design/), Geraadpleegd op 9 september 2015.
2
Ibid.
3
Ibid.
4
"Welk lettertype gebruik ik het best?", (http://www.wallacesanders.be/veelgestelde-vragen/welk-lettertype-gebruik-ik-het-best/), Geraadpleegd op 10 september 2015.
5
INTERACTION DESIGN FOUNDATION,
"A Brief History of the Origin of the Computer Icon"
, (https://www.interaction-design.org/ux-daily/21/a-brief-history-of-the-origin-of-the-computer-icon), Geraadpleegd op 10 september 2015.
De Microsoft Kinect is een zeer geavanceerde spelcontroller voor de Xbox. Je kan het toestel ook 'hacken' en inzetten voor gebruik in andere software/hardware-omgevingen. BORENSTEIN, G.,
3D-scanning met Processing en Kinect: MELGAR, E.,DIEZ, C.,
3D motion tracking met Processing en Kinect:
Een interactieve interface met Processing en Kinect:
Een pixelafbeelding moet een bestaande afbeelding omzetten in digitale codes of een âbeeld uit de werkelijkheidâ omzetten in een reeks digitale codes. Het principe achter digitalisering is even eenvoudig als geniaal, en vooral ook niet nieuw. Reeds in de Klassieke Oudheid was de techniek van het âdigitaliserenâ of coderen van informatie bekend. Uiteraard digitaliseerde men toen geen afbeeldingen, maar gebruikte men een gelijkaardige techniek voor het verzenden van tekstboodschappen.
Cleoxenus en Democlitus bedachten een methode die verder werd uitgewerkt door Polybius, waardoor de communicatie op lange afstand aanzienlijk verbeterde. Ze gebruikten combinaties van fakkels, vastgemaakt aan panelen. Elke combinatie van fakkels vertegenwoordigde een bepaalde letter uit het alfabet. Hiervoor werden twee (houten?) panelen opgesteld. Elk paneel was voorzien van houders voor maximum 5 fakkels. Dit gaf een totaal van 25 mogelijke combinaties wat ongeveer overeen kwam met het aantal letters in het Griekse alfabet.
Naar analogie kunnen we dit vergelijken met de werking van een kruiswoordraadsel. Het eerste paneel staat dan voor de horizontale cijfers in het raster, het tweede (rechtse) paneel voor de verticale cijfers langs het raster. Twee fakkels op het linkerpaneel en vijf fakkels op het rechterpaneel stonden voor de letter k. De vergelijking met een kruiswoordraadsel doet een beetje afbreuk aan de inventiviteit van deze vondst.
De zender âscantâ een tweedimensionale rij van lettertekens. Hij verzendt informatie over de positie van elk element in een raster.Het roept vergelijkingen op met de methodes die door televisies en faxtoestellen worden gebruikt voor het scannen en verzenden van afbeeldingen. Het doet ook denken aan de discretisatie bij het digitaliseren van afbeeldingen
1
.
Vergelijk een digitale afbeelding met een tabel (zoals bijvoorbeeld in een rekenbladprogramma). Elke horizontale pixel krijgt een cel in een (horizontale) rij. Maar ook verticaal wordt elke pixel in een rij geplaatst. Een afbeelding van 300 x 400 pixels bevat op die manier 400 kolommen (horizontaal) en 300 rijen of een totaal van 120 000 pixels.
Net zoals in MS Excel kan je een tabel ook voorstellen als een grafiek. In het vak wiskunde heb je geleerd dat een grafiek een horizontale as (de x-as) en een verticale as (de y-as) heeft. In een grafiek raken de x- en de y-as elkaar links onderaan. Op dat punt is x=0 en ook y=0. Bij een beeldscherm of bij een afbeelding vormt de linkerbovenhoek het absolute ânulpuntâ. De pixel links bovenaan op je computerscherm, in je programmavenster of de linkerbovenhoek van een digitale afbeelding staat op x=0 en y=0. De positie van die pixel is dus x=0 en y=0. Als we één pixel opschuiven naar rechts, dan zitten we op x=1, y=0 enz. Gaan we in plaats van naar rechts, één pixel naar beneden, dan krijgen we x=0, y=1 enz.
In de meest eenvoudige vorm van een digitale afbeelding kan elke pixel twee mogelijke waarden krijgen: een 0 of een 1. Een 0 zou dan kunnen staan voor wit en een 1 voor zwart. We spreken dan van een âbitmapâ, of een âbit-kaartâ. Inderdaad, elke pixel heeft een plaatsje gekregen op de âkaartâ en kan een waarde van één bit krijgen.
Hieronder zie je hoe je op die manier een smiley zou kunnen tekenen.
|
1 |
1 |
1 |
||||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
|||||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
|||||||||
|
1 |
1 |
|||||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
1 |
1 |
1 |
||||||
|
1 |
1 |
1 |
1 |
|||||||
|
1 |
1 |
1 |
1 |
1 |
Elk van die pixels heeft een positie in de tabel. De eerste pixel (links bovenaan) staat bijvoorbeeld op x=0 en y=0. Pixelbewerkingen op zo'n afbeelding zijn relatief eenvoudig. Als we de afbeelding willen âinverterenâ, dan vervangen we alle 1'en door een 0 en omgekeerd.
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
|||||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
||||
|
1 |
1 |
1 |
1 |
1 |
1 |
Uiteraard bevatten de meeste afbeeldingen meer dan 2 kleurwaarden. Hierover leer je meer in het volgende onderdeel.
Als we over digitale afbeelding spreken, dan hebben we het zowel over de manier waarop die afbeeldingen als bestanden worden bewaard, als over de manier waarop een digitaal beeldscherm de afbeeldingen weergeeft. Aan de binnenkant van een beeldscherm zitten de zogenaamde
pixels(picture elements), kleine âpuntenâ die het licht in een bepaalde kleur kunnen uitzenden. De
resolutievan een beeldscherm vertelt hoeveel pixels een scherm horizontaal en verticaal kan weergeven.
Pixels kunnen kleuren weergeven door de
primaire kleurenrood, groen en blauw in een bepaalde verhouding bij elkaar op te tellen (optellen= to add, vandaar
âadditiefâ kleursysteem).
De hoeveelheid die van elke primaire kleur nodig is om een bepaalde mengkleur te verkrijgen, drukt men uit in een getal van 8 bits oftwel 256 verschillende waarden. Vermits een computer ook 0 meerekent (geen hoeveelheid), kan de waarde variëren van 0 ('niets van die kleur') tot 255. Je kan die kleurwaarde ook uitdrukken in een âhexadecimaleâ waarde. Bij hexadecimale coderingkan je de volgende waarden toekennen om tot 256 verschillende combinaties te komen: 00 (tot 99 en alle combinaties daar tussen) tot FF (van AA tot FF en alle combinaties daar tussen). De waarde #CCCCCC geeft bijvoorbeeld lichtgrijs, #000000 geeft zwart, en #FFFFFF toont wit.
|
Kleur |
Rood |
Groen |
Blauw |
RGB-waarde |
|---|---|---|---|---|
|
Wit |
FF |
FF |
FF |
#FFFFFF |
|
Zwart |
00 |
00 |
00 |
#000000 |
|
Rood |
FF |
00 |
00 |
#FF0000 |
|
Groen |
00 |
FF |
00 |
#00FF00 |
|
Blauw |
00 |
00 |
FF |
#0000FF |
|
⦠|
⦠|
⦠|
⦠|
... |
Vermits elke kleur op die manier 256 verschillende waarden kan krijgen, komen we op een totaal van 256*256*256=16 777 216 mogelijke mengkleuren.
â
In toepassingen waar een hogere kwaliteit vereist wordt worden ook wel 12, 16 of nog meer bits per kleur gebruikt, waarmee kleurwaardes tussen 0 en 4095 resp. 0 en 65535 of nog meer aangegeven kunnen worden, zo bevatten RAW-bestanden van digitale camera's meestal 12-bits kleurwaarden.â
2
Het kleurenpalet in Adobe Photoshop:
Een aantal RGB-kleurwaarden
3
:
Digitale foto's zijn ook opgebouwd uit pixels en kunnen eveneens verschillend van afmeting zijn. Het aantal pixels per inch (PPI) noemt men de resolutievan de digitale afbeelding. Hoe hoger de resolutie, des te beter is de detailweergave.
Elke pixel heeft een kleur. Die kleur wordt vaak beschreven met een of meerdere bits (een âbitâ is een afkorting voor âbinary digitâ). Het aantal bits per pixel bepaalt het aantal kleuren dat een pixel kan weergeven. Een twee-bit pixel kan 4 kleuren weergeven; een 8-bit (eÌeÌn byte)-pixel geeft 256 kleuren weer. In het algemeen kan een pixel 2nkleuren weergeven als nhet aantal bits is. Welke verschillende kleuren een pixel kan weergeven, hangt niet alleen af van het aantal bits dat beschikbaar is, maar ook van de gebruikte kleurcodering. Er kan worden afgesproken dat iedere primaire kleur een aantal bits krijgt (RGB) of dat iedere unieke combinatie bits verwijst naar een bepaalde kleur in een palet. Dit laatste systeem wordt gebruikt in GIF-plaatjes, die maximaal 256 kleuren kunnen gebruiken.
Hoe hoger de beeldresolutie en hoe groter het aantal bits per pixel, hoe meer computergeheugen nodig is om alle informatie op het scherm te verwerken. In de allereenvoudigste weergave (1 bit = 1 pixel) kan een pixel alleen âaanâ of âuitâ staan.
Een megapixelis gelijk aan 1 miljoen pixels. De resolutie van een digitale camera wordt vaak in megapixels aangegeven. Dit is dan de resolutie (of het aantal pixels) die de CCD- sensor aankan. Om het correcte aantal pixels te weten vermenigvuldig je het aantal horizontale lijnen met het aantal verticale lijnen van de digitale foto. Zo is dus een camera die een foto produceert met een resolutie van 1280 x 960 pixels een 1.3 megapixel camera en een 5 megapixels camera zal dan een foto produceren van 2560 x 1920 pixels.
Hoe meer pixels, hoe groter het âbestandâ. Hoe meer pixels een afbeelding bevat, hoe meer informatie over de individuele kleuren moet bewaard worden. Om de bestandsgrootte in te perken kan men diverse compressietechnieken toepassen.
1. Een eerste manier bestaat erin om het aantal mogelijke kleurwaarden (de kleurdiepte) te beperken. Een GIF-afbeelding bijvoorbeeld kan maar 256 verschillende kleurwaarden bevatten voor alle kleuren samen. Dit betekent dat een GIF-afbeelding relatief klein is in bestandsomvang, maar ook niet meteen een geschikt formaat voor het bewaren van afbeeldingen waarin het aantal kleuren echt wel van belang is, zoals bijvoorbeeld een foto van een gezicht of een schilderij. In zekere zin bevatten alle digitale afbeeldingen een vorm van âcompressieâ, omdat ze het aantal kleuren in de werkelijkheid altijd op één of andere manier âbeperkenâ. Toch zal een afbeelding met een kleurdiepte van 16-bit (tov. 8 bit bij RGB-kleuren) of 24-bit veel meer ruimte innemen omdat ze veel meer kleurencombinaties mogelijk maakt. Dat wil daarom nog niet zeggen dat alle afbeeldingen sowieso even groot zijn. Een foto van een grasveld zal bijvoorbeeld minder âplaatsâ in nemen op een opslagmedium dan de foto van een schilderij van Pieter Paul Rubens.
2. Ten tweede kan je ook het aantal pixels reduceren.Je kan met beeldbewerkingssoftware het aantal pixels verlagen. Zo kan je een afbeelding van 1920 pixels breedte verlagen naar bijvoorbeeld 300 pixels. Deze techniek wordt vaak toegepast bij het klaarstomen van afbeeldingen voor het gebruik op internet. Ook het aantal pixels per inch kan verlaagd worden (dpi of dots per inch). Voor drukwerk heb je afbeeldingen nodig van 300 dpi, voor internet volstaan afbeeldingen met een resolutie van 72 dpi.Het aantal pixels of dpi verhogen is eveneens mogelijk, maar dit betekent niet dat de kwaliteit van de afbeelding groter wordt. De software voegt dan kunstmatig pixels toe door bepaalde pixels te verdubbelen. Verloren informatie kan echter niet worden âtoegevoegdâ. In politieseries op TV zie je bijvoorbeeld hoe men een âduidelijkâ beeld tevoorschijn tovert uit een lageresolutiebeeld van een digitale camera. Dit kan in feite niet.
3. T enslotte kan men ook met wiskundige algoritmes afbeeldingen comprimeren.Afbeeldingsbestanden kunnen op diverse manieren bewaard worden. TIFF, jpg, gif, png... zijn bekende bestandsformaten voor pixelafbeeldingen. Ze hebben allemaal hun specifieke doeleinden alsook voor- en nadelen. Een TIFF-afbeelding kan zonder compressie worden bewaard, d.w.z. dat alle pixelinformatie en alle informatie over de kleuren behouden blijft in het bestand. Uiteraard zorgt dit ervoor dat een TIFF-bestand veel meer ruimte inneemt op een opslagmedium.
Bij andere afbeeldingsformaten past de gebruikte digitale camera of software een compressiealgoritme toe. In zo goed als alle gevallen betekent dit dat bepaalde pixelinformatie verloren gaat en nadien ook niet meer kan worden toegevoegd.
Een voorbeeld van een compressie-algoritme:
'Het menselijk oog is gevoeliger voor helderheid dan voor kleur. Om op een onzichtbare manier informatie te verwijderen is het de bedoeling dat we minder informatie aan kleur opslaan dan aan helderheid.'Bij een JPG-afbeelding worden op die manier heel wat kleurverschilen weggelaten. Simpel voorgesteld: een jpegverdeelt een afbeelding in een raster waarbij gemiddelde waardes worden gemeten. Veel variatie in kleur wordt weggelaten. Hoe meer verschillen weggelaten worden, hoe groter de compressie.
Ongetwijfeld heb je al gehoord van beeldbewerkingssoftware zoals Adobe Photoshop of het open source GIMP ( www.gimp.org). Met software kan je heel eenvoudige bewerkingen uitvoeren op pixelafbeeldingen, maar ook heel geavanceerde waarbij je software gebruikt om composities te bouwen door verschillende lagenpixels âbovenâ elkaar te plaatsen. Met beeldbewerkingssoftware kan je allerlei bewerkingen doen op individuele pixels of op groepen pixels in een afbeelding.
Hogerop heb je reeds gezien dat een pixelafbeelding bestaat uit een aantal pixels.
Elke pixel krijgt binnen een matrix een unieke positie op basis van zijn x- en y-waarde in die âtabelâ.
Elke pixel heeft een kleurwaarde. In beeldbewerkingssoftware kan je op basis van de positie van elke pixel een bepaalde âactieâ uitvoeren. Een âgomâ in Adobe Photoshop zal bijvoorbeeld de positie van de muiscursor vergelijken met die van de pixels waarboven de muis zich bevindt en vervolgens de kleurwaarde van die pixels vervangen door âwitâ. Als je de âdigitale gomâ groter maakt, zal Photoshop niet alleen de pixel onder de muiscursor wit maken, maar ook alles in een straal daar rond.
Machines begrijpen niet welke informatie in een foto staat. Ze herkennen geen koe, zon, huis of mens.
Toch kan je via de website www.tineye.comzoeken op welke plaatsen op het internet een bepaalde foto reeds eerder is gepubliceerd. Ook een âdeelâ van een afbeelding volstaat om ze terug te vinden in de mazen van het wereldwijde web. De mobiele versie van Google kan streepjescodes, merknamen, schilderijen enz. herkennen en u op basis daarvan de gewenste zoekresultaten tonen. Google Picasa herkent gezichten en kan zelfs de daaraan gekoppelde âpersonenâ herkennen, eens je aan een gezicht een naam verbindt. De machines van de Belgische firma BEST kunnen dankzij de beeldherkenningschip van de Leuvense firma EASICS in een hels tempo producten herkennen. Ze filteren tegen een gigantische snelheid frieten en muizenketels uit krenten, of schroeven uit paperclips. Slimme camera's herkennen gezochte boeven, en digitale politiecamera's herkennen nummerplaten. Op luchthavens âzoekenâ camera's naar verdachte gedragingen van aanwezigen. Big Brother is watching you. Hoe gebeurt zulke â beeldherkenningâ ( image recognition)?
Op de manier waarop beeldherkenning of âpatroonherkenningâ werkt, is geen eenduidig en al zeker geen âeenvoudigâ antwoord te geven. Moderne image recognition-algoritmes werken vaak angstaanjagend goed, maar niet feilloos.
Image recognitionstoot op een hele reeks problemen die niet eenvoudig te overbruggen zijn. Zelfs firma's die zich reeds jaren op de ontwikkeling van zulke algoritmes toeleggen, stuiten nog steeds op het probleem dat hun âtoolsâ niet feilloos en 100% betrouwbaar werken. Menselijke controle of bijsturing is in veel gevallen nog steeds noodzakelijk.
Stel dat we een stuk software willen schrijven dat âgezichtenâ herkent in een afbeelding. Begrijp het niet verkeerd: de software herkent gezichten, maar niet de namen of personen die er aan verbonden zijn. Voor een mens is het duidelijk wat een gezicht is, maar het is niettemin moeilijk om er een definitie op te plakken die je in een herkenbare formule voor een machine zou kunnen gieten. We stuiten al snel op een definitie-probleem:
Een gezicht bevat een neus, twee ogen en een mond... maar hoe definieer je die individuele onderdelen ( feature detection)?
De onderlinge verhouding en positie van die âonderdelenâ is misschien belangrijker. Maar wat te doen als de machine enkel het zijprofiel van het gezicht te zien krijgt? Herkent de software dan nog steeds een âgezichtâ? Wat met âPiet Piraatâ als hij een ooglapje draagt? Is een smiley ook een gezicht? Vaak âtraintâ men de software met een trainingsset, waarbij de software zo is geprogrammeerd (met neurale netwerken) dat hij âkan lerenâ (eventueel met de hulp van een mens) of hij nu echt een gezicht heeft gevonden of niet. De software leert dan bij en onthoudt, net zoals een kind dat woordjes moet leren lezen.
Bovendien kan een afbeelding een gezicht in close-up tonen, of een groepsfoto met meerdere gezichten. Hier stuiten we op het probleem van â schaling-invariantieâ. Hoe vertel je een machine dat hij zowel âkleineâ als âgroteâ gezichten in een afbeelding moet herkennen? Sommige algoritmes kunnen met dit probleem van schaling overweg, maar de handigste manier om dit probleem te omzeilen is door te zorgen voor een â gecontroleerde omgevingâ.
Een voorbeeld:als je een camera in een straat hangt, kan je hem zo plaatsen dat de gezicht van alle mensen die voorbij de lens wandelen steeds ongeveer even groot zijn. Op die manier voorkom je het schalingsprobleem. 's Nachts gaat de camera problemen ondervinden met het herkennen van âgezichtenâ omdat de geregistreerde pixels de âdonkerâ zijn. Er is namelijk te weinig contrast tussen de gezichten en de omgeving. Een goed verlichte inkomhal is dus een beter te âcontrolerenâ omgeving dan een plaats in open lucht, waar de camera niet alleen te leiden heeft onder verschillen in belichting, maar ook onder regen, stof en wind.
Het mag duidelijk zijn dat er nog een verre weg is af te leggen vooraleer machines en software in staat zijn om met het gemak van menselijke intelligentie patronen zoals gezichten, huizen, dieren, groenten, fruit enz. te herkennen in een pixelbeeld van de omgeving.
Vectorafbeeldingen bestaan uit losse of gecombineerde geometrische vormen die met een kleur, verlooptint of 'afbeelding' worden gevuld.
Een cirkel zou je kunnen omschrijven op de volgende manier:
fill(0,0,255);
ellipse(200, 200, 100, 100);
De vulling van de cirkel wordt uitgedrukt in een RGB-waarde. De kleur van de cirkel is dus âblauwâ. De instructie ellipse() bevat een viertal parameters. De eerste paar waarden behandelen de x- en de y-positie t.o.v. het programmavenster. De twee volgende waarden bepalen hoe groot de âhorizontaleâ en de âverticaleâ straal moet zijn. Maak je die beide waarden gelijk, dan teken je een perfecte cirkel, maak je de ene waarde groter dan de andere, dan teken je een ellips.
Omdat enkel de cooÌrdinaten en de vormen en vullingen dienen opgeslagen te worden, blijven de bestanden uiterst klein. Een groot voordeel aan vectorafbeeldingen is dat zij oneindig kunnen geschaald worden zonder kwaliteitsverlies. Om de bovenstaande âellipsâ te vergroten, moet je enkel de waardes aanpassen:
fill(0,0,255);
ellipse(200, 200, 10000, 10000);
Lettertypes zijn over het algemeen eveneens vectorieel. Door deze voordelen zijn vectorafbeeldingen uitermate geschikt voor logo's, maar niet voor âfoto'sâ.
Vectortekenprogramma's:
Adobe Illustrator (commercieel)
Adobe Flash (commercieel, vectoranimatie)
CorelDraw (commercieel)
Processing (open source, vectoranimatie)
Raphael.js (open source, weergave van vectoren in webpagina's)
Xara (commercieel, open source en gratis versie)
Inkscape (open source en gratis)
Anders dan bij bitmapafbeeldingen die uit beeldpunten of pixels bestaan, bestaan er voor vectorafbeeldingen weinig algemeen ondersteunde opslagformaten. Het W3C heeft een internationale XML-standaard voor vectorafbeeldingen ontwikkeld onder de naam SVG (scalable vector graphics).
1Merckx, K.. Niet van gisteren, Leuven, 2013.
2RGB, (nl.wikipedia.org), geraadpleegd op 20 oktober 2014.
3 http://www.rapidtables.com/web/color/RGB_Color.htm, geraadpleegd op 4/11/2014.
In het eerste deel heb je gezien wat microcontrollers, embedded systemen en firmware zijn en wat ze doen. De elektronica slaagt erin inkomende signalen van sensoren of invoer van mensen te digitaliseren. In grotere digitale systemen zoals laptops, desktopcomputers, tablets, smartphones enz. zijn zoveel onderdelen of modules aanwezig dat er meer nodig is dan een enkelvoudige chip of controller voor de verwerking.
âAn operating systemis the level of programming that lets you do things with your computer. The operating system interacts with a computer's hardware on a basic level, transmitting your commands into language the hardware can interpret. The OS acts as a platform for all other applications on your machine. Without it, your computer would just be a paperweight.â 1
Een computer is eigenlijk niet veel meer dan een krachtige rekenmachine. Het Engelse âto computeâ betekent niet meer of minder dan âberekenenâ. Het rekent met nullen en enen en sluits die door een reeks processors (verwerkers) en circuits. In vergelijking met een microcontroller of SoC (zie deel 1) is de laptop, tablet, smartphone of desktopcomputer waarmee je werkt, vooral bedoeld als een zeer veelzijdig toestel. Je moet het voor meerdere taken kunnen inzetten. Het is geen ijverige werkmier of honingbij die voor één specifieke taak wordt ingezet. Een OS of operating system maakt het mogelijk om complexe programma's uit te voeren die gebruik maken van de aanwezige hardware. De mogelijkheden van de hardware vormen vaak de grens waar software aan gebonden is. Een operating software is over het algemeen niet geprogrammeerd in de aanwezige chips of hardware, want dan zou een operating system weinig flexibel zijn. Besturingssystemen zoals het bekende Linux, Mac OS X, Windows... verschijnen in de vorm van te installeren software.
Cool, maar wat doet zo'n besturingssysteem nu eigenlijk. Vergelijk het met de manager in een bedrijf. Een OS (vanaf nu gebruiken we gemakshalve de afkorting OS, van 'operating system' of 'besturingssysteem') bekijkt welke taken aan de gang zijn en verdeelt de middelen die hiervoor beschikbaar zijn, zoals het RAM-geheugen (het tijdelijke werkgeheugen dat wordt gewist als je het toestel uitschakelt), de benodigde opslagruimte, toegang tot randapparatuur, rekenkracht van de processor... In het ideale geval zorgt het OS ervoor dat iedereen(elke gebruiker, elk stuk software...) zijn taak naar wens kan uitvoeren en het systeem niet crasht wegens overbelast.
Een programmeur (of een groep) die een programma schrijft voor een specifieke taak, moet niet van nul beginnen. Hij beschikt reeds over een aantal in het systeem aanwezige functies of mogelijkheden. Vergelijk het naar analogie even met iemand die een huis bouwt: je moet niet zelf je bakstenen bakken, planken zagen, kalk blussen of je eigen truweel smeden. Je kan heel eenvoudig bestaande elementen inzetten om het gewenste eindresultaat te bereiken. De vergelijking loopt uiteraard mank. Maar zonder twijfel heb je die standaardfunctionaliteit bij een digitaal systeem al wel eens opgemerkt. Het OS zorgt er voor dat een softwareontwikkelaar niet rechtstreeks code moet schrijven om bepaalde invoer- of uitvoerapparaten aan te spreken of bestanden te openen of bewaren. Het OS vormt een eenvoudige laag (een interface) tussen de software en de hardware. Denk terug aan de tekening bij het einde van het eerste deel (deel 0!). De grens tussen elke laag in een digitaal systeem (in dit geval tussen de lagen âlogicâ en âioâ, en daarnaast de lagen âlogicâ en âstorageâ) vormt een interface, een grens waar beide lagen met elkaar kunnen communiceren. De interface tussen software en hardware heet de API of Application Programming Interface.
Een voorbeeldje: wanneer je onder Mac OS X een bestand wil openen, krijg je in zo wat elk programma een gelijkaardig dialoogvenster te zien, met dezelfde functionaliteit. Die mogelijkheden om bestanden te openen, te bewaren, af te drukken... worden geleverd door de API van het OS. Cool of verwarrend?
Het printdialoogvenster in LibreOffice onder Mac OS X.
Het printdialoogvenster in Voorvertoning onder Mac OS X.
De meeste programmaâs gebruiken dezelfde dialoogvenstersen bijna identieke knoppenbalken. Programmeurs maken namelijk gebruik van de apiâsdie het besturingssysteem biedt. Een API maakt het immers mogelijk om op eenvoudige wijze systeemtaken (bestanden openen, opslaan, afdrukken) uit te voeren. De programmeur schrijft bijvoorbeeld een stuk code dat het print-dialoogvenster van Windows opent.
Omdat niet alleen de processor, maar ook het besturingssysteem en de corresponderende apiâs verschillen, is het niet zonder meer mogelijk om een Windowsprogramma op pakweg een Mac OS X - of Linuxmachine te installeren en omgekeerd.
Heel wat âprogrammeursâ gebruiken een visuele IDE(Integrated Development Environment). Daarin kunnen ze grafisch aan de slag volgens het wysiwyg-principe (what you see is what you get). In zoân omgeving kan de ontwikkelaar bedieningselementen zoals vensters, knoppen, menubalken enzovoort naar zijn ontwerpvenster slepen en de nodige functionaliteit programmeren. De ontwikkelaar moet zorgen voor een gemakkelijk te bedienen gui (Graphical User Interface)zoals vensters, knoppen enz. en die bedieningselementen moet hij laten âsamenwerkenâ met achterliggende verwerkings- en opslagfuncties. Wanneer de gebruiker bijvoorbeeld op een knop drukt, leest het programma gegevens uit een databank of bestand in of kan het nieuwe gegevens opslaan. Voor Windows en Mac OS X bestaan IDEâs die standaard voorzien zijn van toegang tot de API-functies van het besturingssysteem en de standaard-gui-elementen (knoppen, vensters, menuâs). Een programmeur kan ook gebruikmaken van een platformonafhankelijke IDE, bijvoorbeeld Qt, waarin hij codes kan schrijven voor meerdere besturingssystemen. De ide neemt in dat geval de vertaalslag voor de verschillende systemen voor zijn eigen rekening. Daarnaast kan een ontwikkelaar zich ook bedienen van een widget toolkit, een widget library of gui toolkit. Zoân toolkit is een stuk software dat de programmeur de mogelijkheid biedt om vensters, menubalken, knoppen en andere gui- elementen in zijn code op te nemen. Sommige van deze toolkits (bijvoorbeeld gtk) hebben âhuiseigenâ dialoogvensters voor de gecompileerde programmaâs.
Het miniaturiseren van de computer en zijn onderdelen heeft ertoe geleid dat de computer is uitgegroeid tot een product dat vooral sinds de jaren 1990 in zowat elke huiskamer staat. Niet alleen de hardware, maar ook de programmaâs zijn een bron van inkomsten voor firmaâs. Naast commercieÌle software, waarbij de gebruiker enkel de gecompileerde versie kan kopen maar niet de originele broncode, bestaat er ook een tweede circuit, waarbij eveneens de broncodes beschikbaar worden gesteld. Deze opensourcesoftware is een doorn in het oog van veel commercieÌle softwareontwikkelaars.
Via internet werken ontwikkelaars over heel de wereld samen aan de succesvolste opensourceprogrammaâs, tegenwoordig vaak via een open softwareplatform dat speciaal is bedoeld om met groepen mensen aan dezelfde code te werken nl. GIT, zogenaamde âversie controle beheerâ -software. De gebruikers downloaden de gecompileerde versie, en installeren en gebruiken die software gratis. Ontwikkelaars duiken in de code en het is zelfs toegelaten de code voor andere doeleinden te gebruiken of er blokjes code uit te gebruiken. Zo lang ze de originele auteur maar blijven vermelden ... en dat is niet meer dan normaal, toch?
Een van de belangrijkste opensourceprojecten is gnu/Linux. Dit besturingssysteem werd als hobby ontwikkeld door Linus Thorvalds (1969) als alternatief voor Microsoft Windows. Hij gooide de basiscode van zijn systeem in 1991 op het internet. Sindsdien werken wereldwijd ontwikkelaars en bedrijven aan verbeteringen en uitbreidingen van het systeem. Om programmeurs die elkaar niet persoonlijk kennen via internet met elkaar te laten samenwerken en overlappingen te voorkomen, werden versiecontrolesystemen ontwikkeld. Dit zijn softwareprogrammaâs die het beheer van de code automatiseren en controleren. Daar de code vrij is, is het aan anderen toegestaan hun eigen versie te schrijven en publiceren. Linux wordt vooral op internetservers en door kenners gebruikt. Sinds de jaren negentig van de 20e eeuw beheerst het besturingssysteem Windows van Microsoft de markt van de âpersonal computersâ. Microsoft sluit hiervoor overeenkomsten met producenten en leveranciers, zodat nieuwe computers steevast geleverd worden met een installatie van Windows.
Een alternatief voor Windows is de Applecomputer, met het Mac OS-besturingssysteem. Daarnaast bestaan er nog tal van kleine besturingssystemen, vaak hobbyprojecten van individuele ontwikkelaars of âcommunityâsâ (groepen van ontwikkelaars die zich organiseren via internet), en professionele systemen op basis van UNIX, een besturingssysteem dat het levenslicht zag in Bell Labs (Bell Telephone Laboratories) in 1969. Een besturingssysteem is in werkelijkheid een stuk software dat bij het starten van de computer in het geheugen wordt geladen. Hierdoor kunnen andere programmaâs die voor dat systeem zijn geschreven op een afgesproken manier bepaalde functies van de computer aanspreken en gebruiken. Om dit mogelijk te maken bevat het systeem zogenaamde apiâs (application programming interface) of door het systeem vastgelegde codes of functies die je vanuit je eigen code kunt oproepen.
Klassieke âdesktopprogrammaâsâ bestaan vaak uit duizenden, zo niet honderdduizenden regels code. Voordat die code door een computer uitgevoerd kan worden, moet ze â zoals eerder werd gezegd â worden gecompileerd. Dit wil zeggen dat de code door een stuk software (de compiler) in machinetaal (nullen en enen) wordt omgezet. De gecompileerde code kan rechtstreeks door de processor worden uitgevoerd.
Het succes van GSM's en later smartphones en tablets deed de nood ontstaan aan mobiele compacte besturingssystemen. Het is een zeer veranderlijke wereld. Mobiele b esturingssystemenverdwijnen al even snel van de markt als de repsectieve merken die ze gebruiken. Een populaire systemen zoals Symbian, Windows Mobile, Palm OS, webOS, Maemo, MeeGo, LiMo⦠worden niet langer ontwikkeld. Op dit moment zijn Android, Apple iOS, Windows Phone, BlackBerry, Firefox OS, Sailfish OS, Tizen en Ubuntu Touch OS in gebruik. Mobiele toestellen met Android overheersen op dit moment (anno 2015) de markt. Android is een open source besturingssysteem ontwikkeld door Google Inc. op basis van de Linux-kernel. De open source-licentie heeft ertoe geleid dat ook andere fabrikanten het OS inzetten op hun toestellen. Google bundelt Android met een reeks closed source-applicaties zoals Google Play, Google Music, Google Search⦠2
Interesse in de geschiedenis van Operating Systems? Dan vormen de volgende pagina's een leuke intro:
http://www.linux-netbook.com/linux/timeline/
Bron: http://www.linuxfoundation.org/news-media/infographics/memorable-linux-milestones
3
Je doet het natuurlijk niet, want als je een computer koopt in een standaard computerwinkel of mediaketen, koop je het toestel met een kant-en-klaar geïnstalleerd besturingssysteem. Een PC of laptop komt met Windows, een Applecomputer met Mac OS X. Bij tablets of smartphones stellen we ons nog minder vragen: een iPad of iPhone komt met iOS, een andere tablet of smartphone met Android of Windows. Als je een desktopcomputer zelf samenstelt, moet je het besturingssysteem zelf nog installeren. Toch toont zo'n OS-loze computer ook de nodige output als je hem opstart. Je kent het heus wel van op een Windowstoestel. Bij het opstarten kan je één of andere functietoets indrukken om in een setup- of bootscherm terecht te komen. Hetzelfde geldt wanneer je voor de eerste keer een Raspberry Pi aan je televisiescherm koppelt. Wat je op dat moment te zien krijgt is de
firmware. De firmware is een interface die zich als een dun schilletje over de hardware heen legt. Het vormt dus geen onderdeel van het besturingsysteem zelf. Het doel van dit firmwareprogramma is te controleren of alles ok is met de hardware. Zo'n beetje als de conciërge van een winkel of school die 's morgens de deuren opent en alles nog eens controleert om te zien of zich nergens problemen hebben voorgedaan.
Op die manier controleert de firmware of de processor, het geheugen, de schijfstations en poorten geen fouten vertonen.
Op een Mac heet deze firmware UEFI (Unified Extensible Firmware Interface)
4
, op een Windowstoestel sprak men tot voor kort steevast over het BIOS (Basic Input Output System)
5
.
Na de firmware laat standaard de bootloaderdie op zoek gaat naar beschikbare besturingssystemen (op de harde schijf, in een schijfstation, op een USB-stick). Op de meeste systemen is slechts één besturingssysteem aanwezig, vindt de bootloader er meerdere dan laat hij de gebruiker de keuze welk systeem hij wil opstarten.
Software? Over software valt heel wat te zeggen. Software bestaat in maten en gewichten: van dure professionele pakketten tot al even professionele open source software waarvoor je niets hoeft de betalen. In Deel 6 bekijken we software vanuit multimediaperspectief. We gebruiken software voor het verwerken en bewerken van tekst, drukwerk, beelden, film, animatie, 3D, audio...
Meer en meer software werkt online of maakt op zijn minst de combinatie tussen offline en online mogelijkheden. Meer en meer zien commerciële bedrijven hun software niet als een te verkopen afgewerkt product, maar als dienstverlening ( SaaS= software as a service). De software staat in de âcloudâ en kan, mits je over de juiste licentie beschikt (en voldoende betaalt), van waar ook gebruikt worden.
Heel wat softwaretoepassingen draaien volledig op het web: Gmail, Google Docs, Facebook enz. zijn enkele van die veelgebruikte online services. Die dienstverlening kan tegen betaling gebeuren of volkomen âgratisâ zijn. De producent/leverancier haalt zijn inkomsten uit reclame die vaak op basis van de inhouden van de gebruiker gegenereerd worden.
Die evolutie naar het zien van software als het leveren van een dienst is overal aanwezig. Weinig eindgebruikers zijn nog bereid om een paar duizend euro (of zelfs een paar tientallen euro) te betalen voor één licentie op een bepaald softwareproduct. Die evolutie kent vermoedelijke meerdere oorzaken:
De groei van het internet en de toegenomen snelheid door snelle verbindingen.
De kracht van open source software: Waarom betalen als je even goed kan werken met een gratis product?
Software die als âproductâ werd verkocht op bijvoorbeeld een CD-rom kon gemakkelijk gekopieerd worden. Software die je via een âhuiseigenâ installatieprogramma op je computer plaatst en bij elk gebruik de licentiegegevens online controleert, is veel minder makkelijk te kopiëren.
Lang niet iedereen heeft alle functionaliteit nodig. Veel gebruikers zijn tevreden met kleine apps met een welbepaalde mogelijkheid. Kijk maar naar het succes van de appstores van Apple en Google.
1How Mac OS X Works, ( http://computer.howstuffworks.com/macs/mac-os-x1.htm), geraadpleegd op 1 september 2015.
2"Mobile operating system", (https://en.wikipedia.org/wiki/Mobile_operating_system#World-Wide_Share_or_Shipments), Geraadpleegd op 8 september 2015.
3( http://www.linuxfoundation.org/news-media/infographics/memorable-linux-milestones), Gedownload op 1 september 2015.
4UEFI, ( https://en.wikipedia.org/wiki/Unified_Extensible_Firmware_Interface#/media/File:Efi-simple.svg), gedownload op 1 september 2015.
5UEFI boot: how does that actually work, then? ( https://www.happyassassin.net/2014/01/25/uefi-boot-how-does-that-actually-work-then/), geraadpleegd op 1 september 2015.
Voor de meeste mensen hangt er een waas van mysterie en magie rond software en hardware. Het lijkt allemaal ontzettend ingewikkeld. Een leek die voor het eerst de achterliggende programma-instructies bekijkt, voelt zijn hoofd duizelen. Een programma betekent letterlijk een âprogrammaâ, in de simpelste vorm een reeks instructies die je na elkaar moet voltooien. Je kan niet zonder meer de volgorde veranderen, net zoals je bij een recept een reeks instructies na elkaar moet volgen om het gewenste eindresultaat te bereiken. Anders zal je pudding of chocoladecake er niet zo netjes uitzien en wellicht ook niet eetbaar zijn. Een computerprogramma gaat vaak verder dan een simpele reeks instructies. Het stuk hardware (computer, microcontroller, smartphone...) moet het programma zelfstandig (eventueel met interactie van de gebruiker) kunnen afhandelen. Het programma staat er alleen voor. Pudding zal niet protesteren alsde kinderen met hun lepels pudding naar elkaar beginnen gooien. Maar hardware is nu eenmaal niet zo âintelligentâ als een kind, het beseft niet altijd wat gebruikers beginnen doen. Misschien doet de gebruiker wel dingen die de programmeur niet bedoeld heeft. Daarom moet de programmeur rekening houden met (bijna alle) denkbare â wat alsâ-scenario's.
Menselijke talen zijn veel te complex om dienst te doen als programmeertaal. Programmeertalen moeten zo zijn opgebouwd dat elke instructie maar één ding kan betekenen. Het is voor een computer âzusâ (0 of 1) of âzoâ (1 of 0). Je weet wel: binaire code. Dit komt omdat de huidige computersystemen niet meer zijn dan een gigantisch grote hoeveelheid schakelaars. Zo'n beetje zoals de schakelaar waarmee je het licht aan en uit schakelt, maar dan vele malen kleiner.
Nullen en enen in een matrix om een afbeelding te tekenen (javascriptcode).
Omdat het omgekeerd voor een mens behoorlijk moeilijk is om pakweg tien miljoen schakelaars te bedienen enkel door een reeks nullen en enen in te tikken, zijn er oplossingen bedacht in de vorm van programmeertalen. Een programmeertaalbevat wel woorden uit menselijke talen (meestal uit het Engels), waardoor ze bevattelijk wordt. Meestal gaat het om korte instructies, mnemotechnische hulpmiddelen, symbolen, operatoren of logische schakelingen zoals and, or, if, else, end, print... Omdat die taal niet uit binaire code (nullen en enen) bestaat, is ze voor computers niet begrijpelijk.
Een compileris een speciaal stukje software (weer een programma) dat de in een programmeertaal geschreven instructies omzet in binaire code of machinetaal. Zo blijft de code voor de programmeur leesbaar en kunnen de instructies nadien ook weer aangepast worden. Na elke aanpassing aan de code moet het programma weliswaar opnieuw worden gecompileerd.
Omdat het programmeren in dit soort assembleertaaltoch nog heel wat inzicht vroeg, zijn later de zogenaamde âhogere programmeertalenâ en âscriptingtalenâ ontwikkeld. Ze staan een stuk dichter bij de menselijke taal en zijn hierdoor eenvoudiger te leren. In de loop der jaren (en nog steeds) zijn er honderden verschillende programmeertalen bedacht, vaak met een specifiek doel voor ogen. Elke programmeertaal moet echter op één of andere manier âverwerktâ worden vooraleer het een bruikbaar programma is.
In de programmeertaal Processing tovert de instructie ellipse(20, 20, 20, 10); een cirkel op het scherm. Het middelpunt van de cirkel ligt op pixel 20 van de x-as en pixel 20 van de y-as te rekenen vanuit de linkerbovenhoek van het uiteindelijke programma (dus niet vanuit de rechterbenedenhoek zoals bij een grafiek in bijvoorbeeld MS Excel). De cirkel is 20 pixels breed en 10 pixels hoog... geen echte cirkel dus, maar een ellips.
Voor het bouwen van gebruiksvriendelijke programmaâs met een aangename interface zijn heel visuele programmeeromgevingengebouwd, waarbij je de code niet altijd meer moet kennen. Zo sleep je bij de programmeeromgeving voor de Lego® Mindstorms-robots de code in visuele blokjes bij elkaar op een computerscherm.
De manier waarop computers programmeercode verwerken kan verschillen:
|
Soort verwerking |
Uitleg |
Voorbeelden van software |
|
Compilers |
De meeste programma's worden gecompileerd . Een âcompilerâ is een stuk software dat de codes vertaalt naar nullen en enen. Omdat niet elk besturingssysteem en/of processor op dezelfde manier met nullen en enen omgaat, heb je voor elk benodigd platform een andere compiler nodig. Er bestaan niet voor alle programmeertalen compilers voor alle platformen. Microsoft bouwt voor zijn programmeertalen geen compilers voor pakweg Linux of Mac OS X. Een compiler maakt het werk van de programmeur dus niet op alle vlakken eenvoudiger. Hij moet bezinnen voor hij begint! Gecompileerde software is zeer snel omdat het eindresultaat uit nullen en enen bestaat, de taal van de processor zelf. De code is echter niet meer leesbaar, tenzij de programmeur de code ook publiceert (zoals bij open source het geval is). |
Besturingssystemen zoals Windows, Mac OS X, Linux, MS Office, OpenOffice... |
|
Interpreters |
Soms is een stuk code erg beperkt en kan die worden gecompileerd wanneer de gebruiker het programma opent. De code wordt op dat moment âgeïnterpreteerdâ, simultaan vertaald naar processorinstructies en uitgevoerd. De bekendste interpretertaal is javascript. Een webontwikkelaar kan javascript-code in zijn webpagina's opslaan. Wanneer de browser van een websitebezoeker de pagina opent, wordt de leesbare code door de browser âgeïnterpreteerdâ en (interactief) uitgevoerd. Een browser (Safari, Chrome, Internet Explorer, Opera, Firefox...) beschikt zo goed als altijd over een âjavascript-engineâ die de code in webpagina's kan interpreteren en uitvoeren. Vermits je enkel een âbrowserâ nodig hebt om het programma uit te voeren, werkt javascript doorgaans op alle platformen en systemen waarvoor een browser bestaat. |
Javascript in webpagina's, javascriptbibliotheken zoals jQuery... |
|
bytecode |
Bytecode bevindt zich ergens tussen compilers en interpreters in... Het lijkt een beetje op âinterpreterâsoftware omdat de code niet volledig wordt gecompileerd. Het heeft een extern programma nodig om âgestartâ te kunnen worden. Toch verschillen bytecode-programma's van scriptingtalen zoals javascript omdat de code gedeeltelijk wordt gecompileerd naar een tussenliggende taal, âbytecodeâ. Java is een bekend voorbeeld. Om Java-programma's te starten, heb je een âruntime environmentâ nodig. Zo'n runtime environment moet je eerst op je computersysteem of hardware installeren. Wanneer je het java-programma start, wordt op de achtergrond de âruntime environmentâ (de zogenaamde JRE) gestart. Wanneer de programmeur klaar is met de code, moet hij die exporteren. De code wordt op dat moment vertaald naar âbytecodeâ (geen nullen en enen) die door de âruntime environmentâ wordt uitgevoerd. Het grote voordeel is dat de programmeur slechts één keer code moet schrijven voor alle platformen. Java-programma's werken op alle platformen waarvoor een JRE bestaat, Flash werkt op alle platformen waarvoor een Flashplayer bestaat. Bytecode-programma's zijn wel trager dan gecompileerde programma's. |
Java (jar-bestanden) en de Java Runtime Environment Flash (swf-bestanden) met als âuitvoerprogramma's: de Flashplayer (voor browsers) en Adobe Air (voor desktopomgevingen). |
Vergelijk een programma of applicatie met een auto. De buitenkant van de auto en vooral het dashboard, stuur, pedalen, handrem, versnellingspook vormen de interface, waarmee de chauffeur de auto bestuurt. Onder de motorkap zit de motor die reageert op de acties van de chauffeur. Een programmeertaal zelf is nog geen motor en al zeker geen auto. Met een programmeertaal beschik je wel over een manier en de onderdelen om een auto met motor te bouwen. De programmeur is tegelijk de ingenieur en de monteur die de motor ontwikkelt en bouwt. Niet alle programmeurs zijn daarin even bedreven. Daarom heb je soms een uitzonderlijk goed programma op het vlak van functionaliteit, maar een vreselijke bedieningsinterface. Ook het omgekeerde kan het geval zijn. Uiteraard werken programmeurs niet altijd in hun eentje.
Een programma komt pas tot leven als het reageert op de gebruiker. Een programma zonder gebruikersinteractie lijkt op een auto zonder stuur. Je kan een programma dingen laten doen met of zonder interactie met de gebruiker. Maar natuurlijk wordt het pas echt leuk wanneer de gebruiker merkt dat het programma op zijn acties reageert. Je zou als gebruiker immers al snel denken dat er iets fout loopt als het programma zo maar wat dingen doet (of niet doet).
De analogie met een auto zal het hopelijk allemaal wat duidelijker maken:
In een auto zit een motor en die motor bestaat op zijn beurt uit een hoop kleinere modules. Er zit een carburator, een pomp, cilinders, een radiator, waterpomp enz. in. Uiteraard is zo'n motor alleen niet voldoende. De gebruiker kan de motor en alle onderdelen hiervan interactief besturen. Wanneer hij aan de sleutel draait, start de motor. Als de bestuurder het ontkoppelingspedaal indrukt, de versnellingsbak in de juiste versnelling plaatst en vervolgens het pedaal zachtjes loslaat, komt de auto in beweging. De pedalen, sleutel, versnellingen... zijn interface-elementen die er voor zorgen dat de gebruiker interactief de motor kan aansturen. Het resultaat is dat de auto in beweging komt, de ruitenwissers beginnen bewegen, de lichten kunnen worden aangezet enz. Tussen die interface-elementen en de onderdelen van de motor liggen verbindingen, kabels, slangen enz. die ervoor zorgen dat alles netjes wordt aangestuurd.
|
Programma |
auto |
|
Bedieningsinterface |
dashboard, pedalen, hendels... |
|
Methodes |
rijden, stoppen... |
|
Functies |
de motor die zorgt voor de aandrijving, de ruitenwissers (regenwater wegwissen), de waterpomp, de remmen... |
Methodes horen dus bij het object âautoâ. Functies staan daar los van. Meerdere objecten kunnen dezelfde functies delen. Het verschil zorgt vaak voor verwarring en je kan er inderdaad uren over discussiëren. Een methode hoort dus bij een âobjectâ. Een functie staat los van het object.
We testen het nu zelf eens uit in de programmeertaal Processing. Eerst moet je Processing ( www.processing.org) downloaden en installeren. Kies de juiste versie. Tijdens de les demonstreren we hoe je de IDE installeert en start.
Processing maakt het makkelijker door enkel te spreken over functies en niet het verschil te maken tussen methodes en functies. In de setup()-functie bepaal je hoofdzakelijk het âuitzichtâ van je programma zoals de breedte, de hoogte, de achtergrondkleur...
De draw()-functie is een soort container waarin wordt bepaald wat het programma moet tonen aan de gebruiker (bijvoorbeeld het webcambeeld, een tekening, een foto...).
void setup() { //algemene instellingen van het programma } void draw() { //wat moet er gebeuren? }
Het onderstaande Processing-voorbeeld tekent een witte cirkel van 300 pixels breed en hoog in het midden van een zwart "canvas" van 400 pixels breed en hoog.
void setup(){
size(400, 400);
background(0);
stroke(255);
ellipse(200, 200, 300, 300);
} Zowel size(), background(), stroke() als ellipse() zijn ingebouwde functies in Processing. Processing weet meteen wat hij moet doen als je zo'n functie oproept. Je kan ook parameters toevoegen. Denk nog eens even terug aan de auto. De knop zet de ruitenwissers in beweging, maar door aan het hendeltje te draaien, kan je de ruitenwissers sneller of trager of met een interval laten bewegen. Je kan dus aan een dezelfde âmotorâ meerdere parameters doorgeven. Zo gaat het ook in Processing. Als je geen parameters doorgeeft aan een bepaalde motor... excuseer, functie... dan valt Processing terug op een standaardinstelling. Uiteraard moet je goed weten hoeveel parameters elke functie kan ontvangen. Het heeft immers geen zin (en het zou enkel tot foutmeldingen leiden) als je zo maar wat parameters begint in te voeren. De parameters plaats je tussen de haakjes.
Bijvoorbeeld:
size(400, 400);De twee getallen geven aan hoe breed en hoe hoog (in pixels uitgedrukt) het uiteindelijke programma moet weergegeven worden.
De regel
ellipse(200, 200, 300, 300); vertelt Processing dat hij een ellips van 300 pixels bij 300 pixels moet tekenen met zijn middelpunt op pixel x=200 en y=200. Bij een programma van 400 bij 400 pixels, staat de ellips precies in het midden. Je merkt dus ook dat de volgorde van de parameters wel degelijk van belang is in een Processing-sketch.
Denk aan een auto, een Mercedes bijvoorbeeld. Daarbinnen heb je verschillende soorten die steevast een klasse worden genoemd, bijvoorbeeld de Mercedes C-klasse. Mensen herkennen andere mensen, dieren, koeien, weides, huizen, straten, auto's enz. In een programmeertaal zouden we dit geen âobjectâ noemen, maar een klasse. Ook voor mensen zijn dit niet meteen zelfstandige objecten, we noemen dit âsoortnamenâ. Auto's zijn dus een klasse, maar jouw eigen auto beschouw je wel als een âobjectâ. Het verschil tussen objecten en klassen zit in de meeste moderne programmeertalen. Wat je er mee doet?
Hieronder vind je een voorbeeld in javascript, de scriptingtaal (dus niet echt een programmeertaal: zie 2.2.2), die vooral bekend en populair is als de interactieve taal achter webpagina's. We bouwen een functie met de naam KindMaken, die natuurlijk niet echt doet wat ze belooft, maar we bouwen er wel een âdenkbeeldig virtueelâ kind mee. Niet dat er plots een kind op je computerscherm verschijnt. Elk kind heeft een aantal âparametersâ, in het onderstaande geval een voornaam, familienaam, leeftijd, oogkleur, geslacht. Je kan het nog uitbreiden. Misschien raar om ook de leeftijd als parameter door te geven, want een pasgeboren kind is nog maar een paar ogenblikken oud. Denk echter naar analogie aan een game, die je moet bevolken met virtuele mensen (objecten). In zo'n geval is het wel belangrijk om de leeftijd te kunnen instellen.
Om het enigszins te verduidelijken staan de âzelfbedachteâ woorden in het Nederlands, de ingebouwde woorden in het Engels. Met ingebouwde woorden bedoelen we in dit geval gereserveerde woorden die je niet zelf voor andere zaken kan gebruiken. Je kan dus niet de functieaanroep âalertâ vervangen door bijvoorbeeld âgilâ. Uiteraard verplicht niemand jou om Nederlands te gebruiken. De meeste programmeurs en ontwikkelaars schrijven alles in het Engels.
var KindMaken = function (Voornaam, Familienaam, Leeftijd, Oogkleur, Geslacht) {
this.voornaam = Voornaam;
this.familienaam = Familienaam;
this.leeftijd = Leeftijd;
this.oogkleur = Oogkleur;
this.geslacht= Geslacht;
}
var papa= new KindMaken("Jan", "Peeters", "50", "blauw", "m");
var mama= new KindMaken("An", "Filips", "48", "groen", "v");
alert(papa.voornaam + " en " + mama.voornaam + " gaan trouwen.");
De afkorting var staat voor âvariabele waarde. In dit geval zijn mama en papa twee variabelen en de functie (motor) kindmaken is dat ook, want je hebt die functie ook zelf gedefinieerd. Als je het bovenstaande stuk code kopieert en in een teksteditor (vb. Kladblok, zeker niet in een tekstverwerker) plakt en je bewaart het vervolgens als test.html. Dan kan je het eindresultaat bekijken in een webbrowser.
Probeer de code ook eens aan te passen. Je computer zal niet crashen als je een fout maakt. Al spelend leer je. Zo gaat het ook tijdens het programmeren of scripten.
Tja, misschien toch wel een beetje moeilijk voor een beginner. Programmeertalen zijn niet eenvoudig om te leren. Meer dan in menselijke taal zijn ze heel strikt gebonden aan regeltjes. Een fout stukje spelling of spraakkunst en ⦠oeps, het werkt niet zoals je wil of zelfs helemaal niet. Je bent trouwens niet de enige die programmeren moeilijk vindt. Jef Raskin die in een grijs verleden de interface van de Apple Macintosh-computer ontwierp, schrijft:
âThere is no question that modern systems are becoming increasingly complex and that programming tools need to accommodate this increasing complexity. Simple things have been made unnecessarily difficult, and we have failed to provide sufficient and sufficiently well-designed software tools needed to ease the difficulties of working in today's computer environmentâ. 1
Maar als je toch echt even wil proberen, kan het ook met mijn hobbyproject SIRK dat je vindt op
www.ardeco.be/sirk. De bedoeling van SIRK was om het programmeren een stapje dichter bij menselijke taal te brengen. Bovendien zijn de Engelse gereserveerde woorden hier vervangen door Nederlandstalige woorden met de bedoeling de indruk te wekken dat je kan programmeren in je eigen taal.
Stel dat je het getal 5 op je computerscherm wil weergeven (niet meteen hoogstaande kunst. Je zou denken: âIk open MS Word en tik gewoon 5.â), dan is dit voor een programmeertaal een variabel gegeven. In plaats van de afkorting âvarâ gebruiken we binnen SIRK, gewoon zoals in mensentaal, de bepaalde lidwoorden âdeâ en âhetâ. Onze bedoeling is nu âhet getal 5 afdrukken op het scherm.âWe maken met SIRK dus eerst een getal aan met de waarde 5. We laten het onthouden door de computer (bewaar, store...). Zo kunnen we het later op elk gewenst moment op ons scherm afdrukken (GEBRUIKEN of @ en OP_HET_SCHERM of print).
het getal
5 getal bewaar
getal GEBRUIKEN OP_HET_SCHERM We zouden het ook op de volgende manier kunnen schrijven:
var number
5 number store
number @ print Op www.ardeco.be/sirkvind je nog een boel leukere voorbeelden. Probeer bijvoorbeeld de spelletjes eens uit of de tekenvoorbeelden.
In het echte leven hangt veel wat we doen af van de omstandigheden. Als het regent, open je een paraplu bijvoorbeeld. Doe je dit wanneer de zon schijnt, dan word je raar bekeken.
In de meest eenvoudige vorm (0 of 1) kent een eenvoudig programma twee toestanden. Naar analogie gebruiken we de volgende situatie:
Om zulke condities te testen, gebruiken heel wat programmeertalen een if-else-conditie. Soms werkt dit zelfs letterlijk voor âregenâ. Bij een aantal auto's werken de ruitenwissers bijvoorbeeld als een sensor âregenâ op de ruit âvoeltâ.
In âpseudocodeâ zouden we dit zo kunnen uittekenen:
var regen= testRegensensor();
if(regen==1){
Ruitenwissers(1);
}else{
Ruitenwissers(0);
} Naast eenvoudige if/else-condities kan je ook gebruik maken van (beperkte) herhalingen (loop). Zoals bijvoorbeeld "beweeg 10 keer van links naar rechts op het scherm" of "teken 5 vierkanten met een willekeurige kleur op het scherm".
de xpositie
de ypositie
20 xpositie bewaar
20 ypositie bewaar
de breedte
20 breedte bewaar
de hoogte
20 hoogte bewaar
[
xpositie gebruiken 40 + xpositie bewaar
ypositie gebruiken 40 + ypositie bewaar
kleur xpositie gebruiken ypositie gebruiken hoogte gebruiken breedte gebruiken vierkant
] 5 keer Denk maar eens goed na waarvoor â40+â dient in de bovenstaande code.
1 RASKIN, J., The Humane Interface, New Directions for Designing Interactive Systems, Boston, 2010, 192-193.
Ongetwijfeld heb je het woord al eens gehoord: een algoritme. Het heeft niks met ritmische muziek te maken alhoewel Shazam wel algoritmes gebruikt voor patroonherkenning in muziek. Google gebrukt het PageRank-zoekalgoritme en wanneer je naar een MP3-muziekbestand luistert dan is dit eerst met een compressie-algoritme tot een relatief klein bestand herleid vooraleer het op je mediaspeler is beland. Algoritmes spelen een cruciale rol in de verwerking van big data. Algoritmes zijn in de digitale wereld alomtegenwoordig, maar wat zijn het eigenlijk? Een nette verklaring van het begrip vinden we op Wikipedia:
â(een algoritme) is een eindige reeks instructiesdie vanuit een gegeven begintoestandnaar een beoogd doelleiden. Algoritmen staan in beginsel los van computerprogramma's, al worden voor de uitvoering van algoritmen vaak computers gebruikt. Het doel van een algoritme kan van alles zijn met een duidelijk resultaat. De instructies kunnen in het algemeen omgaan met eventualiteiten die bij het uitvoeren kunnen optreden. Algoritmen hebben in het algemeen stappen die zich herhalen (iteratie) of die beslissingen (logica of vergelijkingen) vereisen om de taak te voltooien.â 1
In wezen gaat het om een stappenplan waarvan je weet dat je tot een bepaald resultaat zal leiden. Het gaat dus verder dan lukraak proberen een bepaald resultaat te bereiken. Je weet heel goed welke stappen je na elkaar moet zetten om tot een resultaat te komen. Op school leer je bijvoorbeeld woordjes alfabetisch rangschikken. Dat doe je in eerste instantie door naar de eerste letter te kijken. Bevatten veel woorden dezelfde beginletters, dan rangschik je die woorden door naar de tweede letter en vervolgens naar de volgende letters te kijken. Rangschikking vereist dus een algoritme, een strikt stappenplan om tot het beoogde eindresultaat (een alfabetische volgorde) te bereiken. Algoritmes blijven dus niet beperkt tot computerwetenschappen, maar je vindt ze al een âeeuwigheidâ terug in de wiskunde. In het tweede millennium voor Chr. gebruikten de Babyloniërs algoritmes voor het berekenen van machten en vierkantswortels.
Het alfabetisch rangschikken van woorden en het ordenen volgens grootte van getallen lijkt voor ons erg makkelijk. Maar het vraagt wel een stappenplan in ons hoofd, ook al doe je het na een tijdje zonder na te denken. Hoe beter het algoritme, hoe sneller de procedure. Dit soort algoritmes wordt reeds van in de beginjaren van de computer gebruikt in de computerwetenschappen. John von Neumann bedacht het âsort mergeâ-algoritme in de 1945. Het sorteert gegevens door het splitsen, ordenen en weer samenvoegen (merge) van data. Tony Hoare bedacht in 1959 het Quicksort-algoritme, dat zoals de naam al doet vermoeden, sneller werkt dan âsort mergeâ. 2 In 1964 bedacht J.W.J. Williams het âheapsortâ-sorteeralgoritme. 3
Zonder dit soort âsorteeralgoritmesâ zouden heel wat moderne computertechnieken zoals data mining, AI, linkanalyse... ondenkbaar zijn.
De het Fourier-transformatie-algoritme en de Fast Fourier-transformatie of het FFT-algoritme liggen aan de basis van heel wat compressie-algoritmen zoals JPG en MP3. Een Fourier-tansformatie zet een geluidssignaal of lichtintensiteit om in een golffunctie. Het internet, WiFi, een smartphone, computer, router, communicatiesatellieten enz., zo wat alle toestellen waarin een soort computer aanwezig is, gebruikt het deze algoritmen. Het meet analoge signalen doorheen de tijd en tekent die uit als een golf op basis van de gemeten frequenties. Door signalen op te zetten in (golf)functies, kan de intensiteit van de golf eveneens getransformeerd (vervormd) worden. Het FFT-algoritme wordt bijvoorbeed gebruikt bij afbeeldingsfilters waarbij men de intensiteit van kleuren of belichting 'transformeert'. Bij compressie worden lage intensiteitsverschillen weggegooid waardoor de bestandsgrootte erg verkleind.
"Fourier-transformaties worden gebruikt bij het omzetten van analoge signalen in digitale data en worden onder meer toegepast bij signaalverwerking, maar spelen ook een rol bij de compressie van beelden. Een complex signaal wordt met fft gereduceerd tot een aantal eenvoudig digitaal te representeren componenten. Daarvoor wordt een analoog sample opgedeeld in kleine stukjes, waarna de stukjes worden geanalyseerd en geconverteerd naar een digitaal signaal." 4
Compressie-algoritmes spelen een bijzonder belangrijke rol. Ze zorgen ervoor dat data kleiner worden, maar vaak gaat dit gepaard met kwaliteitsverlies. De algoritmes maken een afweging tussen kwaliteit en kwantiteit. In 3.2.5 (Compressie) leerde je al meer over de belangrijkste compressie-algoritmes voor afbeelding. In deel 6.2.7 (Codecs en containers) lees je meer over compressie van film.
Het klinkt in de eerste plaats al indrukwekkend, het â Proportional Integral Derivative Algorithmâ maar wat het doet is al even tot de verbeelding sprekend. Een PID-controllerberekent constant foutwaardes als het verschil tussen de gemeten signaalwaarde en het gewenste resultaat en werkt vervolgens de fout weg. PID-controllers worden in de industrie toegepast, maar ook in meer populaire toepassingen. Zangers zingen in een opnamestudio niet altijd netjes op de toon, doorheen een zangpartij zitten ze vaak wel eens net boven of net onder de juiste toon. Dat wil nog niet zeggen dat ze ronduit vals zingen, maar ze zitten zelden loepzuiver op de toon. Autotuningzorgt ervoor dat al die foutjes verdwijnen in de uiteindelijke gemixte opname. Het lied âBelieveâ van de zangeres Cher zou de eerste popsong zijn die van autotuning gebruik heeft gemaakt. Je merkt meteen het verschil als je naar opnames uit de jaren 1960 of 1970 luistert en die vergelijkt met opnames uit de digitale periode vanaf 1984. Beluister bijvoorbeeld eens het album âCommuniqueâ van Dire Straits en het loepzuivere digitale geluid van âBrothers in Armsâ van diezelfde groep. Niet dat we Dire Straits en Mark Knopfler âverdenkenâ van autotuning, maar de digitaliseringsalgoritmes hebben een blijvende âstempelâ gedrukt op alle opnames vanaf de komst van de CD.
Het Dijkstra-algoritme is vooral bekend als het kortste pad-algoritme. Het beschrijft de kortste afstand tussen twee punten.
âHet algoritme van Dijkstra wordt gebruikt door verschillende internetprotocollen, voor het vinden van de kortste route tussen computers of routers. Het algoritme van Dijkstra geeft gegarandeerd het kortste pad, als er überhaupt een pad tussen A en B bestaat, maar kan hier wel lang over doen. De snelheid van het algoritme is afhankelijk van de manier waarop de punten en lijnen opgeslagen zijn in het geheugen van de computer.â 5
Welke links bovenaan verschijnen in Googleszoekresultaten wordt bepaald door het PageRank-algoritme. Facebooktoont bij iedere gebruiker een andere newsfeedgebaseerd op de âvriendenâ met wie je het meest contact hebt (op Facebook dan toch), berichten die de meeste âlikesâ hebben gekregen enz. Wat je te zien krijgt, hangt dus af van een heleboel factoren en wordt bepaald door een linkanalyse-algoritme. Uiteraard verschillen de algoritmen maar de basis voor linkanalyse werd gelegd in 1976 door Gabriel Pinski en Francis Narin.
âWho uses this algorithm? Google in its Page Rank, Facebook when it shows you your news feed (this is the reason why Facebook news feed is not an algorithm but the result of one), Google+ and Facebook friend suggestion, LinkedIn suggestions for jobs and contacts, Netflix and Hulu for movies, YouTube for videos, etc. Each one has a different objective and different parameters, but the math behind each remains the same.
Finally, Iâd like to say that even thought it seems like Google was the first company to work with this type of algorithms, in 1996 (two years before Google) a little search engine called âRankDexâ , founded by Robin Li, was already using this idea for page ranking. Finally Massimo Marchiori, the founder of âHyperSearchâ, used an algorithm of page rank based on the relations between single pages. (The two founders are mentioned in the patents of Google).â 6
Wanneer je op twee verschillende computers van twee verschillende âmensenâ dezelfde zoekterm invoert in Google krijg je vaak andere zoekresultaten. Googles PageRank baseert de zoekresultaten immers ook op uw zoekgeschiedenis en toont op basis daarvan ook andere advertenties via het Google Adwords-algoritme. Wanneer je een zoekterm begint in te voeren toont Google Suggest reeds een reeks mogelijkheden waaruit je een optie kan selecteren. Ook iTunes, Amazon en Netflix tonen op basis van uw zoekgeschiedenis en aankopen andere producten die u wellicht interesseren. Eli Pariser noemt dit âinformatie determinismeâ. De gebruiker zit in een soort van âfilter bubbelâ waar hij zelf voor een deel de controle over verliest. Je kan dus niet zelf meer kiezen wat je te zien krijgt, algoritmes bepalen dit voor u. Vraag is of je, puur uit marketingoogpunt, op die manier geen potentiële kopers van bepaalde producten mist.
Online dating is eveneens een voorbeeld van een veelgebruikte dienst die op basis van suggestie-algoritmes functioneert. Het matching-algoritme van OKCupid (een online datingdienst) werd afgeleverd door de Harvardwiskundige Christian Rudder. Het maakt een âruweâ match op basis van gemeenschappelijke interesses. Vraag is natuurlijk of iemand met gelijkaardige interesses sowieso de beste partner is. Daarom berekent het algoritme eveneens hoe belangrijk elke vraag is voor de andere partij.
Steeds meer computergebruikers plakken hun webcam af met een stukje plakband, iedereen weet dat je privacy wel eens kan geschonden worden door al je internetavonturen. Toch rekenen we wel op veiligheid als we online bankieren of wanneer we een reis boeken via Booking.com en onze creditcardgegevens invullen in een App Store of in PayPal. Zonder dit gevoel van zekerheid en veiligheid zou je wel gek moeten zijn om je bankkaartgegevens ergens achter te laten. Het RSA-algoritme(ooit geschreven door de firma RSA) en het Secure hash-algoritmezorgen ervoor dat onze data veilig en versleuteld worden uitgewisseld tussen onze thuiscomputer en de servers van banken en online winkels. Een ander belangrijk algoritme in de wereld van de cryptografie is het Integer factorization- algoritme.
In 1948 schreef George Orwell het boek â1984â waarin hij scherpe kritiek leverde aan het adres van de USSR. Hij schetste
âeen onmenselijke dictatoriale eenpartijstaat die in alle opzichten volledig beheerst wordt door de Partij. De alom aanwezige leider van de Partij en het land wordt Big Brother genoemd. Iedere bewoner van het land wordt continu in de gaten gehouden via camera'sdie zelfs in de huizen zijn geïnstalleerd. Dit gebeurt onder de slogan â Big Brother is watching youâ (âGrote Broer houdt je in de gatenâ).â 7 Ondertussen leven wij in het westen niet in dictatoriale eenpartijstaten, maar Big Brother lijkt heel reëel. Ieder van ons wordt in de gaten gehouden, zij het niet door mensen, maar door algoritmes. Vanuit de USA houdt het National Security Agency (NSA) en zijn internationale partners (Five Eyes: US, Australië, Canada, Nieuw-Zeeland, Groot-Brittannië) wereldwijd miljoenen mensen in de gaten. Ze monitoren telefoongesprekken, SMS-berichten, e-mailberichten, webcambeelden, GPS-locaties enz. De hoeveelheid verzamelde informatie is veel te groot om te laten analyseren en interpreteren door mensen. De analyse gebeurt automatisch met behulp van krachtige algoritmes.
Sommige algoritmes zoals
IBM's CRUSH, gaan nog een stukje verder. CRUSH of â Criminal Reduction Utilizing Statistical Historyâ zorgt voor
âpredictive analysisâen is in hoofdzaak bedoeld om misdaden te voorkomen. De politiediensten van Memphis konden de misdaadcijfers met 30% laten teruglopen dankzij CRUSH. Het aantal gewelddadige misdrijven liep sinds 2006 terug met 15%. Op basis van statistische gegevens, data-aggregatie en algoritmes, toont de software criminele hot spots op een kaart. Politie-eenheden kunnen op de manier pro-actief ingeschakeld worden en bij wijze van spreken aankomen voor een misdaad plaatsvindt. In de toekomst zullen criminelen heel snel opgespoord kunnen worden dankzij internetactiviteit, GPS en biosignaturen, verdacht gedrag...
âIn the future, these systems will largely take over the work of analysts. Criminals will be tracked by sophisticated algorithms that monitor internet activity, GPS, personal digital assistants, biosignatures, and all communications in real time. Unmanned aerial vehicles will increasingly be used to track potential offenders to predict intent through their body movements and other visual clues.â 8
De film Minority Report van Steven Spielberg uit 2002 toont al een glimp van waartoe dit in de toekomst kan leiden.
Algoritmes voor predictieve analyse zijn reeds lang in gebruik in de beurswereld. De analyse van razendsnel voorbijvliegende transacties gebeurt met behulp van slimme algoritmes. Soms kloppen de predicties niet, zoals bij de âFlash Crashâ van 2010.
Als je dobbelt met een dobbelsteen of de lotto speelt, speel je letterlijk met âtoevalâ. Een computer kan eveneens een lukraak getal genereren. In de meeste programmeertalen kan je de functie om een random getal te genereren eenvoudig oproepen. Random-getalgenerators zijn belangrijk in beveiliging en cryptografie, games, AI enz.
Rekenen kost veel te veel tijd, tijd die je aan aangenamer bezigheden kan besteden. Dat merkte men ook bij de Amerikaanse volkstelling van 1880: 500 ambtenaren hadden 7 jaar lang de handen vol om alle gegevens te verwerken. Herman Hollerith (1860â1929) was ambtenaar bij het landelijk bureau voor statistiek. Hij zag in dat je met de automatische verwerking van ponskaarten veel sneller zou kunnen werken. In 1890 introduceerde hij zijn Hollerithmachine. Gegevens zoals geslacht, leeftijd en nationaliteit van elke inwoner werden op ponskaarten opgeslagen. De machine telde en sorteerde! Met behulp van 42 machines slaagden hetzelfde aantal ambtenaren erin om de klus op een maand te klaren. In 1939 startte IBM met de ontwikkeling van een rekenmachine ,die vijf jaar later onder de naam Automatic Sequence Calculator (Mark I) het levenslicht zou zien. Het toestel werd samen met Harvard University ontwikkeld en was maar eventjes 15 meter lang en 2,5 meter hoog. De Duitser Konrad Zuse (1910â 1995) kende het werk van Babbage niet toen hij van start ging met zijn eigen rekenmachine, die volgens het binaire talstelsel van Leibnizwerkte. Zijn eerste model (Z1) gebruikte nog mechanische schakelingen, maar beschikte wel al over een geheugen. Stilaan begon hij te experimenteren met elektromechanische verbindingen, wat resulteerde in de Z3, de eerste computer waarbij zowel het geheugen als de processor elektromagnetisch functioneerde. Het binaire talstelsel volstond niet voor de verwerking van gegevens. Een elektronische schakeling levert een 1 wanneer er een stroomstoot doorgaat en een 0 wanneer dit niet het geval is. Bij computers is het van belang meerdere schakelingen te kunnen combineren. Soms mag een stroomstoot pas worden doorgegeven wanneer meerdere schakelaars op 1 staan, in andere gevallen volstaat het dat een van beide schakelaars een stroomstoot doorgeeft. De benodigde wiskunde werd geleverd door het werk van de Schotse wiskundige George Boole (1815â1864). Hij schreef in 1847 een boek waarin hij het binaire talstelsel combineerde met de logische verbindingen and, or, not. Voor de rekeneenheden van computers leverde dit de gepaste oplossing om meerdere verbindingen te kunnen combineren. De Brit Alan Turing (1912â1954) ontwikkelde een theoretisch model voor een âcomputerâ onder de naam turingmachine. Deze Logical Computing Machine bleef bij een gedachte-experiment. Turing werd vooral beroemd omdat hij tijdens de Tweede Wereldoorlog de geheime Enigma- code kon kraken. Hiervoor ontwierp hij samen met Tommy Flowers (1905â 1998) de Colossus-computers, die voldoende rekencapaciteit hadden om de Duitse codes te kraken. In 1952 werd hij gearresteerd op verdenking van homoseksualiteit en tot een experimentele chemische castratie veroordeeld. Op 7 juni 1954 werd hij levenloos teruggevonden. Hij zou zelfmoord hebben gepleegd door te bijten in een met cyanide vergiftigde appel. Volgens de legende staat deze appel symbool voor het logo van de Amerikaanse computerfirma Apple. Over Turings dood deden al snel wilde verhalen de ronde. Volgens eÌeÌn complottheorie was Turing om het leven gebracht door de Britse geheime dienst omdat hij door zijn werk tijdens de oorlog op de hoogte was van veel staatsgeheimen. De Hongaar John von Neumann (1903â1957) tekende kort na de oorlog de architectuur uit voor computers. Een computer moest beschikken over een invoereenheid, een processor voor de verwerking van de invoer, een uitvoereenheid en een geheugen voor de opslag van data. De gegevens en de programmaâs moesten binair (op basis van het talstelsel van Leibniz) worden opgeslagen. In 1945 bouwde hij zijn eerste edvac-computer, die echter duidelijk was afgekeken van een vroeger model van de Amerikaan John Atanasoff (1903â1995). Omdat het patent niet goed was geregeld, konden anderen met zijn ideeeÌn aan de haal gaan. Hierdoor stond zijn toestel ook ongewild model voor de eniac (Electronic Numerical Integrator and Calculator) van John Mauchly (1907â1980) en John Eckert (1919â 1995). Zij presenteerden vol trots hun toestel als de eerste elektronische digitale computer. Dankzij de elektronenbuizen was de rekencapaciteit enorm vergroot, maar de buizen maakten het toestel ook erg kwetsbaar. Een elektronenbuis of vacuuÌmbuis kan elektrische signalen versterken of nullen en enen doorgeven. De Mark I maakte voor zijn schakelingen gebruik van elektrische relais, die toelaten een grote stroom aan of uit te zetten met een kleine stroom. Hierdoor waren ze erg geschikt voor gebruik in computers. Maar het resulteerde wel in een zeer groot toestel met meer dan 700.000 onderdelen en 80 kilometer elektrische draden. In 1879 had Thomas Edison de elektrische gloeilamp uitgevonden. Hij leidde de stroom door een stukje verkoold katoen, waardoor het begon te gloeien en licht afgaf. Om te voorkomen dat de draad volledig verbrandde onder invloed van de lucht, plaatste hij het in een luchtledige glazen bol. Veel onderzoekers begonnen te experimenteren met de mogelijkheden van de lamp en dit leidde tot onder meer de radiobuis en de elektronenbuis, die ook perfect bruikbaar bleek als schakelaar in computers. Een relais bevatte veel bewegende onderdelen en zorgde voor relatief lange schakeltijden. Omdat een kleine wijziging in de elektronen een grote verandering kan veroorzaken in de doorgelaten stroom, was een elektronenbuis perfect bruikbaar als versterker. De ENIAC bevatte 18.000 buizen en was in alle opzichten sneller dan de Mark I. Toch had een elektronenbuis ook heel wat nadelen. Ze was niet alleen duur en erg breekbaar, maar slorpte ook massaâs energie op. De komst van de transistor in 1948 loste alle problemen op. De eerste patenten op een transistor dateren al uit 1928, maar lijken nooit in de praktijk te zijn omgezet. De transistor van William Bradford Shockley (1910â1989), John Bardeen (1908â1991), en Walter House Brattain (1902â1987) zou echter al snel de elektronenbuis verdringen. De transistor was veel kleiner, goedkoper en betrouwbaarder dan de elektronenbuis. Bovendien verbruikte hij minder elektriciteit en produceerde minder warmte. Net zoals een elektronenbuis is de transistor (transferÂresistor) een versterker, maar kan hij ook nullen en enen doorgeven. Jack Kilby (1923â2005) van Texas Instruments voegde in 1958 een tiental transistors samen in eÌeÌn geiÌntegreerde schakeling. Tegelijkertijd kwam Robert Noyce (1927â1990) van Fairchild Semiconductor met een soortgelijk circuit op de proppen. Het kreeg al snel de naam âicâ (integrated circuit), maar is bij het grote publiek vooral bekend geworden onder de naam âchipâ.
Sindsdien is de chip uitgegroeid tot het basisonderdeel van elektronische apparaten zoals de computer.Het aantal transistors op een chip zou steeds maar toenemen. Bovendien werden de transistors alsmaar kleiner, waardoor een chip in onze tijd al snel miljoenen tot zelfs meer dan een miljard transistors telt. Het groeiende aantal transistors heeft ertoe geleid dat ook de rekenkracht van computers enorm is toegenomen. Volgens de befaamde wet van Moore(Gordon Earle Moore, 1929) zou de benodigde oppervlakte voor eÌeÌn transistor om de twee jaar halveren. Elke twee jaar kwam er dus een nieuwe âchiptechnologiegeneratieâ met transistors die slechts half zo groot zijn als die van de vorige generatie. Uiteraard kan dit niet oneindig doorgaan. Men kan immers niet kleiner gaan dan de grootte van een atoom.Lange tijd daalde ook de prijs van nieuwe transistors, maar ook daaraan komt stilaan een einde. De initieÌle investeringen voor het ontwerp van een chip zijn door de miniaturisatie zo hoog geworden dat de prijzen enkel nog zakken bij immense productievolumes. Van grote invloed op de miniaturisatieis de consumentenelektronica met steeds lagere prijzen. De schaling leidt er ook toe dat we elektronische toestellen steeds sneller als voorbijgestreefd beschouwen, wat de wegwerpmaatschappij in de hand werkt.
1âAlgoritmeâ, ( https://nl.wikipedia.org/wiki/Algoritme), Geraadpleegd op 19 oktober 2015.
2âQuick sortâ, ( https://en.wikipedia.org/wiki/Quicksort), Geraadpleegd op 19 oktober 2015.
3âHeapsortâ, ( https://en.wikipedia.org/wiki/Heapsort), Geraadpleegd op 19 oktober 2015.
4DE MOOR, W., "Sneller algoritme voor Fourier-transformaties ontwikkeld", (http://tweakers.net/nieuws/79444/sneller-algoritme-voor-fourier-transformaties-ontwikkeld.html), 2012, Geraadpleegd op 19 oktober 2015.
5GUNNINK, M., "Padvinder vindt pad: over Pathfinding", (http://kninnug.nl/padvinder/index.html), Geraadpleegd op 20 oktober 2015.
6OTERO, M., "The real 10 algorithms that dominate our world" (https://medium.com/@_marcos_otero/the-real-10-algorithms-that-dominate-our-world-e95fa9f16c04), 2014, Geraadpleegd op 19 oktober 2015.
7âBig Brother (George Orwell)â, ( https://nl.wikipedia.org/wiki/Big_Brother_(George_Orwell)). Geraadpleegd op 20 oktober 2015.
8DVORSKY, G., "The 10 algorithms that dominate our world", (http://io9.com/the-10-algorithms-that-dominate-our-world-1580110464), 2014, Geraadpleegd op 20 oktober 2015.
Toen ik in 1991-1992 mijn thesis intikte, schreef ik eerst nog alles uit met de hand, met balpen op een massa velletjes papier. Een vriend beschikte toen reeds over een prille Applecomputer, tikte mijn teksten in (hij moet wel vaak hebben gegromd toen hij twee maanden lang stapels handgeschreven en moeilijke leesbare teksten onder de neus geduwd kreeg) en drukte de 200 A4-pagina's van mijn eindwerk af. Foto's moest ik er echter nog manueel aan toevoegen: foto kopieÌren op een witzwartkopieermachine, uitknippen, plakken en het geheel nogmaals kopieÌren. Niet veel anders gebeurde het bij de kranten. The times they are a-changin'.
Het grote voordeel van digitalisering is dat je de data ook achteraf kan bewerken. We bewaren al onze bestanden en gooien steeds minder weg, ook al is het dan virtueel. Seagate, de producent van harde schijven, verkocht in 2011 een totale capaciteit van 330 exabyte aan harde schijfruimte. Behoorlijk wat. Het world wide web zou in 2013 meer dan 3 zettabyte33 aan data hebben bevat en dat is sindsdien exponentieel toegenomen. In dit deel bekijken we hoe die overvloed aan data wordt bewaard. Hoe bewaart een digitaal systeem bestanden?
Naast de opdrachten die je tijdens de les moet maken, maakt iedereen individueel een animatie(film). Hoe dit in zijn werk gaat, leer je tijdens de lessen. Hieronder vind je alvast de uitgeschreven opdracht en een storyboard dat je kan gebruiken als leidraad:
Uitleg volgt nog tijdens de les!
Een digitaal systeem staat zelden alleen. Net zoals ieder van ons rond zich een sociaal netwerk van vrienden, kennissen, collega's, bekenden verzamelt, zo werkt een computer zelden in zijn âeentjeâ.
Computers kunnen in een netwerk samenwerken en uitgroeien tot eÌeÌn supercomputer door hun rekenkracht te combineren zoals bij het renderen van een 3D-film gebeurt. Ze kunnen ook hun opslagruimte combineren zoals bij big data of zoekmachines het geval is.
Het meest bekende netwerk is het internet, waarvan het web (http), e- mail (mailto), chat... de bekendste toepassingen vormen. Het internet of things moet in de nabije toekomst alle digitale apparaten via het internet informatie laten uitwisselen.
In dit deel leer je niet meteen hoe je netwerken opstelt, maar leer je iets dieper en vooral grondiger graven in het internet. Je leert sneller en beter informatie verzamelen en je leert hoe zoekmachines functioneren.
La Belgique industrielle: compte rendu de l'exposition des produits de l ... In dit boek uit 1836 lijsten de auteurs de tentoongestelde producten op van een tentoonstelling van industriële producten in 1835. (compte rendu de l'exposition des produits de l'industrie en 1835)
Link naar het boek online.
Het boek bevat een hoofdstuk over machines, maar geen enkele vermelding over het weefgetouw van Jacquard.
FAURE, F.,DUMOULIN, E.,VALÃRIUS, B.,
Jamar. undefined
Jaargang 1827-1828;
Vermelding van "Journal principalement destiné à répandre les connaissance utiles à l'industrie générale". "le gout de la mécanique industrielle, par la publication de son beau traité sur cette science." "l'art de construire les machines et de la mécanique purement rationelle" (p.388) NOG OP TE ZOEKEN
Diverse vermeldingen over de introductie van "le métier Jacquart(d)" in België.
PDF-bestand met vermeldingen:
Geschiedenis van de techniek in België. Nog niet beschikbaar voor de 19e eeuw. ( HALLEUX)
De rol van Jacquard in de techniek en automatisering ( MERCKX, K.,)
Geschiedenis van de wetenschap in België
De eerste die een soortgelijk programmeerbaar systeem inzette voor industrieel gebruik was de Fransman Joseph Marie Jacquard (1752â1834). Hij ontwierp in 1801 een weefgetouw dat werd aangestuurd door ponskaarten. Hij baseerde zich voor zijn werk op de eerdere uitvindingen van onder anderen Basile Bouchon, Jacques Vaucanson (1709-1782) en Jean Falcon. Basile Bouchon, zoon van een orgelbouwer, bedacht al in 1725 een manier om een weefgetouw aan te sturen met
een geperforeerde rol papier. Het ponskaartsysteem zien we in de 19e eeuw ook opduiken in muziekdozen en pianolaâs. Ponskaarten werkten op een vergelijkbare manier als pin- of kamsystemen. In het geval van muziekdozen kon door de gaatjes lucht van een blaasbalg ontsnappen of er konden pinnetjes door schieten die instructies gaven aan de rest van het mechanisme. Bij Jacquard sprongen pinnen op door de openingen in de ponskaarten en lieten het weefgetouw een bepaald patroon weven. Het grootste voordeel van een ponssysteem was dat je veel meer instructies achter elkaar kon laten uitvoeren door de machine. Bij een cilindersysteem met pinnen of kammen was je beperkt door de omtrek van de cilinder. Ponsplaten kon je oprollen of opvouwen en door het mechanisme laten schuiven bij het uitvoeren van het programma. De wevers van Lyon vreesden voor hun werk en verbrandden het weefgetouw in 1808. Het mocht echter niet baten: het ponssysteem raakte heel snel verspreid in de wolverwerkende nijverheid en de textielindustrie.
Al snel zag men ook op andere vlakken van de samenleving het nut van een ponskaartsysteem. Je kon op een ponskaart allerlei soorten informatie in gecodeerde vorm opslaan en het geautomatiseerd laten uitlezen. Charles Babbage (1791â1871) tekende plannen voor een analytische rekenmachine en voorzag de invoer van ponskaarten. Zijn plannen betekenden een serieuze stap voorwaarts in de ontwikkeling van een rekenmachine. Eerder bouwde de Fransman Blaise Pascal (1623â1662) een mechanische rekenmachine, maar die was nooit een succes geworden. Ook de machine van Babbage kwam niet veel verder dan de ontwerptafel.
p.292
p. 293: vermelding van "boze" inwoners van Lyon.
p. 367. INTRODUCTIE IN BELGIÃ (Kortrijk, crisis in textielsector, 1838)
p. 369-370
p. 358: gebruik van Jacquards weefgetouw in Brussel: concurrentie van buitenland.
De Académie royale des sciences, des lettres et des beaux-arts de Belgique of kortweg Académie royale de Belgique is de Franstalige tegenhanger van de Koninklijke Vlaamse Academie van België voor Wetenschappen en Kunsten (KVAB).
Oorspronkelijk was dit de nationale Koninklijke Academie voor Wetenschappen, Letteren en Schone Kunsten van België. De voertaal was echter het Frans. Na de vernederlandsing van de Rijksuniversiteit Gent en de ontdubbeling van de leergangen aan de Université Libre de Bruxelles/Vrije Universiteit Brussel en de Université Catholique de Louvain/Katholieke Universiteit Leuven ontstond de behoefte om ook een academie in het Nederlands te organiseren. Deze werd opgericht in 1938. De Académie royale de Belgique bleef wel de nationale academie tot de eerste staatshervorming van 1970. Sindsdien valt de Académie royale de Belgique onder de Franse Gemeenschap.
p. 57: GIRAUD introduceert het weefgetouw van Jacquard in 1827 in België. Hij blijkt de enige met de technische vaardigheid om het toestel aan de praat te krijgen. Hij werkt bij M. VELLIQUS in Brussel. In 1829 haalt M. VIAL een ander toestel in Frankrijk maar nogmaals is GIRAUD de enige die het kan laten werken. Anno 1838 is de techniek wijdverbreid in België. Twee machinebouwers zijn in staat om de toestellen te bouwen: COCKERILL in Seraing en Huytens-Kerremans in Gent (beide hebben een EUROPESE REPUTATIE).
p. 80: M.F. LOUSBERGS gebruikt sinds 1832 "les métiers à la Jacquard" voor het weven van katoen. Hij beschikt over ongeveer 100 Jacquardweefgetouwen.
p. 103: Het weven zelf blijft gebruikmaken van de oude technieken maar wel met een mechanisch procédé (système hollande) in Wijnegem (M.E. Kums).
p . 140:
p. 179 - 180: De naam Jacquard wordt in één adem genoemd als de "techniek". M. De Poorter, fabrikant in Brussel, meer dan 700 werknemers. Vanaf 1827.
Charles Etienne Guillery - http://www2.academieroyale.be/academie/documents/FichierPDFBiographieNationaleTome2049.pdf#page=271
Als alternatief werd de Fransman Charles-Etienne Guillery (1791-1861) benoemd voor zowel de scheikunde als de fysica. Guillery, die zich pas in 1829 in Brussel had gevestigd, was op vele terreinen beslagen: aan het Atheneum te Brussel doceerde hij wiskunde, aan het Museum scheikunde en natuurkunde. Hoewel Guillery een aantal elektromagnetische toestellen bouwde (waaronder een elektrische telegraaf), ging zijn voorkeur toch uit naar de scheikunde en al na een jaar liet hij de cursus fysica over aan Floris Nollet (1794-1853), een verre nakomeling, zo werd gezegd, van de Franse abbeÌ Nollet die in het midden van de 18de eeuw de experimentele fysica in Frankrijk had gepopulariseerd. Guillery en Nollet doceerden ook allebei aan de in 1835 opgerichte Militaire School. In 1840 werden ze echter verplicht te kiezen voor eÌeÌn van beide instellingen. Aangezien Nollet aan de Militaire School bleef, nam Guillery de cursus fysica weer op tot aan zijn dood. Vanaf 1842 werd Pierre-NapoleÌon De Villers belast met de cursus wiskundige natuurkunde. ( http://www.dbnl.org/tekst/hall014gesc02_01/)
p. 98: vermelding van Jacquart(d) als "gewone uitvinder" die een "REVOLUTIE" veroorzaakte.
Geert V
ANPAEMELet Brigitte V
ANT
IGGELEN, « Science for the People : The Belgian Encylopédie populaire and the Constitution of a National Science Movement », dans Faidra P
APANELOPOULOU, Agustà N
IETO-G
ALANet Enrique P
ERDIGUERO(éd.),
Popularizing Science and Technology in the European Periphery, 1800-2000
, Farnham et Burlington, Ashgate (
Science, Technology and Culture, 1700â1945), pp. 65-88, spéc. pp. 76-88.
Revue de Bruxelles, 1839
Oprichting van modelbedrijven. Eerste "zal komen in buurt van Aalst".
Een link leggen gaat heel eenvoudig.
1. Selecteer een stuk tekst.
2. Klik op de knop in de opmaakbalk.
3. Plak je link.
4. Klik op het vinkje.
5. Je link is toegevoegd.
Je kan heel eenvoudig links leggen naar andere pagina's op je site.
1. Plaats je cursor in het artikel op de plaats waar je de link wil toevoegen.
2. Klik bovenaan in de menubalk op de knop "Sitelink".
4. Er verschijnt een ankerafbeelding op de plaats waar je de cursor hebt geplaatst.
5. Klik op die ankerafbeelding.
6. Selecteer de gewenste link.
7. De link is toegevoegd.
8. Bewaar je pagina.
1. Ga naar het bureaublad.
2. Klik op "bestanden uploaden".
3. Kies in de vervolgkeuzelijst de gewenste soort bestanden.
4. Sleep je bestanden naar het uploadvlak.
5. De bestanden staan op de server.
Je kan heel makkelijk een PDF- of ZIP-bestand linken aan een pagina.
1. Open de gewenste pagina.
2. Plaats je cursor op de plaats waar je de link naar het bestand of de bestanden wil toevoegen in je pagina.
3. Klik op "bestand" in de menubalk.
4. Op de plaats waar je cursor stond, staat nu een bestandsvlak.
5. Klik op het bestandsvlak.
6. Je krijgt nu een overzicht van alle bestanden (PDF, ZIP...) die op de server staan.
7. Klik op één of meerdere bestanden. Ze worden "groen" als je ze aanklikt. Klik nogmaals om ze te "deselecteren".
8. Je beschikt hier over nog vier andere functies:
| A.uploaden: | via deze knop kan je nieuwe bestanden uploaden.
|
| B.opschriften:
|
Als je op deze knop klikt, kan je het "opschrift" van het bestand wijzigen zodat de gebruiker niet de naam van het bestand te zien krijgt.
|
| C.sorteren:
|
Als je op sorteren klikt, kan je de volgorde van de bestanden wijzigen door ze te slepen met de linkermuisknop ingedrukt.
|
| D.toevoegen | Als je op toevoegen klikt, worden de links naar de bestanden opgenomen in je pagina.
|
1. Klik op uploaden.
2. Sleep je PDF-bestanden naar het uploadvlak of klik op het vlak om PDF-bestanden te selecteren.
3. Klik op "Keer terug" om terug te keren naar de vorige stap.
1. Klik op de knop "opschriften" om de tekstlinks aan te passen.
2. Je kan op de opschriften klikken om ze te wijzigen.
1. Klik op de knop "sorteren".
2. Versleep de bestanden met de linkermuisknop ingedrukt tot ze in de juiste volgorde staan.
1. Klik op "toevoegen" om de links naar de bestanden aan de pagina toe te voegen.
2. De lijst met bestanden staat nu in uw pagina.
1 Dec
In 2013 I started with the development of Agnes.js. The name of the tool refers to Agnes, the woman who was responsible for the elearningproject at CVO Diest Leuven. She retired and I would follow her. That way I wanted to pay homage to her work.
The main purpose of Agnes.js was to provide a javascript library/framework for the development of HTML5 based exercises, independent from jQuery.
First, Agnes had to make it possible to deliver all types of exercises that you can also build with HotPotatoes: filling in the blanks, multiple choice, combination, feedback, crossword...
Secondly, I also wanted to provide new functionality such as slideshows, learning paths and "filling in the blanks"-exercises on top of maps and images.
An important objective was to make this possible using simple HTML elements.
With Agnes.js you can build a filling in the blanks-exercise by creating a div or paragraph-element. Every "strong'-element in that root element becomes a word the user has to fill in. If there is more than one possible answer, you can divide them with a slash. That way a teacher can build an exercise in MS Word by simply selecting words, make them bold and deliver the DOC-file to someone with a little knowledge of HTML... That was the way we used it at CVO.
Please read the manual.
1. Open de gewenste pagina.
2. Boven een artikel zie je een + knopje. Klik erop.
3. Je hebt nu 2 mogelijkheden.
A. Klik op de titel van een bestaand artikel.
B. Voer een titel voor een nieuw artikel/onderwerp in.
21 Nov
Firstly, I wanted to build a user interface for Agnes.js, a user friendly environment in which teachers can build their interactive lessons. There are already a range of software applications that you can use to develop e-learning material, but there is no integrated or easy-to-use environment. Most teachers are limited to the use of Powerpointpresentations or the tools provided by professional publishers of textbooks and learning methods. Most publishers sell digital versions of their textbooks augmented with digital media like audio and videomaterial. The largest part of this digital elearning content matches the classical way of frontal teaching.
A first draft called "lesbouwer" ( www.schoolvoorbeeld.be/lesbouwer.php) I built in 2015. For the design of the GUI I made use of jQuery and jQuery UI and a lot of the tools I already wrote for ArchiText ( Core elements).
23 Nov
As a student I really hate the way we have to annotate and write
bibliographical references. It must be possible to automate it, was my first thought. That's the reason I built an automated "referencing" tool which I integrated into ArchiText and WoWL. It really saves me a lot of work. The referencing tool makes use of the free to use REST-api of Google Books.
The end user must be able to easily merge information from multiple online applications. Thanks to the OEMBED- and OG-protocol, it is possible to request by a simple link information from other pages, and embed them into your own page. Because most web applications and a lot of websites provide such OG- and OEMBED-information
WoWL became a real mashup-app. It goes beyond the original intent to create a GUI for Agnes.js.
Now the end user can add/embed Wikipedia-articles, YouTube, VIMEO, Prezi, Google Maps, Google Street View, Instagram... and content from tons of other webapps.
4 Jan
Kutlu Tuna, former employee of Facebook and twitter will use WoWL for his new course on social media.
WoWL is still in beta and we still have a way to go, but the core functionality works. The team for this project created example lessons and courses in Agnes.js and WoWL.
I prouly announce the first lessons completely built in WoWL:
LATIJN:
http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=4&pageid=393088714
EINSTEIN:
http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=2&pageid=831603605
LICHAMELIJKE OPVOEDING: http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=3&pageid=212516724
4 Jan
Because WoWL has to be "easy-to-use", we choose for a facebook login system instead of a custom registration and login system. The end user can login using his facebook account. The first time he logs in, his facebook-ID, facebook username and facebook email address are stored in a MySQL-database. When the user creates an elearning course, another database table stores the course information, and remembers the facebook ID which created the course.
9 Dec
For this project we registered the domainnames www.wowl.be,
www.wowl.eu
and www.wowl.info.
The icons in the webapp WoWL are nothing more than a font ( https://fortawesome.github.io/Font-Awesome/)
9 Jan
WoWL has a superb new feature: it supports the Open Dyslexia Fonttype. OpenDyslexic is a new open source font to increase readability for readers with dyslexia. When the user clicks on a paragraph it will be displayed in a bigger, highlighted Dyslexia font. The font may look a little strange for readers without reading difficulties, but it had been developed under the supervision of specialists.
24 dec
My first lesson in WoWL 1.0
The time has arrived for me to make my very first lesson in our own e-learning environment. As the interface is not ready for use yet, I will have to make do with my existing Html, CSS and J-Query skills. I have trained myself in Agnes.js, my fellow studentâs (and kind of also my teacher) Kris Merckxâ elearningframework. If you want to take a look at how it works in detail, he has written a really good guideline which can be found over here: http://www.schoolvoorbeeld.be/27-49-Agnes.html.
The result of my work can be admired over here: http://www.schoolvoorbeeld.be/teacher/preview.php?courseid=6&pageid= . It took me quite a while and some help from Kris, but I am very proud of this simple lesson Iâve created. I used Brackets to write out the lesson, and Cyberduck to upload it all to Krisâ server. I am, however, very thankful to Kris that he is creating a intuitive, click-and-drag interface for our e-learning environment, because I most teachers would probably be scared off by al the programming that is involved in creating a lesson with Agnes.js.
A look behind the scenes: my lesson in Brackets
Tine. Thatâs me
Only 23, born and raised in Limburg, Belgium and a teacher-student-intern of Spanish, English and Dutch as a foreign language.
Iâm not a fan of blogging, but decided to give it a go anyway (rather: Iâm being forced â but thatâs okay.) I am, however, a fan of: languages (quelle surprise), computers (isnât that fortunate?), dancing, music, eating and sleeping.
Open My Blog
Meld je aan met je gebruikersnaam en wachtwoord.
In De inhoud van een webpagina aanpassen lees je hoe je foto's rechtstreeks vanaf je computer in je pagina kan slepen. Je kan ook afbeeldingen uit Word kopiëren en plakken in je tekst.
Het is ook mogelijk om meerdere foto's te uploaden naar je site. Die foto's kan je achteraf meerdere keren gebruiken in je pagina's of albums.
1. Klik op "Afbeeldingen".
2. Je komt nu in de foto-app terecht.
3. Klik op de knop "Upload" om naar het uploadprogramma te gaan.
4. In het uploadprogramma kan je op 2 manieren foto's toevoegen.
- Je kan foto's vanaf je computer slepen naar het uploadvenster.
- Je kan klikken op de knop "Bestanden toevoegen".
Hoe bouw je een foto-album?
Meld je eerst aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".
2. Het overzicht van alle albums verschijnt in beeld.
3. Als er nog geen albums in de lijst staan, start je met een nieuw album.
4. Klik op de knop "Nieuw album".
5. Voer een titel in en klik op de knop "Voeg toe".
1. Klik bij het gewenste album op de knop "Afbeeldingen toevoegen".
2. Je komt nu automatisch in de foto-app terecht.
3. Afbeeldingen toevoegen is nu heel eenvoudig.
4. Zorg dat je het gewenste album selecteert in de vervolgkeuzelijst, rechtsbovenaan.
5. Vink de gewenste foto's aan. De foto's zitten nu automatisch in het album.
Meld je aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".
2. Klik op de knop "Album bewerken" achter het gewenste album.
3. Je krijgt nu een lijst te zien van alle afbeeldingen in het album.
a. Sleep afbeeldingen met de linkermuisknop ingedrukt in de gewenste volgorde. De eerste afbeelding wordt meteen ook het coverbeeld.
b. Klik op het afsluitsymbool om een afbeelding uit het album te verwijderen. Je verwijdert hiermee niet de afbeelding zelf.
c. Je kan de naam, de auteur en de korte beschrijving van het album wijzigen.
4. OPGELET: Vergeet de aanpassingen niet te bewaren! Klik bovenaan op de knop "Bewaar aanpassingen".
Meld je aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".
2. Klik bovenaan op de knop "Verwijder".
3. Achter de albums verschijnt nu een verwijderknopje. Klik erop om het gewenste album te verwijderen.
4. Sluit de verwijderfunctie als je klaar bent. Klik op de knop "Sluit verwijderfunctie".
Meld je aan met je gebruikersnaam en wachtwoord.
1. Klik op "Albums".
2. Klik op het meest rechtse knopje in de werkbalk.
3. Je kan nu de volgorde van de albums wijzigen.
4. Sleep met de linkermuisknop ingedrukt, de albums in de gewenste volgorde.
http://www.schoolvoorbeeld.be/files/photoshop.pdf
www.schoolvoorbeeld.be/film.pdf
Fotomontages op basis van schilderijen van Museum M te leuven.
Bekijk inspirerende beelden op
"Classical versus Modern"
en
Een uniek marketingconceptvoor een museum? Zin om mee een eventte organiseren? Kan jij en wil jij deelnemen aan dit project? Neem snel contact met ons op door je in te schrijven voor ons GOPO.
Neem contact op met irene.hermans@ucll.be
Stop de led met de lange pin in digitale output 13 en de korte pin in GND (er vlak naast).
Laad de onderstaande code op naar je bord.
void setup() {
// gebruik pin 13 van de digitale "output".
pinMode(13, OUTPUT);
}
void loop() {
//zet de voltage van pin 13 hoog (5V)
digitalWrite(13, HIGH);
//laat dit zo gedurende 1 seconde
delay(1000);
//zet de voltage van pin 13 laag (0V)
digitalWrite(13, LOW);
//laat dit zo gedurende 1 seconde
delay(1000);
}
/************************************************* * Public Constants *************************************************/ #define NOTE_B0 31 #define NOTE_C1 33 #define NOTE_CS1 35 #define NOTE_D1 37 #define NOTE_DS1 39 #define NOTE_E1 41 #define NOTE_F1 44 #define NOTE_FS1 46 #define NOTE_G1 49 #define NOTE_GS1 52 #define NOTE_A1 55 #define NOTE_AS1 58 #define NOTE_B1 62 #define NOTE_C2 65 #define NOTE_CS2 69 #define NOTE_D2 73 #define NOTE_DS2 78 #define NOTE_E2 82 #define NOTE_F2 87 #define NOTE_FS2 93 #define NOTE_G2 98 #define NOTE_GS2 104 #define NOTE_A2 110 #define NOTE_AS2 117 #define NOTE_B2 123 #define NOTE_C3 131 #define NOTE_CS3 139 #define NOTE_D3 147 #define NOTE_DS3 156 #define NOTE_E3 165 #define NOTE_F3 175 #define NOTE_FS3 185 #define NOTE_G3 196 #define NOTE_GS3 208 #define NOTE_A3 220 #define NOTE_AS3 233 #define NOTE_B3 247 #define NOTE_C4 262 #define NOTE_CS4 277 #define NOTE_D4 294 #define NOTE_DS4 311 #define NOTE_E4 330 #define NOTE_F4 349 #define NOTE_FS4 370 #define NOTE_G4 392 #define NOTE_GS4 415 #define NOTE_A4 440 #define NOTE_AS4 466 #define NOTE_B4 494 #define NOTE_C5 523 #define NOTE_CS5 554 #define NOTE_D5 587 #define NOTE_DS5 622 #define NOTE_E5 659 #define NOTE_F5 698 #define NOTE_FS5 740 #define NOTE_G5 784 #define NOTE_GS5 831 #define NOTE_A5 880 #define NOTE_AS5 932 #define NOTE_B5 988 #define NOTE_C6 1047 #define NOTE_CS6 1109 #define NOTE_D6 1175 #define NOTE_DS6 1245 #define NOTE_E6 1319 #define NOTE_F6 1397 #define NOTE_FS6 1480 #define NOTE_G6 1568 #define NOTE_GS6 1661 #define NOTE_A6 1760 #define NOTE_AS6 1865 #define NOTE_B6 1976 #define NOTE_C7 2093 #define NOTE_CS7 2217 #define NOTE_D7 2349 #define NOTE_DS7 2489 #define NOTE_E7 2637 #define NOTE_F7 2794 #define NOTE_FS7 2960 #define NOTE_G7 3136 #define NOTE_GS7 3322 #define NOTE_A7 3520 #define NOTE_AS7 3729 #define NOTE_B7 3951 #define NOTE_C8 4186 #define NOTE_CS8 4435 #define NOTE_D8 4699 #define NOTE_DS8 4978
#include "pitches.h"
void setup(){
}
void loop() {
tone(11,1047,500);
delay(1000);
tone(11,1175,500);
delay(1000);
tone(11,1319,500);
delay(1000);
tone(11,1047,500);
delay(1000);
}
Sluit het ledlampje aan op digitale pin 13 en "grond".
const int temperaturePin = 0;
void setup(){
// start communicatie met seriële poort
// Gemeten in bits per seconde: Baud 9600
Serial.begin(9600);
pinMode(13, OUTPUT);
}
void loop(){
//float = kommagetallen
float voltage, degreesC;
//we meten de exacte voltage met een afzonderlijke functie getVoltage()
// geeft waarde terug tussen 0 en 5 volt
voltage = getVoltage(temperaturePin);
//omzetten van die waarde in graden celsius
degreesC = (voltage - 0.5) * 100.0;
if(degreesC>22){
digitalWrite(13, HIGH);
}else{
digitalWrite(13, LOW);
}
Serial.print("voltage: ");
Serial.print(voltage);
Serial.print(" graden C: ");
Serial.print(degreesC);
Serial.println("");
delay(2000); // wacht 2 seconden
}
float getVoltage(int pin){
return (analogRead(pin) * 0.004882814);
}
Kies "Hulpmiddelen/Seriële monitor" in de werkbalk om de uitvoer te controleren.
A morbid sense of humor:
Een woensdagnamiddag in Brussel. Kaplan vertelt meer over zijn boek tijdens een voorstelling waarbij we hem enkel horen via een directe online verbinding en een presentatie...
Ook al was Kaplan niet fysisch aanwezig, zijn presentatie zoog meteen al mijn aandacht naar hem toe. Zijn interessegebieden vertonen heel veel raakvlakken met mijn professionele activiteiten: multimediale geschiedenis, digitale beeldbewerking en nieuwe technologieeÌn zoals augmented reality.
Door zijn innovatieve kijk op het historische en theoretische onderzoek van fotografie geldt professor Louis Kaplan als een internationaal erkende autoriteit. Hij publiceerde acht boeken waaronder het vlot leesbare en ronduit ludieke The Strange Case of William Mumler, Spirit Photographer 1. Voor de onderwerpen van zijn boeken put hij uit zeer diverse, maar meestel onderbelichte aspecten van de Europese en Noord-Amerikaanse visuele cultuur uit de negentiende en de twintigste eeuw, van spiritisme tot augmented reality.
Hij hing zijn presentatie tijdens de Photography Performing Humor-conferentie in Brussel op aan zijn nog te verschijnen boek Photography and Humour. 2 Kaplan introduceerde het publiek in zeer diverse vormen van fotografische humor. Ook in dit visuele medium is humor vaak verbonden met ernstige onderwerpen zoals de eigen identiteit, sociale toestanden en de dood. Van bij het ontstaan van de fotografie in de prille negentiende eeuw toonden fotografen een morbide gevoel voor humor, vandaar ook de titel van de presentatie. Meer dan bij de andere keynotes staafde Kaplan zijn betoog met een fascinerende reeks afbeeldingen. Zijn voorbeelden balanceerden tussen bijtende politieke satire en stereoscopische huiselijke komedies, tussen conceptuele humor in de kunst tot surrealistische zwarte humor. Hij putte rijkelijk uit het in 1898 verschenen Magic: Stage Illusions and scientific diversions including trick photographyvan Albert Hopkins 3. Hij toonde hierbij aan dat technieken van beeldmanipulatie zoals bekend uit softwaretools als Adobe Photoshop een rijk verleden kennen. Negentiende-eeuwse fotografen benutten technieken zoals maskers, multi exposure, montage en compositie die bij een hedendaagse doorwinterde Photoshopper in de digitale vingers zitten. Die prille vormen van beeldmanipulatie zoals het fotograferen voor een zwarte achtergrond of spiegels leverden morbide afbeeldingen van onthoofdingen op en geestverschijningen. Hier kon Kaplan terugvallen op zijn eerdere onderzoek en publicaties.
Kaplan putte voor zijn voorbeelden uit het werk van pioniers uit de fotografie als Hyppolyte Bayard, gerenommeerde fotografen als Jacques Henri Lartigue, Elliott Erwitt, Weegee, Cindy Sherman en Martin Parr, maar ook het werk van onbekende Photoshoppers. Het leverde een geestige, vaak absurde en soms hilarische reeks voorbeelden op waar Kaplan tussen door laveerde met een pittige anekdotische vertelstijl.
De vergankelijkheid een toekomst geven.
Oude familiefoto's vertellen een verhaal, even fragmentarisch als mijn herinnering. Foto's vormen dode bevroren momentopnames uit mijn eigen geschiedenis. Kan ik de verloren en gemiste momenten weer tot leven wekken?
And if they had the words
I could tell to you
To help you on the way down the road
I couldnât quote you no Dickens, Shelley or Keats âcause itâs all been said before
Make the best out of the bad just laugh it off
You didnât have to come here anyway
So remember, every picture tells a story donât it
(R. Stewart)
Maart 2016. Ik stond naast mijn vader toen hij zijn laatste woorden zei. Ik ga toch nog niet dood, zei hij wat bevreesd, en in zijn woorden klonk de zorg om alles en iedereen. Het klonk vreemd, de woorden gingen vluchtig en nu nog brandt dat laatste beeld op mijn ogen. In mijn hoofd speelden de verhalen van mijn vader en ikzelf. Zesenveertig jaar heb ik hem gekend, beleefd, gezien, heb ik de tijd gehad om verhalen te distilleren over hem en mij. We bouwden samen een verleden. Hij was er al toen ik er nog niet was, hij maakte deel uit van een verleden dat ik nooit heb gekend, waar ik enkel over heb gehoord of waar ik vergeelde foto's van heb gezien. Bij het opruimen van zijn kamer vond ik een stapel oude foto's van familieleden die ik nooit heb gekend, maar wel herken. Elk beeld vertelt zijn eigen verhaal, soms maar wat flarden. Vergeten familieverhalen, soms nog onduidelijk of verwarrend, het verleden ontsluit zich slechts fragmentarisch via deze beelden. Hoeveel beelden gingen verloren, hoeveel momenten zal ik nooit zien? Als historicus weet ik dat dit soort beelden geen geschiedenis maken, maar ze zijn niettemin een deel van mezelf, van mijn verleden, van wie ik ben en van wat mijn kind ooit zal zijn. Ik mis heel veel en ik heb heel veel gemist. Triljoenen beelden gingen verloren, elk mogelijk moment uit mijn en zijn verleden. Het verleden ging weg en als ik de verhalen niet vertel, dan betekenen de beelden niets meer, ijle beelden van een verdwenen tijd.
De dag na het overlijden van mijn vader maakte ik een kaartje als herinnering, een reeks
memento mori,voor iedereen die hem had gekend. Ik se
â All photographs are memento mori. To take a photograph is to participate in another personâs (or thingâs) mortality, vulnerability, mutability. Precisely by slicing out this moment and freezing it, all photographs testify to timeâs relentless melt.â
Een foto verhaalt één moment, één enkel frame, zoals een snede kaas uit een groot blok. Kate Morton omschreef fotografie in haar debuutroman The House at Rivertonals een ietwat ironische manier om dode momenten, die eigenlijk enkel mogen verder leven in de herinnering, te laten overleven:
âIt is a cruel, ironical art, photography. The dragging of captured moments into the future; moments that should have been allowed to be evaporate into the past; should exist only in memories, glimpsed through the fog of events that came after. Photographs force us to see people before their future weighed them down....â
De foto's die het kaartje haalden, waren zelden meer dan willekeurigedoor de fotograaf gekozen cadrages. De fotografen van dienst hadden geen artistieke ambities, de beelden zijn niet meer dan vernacular photographies. Toch ontstonden ze uit meer dan louter willekeur. Elk beeld vertolkte een verhaal dat net zoals het beeld zelf uit de werkelijkheid, uit het continuüm, was losgesneden en nu verder leefde. De fotograaf had het moment gedood en vastgelegd en elk beeld bracht een verhaal tot leven.
âTo photograph people is to violate them, by seeing them as they never see themselves, by having knowledge of them that they can never have; it turns people into objects that can be symbolically possessed. Just as a camera is a sublimation of the gun, to photograph someone is a subliminal murder - a soft murder, appropriate to a sad, frightened timeâ, schreef Susan Sontag.
Toch is elk beeld meer dan pure willekeur, het zijn zorgvuldig uitgekozen momenten. Ook al had de fotograaf geen artistieke pretenties, de fotograaf legde een magisch moment vast. Elk beeld was een toevallig, maar niettemin bewust gekozen moment. De Amerikaanse fotograaf Stephen Wilkes omschrijft dit proces als het vastleggen van magische momenten :
â It's my eye seeing very specific moments, I like to describe myself as a collector of magical moments."
Elke vernacularfoto vertolkt een verhaal, een beeld dat magische momenten en verhalen in leven houdt, ook al zijn de actoren er niet meer om ze te bevestigen of te ontkennen. Het maakt ons tot wie we zijn of tot wat we willen zijn.
â Photography is a medium that is famous for freezing time. The word snapshot suggests that a tiny slice of time is recorded for posterity⦠A photographic print is flat, and essentially is made of 2 dimensions: length and width. Yet through composition and lens focus we give a print depth⦠The best images are the ones which let you feel like you can step directly into the frame into a world which is on the other side.â
(Fong Qi Wei) 1
Een foto vormt een momentopname, een
dood moment, een
fractie van tijdop beeld vastgelegd. Fotograaf en kunstenaar Fong Qi Wei omschrijft fotografie als een manier om de tijd te bevriezen. De fotograaf se
Gordon Bell van Microsoft Research trachtte met zijn MyLifeBits-project zijn volledige geschiedenis vast te leggen met audio-, beeld-, tekst- en videomateriaal. Lifeloggingis de exacte benaming die de onderzoekers van Microsoft er voor in het leven geroepen hebben. Het is in hun ogen een enige manier om tot een Total Recallvan je persoonlijke verleden te komen. De vraag is natuurlijk of we dit wel willen. De SenseCam is een soort van webcam die je rond de hals kan dragen. Het toestel maakt automatisch, met behulp van bewegingssensoren, warmtedetectoren enz. foto's van je hele dag. Oorspronkelijk werd het ontwikkeld voor het helpen van Alzheimer-patieÌnten. Het bezorgt deze mensen een soort valse vorm van herinnering, elk vergeten moment wordt bewaard in een digitale databank.
Hoe lang duurt een moment? De meeste mensen ervaren een moment als iets wat ze bewust kunnen zien. Het bewust waarnemen van een beeld duurt ongeveer honderd milliseconden. Nemen we de tijd dan waar in stukjes of frames zoals een filmcamera dat doet? Maken onze hersenen van elk moment een afzonderlijke stillof foto die ze levenslang vastleggen in ons geheugen? Betekent dit dat onze hersenen de binnenkomende signalen van sensoren zoals de ogen en de oren bemonsteren (samplen) en de informatie discretiseren zoals bij digitalisering gebeurt? Het sleutelwoord bij digitaal is discretisatie in ruimte en tijd. Bij het digitaliseren van analoge beeldinformatie, plaatst een digitaal fototoestel een denkbeeldig raster over de fysieke wereld en meet de binnenkomende signalen op het moment dat de fotograaf klikt. Een sample of een monster van een digitale foto bestaat uit een verzameling van picture elements of pixels, de bemonstering gebeurt bij fotografie enkel geometrisch, in lengte en breedte, en niet doorheen de tijd zoals bij een audio- of filmopname. Een digitaal systeem meet eveneens de signaalniveaus (discretisatie van de signaalwaarden) zoals bijvoorbeeld de lichtintensiteit van een pixel. Het lijkt erop dat onze hersenen niet enkel momentopnames maken in een geometrisch perspectief, maar ze eveneens inhoudelijk verwerken. Ze koppelen beelden aan verhalen, geluiden en geuren. Het lijkt wat op de manier waarop sociale media gebruikers beelden laten taggenof er doorzoekbare informatie aan te koppelen. Wat Ingrid Hoelzl opmerkt over de evolutie van analoge naar digitale fotografie, kan dus in zekere mate ook gezegd worden over de manier waarop onze hersenen beelden verwerken: "The algorithmic image is no longer governed by geometric projection, but by algorithmic processing."(Softimage, 5).
Onderzoekers van de universiteit van Glasgow ontdekten dat ons brein de werkelijkheid niet ervaart als een continuüm. Net zoals bij digitalisering verdelen onze hersenen binnenkomende signalen in momentopnames. De resultaten verschenen in het vakblad Current Biology. Professor Gregor Thut van de universiteit van Glasgow zegt hierover: âRitmiek is inderdaad alomtegenwoordig, niet alleen in de hersenactiviteit, maar ook in de hersenfunctie. Voor de waarneming betekent dit dat, ondanks het âfeitâ dat we de wereld ervaren als een continuüm, we niet constant âmonstersâ nemen van de wereld, maar in discrete momentopnames, bepaald door de cycli van hersenritmes.âDe snelheid waarmee onze ogen de werkelijkheid bemonsteren, ligt veel hoger dan bij een fototoestel.
Wat bepaalt de lengte van het kortst mogelijke moment?Meten we hoe snel een mens bewust of onbewust een moment kan ervaren (een ogenblik) ofbestuderen we het kortst te registreren moment? Onderzoekers van de MIT Media Lab Camera Culture Group ontwikkelden onder leiding van Ramesh Raskar een camera die een biljoen beelden per seconde kan maken. Wanneer je de beelden in slow motion bekijkt, krijg je de werkelijkheid op een heel andere manier te zien. Hiermee zijn de MIT-wetenschappers er zelfs in geslaagd om de beweging van licht in slow motion vast te leggen. Ze brengen op die manier een nooit eerder waargenomen wereld tot leven met een fototoestel dat het kortst mogelijke moment vastlegt. Daarmee legt de camera echter nog niet de werkelijkheid vast:
â The camera does not capture the visual forms of an event, but instead creates the visual form of a photographic event. It depicts a moment th at never actually existed, and which has therefore never been perceived or recognized or photographed as such. The photograph does not reveal the optical unconscious, but rather the photographic uncanny: It shows what does not priory exits to the photographic event, that is, the photograph. The photograph is uncanny not because it reanimates the past, but because iet creates ghostly references.â (46)
A picture of you in your birthday suit,You sat in the sun on a hot afternoon.Picture book, your mama and your papa,and fat old uncle charlie out cruising with their friends.Picture book, a holiday in august, outside a bed and breakfast in sunny southend.Picture book, when you were just a baby,those days when you were happy, a long time ago.( R. Davies )
Fotografie biedt de mens een middel om het verleden/heden visueel te bewaren. Anders dan een tekst lijken foto's historici een objectiever houvast te bieden. Nochtans leggen ze slechts één verleden vast, bekeken vanuit het perspectief van de fotograaf die een kader legt over zijnheden. Millennia lang was de mens aangewezen op het gesproken verhaal. De komst van het schrift in het vierde millennium voor onze tijdrekening maakte het mogelijk om het verleden ook buiten het geheugen van de mens vast te leggen. Het waarheidsgehalte hing af van het standpunt van de schrijver, van zijn opmerkzaamheid, van zijn woordenschat en van tal van andere factoren. Misschien verzweeg hij dingen of verdraaide hij de werkelijkheid. Bovendien kon hij enkel noteren wat hij zelf met zijn beperkte gezichtsveld had waargenomen, wat anderen hem hadden verteld of wat hij had gelezen. Historici kennen het verleden slechts fragmentarisch. Elk geschiedenisboek vertelt maar een klein stukje en zelfs als we alle bekende feiten samenvoegen dan nog komen we niet tot een lappendeken dat het hele verleden bestrijkt. We missen letterlijk de geuren en de kleuren, de geluiden en de beelden.
Kan technologie het verleden in beeld brengen zonder fototoestel? Een digitale afbeelding bestaat uit een reeks pixels of beeldpunten, verdeeld over een geometrisch raster van horizontale rijen en verticale kolommen. Elk beeldpunt kan een bepaalde kleurwaarde aannemen. Jeffrey Thompson, assistent-professor en programmadirecteur in Visual Art & Technology aan het Stevens Institute of Technology in Hoboken, schreef in 2013 een stuk software dat willekeurig afbeeldingen genereert. Als je de software voldoende tijd geeft, creëert hij elke mogelijke afbeelding. In datzelfde jaar zette Thompson de tentoonstelling Every Possible Photographop waarin hij de mogelijkheden van zijn software demonstreerde:
âThis project investigates the idea of using computation to âuse upâ a piece of technology, in this case a digital camera. Using custom-written software (and a very long period of time), every possible photograph is generated, one at a time and in numerical order. The idea that extremely useless labor is interesting is central to this project (and the proposed project as well), as is the eschewing of the utility of data and its representation in traditional visualization work. Attempting to create every image a camera is essentially a time machine; somewhere in the set of images and alongside billions of âmeaninglessâ others are a photograph of me, a photograph of me if I didnât get a haircut last week, and a photograph of me with someone who I have never met.â
Indien de software een foto zou genereren van 400 bij 300 pixels, dan resulteert dit in 120 000 pixels per foto. De kwaliteit zou laag zijn, maar niettemin een herkenbaar beeld opleveren. Bij een kleurdiepte van 24 bit, zou de software een keuze hebben uit 16 777 215 kleuren per pixel. Op die manier kan de software achter het Every Possible Photograph-project elk denkbaar beeld uit het verleden of de toekomst genereren. Elk mogelijk beeld ontwikkelen zou niet alleen een computer met een enorme rekenkracht vereisen, maar bovendien zou de ontwikkeling (rendering) van alle beelden onwaarschijnlijk veel in beslag nemen. Thompson beperkte zich tot afbeeldingen van 15 bij 10 pixels en grijswaarden. Maar zelfs in dat geval zou het genereren van elke mogelijke combinatie 46 138 562 195 008 110 600 774 753 760 087 749 172 181 189 607 929 628 058 548 517 099 604 563 033 706 075 jaar duren.
A single âphotographâ, number 657
2
Every Possible Photographzou elke momentopname uit het verleden van mijn vader in beeld kunnen brengen. Maar de grootste uitdaging zou er uit bestaan om het werkelijke verleden van het fictieve verleden te scheiden. Immers, elk denkbaar verleden, elke denkbare toekomst is voor de visualisatiesoftware even waarschijnlijk. De software zou alle mogelijke wat als-scenario's tot leven brengen, elk mogelijk heden en verleden. Wat als-scenario's zijn voor de meeste historici niet meer dan leuke denkoefeningen, maar ze zijn misschien niet meer of minder waarschijnlijk dan werkelijke gebeurtenissen. Toen ik in 2012 mijn boek In geen tijdschreef, was ik lusteloos op zoek naar een rode draad die alle hoofdstukken aan elkaar zou rijgen. Mijn dochtertje keek bij toeval naar de Pixar-film "Brave". De verteller in de film reikte me de volgende woorden aan:
âAnderen zeggen dat de draden van het lot geweven worden als een kleed en dat iemands lot verstrengeld is met dat van vele anderen. We zijn allemaal op zoek naar het patroon of willen het veranderen.â
Met CGI (computer generated images) kunnen we elke gesponnen draad, elk potentieel moment uit het verleden vastleggen en ook elk denkbaar moment, ook al is het nooit effectief gebeurd. We kunnen van Hitler een menslievend figuur maken en de Holocaust annuleren, we kunnen de wereld bevrijden van de mens of de wereld totaal vernietigen. Elk denkbaar verleden, elke denkbare toekomst wordt mogelijk. Vastgelegd in foto's, beeld voor beeld. Allen even waarschijnlijk als onwaarschijnlijk. Ik had elke mogelijke vader kunnen hebben, niet volgens mijn DNA, maar wel dankzij Every Possible Photograph. Every picture tells a story,fictief of non-fictief.
Kris Merckx
1. Conveying the Passage of Time through Photography, (http://twistedsifter.com/2013/08/conveying-time-through-photography-fong-qi-wei/), Geraadpleegd op 6 juni 2016.
2. THOMPSON, J. A single âphotographâ, number 657 (http://jeffreythompson.org/every-possible-photograph.php), Geraadpleegd op 7 mei 2016.
De praktijk van fotomanipulatie.
Manipulatie is inherent aan fotografie en niet het gevolg van digitale fotografie of beeldbewerking. De hang naar objectiviteit in documentaire fotografie is een relatief recent gegeven. Weliswaar dient er een onderscheid gemaakt te worden tussen manipulatie en bedrog.
âTraditional photographs - the ones our culture has always put so much trust in - have never been âtrueâ in the first place. Photographers intervene in every photograph they make, whetherby orchestrating or directly interfering in the scene being imaged; by selecting, cropping, excluding, and in other ways making pictorial choices as they take the photograph; by enhancing, suppressing, and cropping the finished print in the darkroom; and, finally, by adding captions and other contextual elements to their image to anchor some potential meanings and discourage others.â 1 (G. Batchen)
Het begrip Photoshoppendraagt in onze tijd een erg negatieve lading. Digitale fotografie en beeldbewerking zouden fotografie van haar echtheid hebben ontdaan.
"It has often been argued that digital interventions undermine photography's supposed truthful status, and have thus come to herald the death of analog photograpy's most specific hallmark". 2
Nochtans ontstond manipulatie van beelden niet bij het verschijnen van digitale beeldbewerkingsprogramma's. In zekere zin dook het streven naar objectiviteit en echtheid in de fotografie pas relatief laat op. Het in scene zetten van beelden behoorde tot de normale gang van zaken. De vroege fotografen volgden de tradities uit de schilderkunst en de theaterkunst waarbij respectievelijk de portretkunst en de decorbouw tot voorbeeld dienden. In het laatste kwart van de 19e eeuw verscheen in de fotografie straight photographyop de voorgrond. Deze fotografen streefden naar een pure fotografie waarbij het documentaire en het vormelijke aspect het belangrijkst waren. Een foto mocht niet in scene worden gezet of gemanipuleerd. De gedetailleerde foto's die fotografen als Paul Strand en Edward Weston maakten, streefden naar objectiviteit.
Volgens Geoffrey Batchen is het een illusie te denken dat een foto de objectieve werkelijkheid kan weergeven. Elke fotograaf manipuleert in min of meerdere mate de foto's die maakt. Immers, elke fotograaf se
âAny familiarity with photographic history shows that manipulation is integral to photography. Over and above the cultural bias toward "Renaissance space" that provides the conceptual grounding of photography itself, there are the constraints of in-camera framing, lenses, lighting, and filtration. In printing an image, the selection of paper and other materials affects color or tonality, texture, and so forth. Furthermore, elements of the pictorial image can be suppressed or emphasized, and elements from other "frames" can be reproduced on or alongside them. And context, finally, is determining.â 3
Daarom geldt manipulatie volgens Van Gelder niet als een waardig criterium om het verschil tussen analoge en digitale fotografie te bepalen. Analoge fotografie verschaft de kijker geen echterbeeld van de werkelijkheid. 4 Door bepaalde elementen te benadrukken en andere weg te laten kan fotografie een onevenwicht te weeg brengen in wat de kijker als waarheid aanvaardt. Ritchen stelt
â Photography, even of the most realistic type, can articulate truths even though facts may be wrong and conversely, can also be quite wrong as to the essence of a situation despite getting the facts rightâ. 5
Dit geldt zowel voor analoge als voor digitale fotografie. De Amerikaanse filosoof Scott Walden begrijpt het wantrouwen in het waarheidsgehalte van digitale foto's:
âDigital images can also le a ve the veracity of our thoughts unscathed. But it will be much more difficult for the viewer to have confidence in such thoughts because it is much more complex to verify the degree of objective, mechanical creation of digital images than that op analog images.â 6
Hoelzl duidt de algoritmische verwerking in digitale fotografie en beeldbewerking als één van de belangrijkste verschilpunten met analoge fotografie 7
â On the subject of retouching photographic negatives, there are many conflicting opinions, and a great deal of nonsense has been uttered both for and against this operation; some perfectly competent photographers urging that a photograph is quite incomplete until it has been retouched, others asserting that when a negative leaves the dark room it is quite ready for the printer." 8
(R. Johnson, A.B. Chatwood, 1895)
âComposite photography consists in the fusion ot a certain number of individual portraits into a single one. This is effected by making the objects which are to be photographed pass in succession before the photographic apparatus, giving each of them a fraction of the long exposure, equal to such exposure expressed in seconds and divided by the number of the objects which are to be photographed.â 9
(A. Hopkins, 1898)
De se
In het boek â Magic. Stage illusions and sci ent ific diversions including trick photographyâbeschreef Hopkins een reeks technieken voor het trukeren van afbeeldingen. Vele van de door hem beschreven vormen van beeldmanipulatie vonden hun weg naar de film. De speciale effecten in de films van filmpionier Georges Méliès waren er schatplichtig aan. De kijkers waren er zich in de meeste gevallen van bewust dat het ging om trucage. De maker had niet de bedoeling om zijn publiek iets wijs te maken of te bedriegen, maar wou verbazing wekken zoals een goochelaar dat deed op het podium. Anders gaat het wanneer de makers bewust de bedoeling hebben om de kijker te bedriegen. In de jaren 1920 raakten de Britse nichtjes Frances Griffith en Elsie Wright wereldberoemd toen ze foto's maakten van henzelf in de tuin omringd met elfjes. Experts verklaarden de foto's als echt. Het zou vijftig jaar duren vooraleer ze hun bedrog toegaven. Het gebruik van vervalste foto's om het eigen gelijk kracht bij te zetten, kent een lange traditie in de politiek en de oorlogsfotografie:
âThe use of faked photographs is a long-standing political trick, in the form both of photographs misappropriated or changed after they were produced and in ones set up for the camera. Before lithographyâ enabled newspapers to use photographs directly around 1880, photographs were at the mercy of the engravers who prepared the printing plates for reproduction. Even now, cropping and airbrushing are decisive methods of manipulating existing imagery, and set-up or staged ("restaged") images are always a possibility.â 10
"Every day, the internet generates trillions of images and videos (...). The volume of photos and videos generated in the past 30 days is bigger than all images dating back to the dawn of civilization. In the presence of massive volume, large variety and high velocity, programming machines to recognize all objects in the observed images seems to be an impossible task to carry out. However, the performance of computer vision can be enhanced substantially by big data." 11
(S. Liu, J. McGree, Z. Ge, Y. Xie)
Anders dan het algemeen overheersende denkbeeld is beeldmanipulatie geen gevolg van de digitalisering, beeldbewerkingssoftware betekende enkel een krachtige stimulans. Volgens Rosler is het succes van digitale beeldmanipulatie
âthe logical consequence of digital developments of a cultural imperative to create perfectly tricked pictures, rather than vice versa.â 12
De opkomst van digitale beeldmanipulatie roept ons op om de eigenheid van fotografie als visueel medium opnieuw in vraag te stellen, op dezelfde manier waarop de schilderkunst zichzelf in vraag diende te stellen bij het ontstaan van de fotografie. Zelfs de meest realistische portretschilderijen konden niet tippen aan het realisme van een foto. Schilderijen zijn gebaseerd op getekende lijnen en penseelstreken. Foto's bestaan uit een reeks microscopisch kleine belichte partikels of pixels waarvan de werkingerg lijkt op die van de retina in een menselijk oog. Zo vereist ook de opkomst van digitale fotografie en beeldmanipulatie dat het representatieve karakter van fotografie in vraag wordt gesteld.
Ingrid Hoelzl ziet in de overgang naar digitale fotografie twee belangrijke verschuivingen. In de eerste plaats ruimt het klassieke geometrische aspect van het 2D-beeld plaats voor de algoritmische verwerking van beelddata. Daarnaast maakt een beeld slechts onderdeel uit van een reusachtige databank:
â I n the digital age, computers process data, while the image is part of the database. As a tentative view of networked databases, the image is continuously updated and refreshed.â 13
De menselijke retina reageert gevoeliger op helderheid dan op kleuren. Het menselijk brein heeft weinig oogvoor tintverschillen. Wanneer een mens naar een blauwe lucht kijkt, merkt hij niet de duizenden tinten blauw die een beeldchip wel kan registreren. Het JPG-algoritme laat daarom heel wat kleurverschillen weg. Eenvoudig voorgesteld: een jpeg verdeelt een afbeelding in een raster waarbinnen gemiddelde waardes worden gemeten. Veel variatie in kleur wordt weggelaten. Hoe meer verschillen weggelaten worden, hoe groter de compressie. Hoe kleiner de cellen in het raster, hoe meer kleurverschillen het algoritme bewaart en hoe lager de compressie. Dit algoritme dat in de meeste digitale toestellen de facto is ingebed, manipuleert op die manier reeds het beeld dat de beeldchip van het fototoestel registreert.
Een digitale afbeelding bestaat uit een eindig aantal rijen en kolommen. Elke cel van die matrix vormt een pixel en die pixel kan, afhankelijk van de gebruikte hardware tussen de 2 en de ettelijke miljoenen kleurwaardes aannemen. Software maakt het mogelijk elke afzonderlijke pixel te bewerken, te verwijderen of te vervangen. Hiervoor hebben softwareontwikkelaars gebruiksvriendelijke bewerkingsinterfaces gebouwd. Naast het digitaal retoucheren van fotografische afbeeldingen, kan de gebruiker afbeeldingen in composities of collages samenvoegen. De eigenheid van digitale afbeeldingen maakt het anderzijds ook mogelijk om nieuwe afbeeldingen te genereren. In zo'n geval spreekt men van CGI of computer generated images.
Het insluiten van camera's in mobiele telefoons, tabletcomputers en laptops heeft ertoe geleid dat het maken van foto's niet alleen veel goedkoper is geworden, maar dat de stap om een foto te maken is geminimaliseerd. Dankzij social media is het delen van foto's een fluitje van een cent. Zoals Hoelzl stelt, maakt deze gigantische hoeveelheid beeldbestanden deel uit van een gigantische databank van genetwerkte gegevens: big data. De term âbig dataâ duidt niet op een computertechniek, maar slaat op de gigantische hoeveelheid digitale informatie die wereldwijd beschikbaar is. In 2016 zullen datacenters (plaatsen waar internetservers staan opgesteld) wereldwijd 16000 ha oppervlak innemen. De gezamenlijke datacapaciteit is dus enorm en naar schatting is op dit moment slechts 0.5% van die gegevens geanalyseerd. Datascientists hopen hiervan binnen enkele jaren tijd tot 33% te taggen en analyseren. Vooral het analyseren van afbeeldingsdata maakte op technologisch vlak rasse schreden voorwaarts. Robuuste, schaalbare en zelflerende algoritmes voor het ophalen, indexeren, organiseren van visuele informatie zijn in voortdurende ontwikkeling. Slimme algoritmes herkennen objecten in afbeeldingen en kunnen die koppelen aan zoekalgoritmes. Intelligente bewakingscamera's herkennen mensen en hun respectieve interesses en eventueel verdachte gedragingen.
Japanse onderzoekers slaagden er in 2008 in om op basis van een fMRI-scan van de hersenen beeldmateriaal uit menselijke hersenen te reconstrueren. Het onderzoek naar visual image reconstruction from brain activity gaat door aan verschillende onderzoekscentra en men bereikt op dit moment al onvoorstelbare resultaten. Bij sommige computerwetenschappers rijst het vermoeden dat de werkelijkheid slechts een virtuele simulatie is, een verzameling van gemanipuleerde visuele gegevens. De simulatiehypothese stelt dat de zichtbare realiteit niet echt is, maar dat we leven in een computersimulatie. De âgesimuleerdenâ (wij mensen) zijn zich er totaal niet van bewust. Dit idee vormt de basis achter SF-films zoals The Matrix. Volgens de Britse computerdeskundige Nick Bostrom zijn er argumenten om aan te nemen dat dit wel degelijk het geval is. De fotograaf, noch de softwaregebruiker gelden dan als de manipulator. Zij zijn zelf het slachtoffer van een volledig gemanipuleerde en virtuele omgeving. Meer nog, misschien maken ze zelf wel deel uit van die visuele illusie.
1. G. BATCHEN, "Phantasm: Digital Imaging and the Death of Photography", Aperture,136 (1994), 48.
2. H. VAN GELDER, H. WESTGEEST, Photography theory in historical perspective,Chichester, 2012, 23.
3. M. ROSLER, Image Simulations, Computer Manipulations: Some Considerations, (http://www.artic.edu/~pcarroll/rosler.html), Geraadpleegd op 5 juni 2016.
4. VAN GELDER, Photography theory,31
5. F. RITCHEN ,âWhat is Magnum? â, Our Time: The World as Seen by Magnum Photographers,(New York: The American Federation of Arts in association with W.W. Norton & Company, 1989), 422.
6. S. WALDEN, Photography and philosophy: Essays on the pencil of nature, Malden, 2008, 108-110.
7. I. HOELZL, R. MARIE, Softimage, towards a new theory of the digital images, Chicago, 2015, XX.
8. R. JOHNSON, A.B. CHATWOOD, Photography artistic and scientific, Londen, 1895, 116.
9. A. HOPKINS, Magic. Stage illusions and sci ent ific diversions including trick photography, New York, 1898, 495.
10. M. ROSLER, Image Simulations, Computer Manipulations: Some Considerations, (http://www.artic.edu/~pcarroll/rosler.html), Geraadpleegd op 5 juni 2016.
11. S. LIU, J. MCGREE, Z. Ge, Y. XIE, Computational and statistical methods for analysing big data with applications, Londen, 2016, 58.
12. .M. ROSLER, Image Simulations, Computer Manipulations: Some Considerations, (http://www.artic.edu/~pcarroll/rosler.html), Geraadpleegd op 5 juni 2016.
13.. I. HOELZL, R. MARIE, Softimage, towards a new theory of the digital images, Chicago, 2015, XVIII.
Leren betekent ook informatie bestendigen in het geheugen. Ruwweg kunnen we als mens op twee manieren informatie leren en opslaan. Declaratieve herinneringengaan via de kortetermijnbuffer naar onze hersenen. Het betreft in dit geval semantische herinneringen, zoals begrippen en feiten, en episodische herinneringen, die gekoppeld zijn aan een bepaalde tijd en ruimte. Dit soort informatie raakt het snelst vergeten. Niet-declaratieve herinneringengaan niet via de kortetermijnbuffer en lijken door onze hersenen meer te worden bestendigd. Hierin onderscheiden we drie vormen van leren: motorisch leren verloopt via de kleine hersenen, perceptueel leren via de neocortex en gewoontevorming via de basale ganglia.
De langetermijnopslag, kortom de âharde schijfâ of het geheugen van onze hersenen, ligt in de neocortex en voor een stuk in de hippocampus, in het zogenaamde "zoogdierenbrein". Mensen met geheugenproblemen zoals dementie âvergetenâ de namen van hun kinderen, maar kunnen meestal wel nog fietsen of koken. Het lijkt erop dat aangeleerde stappenplannen beter geconsolideerd worden dan pure feitenkennis. Ook al hebben computers niet meteen last van dementie, toch onderscheiden we ook hier die
In onze tijd installeren we met het grootste gemak nieuwe programmaâs op een computer. Elk programma voert onder impuls van de invoer van de gebruiker bepaalde instructies uit. Een machine zorgt niet alleen meer voor de energieomzetting, ze neemt niet alleen werk uit handen, maar ze verzorgt ook voor een stuk de stuurfunctie. De logische instructies die we als mens zouden uitvoeren, zijn als een programma in de computer vastgelegd. Het programmeren van een machine en het vastleggen of opslaan van het programma is zeker geen beginpunt in de technische evolutie. Een hamer of bijl maakt werk eenvoudiger, een hefboom verlicht letterlijk het werk, een watermolen kan energie omzetten, maar een programmeerbare machine gaat nog een stap verder. Die neemt een stuk van de stuurfunctie voor zijn rekening. Het vormt een stap op weg naar kunstmatige intelligentie.
Noel Sharkey, hoogleraar artificieÌle intelligentie en robotica aan de universiteit van Sheffield, bestudeerde het werk Peri automatopoietikes van
â(...) Nadat ik Herons tekst grondig had gelezen, had ik niet de minste twijfel over zijn intentie. Het is duidelijk dat hij zijn robot had ontworpen om hem te kunnen programmeren en om hem in het theater voor verschillende effecten te gebruiken. Op een bepaald punt beschrijft hij zelfs hoe je ingewikkeld gedrag moet programmeren.â
Net zoals in moderne programmeertalen slaagde Heron er ook in om een âtimerâ-functie in te bouwen. Daarvoor plakte hij met was een stuk van het touw vast aan de as. Het zakkende gewicht trok het was stilaan los. Als het touw eenmaal was losgekomen, begon de as weer te roteren. Je zou de instructies voor Herons robot kunnen uitschrijven met een eenvoudige programmeertaal, zoals de programmeertaal die (als een gratis alternatief) voor Lego® Mindstorms- robots werd ontwikkeld.
task main(){
OnFwd(OUT_A,75);
OnFwd(OUT_B,100);
Wait(3000);
}
De ongeziene genialiteit die hij aan de dag legde bij het programmeren van zijn automatische theaters doet vermoeden dat ze slechts een stap waren in een lange traditie van programmeerbare machines. Dat blijkt ook uit zijn teksten. Heron klaagt er uitdrukkelijk over dat schrijvers die voor hem leefden niet duidelijk genoeg waren in hun boeken over automaten. Hij verwijst ook expliciet naar het thans verdwenen boek van Philo van Byzantiumover automatische theaters. Ook de werken van Aristoteles bevatten referenties aan automaten, en zelfs in de Ilias van Homeroslijken sommige passages automaten ter sprake te brengen.
Moderne software heeft met andere woorden oeroude wortels.
Het heeft er dus alle schijn van dat automaten een onafgebroken traditie van overerving kennen, startend bij Philo van Byzantium over Heron, via de Arabische ingenieur Al-Jazarien Leonardo da Vincinaar de programmeerbare weefgetouwen van Jacquard. Moderne software heeft met andere woorden oeroude wortels.
Kris Merckx - Uit het boek: "Niet van gisteren". http://www.nietvangisteren.be
lorem ipsum
Je hoort het wel vaker. De computer kan geen âopen vragenâ interpreteren, âgesloten oefeningenâ wel. Een stuk software kan perfect kruiswoordraadsels, invuloefeningen, combinatie-oefeningen en dies meer verbeteren (nadat een gebruiker ze heeft ingevuld), maar open vragen zijn een ander paar mouwen. De computer weet niet veel raad met vragen als âWaarom probeerde België zich los te maken van Nederland in 1830 (en is het nog gelukt ook)?â
Natural Language Processing of NLPprobeert die taalkundige softwareproblemen op te lossen. Het kent al een lange ontwikkelingsgeschiedenis, maar heeft nog een hele weg af te leggen. We proberen in dit artikel uit te leggen hoe NLP-toepassingen zoals Google Translate werken. Misschien kijk je achteraf met ogen vol verwondering naar die gekke vertalingen die soms (vaak) wel eens opduiken in Google Translate. Geloof je me niet? Lees dan even verder en leer de grote struikelblokken van het softwarematig begrijpen van menselijke talen kennen.
Beeld je de volgende oefening in:
Op 6 ......................... vieren we de verjaardag van â¦...........................
Zie ginds komt de ......................... uit ............................ weer aan.
We kunnen een stuk software schrijven dat dit soort oefeningen perfect kan verbeteren. We schrijven het zo dat ook andere zinnen kunnen ingevoerd worden. Een docent/leraar zou op de volgende manier een oefening kunnen aanmaken die door de software automatisch wordt omgezet in een invuloefening:
Op 6 <antwoord>december</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas</antwoord>
De software weet dat hij alle woorden tussen de markering â<antwoord></antwoord>â moet verbergen. Bovendien kan hij zelf tellen hoeveel vragen er zijn. In de eerste zin moeten twee woorden worden ingevuld. De oefening staat dus op 2 punten. Maar hier duikt meteen een probleem op. Wat als de student/leerling i.p.v. december gewoon een 12 invoert, of i.p.v. Sinterklaas, âde sintâ? Dit kan je als docent toch onmogelijk fout rekenen?
Heel wat programma's lossen dit op door aan de persoon die de oefening samenstelt te vragen alle mogelijke antwoorden in te voeren. In ons geval zou het er dan als volgt kunnen uitzien:
Op 6 <antwoord>december/12</antwoord> vieren we de verjaardag van <antwoord>Sinterklaas/de sint</antwoord>
De leraar voert hier alle mogelijke antwoorden in, telkens gescheiden door een schuine streep. Maar ook dan zijn de problemen niet helemaal van de baan. Want wat moet je als docent doen met een leerling met dyslexie die â demecberâ schrijft of â sntriklaasâ? Ook die antwoorden moeten goedgekeurd worden. Uiteraard niet voor iedereen, enkel voor leerlingen met een schrijf/taalprobleem. Het zou niet zinvol zijn om alle mogelijke schrijffouten vooraf in te voeren. Bovendien zouden leerlingen zonder taalproblemen dan rijkelijk beloond worden.
Vaak gaat men ervan uit dat software niet in de mogelijkheid zou verkeren om hier een echte oplossing voor te bieden. NLP of Natural Language Processing kan echter heel wat van deze beperkingen opvangen.
NLP combineert elementen uit de wetenschap, de taalkunde en het domein van Artificiële Intelligentie (AI). Twee belangrijke domeinen waarop NLP zich toespitst zijn
Alan Turinglegde de basis voor NLP met zijn beroemde Turingtestwaarbij een mens en een machine op afstand in vraag-antwoord-stijl met elkaar communiceren. Als de machine de mens kan overtuigen dat hij âeveneens een mensâ is, dan evenaart de machine in Turings ogen de menselijke intelligentie. De computer slaagt in de test als hij in meer dan 30% van de tijd voor een mens wordt aanzien.
Joseph Weizenbaum ontwikkelde tussen 1964 en 1966 ELIZA, de eerste beroemd geworden âchatbotâ. ELIZA simuleerde een psychotherapeut, een goed uitgangspunt om in vraag-antwoordstijl te werken. Omdat de kennis van ELIZA erg beperkt was, antwoordde de âchatbotâ vaak met open vragen zoals âWaarom zeg je dat je hoofdpijn hebt?â. De supercomputer Eugene Goostman slaagde in juni 2014 voor de test door het âbreinâ van een 13-jarige te simuleren.
Om een machine (computer, software...) taalte laten begrijpen, moet ze ook de betekenis van een tekst of zin kunnen achterhalen. Wanneer een kind taal leert, vertaalt het simultaan de werkelijkheid naar taal en omgekeerd. Een dorp bevat straten en huizen, een huis bevat kamers, kamers bevatten meubels enz. Woorden en begrippen hebben relaties en staan in verband met elkaar... Woorden en begrippen vormen netwerken, interfereren met elkaar enz. In hun hoofd vormen en herkennen kinderen stapsgewijs al die relaties en begrippenkaders... ze krijgen een beeld van de wereld en van de werkelijkheid: een ontologie. Vanaf de jaren 1970 zagen programmeurs in dat het nodig was om ook voor NLP zulke âontologieënâ te ontwikkelen. De ârelatiesâ en âbegrippenkadersâ uit de echte wereld moesten vertaald worden naar gegevens die door een computer konden begrepen worden. Voorbeelden van zulke âontologieënâ zijn ondermeer MARGIE, SAM en PAM... Ze leidden tot nieuwe chatbots zoals Parry en Jabberwacky.
Deze manier van werken had tot gevolg dat in de jaren 1980 de meeste NLP-systemen bestonden uit eindeloze reeksen regeltjes, tot verregaande schematisering van taal. Vanuit softwarecode gezien leidde dit tot eindeloze âif-elseâ-structuren. Je kent het wel: âAls (if) je braaf bent, krijg je een koekje, anders (else) een stokje.âIn de werkelijkheidzit er veel meer variatie. Het is mogelijk dat het kind anders altijd heel braaf is en nu één keertje stout. Neem je dan het vieruurtje af? In de werkelijkheid verloopt niet alles zwart (1) â wit (0), het is niet altijd zus of zo. Als je 4 tekorten hebt op je rapport is de kans groot dat je mama boos is, tenzij ze weet dat je heel erg je best hebt gedaan. In de echte wereld wegen we voortdurend af, volgen we niet altijd stricte regels, werken we volgens waarschijnlijkheden en statistische kansen.
Heel wat nieuwe NLP-systemen zouden zich gaan baseren op zulke statistische modellen. Die ârevolutieâ binnen de NLP-wereld was ook een gevolg van de beperkte rekenkracht van de toenmalige generatie computersystemen. Gokken ging nu eenmaal sneller en makkelijker dan eindeloze reeksen âifâ- en âelseâ-structuren te doorlopen. Ook de taaltheorieën van Noam Chomsky, de Amerikaanse taalkundige, die grammaticale gelijkenissen tussen talen zocht, eerder dan verschillen, vormden een rijke inspiratiebron.
Zulke statistische systemen werken veel beter in het geval van âonverwachte invoerâ van de gebruiker ( vb. sniterklaas i.p.v. Sinterklaas). In de echte wereld zijn afwijkingen en fouten immers niet ongewoon, integendeel. Vooral op het vlak van âvertalingenâ bieden de statistische technieken succes. Veel vertaalprogramma's die gebaseerd waren (en soms nog zijn) op woordenlijsten (een soort vertalende woordenboeken) liepen al snel tegen hun grenzen aan. Je kan immers geen zinnen vertalen door de individuele woorden te vertalen, maar door kleine brokjes data te vertalen en hieruit ook te âlerenâ. Statistische systemen zijn echter ook niet heiligmakend (denk aan Google Translate). Recent ligt de focus op een combinatie van beide technieken: de âharde regeltjesâ-weg en de statistische techniek.
Het mag duidelijk zijn dat we ondanks het aanvankelijke optimisme in de jaren 1960 nog een hele weg moeten afleggen vooraleer machines menselijke talen begrijpen en er mee kunnen communiceren. Toch staan de ontwikkelingen niet stil. Bereikt de machine dan echt âkunstmatige intelligentieâ zoals Alan Turing stelde? Vreemd genoeg verandert de betekenis van AI (arti f i c ial intelligence)bij elke nieuwe vooruitgang. Zo werd âschakenâ lange tijd als het toppunt van menselijke intelligentie gezien. Toen de IBM-computer Deep Bluede wereldkampioen schaken Garry Kasparov versloeg, verloor schaken plots veel van zijn allure. De volgende uitdaging kwam er aan: computers zouden nooit creatief kunnen antwoorden op âopenâ vraagstellingen. In 2010 ging IBM's supercomputer Watsonde uitdaging aan en won: hij versloeg met glans de âall-time-greatest human Jeopardy champions, Ken Jennings en Brad Rutterâ 1 . De Jeopardyquiz stelt open vragen over alle domeinen van de menselijke cultuur. De vragen bevatten tal van woordspelingen en hints, maar zelden een duidelijke vraagstelling.
Op tal van terreinen die vroeger als uniek voor de menselijke intelligentie werden gezien, steekt de machine zijn menselijke tegenspeler voorbij. Machines zullen nooit gevoelens hebben of bewustzijn. Maar wat betekent dit precies?
De hond slaapt in zijn mandje. Jacky is heel erg lief. Als ik thuis kom, komt hij al kwispelstaartend naar me toegelopen. Waar blijft hij vandaag? Weet jij het? Ik ben zo bang dat hij weggelopen is.
Als menselijke lezer snap je meteen waarover dit korte tekstje gaat. Hoe kunnen we een machine leren om deze tekst te begrijpen? Tussen mens en machine is er in dit geval al meteen een immens verschil. Een kind leert al snel een visueel beeld van een hond te koppelen aan het begrip âhondâ en de bijhorende geluiden. Denk maar aan de mama's en de papa's die vragen: âEn, hoe doetde hond? Nee, niet miauw.â Het taalmechanismein het hoofd van het kind koppelt aan de hond bepaalde acties zoals blaffen, lopen, kwispelstaarten, maar ook onderdelen zoals staart, poten, tong... Een heel kader, onderdeel van de âwereldontologieâ in het hoofd van het kind. Maar hoe vertalenwe die taalverwerking naar een computer? Oeps, dat is wat anders.
Laat ons eerst eens de tekst scheiden in zijn onderdelen: zinnen ( sentence breaking). Dat kan eenvoudig door te zoeken naar leestekens zoals punten, vraagtekens of uitroeptekens. Dit werkt perfect voor heel wat talen, maar niet voor pakweg Arabisch, Chinees of Japans, want daar is het gebruik van leestekens onbekend. Vervolgens kunnen we de zinnen splitsen in hun diverse woorden ( word segmentation), maar dat werkt al evenmin voor de genoemde talen: Arabisch kent bijvoorbeeld geen door spaties onderscheiden woorden. Daar bepaalt het uitzicht van een bepaald karakter (letter) of het gaat om het begin, het midden of het einde van een woord.
Zinnen bepalen of ze iets meedelen of eerder iets vragen (het vraagteken), en vragenop hun beurt kunnen open of gesloten (ja of neen, if of else, 1 of 0) zijn. De soort zinnen wordt bepaald door de âdiscourse analysisâ. De machine kijkt vervolgens naar de individuele woorden en probeert die te herleiden tot hun basis of stam in een proces dat âstemmingâ en âmorphological segmentationâ heet. In een taal als het Engels is dit een relatief eenvoudig proces:
openis de âstamâ van open, opens, opening, opened...
In talen zoals het Turks is dit een uiterst moeizame techniek. De stam is niet noodzakelijk hetzelfde als de morfologische âwortelâ van het woord. Meestal volstaat het dat verwante woorden dezelfde stam bevatten. Heel wat zoekmachines behandelen woorden met dezelfde stam als synoniemen om de zoekterm enigszins uit te breiden (conflatie). Googlegebruikt âstemmingâ sinds 2003. Voordien zou de zoekterm âvisâ niet âvissenâ of âgevistâ opgeleverd hebben.
Dit leidt soms tot foute resultaten. De machine kan teveel resultaten leveren (overstemming) zoals wanneer je âuniversiteitâ zoekt en ook âuniversumâ krijgt. In dit geval behandelt de machine beide woorden door hun gemeenschappelijke stam als synoniemen. In andere gevallen krijg je te weinig zoekresultaten (understemming).
Bij woorden zoekt het NLP-systeem niet alleen naar de stam, maar bovendien ook naar de woordsoort: gaat het om een adjectief of een zelfstandig naamwoord? Bovendien kunnen zelfstandige naamwoorden ook eigennamen zijn.
Jackyis een hond.
Deze techniek van ânamed entity recognitionâ werkt simpelweg door naar hoofdletters te kijken. Maar ook dit levert problemen op. Bij het begin van een zin schrijf je steevast een hoofdletter. In het Duits krijgen dan weer alle naamwoorden een hoofdletter.
Jackyist ein Hund.
En in het Engels schrijf je ook een hoofdletter als je het over jezelf hebt:
I, Iwanna be your dog.
De woordsoort wordt vaak bijgehouden in een soort lexicon, een soort lijst waarin op basis van de stam en eventuele voor- en achtervoegsels de woordsoort wordt bepaald ( Part-of-speech tagging). Maar eenvoudig is dit niet. Immers, afhankelijk van de zin kan een woord iets compleet anders betekenen:
Ik speel met de balop het bal.
Je merkt het al. De betekenis zit niet in het woord alleen, maar ook in zijn relatie met andere woorden: homoniemen (w ord sense disambiguation). De volgende zin klinkt afhankelijk van tegen wie (je docent) of wat (een eik) je het zegt helemaal anders, maar een NLP-systeem heeft het er moeilijk mee:
Je bent een eikel.
Via de techniek van â n atural language understandingâ probeert een NLP-systeem logica te vinden in korte fragmenten tekst. Welke adjectieven horen bij zelfstandige naamwoorden ( conference resolution)? Wat zijn de onderlinge relaties tussen objecten in een zin ( r elationship extraction)?
Op die manier probeert een NLP-systeem stilaan de zin te âparsenâ, een stamboom te maken van een zin en tenslotte van het hele verhaal.
âJe bent een eikel,âzei ik tegen de directeur .Ik was woedend.Hij werd door mijn uitspraak eveneens razend.
Deze zin verklapt hoe beide partijen zich voelen. Een NLP-systeem kan op basis van de betekenis van woorden en de frequentie waarmee ze voorkomen, raden wat het gevoel is dat uit een tekst spreekt: sentiment analysis . Je kan het zelf uittesten op https://semantria.com/.
Fouten laten herkennen door een machine vraagt geen âhogereâ intelligentie.
Een basisvoorbeeld van âtokenizationâ: van elk woord wordt bepaald of het alfabetisch, numeriek of symbolisch is:
Een voorbeeld van âtaggingâ waarbij van elk woord de woordsoort wordt opgegeven op basis van een âlexiconâ (een woordenlijst):
Tekstbegrip kan dan voor digitale systemen nog relatief moeilijk zijn, toch zijn steeds meer artikels niet meer door mensen geschreven. Google kocht Jetpac, een app die op basis van image recognition-algoritmes automatisch stadsgidsen genereert. Associated Press laat duizenden artikels schrijven door robotschrijvers. Betekent dit dat het einde van de âmenselijke journalistâ in zicht is? 1
Het onderstaande artikel werd door een robotjournalist geschreven:
Aerie Pharmaceuticals Inc. (AERI) on Tuesday reported a loss of $13.1 million in its third quarter. The Research Triangle Park, North Carolina-based company said it had a loss of 54 cents per share. Losses, adjusted for stock option expense, came to 44 cents per share.
Het artikel voldoet aan de vereisten voor dit soort artikels: het is correct en gedetailleerd. Uiteraard moet je je bij een robotjournalist niet een humanoïde robot voorstellen die op een toetsenbord teksten zit in te tikken. Het gaat om een stuk software dat ânatuurlijke taalâ produceert. Auteur van dienst is in dit geval WordSmithvan de softwareproducent Automated Insights. In 2013 produceerde WordSmith wereldwijd 300 miljoen nieuwsverslagen voor diverse klanten, meer dan alle âmenselijkeâ journalisten samen en vooral veel goedkoper...
Volgens Automated Insightskomen de jobs van echte journalisten niet in gevaar:
âWeâre producing articles that never would have existed in the first place,â he says. âAP was doing 300 corporate-earnings stories per quarter; theyâre now doing about 4,440. So 4,100 of these stories would not exist without Wordsmith.â
âThe computer handles the who, what, where and when, and humans are freed up to ask why and how.â
De LA Times zet Quakebot in om geautomatiseerd artikels af te leveren op basis van data van de US Geological Survey (aarbevingen). Inleving, gevoel, medelevenâ¦. zijn vreemd bij dit soort artikels, maar dat is voor "objectieve" verslaggeving ook niet nodig. âCreatief schrijven" ligt voorlopig nog buiten de mogelijkheden, want de algoritmes voeden zich met gestandaardiseerde informatie, een beetje te vergelijken met gestructureerde data in een rekenbladprogramma. Een van de mogelijke pistes om meer menselijke "warmte" in een tekst te steken is door de data aan te vullen met informatie geleverd door sensoren. Shazam is een bekend voorbeeld van een stuk software dat op basis van geluidsherkenning over 'semi-'menselijke intelligentie lijkt te beschikken. Googles Jetpac gaat in Instagramafbeeldingen op zoek naar "tags" die verwijzen naar menselijke ervaringen en cultuur. Op die manier zoekt en vindt Jetpac de leukste of hipste plaatsen.
Simon Colton is professor in "computational creativity" aan de Universiteit van Londen. Hij begeleidt het "What-If Machine"-project, een initiatief van de EU om de grenzen van softwarematige creativiteit af te tasten. Hij vertelt over die pogingen:
âTo me these projects [such as Wordsmith] are straightforward data visualisations. (â¦) Instead of pie charts and graphs they do words, and they miss various aspects needed for a good read. I tell people not to worry about their creative jobs being threatened by automation because of what I call âthe humanity gapâ. Even if software was good at wit, humour and writing style, it would not be human. If you want human insight, youâre not going to get it from a computer any time soon.â
Vaak hoor je dat Wikipedia-informatie onbetrouwbaar is. Nochtans zijn een massa artikels niet meer door menselijke auteurs afgeleverd maar door software-algoritmes. De meest bekende Wikibot luistert naar de naam Lsjbot, geprogrammeerd door de Zweed Sverker Johansson. Lsjbot schraapt informatie van betrouwbare bronnen en schrijft korte artikels over onderwerpen gerelateerd met dieren. Per dag levert de bot ongeveer 10 000 artikels af. In totaal zouden ongeveer 8.5% van de artikels van de (Zweedse) Wikipedia geschreven zijn door Lsjbot.
Wikipedia zette voor het eerst een bot in in 2002. Die "Rambot" leverde per dag duizenden artikels op over zo wat elk(e) dorp, stad of staat van de Verenigde Staten en ook van een aantal andere landen. Een robot onder de gepaste naam Asteroids schraapte data van de NASA en leverde artikels over⦠asteroïden. Op dit moment zijn er meer dan duizend verschillende Wikibots aan het werk: ze verbeteren teksten en tegenstrijdigheden⦠De meest actieve is Cydebot die meer dan 4.5 miljoen aanpassingen aanbracht. 2
Toch getuigt de techniek voor het geautomatiseerd schrijven van artikels niet altijd van âkunstmatige intelligentieâ. Quakebot gebruikt bijvoorbeeld door mensen opgestelde sjablonen en vult die met vooraf verzamelde en gestructureerd bewaarde data over aardbevingen. Het eindresultaat klinkt als een door mensen geschreven artikel, en dat is het voor een groot deel natuurlijk ook. Maar de robot doet in wezen niet veel meer dan het vullen van sjablonen met gestructureerde data. Andere ontwikkelaars, zoals Narrative Science proberen robotjournalisme naar een ander niveau te tillen. Zij pogen de software zelf te laten uitmaken waarover de data gaan en op basis daarvan âcontentâ te laten genereren. De software beslist in dit geval zelf hoe de inhoud moet klinken.
In het volgende hoofdstuk behandelen we OCR, een techniek om een gescande of gekopieerde tekst (uit afbeeldingen dus) te converteren naar bewerkbare tekst. Dat is relatief gezien â
peanutsâ in vergelijking met NLP.
Vooraleer machines vlekkeloos in menselijke talen kunnen communiceren, is er nog een hele weg af te leggen. Het draait niet enkel om de semantiek.In de Studio 100-reeks ROX praat de gelijknamige auto vlekkeloos met de andere (menselijke) personages. Hij herkent en interpreteert hun vragen en antwoorden en reageert er vaak laconiek op. Onze vriend âROXâ combineert het beste op het vlak van NLP met speech recognition, speech segmentationen speech processingen als kers op de taart natural language generation.
Het verstaan van gesproken taal (speech recognition) is nog een aardig stuk moeilijker dan het lezen of interpreteren van gedrukte tekst omdat er in gesproken tekst nauwelijks pauzes zijn tussen woorden. Ook letters vloeien onhoorbaar in elkaar over. Het verdelen van een uitspraakin afzonderlijke woorden (speech segmentation) is vreselijk moeilijk te programmeren. Natural language generation, het genereren van taal in geluidsvorm, is daarentegen al aardig ingeburgerd in bijvoorbeeld GPS-systemen. De software kan in dat geval gebruik maken van vooraf opgenomen geluid (afzonderlijke woorden of zinnen) dat het tot de gewenste zinnen samenvoegt. Dat is echter nog heel wat anders dan het kunstmatig âtoon per toonâ genereren van spraak (speech synthesis).
In
machine translationkomen alle toeters en bellen van NLP-systemen en
natural language generationsamen. Zinvolle vertalingen laten gebeuren door een machine is dus allesbehalve evident. Het vraagt niet alleen begrip van beide talen, maar ook het betekenisvol begrijpen en converteren van het ene bekenissysteem (taal) naar het andere (een andere taal). Een voorbeeld: In het Chinees plaatst een spreker geen âtijdâ in zijn zin. Je kan dus niet aan de persoonsvorm zien wanneer de actie zich heeft afgespeeld. Tijd heeft in het Chinees geen belang wanneer je schrijft of spreekt, een volledig andere manier van âdenkenâ dan sprekers van Indo-Europese talen. Allesbehalve eenvoudig dus om te vertalen van pakweg het Chinees naar het Nederlands of omgekeerd. Denk dus zeker nog eens na wanneer mensen spotten met de vertalingen van bijvoorbeeld
Google Translate.
Kris Merckx, 2015.
âRISE OF THE ROBOT JOURNALISTâ, ( http://www.slow-journalism.com/rise-of-the-robot-journalist), Geraadpleegd op 19 oktober 2015.
DUBE, R., "Could programs live Wiki bot ever produce all internet content?", (http://www.makeuseof.com/tag/could-wiki-bot-produce-all-content/), 2014, Geraadpleegd op 19 oktober 2015.
"Computer denkt voor het eerst als mens in Turing Testâ, http://www.automatiseringgids.nl/nieuws/2014/24/computer-denkt-voor-het-eerst-als-mens-in-turing-test, Geraadpleegd op 23 september 2014.
Bostrom, N. Superintelligence. Paths, dangers, strategies, Oxford, 2014.
De Antwerpse wereldtentoonstelling van 1894 als ambigu spektakel van de moderniteitIn de film The Matrix komt het hoofdpersonage vrij snel te weten dat de wereld waarin hij leeft niet echt is. Alles en iedereen blijkt gesimuleerd door een gigantische machine die de levensenergie van mensen benut als een soort serieel geschakelde biologische batterij. De menselijke ervaringen blijken het resultaat van ingenieuze software die data invoert in de hersenen van de miljoenen aan de machine gekoppelde mensen. De Britse computerwetenschapper Nick Bostrom heeft die simulatiehypothese op levensvatbaarheid getest. Hij heeft een reeks voorwaarden uitgeschreven om na te gaan of zo'n digitale onderdompeling inderdaad mogelijk is of niet reeds het geval is. Immersieve technieken zijn in de digitale wereld alomtegenwoordig.
1
Computersimulaties, 3D-games, virtual reality, augmented reality, MMORPG's⦠gelden als de belangrijkste vormen van immersieve technieken waarbij de grenzen tussen de werkelijkheid en de digitale representatie vervagen.
2
In het artikel
A
historical
comparison
between
world
exhibitions
and
the
webvergelijkt Berteke Waaldijk
3
de overeenkomsten tussen wereldtentoonstellingen in de negentiende eeuw en digitale representaties op het web en in games. Volgens Waaldijk schakel(d)en de bezoekers in beide immersieve omgevingen voortdurend heen en weer tussen immersie en persoonlijke controle. De keuzevrijheid van de bezoeker staat centraal in deze visie. In hun artikel over de Antwerpse wereldtentoonstelling van 1894 benadrukken Bram Van Oostveldt en Stijn Bussels het
spanningsveld
tussen
vervreemding
en
spektake
l.
4
Vanuit dit standpunt heeft de â
moderniteit
iedere
vorm
van
authentiek
leven
vervangen
door
een
constante
stroom
van
beeldenâ.
5
Volgens de klassieke marxistische geschiedschrijving is vervreemding een proces waarbij de mens geen invloed of controle kan uitoefenen op de (of op zijn) ontwikkeling. Zo'n proces veronderstelt dat er ooit iets heeft bestaan als een niet-vervreemde toestand, een situatie in het verleden waarin de burger niet vervreemd was van zijn eigen arbeid. De representatie van Oud-Antwerpen toonde die
idealeniet-vervreemde toestand en bood een â
welbehagen
dat
voor
een
belangrijk
deel
(lag)
in
het
verdoezelen
van
negentiende-eeuwse
sociale
spanninge
nâ.
6
De moderniteit was een breukervaring en de continuïteit van tradities die Oud-Antwerpen representeerde, moest de vervreemding ten opzichte van diezelfde tradities bezweren. De tentoonstelling en de diverse representaties verschaften volgens de auteurs aan de bezoekers de illusie dat ze weerstand konden bieden aan het geweld van de moderniteit. Door de strategieën van immersie zouden de bezoekers zich â
volledig
opgenome
nâ wanen â
in
het
gerepresenteerd
eâ.
7
Waaldijk treedt die stelling van aliënatie niet bij. Vervreemding veronderstelt immers een ontkoppeling van een oorspronkelijke essentie. De overeenkomsten tussen de vormen van immersie bij wereldtentoonstellingen en bij moderne digitale technieken doen nog meer vragen rijzen over het concept van vervreemding dat Van Oostveldt en Bussels aanhangen. Zoals Thomas Decreus het terecht stelt â
als
die
essentie
wegvalt,
verdwijnt
ook
de
maatstaf
om
het
vervreemde
van
het
authentieke
te
onderscheiden
en
worden
beide
noties
nietszeggen
dâ.
8
Een moderne gamer die opgroeit met immersieve speltechnieken en bijvoorbeeld opgaat in een spel over de middeleeuwen, voelt zich niet vervreemd van die
authentieketoestand. Vervreemding veronderstelt immers een vorm van gemis. Het onderdompelen in een representatie blijft bovendien niet beperkt tot de immersie tijdens wereldtentoonstellingen of in digitale omgevingen. Een lezer van een boek kan evenzeer opgaan in het
verhaal. Net zoals in digitale omgevingen waren de bezoekers van wereldtentoonstellingen zowel verbaasd door de technische hoogstandjes als door datgene dat gerepresenteerd werd/wordt. Bezoekers schakelen snel heen en weer tussen immersie (immersion) en afstand nemen (distancing). 9 In een computergame is de bezoeker ondergedompeld in zijn rol van held op zoek naar overwinning en succes. Maar simultaan is hij zich ook bewust van de regels van het spel en de strategieën die de ontwikkelaar heeft geprogrammeerd. Gamers schakelen bliksemsnel heen en weer tussen immersie en distancing. Ze beschikken over vrijheid en controle.
De geschiedkundige vergelijking tussen het web en wereldtentoonstellingen maakt het mogelijk een beter inzicht te krijgen in de relatie tussen beide bewustzijnsvormen.
10
Websitebezoekers volgen niet slaafs de commerciële belangen van de ondernemers achter de toepassingen. Hyperlinks maken het mogelijk voortdurend keuzes te maken, afstand te nemen. Volgens Waaldijk beschikte de bezoeker van een wereldtentoonstelling net zoals een hedendaagse websitebezoeker over de vrijheid om te kiezen tussen wat hij (en ook
zijzoals meteen blijkt) zelf belangrijk vond.
Volgens Hobsbawm waren wereldtentoonstellingen een van de eerste vormen van massatoerisme.
11
Anders dan bij een lm of theatervoorstelling was een bezoek aan een wereldtentoonstelling geen lineaire ervaring. De bezoeker kon schakelen tussen de meerdere representaties, maakte zijn eigen keuzes net zoals bij hypertekst op het web. Waaldijk stelt dat bezoekers van wereldtentoonstellingen dankbaar en veelvuldig van die vrijheid gebruik maakten.
12
Ze gaven anderen advies bij het maken van hun keuze. Het doel was niet enkel de bezoeker onder te dompelen. Minstens even belangrijk waren puur vermaak en zelfs educatie. Commercie was een essentieel onderdeel van een wereldtentoonstelling, net zoals dat nu het geval is bij websites, maar was niet de enige dimensie. De gebruikers schakelden heen en weer tussen hun rol van
vrijeburger en die van
vrije
consumen
t. Op een wereldtentoonstelling kreeg een bezoeker een beeld van waar zijn producten vandaan kwamen. Lauren Rabinovitz ziet wereldtentoonstellingen als de eerste publieke plaatsen waar vrouwen konden kiezen, kijken en inspecteren. De nieuwe rol van de vrouw als consument in de entertainmentindustrie vormde op die manier een cruciale stap in de emancipatie.
13
De overvloed van indrukken wekte verwarring op en dompelde de bezoeker onder, maar toonde paradoxaal genoeg eveneens een gevoel van afstand en controle. De bezoeker had de vrijheid om keuzes te maken. De bezoeker was geen willoos vervreemd element in een gesimuleerde omgeving, maar had een gevoel van controlevrijheid waar hij ook dankbaar gebruik van maakte.
1. BOSTROM, N., S u p e rin t e lli g e n c e : P a t h s , D a n g e r s , S t r a t e g i e s, Oxford, 2014.
2. MERCKX, K., Au g m e n t e d r e a li t y . C o m b in ee r d e v ir t u e l e m e t d e e c h t e w e r e l d, Amsterdam, 2011.
3. WAALDIJK, B. T h e d e s i g n o f w o r l d c i t i z e n s hi p . A hi s t o ri c a l c o m p a r i s o n b e t w ee n w o rl d e x hi b i t i o n s a n d t h e w e b(Digital material. Tracing new media in everyday life and technology), Amsterdam, 2009.
5. ibid., 6.
6. ibid., 16.
7. bid., 6.
8. DECREUS, T., P o s t - m a r x i s m e e n v e r v r ee m d in g .
11. Ibid., 114.
12. Ibid., 115.
13. Ibid., 115.
14. Ibid., 116.
15. Ibid., 117.
BOSTROM, N., S u p e rin t e lli g e n c e : P a t h s , D a n g e r s , S t r a t e g i e s, Oxford, 2014.
DECREUS, T.,
P
o
s
t
-
m
a
r
x
i
s
m
e
e
n
v
e
r
v
r
ee
m
d
in
g
:
ee
n
o
n
m
og
e
lij
k
e
c
o
m
b
in
a
t
i
e
?(https://thomasdecreus.wordpress.com/2013/10/25/post-marxisme-en-vervreemding-een-onmogelijke-combinatie/), Geraadpleegd op 4 januari 2016.
WAALDIJK, B.
T
h
e
d
e
s
i
g
n
o
f
w
o
rl
d
c
i
t
i
z
e
n
s
hi
p
.
A
hi
s
t
o
ri
c
a
l
c
o
m
p
a
ri
s
o
n
b
e
t
w
ee
n
w
o
rl
d
e
x
hi
b
i
t
i
o
n
s
a
n
d
t
h
e
w
e
b(Digital material. Tracing new media in everyday life and technology), Amsterdam, 2009.
Een computer kan met behulp van software een heleboel taken automatiseren om de mens werk uit handen te nemen en vooral de benodigde (werk)tijd te verkorten. Toch beseffen velen nog steeds niet hoe ze dat precies moeten doen. De zoek-en-vervangopdracht in een tekstverwerkingsprogramma is daar een simpel voorbeeld van. In heel wat software kunnen steeds weerkerende taken met behulp van zogenaamde macroâs geautomatiseerd worden. Je voert een aantal taken uit terwijl de computer de uitgevoerde opdrachten stapsgewijs registreert. Nadien kan hij zelfstandig die taak herhalen. De lijst met instructies is vastgelegd in het geheugen van de computer. In automaten zitten de instructies eveneens in de machine.
Tijdens mijn lessen steek ik mijn bewondering voor Leonardo da Vinciniet onder stoelen of banken. Elke kans die zich voordoet om het over hem te hebben neem ik te baat. Iedereen kent Leonardo, al was het maar omdat hij de beroemde Mona Lisa heeft geschilderd.
Leonardo da Vinci was niet alleen schilder, maar ook ingenieur en beeldhouwer. Hij las gretig de vertalingen van Heron en Vitruvius, en bestudeerde de verschillende onderdelen van de machines. Hij noemde ze de âelementenâ of âorganenâ van de machines. Door die onderdelen op allerlei manieren te combineren kon je in zijn ogen een oneindig aantal machines bedenken en bouwen. Wanneer je de werken van Da Vinci bekijkt, doen ze vaak denken aan de handleidingen uit dozen Lego® Technics. In zijn teksten beschreef hij welke soorten schroeven, tandwielen, vliegwielen, kogellagers, kettingen, veren, katrollen enzovoort er bestaan en hoe je ze maakt. Hij voorzag zijn teksten van uitgebreide technische tekeningen in perspectief. Zelf ontwierp hij een hele reeks machines: oorlogstuig zoals mortieren en tanks, baggerschepen, vliegtuigen, een helikopter, een duikpak, een hydraulische zaag ... Hij observeerde ook nauwlettend de vlucht van vogels en de werking van hun vleugels en veren. Leonardo ontwierp op basis daarvan tal van (zweef)vliegtuigen, die hij zelfs voorzag van schokdempers om bij de landing het âvliegtuigâ niet te beschadigen. Velen denken dat hij prototypes van die geniale vondsten zelf heeft uitgetest. Toch is het grootste deel van zijn uitvindingen nooit in praktijk gebracht. Een van de meest verbazingwekkende afbeeldingen uit de beschrijvingen van Leonardo da Vinci is die van een fiets. De fiets zoals we hem nu kennen, werd pas uitgevonden aan het einde van de 19e eeuw.
In de Codex Atlanticus, een bundel tekeningen en teksten van Leonardo die vervaardigd zijn tussen 1479 en 1519, âstaatâ echter een tekening van een fiets met spaken, tandwiel, ketting, stuur enzovoort. Dit zou betekenen dat de fiets niet in Frankrijk of Duitsland werd uitgevonden, maar driehonderd jaar eerder in ItalieÌ, door de uitvinder aller uitvinders: Leonardo da Vinci. Recent onderzoek zou echter aantonen dat de fiets helemaal niet door Leonardo of een van zijn leerlingen werd getekend, maar pas veel later bij de restauratie van de âtekstenâ is toegevoegd. Oorspronkelijk stonden er wel een aantal onderdelen van een voertuig dat sterk op een fiets lijkt, maar geen frame. Het is niet duidelijk wie de vervalsing heeft gemaakt. Sommige Leonardo- specialisten blijven echter vast geloven in de echtheid van het ontwerp.
In 1550 schreef Giorgio Vasari (1511â1574) in zijn boek over het leven van de belangrijkste Italiaanse kunstenaars:
âToen Leonardo da Vinci in Milaan was, kwam de koning van Frankrijk op bezoek. Hij vroeg hem iets speciaals te doen. Da Vinci ging aan de slag en presenteerde hem een leeuw die een paar stapjes zette en zijn borstkas opende, waar tal van lelies uit tevoorschijn kwamen.â
De Amerikaanse robotexpert Mark Rosheim bestudeerde de Codex Atlanticus van Da Vinci in de hoop sporen te vinden van die robotleeuw. Hij is ervan overtuigd dat Da Vinci de leeuw op een mechanisch programmeerbaar wagentje had geiÌnstalleerd. Een veermechanisme deed wielen draaien, die op hun beurt kleinere wielen in beweging zetten. Die stuurden houten armen aan, waaraan een soort schaarmechanisme was bevestigd. Door de armen volgens een vastgelegd plan te laten bewegen kon het karretje rijden en ook draaien.
Leonardo was niet de enige die vruchtbaar gebruikmaakte van de kennis van automaten die via vertalingen van klassieke en hellenistische werken doorsijpelde. AbuÌ al-âIz Ibn IsmaÌâiÌl ibn al-RazaÌz al-JazariÌof kortweg Al-Jazari voor de vrienden (1136â1206) werd genoemd naar zijn geboorteplaats Al-Jazira (tussen Tigris en Eufraat). Hij werkte als astronoom, wetenschapper, wiskundige en ingenieur aan het paleis van Diyarbakır, die heerste over Oost-AnatolieÌ. Over het leven van Al-Jazari is niet veel bekend, maar gelukkig bleef zijn KitaÌb fiÌ maârifat al-hiyal al-handasiyya(Het boek der kennis van ingenieuze mechanische apparaten) bewaard. Het bestaat uit een zestal hoofdstukken die handelen over mechanica en techniek: water- en tijdkaarsen, apparaten die trucs verrichten, hydraulische automaten en meetinstrumenten, fonteinen, muziekautomaten, hijsmachines enzovoort. Al-Jazari was duidelijk op de hoogte van de vondsten en mechanische onderdelen van de hellenistische technici. Hij vermeldde de krukas, het echappement, de waterhijsmachines, de dubbele pomp ... Het is niet altijd duidelijk in welke mate hij zelf aanpassingen heeft aangebracht. In zijn werk vinden we ook beschrijvingen van gesegmenteerde versnellingen, tijdkaarsen en klokken die met gewichten en waterkracht werden aangedreven. Zijn bekende olifantenklok lijkt de voorloper van onze koekoeksklok.
Afbeelding: 18e eeuwse automaat
De eerste die een soortgelijk programmeerbaar systeem inzette voor industrieel gebruik was de Fransman
Joseph Marie Jacquard(1752â1834). Hij ontwierp in 1801 een weefgetouw dat werd aangestuurd door ponskaarten. Hij baseerde zich voor zijn werk op de eerdere uitvindingen van onder anderen
Basile Bouchon, Jacques Vaucanson en Jean Falcon. Basile Bouchon, zoon van een orgelbouwer, bedacht al in 1725 een manier om een weefgetouw aan te sturen met een geperforeerde rol papier. Bouchons vader maakte cilinders met pinnen voor orgels. Om de pinnen op de juiste plaatsen aan te brengen in de cilinder, tekende hij eerst een patroon op een kartonnen plaat. Die plaat draaide hij vervolgens om de cilinder waardoor hij precies wist waar hij de pinnen in de cilinder moest slaan. Basile meende dat het handiger zou zijn de kartonnen platen zelf te gebruiken. Het was Jacquard die het systeem als eerste succesvol wist te implementeren.
Het
ponskaartsysteemzien we in de 19e eeuw ook opduiken in muziekdozen en pianolaâs. Ponskaarten werkten op een vergelijkbare manier als pin- of kamsystemen. In het geval van muziekdozen kon door de gaatjes lucht van een blaasbalg ontsnappen of er konden pinnetjes door schieten die instructies gaven aan de rest van het mechanisme. Bij Jacquard sprongen pinnen op door de openingen in de ponskaarten en lieten het weefgetouw een bepaald patroon weven. Het grootste voordeel van een ponssysteem was dat je veel meer instructies achter elkaar kon laten uitvoeren door de machine. Bij een cilindersysteem met pinnen of kammen was je beperkt door de omtrek van de cilinder. Ponsplaten kon je oprollen of opvouwen en door het mechanisme laten schuiven bij het uitvoeren van het programma. De wevers van Lyon vreesden voor hun werk en verbrandden het weefgetouw in 1808, zo vertelt het verhaal. Blind protest tegen een niet te stuiten innovatie. Maar dit verhaal klopt niet. Van die brand is helemaal geen sprake geweest. Het verhaal duikt voor het eerst op aanvang 19e eeuw. Al snel zag men ook op andere vlakken van de samenleving het nut van een ponskaartsysteem. Je kon op een ponskaart allerlei soorten informatie in gecodeerde vorm opslaan en het geautomatiseerd laten uitlezen. Charles Babbage(1791â 1871) tekende plannen voor een analytische rekenmachine en voorzag de invoer van ponskaarten. Zijn plannen betekenden een serieuze stap voorwaarts in de ontwikkeling van een rekenmachine. Eerder bouwde de Fransman Blaise Pascal (1623â1662) een mechanische rekenmachine, maar die was nooit een succes geworden. Ook de machine van Babbage kwam niet veel verder dan de ontwerptafel.
Kris Merckx - Uit het boek "Niet van gisteren", http://www.nietvangisteren.be
Tijdens deze lessenreeks ontwikkel je het prototype van de interface van een softwareservice. Dat is een mond vol :-). Een interface is de "laag" waarmee een computersysteem communiceert met de "buitenwereld". Dit kan een temperatuursensor of microfoon zijn, maar ook een scherm of muis. In onze lessen ligt de focus op de interactie tussen mens en "machine" (een USER INTERFACE).
De diverse interfaces voor "human machine interaction" komen aan bod. De hele geschiedenis van interfaces passeert de revue: CLI, GUI, NUI, AR, VR...
Je vormt een groep. De lector geeft je een opdracht ( https://www.schoolvoorbeeld.be/nodig/ui-opdrachten.pdf ). Overleg hoe je dit wil aanpassen. Begin met een brainstorm. Zet je ideeën op papier.
Nadat je feedback hebt gekregen van de lectoren, kan je starten met het ontwerpen van de USER INTERFACE voor je applicatie. Hiervoor kan je gebruik maken van Adobe XD. Dat programma kan je gratis downloaden.
Waar moet je rekening mee houden als je een "USER INTERFACE" bouwt? Waar moet je op letten? Storytelling: gebruik herkenbaarheid en storytelling bij een pitch.
Waar moet je rekening mee houden bij UX-design? Bekijk de presentatie op Presentatie "Soorten interfaces & UX-design" én lees zeker het bijhorende hoofdstuk in de cursus (Lees zeker het volledige deel over UI- en UX-design/interfaces in https://www.schoolvoorbeeld.be/nodig/smartboek.pdf).
Film over "huisstijl" en UX-design: heb je nog te goed (uitleg over huisstijlen, lettertypes, logo-ontwerp, kleurpaletten, UX-design...)
Op zoek naar een handige tool voor het bouwen van "mockups" en/of interfaces? Pencil is een gratis en open source tool met een massa mogelijkheden. Adobe XD komt uit de stal van Photoshop. Het heeft een heel uitgebreide toolset voor het bouwen van een interface-prototype en heeft ook heel wat presentatiemogelijkheden.
Installeer Adobe XD en/of Pencil voor het uitvoeren van de opdracht rond interface-ontwerp.
"Pencil is built for the purpose of providing a free and open-source GUI prototyping tool that people can easily install and use to create mockups in popular desktop platforms."
Andere (commerciële) tools:
Mijn persoonlijke website: www.ardeco.be
De website bij het boek Niet van Gisteren: www.nietvangisteren.be
Linkedin: https://www.linkedin.com/in/kris-merckx-3a791b36/
Een overzicht van mijn uitgaven: http://www.schoolvoorbeeld.be/boeken/
Als je programmeert, moet je je de taal van de computer eigen maken... binaire code. Dat is niet evident! Daarom zijn er tussenliggende programmeertalen ontwikkeld die voldoende duidelijk zijn voor de mens, maar ook voor de machine.
Presentatie van deze lesTijdens de lessen gebruiken we de teksteditor Brackets en het FTP-programma Cyberduck.
Een website bouw je in HTML. HTML is geen programmeertaal. Je bepaalt ermee welke onderdelen je webpagina bevat: titels, alinea's... Met HTML kan je ook links leggen naar andere pagina's en bestanden.
Start met HTML
Op een website worden inhoud en opmaak in afzonderlijke bestanden opgeslagen.
Waarom zo ingewikkeld doen?
Wel, het maakt het werk er een pak eenvoudiger op...
Cascading Style Sheets... webpagina's maak je op met een afzonderlijk bestand, een CSS-bestand. Hierin bepaal je hoe de webpagina-elementen er moeten uitzien. Het grootste voordeel is dat al die stijlkenmerken in een apart bestand worden bewaard. Als je dit bestand wijzigt, verandert automatisch de opmaak van alle daaraan gekoppelde webpagina's.
Wie een website publiceert, wil natuurlijk dat zijn site goed gevonden wordt door de zoekmachines. Hoe optimaliseer je je website voor zoekmachines en sociale mediasites?
SEO gaat niet over het manipuleren van de zoekresultaten. Het is het structureren en groeperen van informatie op zoân manier dat het voor de zoekmachines duidelijk is waarover je website gaat. SEO is geen zoekmachine-spam. Het kunstmatig manipuleren van de zoekmachines is niet alleen geen duurzame aanpak, het zal ook niet resulteren in conversies. En dat is uiteindelijk waarover het gaat. (Bron: https://wijs.be/nl/diensten/traffic-en-conversieoptimalisatie/seo)
Het begrip SEO staat voor âSearch Engine Optimizationâ . Het is niet één bepaalde techniek, maar een geheel van manieren om je webpagina's beter toegankelijk te maken voor zoekmachines. De nummer één van de zoekmachines blijft Google. Als je je webpagina's gestructureerd opbouwt, met keurige en semantische HTML, dan zal Google beter begrijpen waarover je pagina gaat.
Zo is een <article> voor Google duidelijker dan wanneer je voor hetzelfde onderdeel een <div>-element zou gebruiken. Het HTML-element article vertelt immers al dat het gaat om een "artikel" (dat kan natuurijk zowel een nieuwsbericht als een winkelartikel zijn).
Een zoekrobot zoekt niet op het moment dat jij iets zoekt op internet. Google stuurt "zoekrobots" uit die voortdurend nieuwe of bestaande webpagina's "lezen" en indexeren. Zoekrobots zijn stukjes software die de HTML-code van webpagina's uitlezen en proberen uit te vissen waarover de inhoud gaat. Met SEO-data kan je het werk van een zoekrobot vergemakkelijken.
Naast het proberen begrijpen van de inhoud van een webpagina, gaat een zoekrobot in de HTML-code ook op zoek naar "links". Als de robot een link vindt, dan zal de zoekrobot ook die link gaan verkennen. Op die manier "indexeert" Google voortdurend het world wide web.
Wanneer jij iets zoekt in Google, dan tovert Google voor jou resultaten op uit die gigantische inhoudstafel die in een enorme databank is opgeslagen. De zoekmachine bouwt op dat moment bliksemsnel een HTML-pagina met (hopelijk relevante) zoekresultaten.
Metatags stop je in het <head>-gedeelte van je webpagina. Belangrijk is vooral het geven van een zinvolle "title" aan je webpagina.
Een foute "title":
<title>Welkom op mijn site</title>
De title vertelt best iets over het onderwerp van je site, over de inhoud van de betrokken pagina, en misschien is het ook zinvol om er de locatie in te vermelden:
<title>Restaurant Belgische Keuken - Parijsstraat Leuven</title>
Een tweede bijzonder belangrijk onderdeel is de "omschrijving/beschrijving". Naast de title komt die "description" in de zoekresultaten van Google terecht. Bekijk het onderstaande voorbeeld. De "blauwe" title is gebaseerde op de <title> van de betrokken webpagina. De "zwarte" tekst die Google toont is (over het algemeen) gebaseerd op de meta-tag "description".
Op https://webcode.tools/meta-tags-generator kan je geautomatiseerd metatags aanmaken voor elk van je webpagina's.
Open Graph is bedacht door Facebook in 2010. Dit werd gedaan om een betere integratie tussen websites en Facebook te bewerkstelligen. In de praktijk kwam het er op neer dat links van websites die gepost werden op Facebook zogenoemde ârich graphsâ konden worden. Een andere uitleg is dat je als website hiermee een zekere mate van controle krijgt op hoe je er op Facebook uit ziet.âMaak geautomatiseerd OG-tags aan voor al je webpagina's op https://webcode.tools/open-graph-generator.
Een voorbeeld. Als iemand een link van een website plaatst in zijn of haar status op Facebook dan verschijnt er automatisch een soort kaartje. Vaak zie je hierin een afbeelding, een titel, een omschrijving en een link. Ook bij LinkedIn, Google+ en Twitter gebeurt dit. Deze gegevens kun je zelf beïnvloeden en min of meer âdicterenâ aan sociale netwerken. Kortom: je kunt het âkaartjeâ zelf invullen.
(Bron: http://www.42bis.nl/2015/02/facebooks-open-graph-wat-het-en-wat-kun-je-er-mee/)
Sociale media gaan niet "actief" op zoek naar webinhouden zoals zoekmachines dit doen. Open Graph-tags zijn echter belangrijk wanneer iemand een webpagina of link deelt op sociale media. Dankzij OG-tags, kan de webontwikkelaar bepalen welke tekstjes, titels en foto's moeten verschijnen, als iemand een webpagina of webinhoud deelt.
Google gooit sites die niet of moeilijk mobiel toegankelijk zijn, achteruit in de zoekresultaten. Je hebt er dus alle belang bij je site "responsive" te maken. Om dit proces te vereenvoudigen, kan je gebruik maken van een CSS-framework dat je het grootste deel van dit werk uit handen neemt.
Tijdens de lessen gebruiken we hiervoor cssbib.css ( https://www.schoolvoorbeeld.be/css/cssbib.css), dat deels gebaseerd is op skeleton.css ( http://getskeleton.com/), maar met een hele reeks uitbreidingen.
Daarnaast moet je een afzonderlijke regel toevoegen aan je webpagina die je site mobiel-gebruiksvriendelijk maakt. Voeg de volgende regel toe aan de <head>-sectie van je pagina:
<meta name="viewport" content="width=device-width, initial-scale=1.0">
Met JSON-LD voeg je gestructureerde gegevens toe aan je pagina. Die informatie is niet zichtbaar voor de eindgebruiker, tenzij hij/zij de broncode van de pagina bestudeert. Zoekmachines zoals Google, begrijpen dankzij JSON-LD echter veel beter waarover de inhoud van je pagina gaat. Uiteraard moeten de JSON-LD-gegevens ook effectief overeenkomen met de werkelijke (zichtbare) inhoud van je pagina.
Een voorbeeld:
<script type="application/ld+json"> {
"@context": "http://schema.org/",
"@type": "Event",
"name": "Rock Werchter", "description": "Het bekendste Belgische rockfestival.",
"startDate": "2018/30/06",
"endDate": "2018/07/04",
"location": {
"@type": "Place",
"name": "Werchter",
"address": {
"streetAddress": "Festivalterrein",
"addressLocality": "Werchter",
"addressRegion": "Vlaams-Brabant"
}
}
} </script>
Maak geautomatiseerd JSON-LD-gegevens aan: https://webcode.tools/json-ld-generator/event
Door bepaalde informatie zoals bijvoorbeeld bedrijfsvermeldingen, beoordelingen, contactgegevens, evenementen, recensies, recepten, reviews, prijsindicaties, productspecificaties enz. met deze standaarden te beschrijven, worden ze gemakkelijker door Google herkend en kunnen deze data als rich snippets verschijnen in de zoekresultaten.
(Bron: https://www.siteoptimo.com/wat-is/microdata/)
Een voorbeeld:
<address itemscope itemtype="http://data-vocabulary.org/Organization">
<span itemprop="name">Nettuts+</span>
Postal Address:
<span itemprop="address" itemscope
itemtype="http://data-vocabulary.org/Address">
<span itemprop="street-address">PO Box 21177</span>,
<span itemprop="locality">Melbourne</span>,
<span itemprop="region">Victoria</span>,
<span itemprop="country-name">Australia</span>.
</span>
<span itemprop="geo" itemscope itemtype="http://www.data-vocabulary.org/Geo/">
Latitude: <span itemprop="latitude">37.49 S </span>
Longitude: <span itemprop="longitude">144.58 E</span>
</span>
Phone: <span itemprop="tel">+61 (0) 3 9023 0074</span>
<a href="http://net.tutsplus.com/" itemprop="url">Nettuts+ | Web development tutorials, from beginner to advanced.</a>.
</address>
Maak geautomatiseerd microdata aan op https://webcode.tools/microdata-generator
Een aantal belangrijke tips:
- Vervang je links niet door aanklikbare afbeeldingen.
- Voeg "title" en "alt"-attributen toe aan je afbeeldingen.
- Geef je pagina's of "virtuele" mappen duidelijke namen.
- Gebruik HTML5-elementen.
Zoekrobots zoals Google gebruiken AI (lees: patroonherkenning) om de inhoud van je teksten, foto's en video's... te "begrijpen". Als je wil uittesten wat Google allemaal kan op het vlak van "beeldherkenning", klik dan eens op de volgende link
Werkend voorbeeld: https://www.schoolvoorbeeld.be/websites/plugins/newspaper.php
Met de NewsPaper-plugin kan je een reeks artikels verbergen en via een selectielijst (een vervolgkeuzelijst) die weer één voor één lezen. Dat maakt de inhoud van je pagina's minder zwaar. Het opsplitsen en verbergen van de informatie op je webpagina, maakt het voor bezoekers eveneens gebruiksvriendelijker.
<script src="https://code.jquery.com/jquery-3.2.1.min.js" integrity="sha256-hwg4gsxgFZhOsEEamdOYGBf13FyQuiTwlAQgxVSNgt4=" crossorigin="anonymous"></script>
Plak deze link onder die van jQuery, allebei in de <head>-sectie van de pagina waarin je het effect wil bereiken.
<script src="https://www.schoolvoorbeeld.be/js/jslibnew.js?v7"></script>
Maak in je HTML-pagina een onderdeel dat een aantal <article>-elementen bevat.
Bijvoorbeeld:
<section class="newspaper">
<article>
<h3>Titel van dit artikel</h3>
<p>Inhoud van dit artikel.
</article>
<article>
<h3>Titel van dit artikel</h3>
<p>Inhoud van dit artikel.
</article>
<article>
<h3>Titel van dit artikel</h3>
<p>Inhoud van dit artikel.
</article>
</section>
We hebben aan het element de CSS-klasse "newspaper" gegeven, maar dat mag je uiteraard zelf beslissen. Het hoeft ook geen <section>-element te zijn, het mag ook gewoon gaan om een <div>.
<script>
$(document).ready(function(){
$(".newspaper").newspaper();
});
</script>
Klaar is kees... Je kan alles natuurlijk ook nog wat "vormgeven" met CSS.
Standaard gaat de plugin op zoek naar <article>-elementen. Wil je andere elementen zichtbaar en onzichtbaar maken, dan moet je de opties van de plugin wijzigen. Standaard neemt de plugin het eerste <h3>-element dat hij in het <article> vindt, als titel voor de selectielijst. Ook dat kan je wijzigen. Als de plugin geen titel vindt, dan nummert hij de lijst.
<script>
$(document).ready(function(){
$(".newspaper").newspaper({
element: "div",
title:"h1",
text: "Kies het gewenste artikel"
});
});
</script>
| Optie | Doel | Waarde | Standaard |
element |
Standaard zoekt de plugin <article>-elementen. Je kan dit vervangen door een ander element. | p, div, li... | article |
title |
Standaard zoekt de plugin naar de eerste <h3> in elk "artikel". Je kan die waarde veranderen. | h1, h2, h4... | h3 |
text |
De titel van de vervolgkeuzelijst. | Een tekst tussen aanhalingstekens. | "Kies een artikel" |
1. Link het javascriptbestand.
Absolute pad:
icarosp/ui/crowl.modals/jq.crowl.modal.js
2. Voeg een link toe waarmee je het venster wil openen:
<a href="inhoudvenster.html" class="OpenWin">Open</a>
Andere mogelijkheden:
<p data-content="Deze inhoud moet in het venster getoond worden" class="OpenWin">Inhoud van de alinea waarop kan geklikt worden.</p>
3. Voeg het javascript toe:
$(".OpenWin").jqCrowlModal();
4. Bepaal het uitzicht van het venster:
$(".OpenWin").jqCrowlModal({
width:"80vw",
height:"80vh",
background:"white",
animation:"bigEntrance",
roundedCorners: "4px",
shadow:true
});
Voor alle animatieklassen:
Animatie-effecten in Crowl
5. Bepaal wanneer het venster moet opengaan:
$(".OpenWin").jqCrowlModal({
events: "click contextmenu"
});Standaard opent een venster bij een klik of rechtsklik op het element. Je kan meerdere events tegelijk opnemen, gescheiden door een spatie.
6. Bepaal waar het venster moet opengaan:
$(".OpenWin").jqCrowlModal({
location: "centercenter"
});topleft, topcenter, topright
centerleft, centercenter, centerright
bottomleft, bottomcenter, bottomright
mouseleft, mousetop, mouseright, mousebottom
elementleft, elementtop, elementright, elementbottom
* en **:
de optie bubble:true zal een pijtlje in het venster weergeven, afhankelijk van de positie van het venster.
7. Knoppen
$(".OpenWin").jqCrowlModal({
buttons: {
closemodal: false /*default*/,
submit: true /*default*/,
cancel: false /*default*/
},
buttontext: {
submit: "OK",
cancel: "ANNULEER"
},
onSubmit: function(){
/*Uw code*/
},
onCancel: function(){
/*Uw code*/
},
onClose: function(){
/*Uw code*/
}
});
Tijdens een eerste reeks lessen leren de studenten dat het begrip "computer" in onze tijd een zeer ruim begrip is. Het beperkt zich niet tot de klassieke "desktop" en "laptop", zelfs niet tot de tablet of de smartphone. Stilaan is heel onze omgeving doordrenkt van "smart" toestellen.
De studenten leren waar we overal kleine computers in aantreffen: televisie, auto, domotica...De studenten gaan aan de slag met een Arduino-ontwikkelbord. Het is de bedoeling dat ze op basis een stuk bestaande C-code (C is nog steeds de belangrijkste programmeertaal ter wereld) aanpassen en een temperatuursensor bouwen. Daarnaast bouwen ze een toepassing met een ledlicht waarmee ze in "morsecode" een signaal moeten uitsturen.
De studenten verwerken zelf hun theorie (hoofdstuk in de handleiding) tijdens het uitvoeren van de groepsopdracht.
De uitleg van de opdracht vind je hier: https://www.schoolvoorbeeld.be/Multimedia/4-Interfaces
De studenten krijgen instructies over het bouwen van een huisstijl voor een interface, het ontwikkelen van een logo en kleurschema, over het bouwen van een "goede" presentatie.
Ze presenteren hun "app" in de aula in aanwezigheid van een
extern jurylid (Dirk Remmerie van communicatiebureau Xpair Communication)
De studenten beoordelen elkaar via een door de lector gebouwd formulier: https://www.schoolvoorbeeld.be/Multimedia/Feedback-interface
Op die pagina vind je ook de werkstukken van de studenten.
Korte presentatie en hoofdstuk in de handleiding.
Samen met de lector (via beamer) bouwen de studenten hun eerste programmacode in de programmeertaal Processing (een afgeleide van JAVA). De broncode van deze les is online beschikbaar op https://www.schoolvoorbeeld.be/Multimedia/Processing
De bedoeling is dat de studenten minimaal 2 aanpassingen/uibreidingen aan de code toevoegen. Hiervoor kunnen ze een beroep doen op de lector of op online informatie.
Multimedia, grafische vormgeving, film, informatie, IT, ICT, videobewerking, videomontage, animatie, beeldbewerking, compositing, huisstijlen, webdesign, programmeren, visualiseren... het komt allemaal wel aan bod.
De materie is echter zo ruim dat we onmogelijk alles kunnen aanbieden en aanleren. Bovendien zijn de mogelijkheden enorm uitgebreid. Je kan niet zeggen: "Nu kan ik het". Je zal blijvend moeten evolueren en studeren...
Naast de theorie- en praktijklessen en de groepsopdrachten... volg je ook een individueel traject. Hieronder vind je uitgestippeld wat er van je verwacht wordt.
https://www.schoolvoorbeeld.be/Multimedia/Progressietraject
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Deze nieuwe versie van de film is veel beter dan de eerste versie. De geluidsopname (stem) kon beter, maar de uitleg is duidelijk en ok.
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Leuk in beeld gebracht. Vooral ook fijn dat jullie zelf de technieken uitgeprobeerd hebben. De inleiding vind ik wat lang duren, maar is op zich al een animatievorm. Enkel de uitleg over tekenfilm loopt wat mank.
Een flipbook werkt niet zoals een tekenfilm. Bij een tekenfilm tekenen de animatoren niet alles in één laag.
Alle onderdelen van een "scene" worden afzonderlijk getekend.Een flipbook is in veel gevallen een stukje tekenfilm dat werd afgedrukt.
ONTBREEKT: hoe worden tekenfilms gemaakt. Het concept van "lagen".
Bekijk de
presentatie:
Deel 6: Film en animatie. Studeer ook de uitleg in het
handboek:
http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Zeer sterk. Visualisaties, uitleg... zeer goed. Jullie leggen subliem uit hoe een OS werkt en wat het is.
Kleine bemerking: het OS van Apple heet niet "Apple", maar "Mac OS X".
ONTBREEKT: Eventueel hadden jullie nog wat over zeer oude/grote OS kunnen spreken zoals UNIX.
Bekijk de
presentatie:
Deel 1: Computerarchitectuur. Studeer ook de uitleg in het
handboek:
http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
LEES ZEKER OOK DE FEEDBACK HIERONDER:
De uitleg over het doel van een interface is ok. Maar toch wel wat bemerkingen .
De animatiefiguurtjes zijn leuk, maar niet functioneel. Wat doen ze in dit filmpje? Een wasmachine heeft inderdaad een interface, maar niet noodzakelijk een elektronische of digitale. Bovendien hebben de toestellen die jullie bij het begin tonen weinig te maken met een NUI of STAG. Jullie gebruiken die termen zonder ze uit te leggen. Het lijkt erop als je het filmpje bekijkt, dat enkel een smartphone een goed voorbeeld is van interfaces.
Jammer dat een van de meest uitgebreide hoofdstukken van het handboek zo'n "magere" behandeling krijgt. Bekijk voor het examen zeker grondig het corresponderende hoofdstuk en deze presentatie Deel 2: Soorten interfaces & UX-designONBREEKT:
Bekijk de
presentatie:
Deel 2: Soorten interfaces & UX-design. Studeer ook de uitleg in het
handboek:
http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
De onderstaande vragen moet je kunnen beantwoorden om uw examen goed te kunnen oplossen. De antwoorden vind je in de cursus. Zorg ervoor dat je volledige antwoorden formuleert en een vlot doorlopend verhaal vertelt. Toon dat je de leerstof begrijpt, geef voorbeelden, wees grondig en volledig.
OPGELET: de uitleg in de presentaties is lang niet voldoende als achtergrond voor je examen. Zorg voor een zinvol begrijpelijk antwoord op alle vragen.
DOWNLOAD DIT OVERZICHT ALS PDF
Computerarchitectuur https://www.schoolvoorbeeld.be/icarosp/home/docs/architectuur.pdf
Embedded/elektronica https://www.schoolvoorbeeld.be/icarosp/home/docs/deel1.pdf
Smart technology https://www.schoolvoorbeeld.be/icarosp/home/docs/bigdata.pdf
Handboek (deel 1) http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen in dit deel?
Begrippen verklaren en uitleggen:
Interfaces: https://www.schoolvoorbeeld.be/icarosp/home/docs/deel2.pdf
Programmeren: https://www.schoolvoorbeeld.be/icarosp/home/files/programmeren.pdf
Handboek (deel 2) http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen na dit deel?
Begrippen verklaren en uitleggen:
Film: Operating systems
Presentatie: https://www.schoolvoorbeeld.be/icarosp/home/docs/bigdata.pdf
Handboek (deel 3): http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen na dit deel?
Begrippen verklaren en uitleggen:
Deel 5: niet te studeren
Film Audio/geluid
Presentatie: https://www.schoolvoorbeeld.be/icarosp/home/files/animatie.pdf
Handboek (deel 3): http://www.schoolvoorbeeld.be/cursusmultimedia.pdf
Wat moet je kennen/kunnen na dit deel?
Begrippen verklaren en uitleggen:
LEES ZEKER OOK DE FEEDBACK HIERONDER:
Jullie leggen uit wat het verschil is tussen digitaal en analoog, maar niet hoe je van analoog naar digitaal gaat. De animatie is niet meer dan een automatische slideshow, maar er zit niet echt animatie in. De kijker moet voortdurend tekst lezen. Jullie gebruiken nergens afbeeldingen om het geheel te verduidelijken. Een zwaar gemiste kans.
Bekijk de presentatie: Deel 1: Digitale en elektronische verwerkingssystemen. Studeer ook de uitleg in het handboek:LEES ZEKER OOK DE FEEDBACK HIERONDER:
Een aantal animaties zijn mooi en de meeste uitleg klopt ook (in grote lijnen). Toch bemerk ik eveneens een aantal minpuntjes.
Presentatie frontend en backend
Frontend en backend? Wat is dat allemaal. Bekijk het onderstaande filmpje.
Een krant is een mooi voorbeeld om uit te leggen hoe een databankgestuurde website nu precies werkt. We gebruiken HLN.be als een voorbeeld.
Elk artikel in deze online krant, bevat een aantal terugkerende elementen. De belangrijkste structuuronderdelen heb ik naast de foto opgesomd.
Bron: https://www.hln.be/de-krant/aannemer-licht-gezinnen-op-voor-honderdduizenden-euro-s~a74fc6fc/
Je zou in een rekenbladprogramma als LibreOffice Calc of MS Excel een lijst kunnen maken met deze gegevens van een "aantal" artikels die je op HLN.be vindt.
Het zou er zo kunnen uitzien:
Een databank is echter veel meer dan enkel maar een rekenblad. In een databank bewaar je gegevens evenzeer in rijen en kolommen. Een databank kan echter hele reeksen tabellen bevatten die je eveneens met elkaar kan koppelen. Het wordt duidelijk in de volgende stap.
Een relationele databank heeft niets te maken met een datingsite. Alhoewel ze voor een datingsite vermoedelijk ook wel een relationele databank zullen gebruiken om de profielen van de gebruikers met elkaar in verbinding te brengen. Ik gebruik nog steeds het voorbeeld van de krant om duidelijk te maken wat een databank nu precies is.
Net zoals in het rekenblad bewaren we de gegevens in een "tabel". Data die "meerdere" keren kunnen voorkomen, zoals de naam van de auteur, nemen we echter niet op. Dit doen we op een "andere manier".
Ik geef Engelstalige veldnamen aan de kolommen. Niet omdat dit moet, maar omdat het wat de gewoonte is. Waarom ik niet gewoon "date" en "time" gebruik, leg ik later nog wel uit. Je merkt dat ik geen "veldnaam" geef aan de eerste en de laatste kolom en dat het veld "author" ontbreekt.
| ... | title | articledate | articletime | cover | content | ... |
| ... | Sinterklaas komt om het leven | 05/12/2018 | 06/12/2018 10:22:10 | images/sint.jpg | Op 5 december viel Sinterklaas van een dak. Hij kwam hierbij om het leven... | ... |
| ... | Trump laat haar kleuren | 03/01/2019 | 04/01/2079 11:10:20 | images/kuif.jpg | Trump gaat voortaan door het leven met bruin haar... | ... |
| ... | ... | ... | ... | ... |
|
... |
Omdat een auteur meerdere artikels kan schrijven, en we van elke auteur eveneens wat informatie willen bewaren (zoals zijn/haar naam, e-mailadres enz.), maken we voor de auteurs een afzonderlijke tabel aan.
Achteraf gaan we de tabel "articles" linken aan de tabel "authors".
| id | name | |
| 1 | Joske Janssens | joske.janssens@leukekrant.be |
| 2 | Louisa Peeters | louisa.peeters@leukekrant.be |
| 3 | Achmed Birandouni | achmed.birandouni@leukekrant.be |
Je merkt dat elke rij in de tabel "authors" een kolom met de naam "id" heeft gekregen. Dit "id" is een uniek nummer. Elke keer je aan de tabel een rij toevoegt, wordt dit id met één verhoogt. Als je een rij verwijdert, behouden de andere rijen hun nummer. Als je rij met id 2 zou verwijderen, zal rij 3 gewoon het id "3" blijven houden.
We noemen de eerste kolom van de tabel "articles" eveneens id. Ook deze kolom heeft de hierboven beschreven kenmerken. Je merkt dat de laatste kolom de benaming "authorid" heeft gekregen.
| id | title | articledate | articletime | cover | content | authorid |
| 1 | Sinterklaas komt om het leven | 05/12/2018 | 06/12/2018 10:22:10 | images/sint.jpg | Op 5 december viel Sinterklaas van een dak. Hij kwam hierbij om het leven... | 1 |
| 2 | Trump laat haar kleuren | 03/01/2019 | 04/01/2079 11:10:20 | images/kuif.jpg | Trump gaat voortaan door het leven met bruin haar... | 3 |
| ... | ... | ... | ... | ... |
|
... |
Het artikel met id 1 heeft als authorid 1, artikel met id 2 krijgt als authorid 3. D.w.z. dat "Sinterklaas komt om het leven" geschreven is door Joske Janssens. Het artikel over Trump is dan weer geschreven door de auteur met id "3" oftewel Achmed Birandouni.
De meeste hostingmaatschappijen bieden standaard MySQLaan als databanksoftware. De hierboven beschreven tabellen, kan je aanmaken in een databank op je hostingpakket. Als een hostingmaatschappij MySQL aanbiedt, dan kan je de databank over het albemeen beheren via een online tool met de naam PHPMyAdmin. De interface schrikt op het eerste zicht wat af. Maar toch is het vrij makkelijk om de twee tabellen hier boven in PHPMyAdmin aan te maken.
Opgelet: Niet iedereen kan de databank openen en bekijken. Je moet over een gebruikersnaam en wachtwoord beschikken om tabellen te kunnen aanmaken. Die kan je zelf instellen in je persoonlijke hostingaccount.
In PHPMyAdmin maak je een nieuwe tabel aan door aan de linkerkant op "Nieuw" te klikken.
Je kan het aantal benodigde kolommen invoeren en een naam geven aan de tabel.
Bij "Naam" voer je de naam in van de kolom. Bij "type" bepaal je welk type informatie je in die kolom wil opslaan.
Een ID (de eerste kolom in onze beide tabellen) krijgt als "type" int. Een int of integer is een positief geheel getal (een natuurlijk getal). Je vinkt ook de optie "AI" aan (staat voor "auto increment" om de waarde automatish te laten verhogen. Vervolgens krijg je het onderstaande venster te zien. Klik op "Starten".
Velden zoals "title" en "content" (in de tabel "articles") en "name" en "email" (in de tabel "authors") krijgen als type "text" , "mediumtext" of "longtext" (afhankelijk van de hoeveelheid data die je per veld wil bewaren. Als je de optie "Leeg" aanvinkt, dan geef je aan dat het veld niet "moet" ingevuld worden, dat het ook leeg mag blijven.
Voor "articledate" kozen we als naam niet simpelweg voor "date" omdat dit problemen zou kunnen opleveren. Date en time... zijn wat men noemt " gereserveerde woorden", woorden die MySQL intern gebruikt om bepaalde types van data aan te duiden. Net zoals "text" en "integer" ook interne benamingen zijn. Die gebruik je dus best nooit als veldnaam.
Voor articledate kiezen we als type "date", voor "articletime" se
Voor dat veld stellen we een standaardwaarde in. Opgelet: als je een standaardwaarde (in dit geval timestamp) kiest, dan mag je de optie "leeg" niet aanvinken.
Via de tab "invoegen" kan je informatie aan elke tabel toevoegen. De bedoeling is dat we hiervoor achteraf een invoerformulier aan onze site toevoegen. Op die manier moet de "journalist" niet rechtstreeks in PHPMyAdmin aan de slag. Hij/zij kan via een eenvoudig invoerformulier (na wachtwoordtoegang) informatie toevoegen aan de tabellen.
Tijd voor automatisering. In een volgende stap genereren we automatisch een HTML-pagina met de inhoud van de tabel "articles".
In de vorige les hebben we een databank aangemaakt in MySQL. Het is de bedoeling dat we de data die in de tabel "articles" en "authors" zitten, gaan weergeven in een webpagina. Om de databankgegevens om te zetten in webpagina's gebruiken we een tussenliggende taal: PHP.
PHP is de tussenliggende taal of de middleware.
PHP kan op diverse manieren met een databank spreken:
1. Create : inhouden in de databank wegschrijven (bewaren)
2. Read : inhouden uit de databank lezen en weergeven (omzetten in HTML of wat anders)
3. Update : aanpassen van data in de databank (bijvoorbeeld als er een foutje in staat)
4. Delete : verwijderen van gegevens uit de databank.
PHP werkt op de server. Dat wil zeggen dat de code die je schrijft in PHP niet meer zichtbaar is in de browser van de websitebezoeker.
In deze les lezen we de gegevens die in de tabel "articles" staat uit, en zetten we die om in een HTML-pagina. In deze tabel bewaarde ik ondertussen (via PHPMyAdmin) de volgende gestructureerde gegevens:
Ik wil hiervoor de volgende structuur krijgen in mijn HTML-pagina. Je kan dit gerust het HTML-sjabloonnoemen:
<article> <h1>TITEL VAN DE RIJ</h1> <img src="AFBEELDING"/> <p>INHOUD VAN DE RIJ</p> </article>
Van je hostingprovider of via je hostingprovider krijg je de gegevens van je databank: het adres (host), de naam van de databank, de gebruikersnaam en het wachtwoord. Die gegevens heb je nodig om je databank te kunnen openen.
Je maakt nu een nieuw bestand in de map van je website met de naam read.php.
In je teksteditor plak je de onderstaande code.
<%NOTHING%?php
$servername = "ADRES of HOST";
$username = "GEBRUIKERSNAAM";
$password = "WACHTWOORD";
$dbname = "DATABANKNAAM";
// Maak de verbinding
$conn = new mysqli($servername, $username, $password, $dbname);
// Controleer de verbinding
if ($conn->connect_error) {
//breek de code hier af als de verbinding mislukt
die("Verbinding met de databank is mislukt: " . $conn->connect_error);
}
//se%NOTHING%lecteer alle rijen van de tabel 'articles'
$sql = "sel%NOTHING%ect * FROM articles";
//bewaar het resultaat van de zoekopdracht
$result = $conn->query($sql);
//als het aantal rijen groter is dan 0, zet de rijen dan om in HTML
if ($result->num_rows > 0) {
// maak een "loop" door alle rijen
while($row = $result->fetch_assoc()) {
//hier sluiten we de PHP-code even af om rechtstreeks HTML te kunnen schrijven
?>
<article>
<h1><?echo $row["title"];?></h1>
<img src="<?echo $row['cover'];?>"/>
<p><?echo $row["content"];?></p>
<sub><?echo $row["articledate"];?></sub>
</article>
<?
}
} else {
//Er staan geen artikels/rijen in de databank
echo "Geen artikels gevonden in de databank";
}
$conn->close();
?>
Als je de pagina nu opent in de browser, krijg je de output te zien in HTML. Bekijk je de broncode van je webpagina in de browser, dan zal je merken dat de PHP-code niet meer zichtbaar is.
De PHP-code hierboven is gebaseerd op codevoorbeelden van w3schools.com
In de les heb je de basis van CSS geleerd. Je hebt gezien hoe je elementen kan opmaken en hoe je ervoor kan zorgen dat bepaalde afbeeldingen links, en andere rechts worden uitgelijnd.
Bekijk de code van het HTML- en het CSS-bestand op deze pagina.
De bedoeling is dat je het HTML-bestand en het CSS-bestand zodanig aanpast dat een "article"-element de ene keer een witte tekst met zwarte achtergrond heeft, de andere keer een zwarte tekst met witte achtergrond.
TIP: je hebt hiervoor de volgende stijleigenschappen nodig.
color: white;
background-color:black ;
(of omgekeerd)
1. Download het ZIP-bestand hieronder. Pak het uit en pas het aan.
2. Meld je aan op www.schoolvoorbeeld.be/task
3. Maak een nieuwe map aan met de naam "oefening1".
4. Upload in die map je aangepaste bestanden.
Aan de vormgeving van je site begin je niet zo maar. Op basis van het CSS-frameworkbouw je vanaf volgende les de startpagina op.
Maak tegen volgende les op papier een draadmodel van hoe je startpagina er zal uitzien. Je uploadt een foto van dat draadmodel in je map via www.schoolvoorbeeld.be/task. Maak een map aan met de naam "oefening2" en plaats daarin een foto of PDF van je draadmodel.
Breng het originele document volgende les ook mee.
In de vorige les heb je geleerd hoe je artikels uit een MySQL-databank kan weergeven in een webpagina. De PHP-code op de server zet de rijen uit de tabel om in stukjes HTML-code. In deze les leg ik uit hoe je gegevens kan filteren uit de tabel. D.w.z. je wil net alles tonen, maar slechts bepaalde artikels die voldoen aan jouw zoekopdracht.
We starten met de code van de vorige les.
<!DOCTYPE html>
<html lang="nl">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" href="https://www.schoolvoorbeeld.be/css/cssbib.css">
<title>Paginatitel</title>
</head>
<body>
<div class="container">
<div class="row">
<div class="twelve columns">
<%NOTHING%?php
include "config.php";
// Maak verbinding
$conn = new mysqli($servername, $username, $password, $dbname);
// Controleer verbinding
if ($conn->connect_error) {
die("Verbinding met databank is mislukt: " . $conn->connect_error);
}
$sql = "se%NOTHING%lect * from articles";
$result = $conn->query($sql);
if ($result->num_rows > 0) {
// output data of each row
while($row = $result->fetch_assoc()) {
?>
<article>
<h3><%NOTHING%?echo $_row["title"];?></h3>
<p><%NOTHING%?echo $_row["content"];?></p>
</article>
<%NOTHING%?PHP
}
} else {
echo "Geen artikels gevonden in de databank";
}
$conn->close();
?>
</div>
</div>
</div>
</body>
</html> Het is heel normaal dat de PHP-code alle artikels omzet in HTML. We vragen immers om alle artikels uit de tabel "articles" op te halen:
se%NOTHING%lect * from articlesWe willen nu echter gaan filteren op de resultaten. Stel dat ik enkel de artikels wil waarbij het woord "sint" in de titel voorkomt:
se%NOTHING%lect * from articles where title like '%sint%'Het woord sint staat niet enkel tussen twee weglatingstekens, maar ook tussen twee %-tekens. Die duiden aan dat er voor en achter het woord sint al andere tekens mogen staan.
Indien je artikels zou willen zoeken waarvan de titels beginnen met "sint", dan zou je het volgende doen:
se%NOTHING%lect * from articles where title like 'sint%'se%NOTHING%lect * from articles where title = 'sint'se%NOTHING%lect * from articles where rubriek = 'sport'se%NOTHING%lect * from articles where title like '%sint%' or content like '%sint%'se%NOTHING%lect * from adressen where postcode=3300 and naam like '%janssens%'Een computer kan met behulp van software een heleboel taken automatiseren om de mens werk uit handen te nemen en vooral de benodigde (werk)tijd te verkorten. Toch beseffen velen nog steeds niet hoe ze dat precies moeten doen. De zoek-en-vervangopdracht in een tekstverwerkingsprogramma is daar een simpel voorbeeld van. In heel wat software kunnen steeds weerkerende taken met behulp van zogenaamde macroâs geautomatiseerd worden. Je voert een aantal taken uit terwijl de computer de uitgevoerde opdrachten stapsgewijs registreert. Nadien kan hij zelfstandig die taak herhalen. De lijst met instructies is vastgelegd in het geheugen van de computer. In automaten zitten de instructies eveneens in de machine.
De kennis van het bouwen van klokken en automaten ging niet volledig verloren in de middeleeuwen. Meer nog, heel wat kerken en kathedralen zijn uitgerust met op 'pinmechanismen' gebaseerde automaten. De kennis die Heron demonstreerde met zijn automatische theaters, was dus zeker niet verloren gegaan. Klokken, automaten, muziekdozen... Ze kenden een gemeenschappelijke evolutie en kruisbestuiving die rechtstreeks een invloed zou uitoefenen op de moderne computer- en robottechnologie.
In de loop van de eeuwen werden mechanische muziekapparaten ontwikkeld in opdracht van en voor de rijkere klassen (adel en geestelijkheid). De geschiedenis van de mechanische muziek is nauw verbonden met die van de klok en automatische poppen en beelden. In het Engels maakt men een onderscheid tussen de woorden clocken timepiece. Clockverwijst altijd naar het mechanische geluid dat het uurwerk produceert, terwijl een timepiecewel het tijdstip aangeeft, maar hierbij geen geluid laat horen.
Zowel in de moslimwereld als in het christelijke Westen waren klokken essentieel in de godsdienst beleving. Ze gaven aan wanneer de momenten van gebed en bezinning waren aangebroken. De historische bronnen zijn niet altijd volledig en vaak worden uitvindingen onterecht toegeschreven aan een bepaalde persoon of zelfs regio.
Het mag duidelijk zijn dat de ingenieurs in het Oosten en het Westen te rade zijn gegaan bij de klassieke voorbeelden, en soms eigen toevoegingen hebben gedaan. Bovendien werd niet altijd een strikt onderscheid gemaakt tussen klokken, automaten en mechanische muziekinstrumenten.
In wezen vinden we in de muziekdozen twee verschillende, maar toch op elkaar lijkende technieken:
Beide worden aan het draaien gebracht, waarbij ofwel de pinnen ofwel de gaten instructies doorgeven aan de rest van het mechanisme. Zonder twijfel is de cilinder met pinnen de oudste vorm voor het mechanisch doorgeven van instructies, zoals het produceren of reproduceren van muziek. Heron van Alexandrië (eerste eeuw na Chr.) maakte er al gebruik van.
Voor het oudst bekende door cilinders aangestuurde mechanische muziekinstrument moeten we naar het Bagdad van de 9e eeuw. De drie gebroeders Ahmad, Muhammad en Hasan bin Musa ibn Shakir, beter bekend als de BanÅ« MÅ«sÄ(zonen van Mozes, naar de naam van hun vader), waren in opdracht van de Abassidische kalief al-Maâmun actief in de astronomische observatoria van Bagdad en in het zogenaamde Huis van de Wijsheid (Bayt al-Hikma). Naar verluidt stuurden ze boodschappers naar onder meer Byzantium om op zoek te gaan naar originele of gekopieerde klassieke teksten over wetenschap en techniek. Muhammad zou zelf ook naar Byzantium zijn gereisd. Maandelijks betaalden ze meer dan 500 dinar aan een groep vertalers die de overgebrachte klassieke werken omzetten in het Arabisch.
...
In opdracht van de kalief verifieerden ze de door Eratosthenes berekende omtrek van de aarde, wat bewijst dat ze niet alleen goed onderlegd waren in de astronomie, maar ook in de wiskunde. De meeste bekendheid verwierven ze echter door hun boek KitÄb Al-Hiyal (Het boek van ingenieuze apparaten). Heel wat toestellen in dit boek zijn duidelijk geïnspireerd op de ontwerpen van onder meer Heron van Alexandrië, Philo van Byzantium en oudere Perzische, Indiase of misschien zelfs Chinese uitvindingen.
Toch hebben de broers overduidelijk hun eigen stempel gedrukt en veel ingenieuze toevoegingen bedacht. Het verschil zat hem in het gebruik van onder andere automatische zwengels, ventielen en conische kleppen als automatische reguleersystemen. Als geen ander wisten ze om te gaan met kleine variaties in aerostatische en hydrostatische druk om net dat doel te bereiken dat ze voor ogen hadden.
Een voor ons uitgangspunt belangrijk apparaat in de KitÄb Al-Hiyal is de automatische fluitspeler. Het toestel vindt zijn voorlopers overduidelijk in het werk van de Alexandrijnse ingenieurs Ktesibios, Heron en Philo van Byzantium. Velen zien de automatische door waterkracht aangedreven fluitspeler van de Musa-broers als het eerste programmeerbare muziekinstrument. Door de uitgebreide beschrijving van het uiterlijk en de werking weten we dat het toestel ook echt heeft gefunctioneerd en dat het niet zomaar gaat om een legende. Het zou ons te ver leiden als we de volledige werking van het toestel hier zouden uitleggen, maar we beperken ons tot het meest essentiële onderdeel: de programmeerbare trommel of cilinder om de melodie vast te leggen of weer te geven.

Door een fluit werd een constante luchttoevoer geblazen. Net zoals bij een blokfluit was hun automatische fluit voorzien van openingen voor de diverse âvingerzettingenâ. Dempers sloten de openingen van de fluit luchtdicht af. De dempers waren op hun beurt bevestigd aan houten armpjes of lichters. Een groot tandwiel werd in beweging gebracht door een constante waterstroom. Dat zette op zijn beurt een kleiner tandwiel in beweging dat een trommel of cilinder liet roteren. Op de cilinder waren vermoedelijk houten pinnen aangebracht die tijdens het roteren de armpjes of lichters naar beneden drukten, waardoor de dempers van een of meerdere openingen werden opgelicht, de lucht kon ontsnappen en de melodie weerklonk. Het spreekt voor zich dat de snelheid van de watertoevoer bepalend was voor de snelheid van het afspelen van de muziek. Ze voorzagen in hun beschrijving ook de mogelijkheid om de hele constructie te verbergen in een standbeeld van een fluitspeler, waarbij de vingers werden benut als lichters en de trommel werd verstopt in de mouw.
Een nog veel grotere uitdaging was het vastleggen van de melodie. Ook daarbij gingen ze uiterst inventief te werk. Hun beschrijving om de vingerzettingen van een echte fluitspeler te registeren en die melodie op de cilinder over te zetten, is niet alleen zeer duidelijk maar vooral ook onwaarschijnlijk ingenieus! De Musa-broers lieten zich hier duidelijk inspireren door de houten, met was bestreken bordjes die de leerlingen van de basisschool van Byzantium als schrijftabletjes gebruikten. Ze bestreken een houten of messing cilinder met zwarte was. Een constructie van lichters werd aan één zijde aan de vingers van een echte fluitspeler bevestigd.
Aan de andere kant hechte men er stiften aan die boven de met was bestreken trommel hingen. Wanneer de fluitspeler zijn melodie speelde, tekenden de stiften in de was van de roterende trommel een patroon telkens als de fluitspeler zijn vingers oplichtte. Zo verkregen ze een nagenoeg perfecte weergave van de melodie in de waslaag. Gelijkenissen met de eerste fonograaf met wassen cilinders van Edison zijn hier niet uit de lucht gegrepen! Uiteraard moesten ze dit patroon dan nog overzetten op een kleinere cilinder.
Niet alle onderdelen of uitbreidingen van de automatische fluitspeler zijn even goed uitgewerkt, maar de broers zagen duidelijk een massa mogelijkheden. Zo bedachten ze dat het mogelijk moest zijn om de cilinder opzij te laten schuiven nadat een melodie afgespeeld was. Dat wilden ze bereiken door de trommel met een touw vast te maken aan een vlotter. Door op het juiste moment een watervat met sifon te laten leeglopen, kon de zakkende vlotter de trommel opzijtrekken en vervangen door een andere.
In Toledo wekte de waterklok van al-Zarqali in de 11e eeuw verbazing en ontzag. In de 12e eeuw bouwde de ingenieur Badi al-Zaman al-Jazarieen tot de verbeelding sprekende waterklok in de vorm van een Indische olifant met op zijn rug Chinese draken, een feniks en allerlei Arabische figuren. Hij beschreef de klok uitgebreid in zijn Kitab fi maârifat al-hiyal al-handasiyya (Boek der kennis van mechanische toestellen).
...
Net zoals de BanÅ« MÅ«sÄ liet hij zich inspireren door klassieke voorbeelden. In het christelijke Praag werd de astronomische klok in de 14e eeuw uitgerust met een reeks âautomatenâ. In Europa waren vooral de Lage Landen en Zuid-Duitsland toonaangevend. Samen met zijn vader verhuisde de klokkenmaker Nicholas Vallin (1558â1603) in de jaren 1580 vanuit Rijsel (Lille) naar Engeland. Het British Museum bewaart nog steeds een prachtexemplaar van een muzikale kamerklok van zijn hand. Het toestel heeft een wijzerplaat met wijzers voor uren en minuten. Elk kwartier speelt de klok een ander stukje muziek op de dertien bellen die bovenaan bevestigd zijn. Naar klassiek voorbeeld wordt de klok aangedreven door gewichten.
De Alexandrijnse ingenieur Ktesibios rustte in de derde eeuw voor Christus zijn waterklokken al uit met zingende vogels. De automatenbouwers van de 18e eeuw wilden hun vogels niet alleen laten zingen, maar vooral ook levensecht maken. Beroemd is de mechanische eend van Jacques de Vaucanson (1709â1782), die kon eten, drinken en... uitwerpselen produceren. De Londense juwelier en goudsmid James Cox (1723â1800) liet zich door de juiste mensen omringen om zijn ongebreidelde fantasie in de realiteit om te zetten. Zijn roem bezorgde hem klanten in oost en west. In 1772 opende hij een eigen museum, de Spring Gardens, waar hij zijn automaten onderbracht. Om de kosten van deze wel erg dure operatie te drukken organiseerde hij loterijen in Londen en Dublin. In de collectie van het Hermitagemuseum in Sint-Petersburg bevindt zich nog steeds de Peacock Clock, een prachtige automaat van Cox bestaande uit onder meer een mechanische pauw, haan en uil en een wijzerplaat verstopt in een paddenstoel. De automaat is nog steeds het pronkstuk van het museum en bovendien de enige nog resterende 18e-eeuwse automaat.
Om ruimte te besparen verving Antoine Favre-Salomon (1734â1820), een klokkenmaker uit Geneve, in 1796 de belletjes door een kam met voorgestemde metalen noten. Daardoor konden uurwerkmakers mechanische muziektoestellen inbouwen in veel kleinere toestellen. Zijn stadsgenoot Isaac Daniel Piguet (1775â1841) zou vier jaar later de cilinder vervangen door een horizontaal geplaatste schijf met pinnen. Nauwelijks elf jaar later nam de productie van muziekdozen ongeveer 10% in van de Zwitserse export, waarmee ze de verkoop van uurwerken en kant ruim voorbijstak. Voor het eerst bereikten de muziekdozen een groter publiek.

En wat met Leonardo die zo wat overal opduikt en vaak wordt afgeschilderd als het grote genie van de renaissance?
Leonardo da Vinci was niet alleen schilder, maar ook ingenieur en beeldhouwer. Hij las gretig de vertalingen van Heron en Vitruvius, en bestudeerde de verschillende onderdelen van de machines. Hij noemde ze de âelementenâ of âorganenâ van de machines. Door die onderdelen op allerlei manieren te combineren kon je in zijn ogen een oneindig aantal machines bedenken en bouwen. Wanneer je de werken van Da Vinci bekijkt, doen ze vaak denken aan de handleidingen uit dozen Lego® Technics.
Modulair ontwerp, zoals dat tegenwoordig ook opduikt bij het zogenaamde object-georiënteerde programmeren, duikt dus ook al in zijn geschriften op.
In zijn teksten beschreef hij welke soorten schroeven, tandwielen, vliegwielen, kogellagers, kettingen, veren, katrollen enzovoort er bestaan en hoe je ze maakt. Hij voorzag zijn teksten van uitgebreide technische tekeningen in perspectief. Zelf ontwierp hij een hele reeks machines: oorlogstuig zoals mortieren en tanks, baggerschepen, vliegtuigen, een helikopter, een duikpak, een hydraulische zaag... Velen denken dat hij prototypes van die geniale vondsten zelf heeft uitgetest. Toch is het grootste deel van zijn uitvindingen nooit in praktijk gebracht.
Leonardo da Vinci was ervan overtuigd dat de natuur geen levende wezens kan laten bewegen zonder daarbij gebruik te maken van âmechanische onderdelenâ. Daarom voerde hij in het geheim dissecties uit op lijken om de werking van de menselijke organen en spieren te bestuderen. Uit wat hij leerde, raakte hij ervan overtuigd dat het mogelijk moest zijn om organen of werkende organismen na te bouwen. Eeuwen voordat ze opnieuw werd ontdekt, vond hij aderverkalking en de oorzaak ervan. Door het nauwkeurig bestuderen van botten en spieren slaagde hij erin om de eerste ârobotsâ te bouwen die zich âzelfstandigâ konden bewegen.
In 1550 schreef Giorgio Vasari (1511â1574) in zijn boek over het leven van de belangrijkste Italiaanse kunstenaars:
"Toen Leonardo da Vinci in Milaan was, kwam de koning van Frankrijk op bezoek. Hij vroeg hem iets speciaals te doen. Da Vinci ging aan de slag en presenteerde hem een leeuw die een paar stapjes zette en zijn borstkas opende, waar tal van lelies uit tevoorschijn kwamen."
De Amerikaanse robotexpert Mark Rosheim bestudeerde de Codex Atlanticus van Da Vinci in de hoop sporen te vinden van die robotleeuw. Hij is ervan overtuigd dat Da Vinci de leeuw op een mechanisch programmeerbaar wagentje had geiÌnstalleerd. Een veermechanisme deed wielen draaien, die op hun beurt kleinere wielen in beweging zetten. Die stuurden houten armen aan, waaraan een soort schaarmechanisme was bevestigd. Door de armen volgens een vastgelegd plan te laten bewegen kon het karretje rijden en ook draaien.
Leonardo was niet de enige die vruchtbaar gebruikmaakte van de kennis van automaten die via vertalingen van klassieke en hellenistische werken doorsijpelde. Gedurende de middeleeuwen, die vaak als een donkere periode zonder vooruitgang worden afgeschilderd, kenden automaten en klokken een sterke ontwikkeling. Leonardo is dus niet het grote genie die het programmeren van robots heeft bedacht. Hij kon buigen op een grote traditie in Europa, een traditie die haar oorsprong vond in het Egyptische Alexandrië van de oudheid.
Basile Bouchon, zoon van een orgelbouwer, bedacht al in 1725 een manier om een weefgetouw aan te sturen met een geperforeerde rol papier. Bouchons vader maakte cilinders met pinnen voor orgels. Om de pinnen op de juiste plaatsen aan te brengen in de cilinder, tekende hij eerst een patroon op een kartonnen plaat. Die plaat draaide hij vervolgens om de cilinder waardoor hij precies wist waar hij de pinnen in de cilinder moest slaan. Basile meende dat het handiger zou zijn de kartonnen platen zelf te gebruiken. Het was Jacquard die het systeem als eerste succesvol wist te implementeren.
Het
ponskaartsysteemzien we in de 19e eeuw ook opduiken in muziekdozen en pianolaâs. Ponskaarten werkten op een vergelijkbare manier als pin- of kamsystemen. In het geval van muziekdozen kon door de gaatjes lucht van een blaasbalg ontsnappen of er konden pinnetjes door schieten die instructies gaven aan de rest van het mechanisme. Bij Jacquard sprongen pinnen op door de openingen in de ponskaarten en lieten het weefgetouw een bepaald patroon weven. Het grootste voordeel van een ponssysteem was dat je veel meer instructies achter elkaar kon laten uitvoeren door de machine. Bij een cilindersysteem met pinnen of kammen was je beperkt door de omtrek van de cilinder. Ponsplaten kon je oprollen of opvouwen en door het mechanisme laten schuiven bij het uitvoeren van het programma. De wevers van Lyon vreesden voor hun werk en verbrandden het weefgetouw in 1808, zo vertelt het verhaal. Blind protest tegen een niet te stuiten innovatie. Maar dit verhaal klopt niet. Van die brand is helemaal geen sprake geweest. Het verhaal duikt voor het eerst op aanvang 19e eeuw.
Al snel zag men ook op andere vlakken van de samenleving het nut van een ponskaartsysteem. Je kon op een ponskaart allerlei soorten informatie in gecodeerde vorm opslaan en het geautomatiseerd laten uitlezen. Charles Babbage(1791â 1871) tekende plannen voor een analytische rekenmachine en voorzag de invoer van ponskaarten. Zijn plannen betekenden een serieuze stap voorwaarts in de ontwikkeling van een rekenmachine. Eerder bouwde de Fransman Blaise Pascal (1623â1662) een mechanische rekenmachine, maar die was nooit een succes geworden. Ook de machine van Babbage kwam niet veel verder dan de ontwerptafel.
De computer met ponskaarten van Babbage baande via bedrijven als IBM zijn weg naar de moderne industrie. Die veroveringstocht kwam nog niet tot zijn einde.
Zo lijkt dit verhaal rond. Mijn ontdekkingstocht naar de oorsprong van computertechnologie, robotica, programmeren en automatisering, begon op de zolder bij mijn ouders. Het bracht ons tot het Alexandrië van de Klassieke Oudheid. Misschien een woordje meer over dit Silicon Valley van de Klassieke Oudheid.
Als je gewend bent om te werken met kantoorprogramma's zoals teksverwerkers (MS Word, LibreOffice...) en presentatieprogramma's (zoals MS Powerpoint, Apple Keynote...), dan ben je gewend om teksten en foto's en vormgeving samen te voegen in één bestand. Als je een bestand van je tekstverwerker doorstuurt naar vrienden, dan ben je er zo goed als zeker van dat de foto's die je aan het document hebt toegevoegd, nog steeds in dat document zitten als de bestemmeling het bestand opent. Enkel de lettertypes kunnen wat problemen geven.
Bij een website werkt het net iets anders. Een website bestaat uit een reeks afzonderlijke bestanden en een reeks mappen.
Op de afbeelding hieronder zie je een voorbeeld:
Ook al toont een webpagina afbeeldingen tussen de tekst, de afbeeldingen zijn steeds gelinkt. Ze staan extern, meestal in een afzonderlijke map (in dit geval de map 'images'). Als je een webpagina opent in een browser, dan weet de browser dat hij die foto's moet gaan zoeken in de map op de webserver.
Stel dat je domeinnaam www.blabla.beis, dan zal het adres van de afbeelding www.blabla.be/images/banner.jpgzijn. Zo zie je dat het adres dat in je browserbalk verschijnt, ook effectief een mappenstructuur weergeeft (images/banner.jpg).
Ook video's of kaarten die in een webpagina getoond worden, staan niet "echt" in de webpagina. Ze worden "ingesloten", zoals je een foto achter een frame steekt in een kader. Kaarten komen vaak van Google Maps of OpenStreetMaps, films van YouTube of VIMEO...
Webpagina's staan altijd in de basismap en eindigen op de uitgang .html, zoals een Worddocument eindigt op .doc of .docx. De opmaak van een webpagina (kleuren, lettertypes, afmetingen, posities...) staat beschreven in afzonderlijke documenten met de uitgang .css (in het voorbeeld style.css in de map style).
Een voorbeeld van CSS-code uit een stijlbestand:

De reden waarom stijlinformatie in een afzonderlijk document staat, is eigenlijk heel logisch. Als de eigenaar van een site de stijl van zijn/haar site wil aanpassen, dan moet hij/zij enkel dit ene stijldocument wijzigen. De site verandert dan meteen van uiterlijk zonder dat de inhouden opnieuw moeten ingevoerd worden.
Dankzij CSS kan de stijl van zeer grote sites in één oogwenk aangepast worden. De webmaster past het stijldocument aan en heel de site, of die nu één of 10 miljoen webpagina's bevat, verandert meteen van uitzicht.
Om die reden kan een site of online app zoals Facebook of Instagram er na een nachtje slapen plots volledig ander uitzien. Als een bedrijf zoals Facebook het CSS-bestand van hun site aanpassen, dan veranderen automatisch alle miljoenen profielen van uitzicht. Stel je voor dat je de huisstijl zou willen wijzigen in duizend Worddocumenten, dan zou je wel even wat tijd nodig hebben.
Als je een website of webpagina in je browser opvraagt of via een zoekmachine als Google opzoekt, dan stuurt de webserver waarop die pagina "staat", je een reeks bestanden door: HTML- en CSS-bestanden (zie hierboven) en eventueel afbeeldingen en andere bestanden.
Je browser krijgt al die onderdelen toe en bouwt met behulp van het stijldocument (het CSS-bestand) de hele site op in het browservenster.
Je kan het perfect vergelijken met een IKEA-zelfbouwpakket. IKEA (de server) stuurt je één of meer kartonnen dozen. Jij (de browser) opent die dozen en bouwt met behulp van de handleiding (CSS) de planken en schroeven (HTML, foto's, films...) op tot een kast (de zichtbare webpagina).
Naast HTML en CSS is er nog een derde "taal" van cruciaal belang in moderne websites: JAVASCRIPT. Dit is een echte "programmeertaal". Vergelijk het nogmaals met een IKEA-kast. Bij een kast kan achteraf ook deuren en schuiven open- en dichtdoen. De "gebruiker" kan "interactief" met de kast omgaan.
Op een website zullen op die manier slideshows, accordeon-effecten enz. met behulp van javascript worden geprogrammeerd. De webmaster kan code schrijven (of in veel gevallen gewoon ergens downloaden) om interactieve effecten aan de site toe te voegen.
SAMENGEVAT: DE FRONTEND (wat we van een site zien in de browser) WORDT GEBOUWD MET EEN COMBINATIE VAN DRIE TALEN: HTML, CSS en JAVASCRIPT.
Een "echte" webmaster zal een site in code bouwen in een teksteditor. Opgelet: een teksteditor is nog wat anders dan een tekstverwerker. Je kan er niet visueel pagina's in samenstellen. Je tikt code in in HTML of CSS of javascript. Je moet dus wel weten wat je aan het doen bent en hoe je dit moet doen.
De HTML-code van een webpagina in een teksteditor:
Over SEO heb je ongetwijfeld al veel gehoord. Voor de webmaster betekent dit dat hij/zij door aanpassingen aan de HTML-code de site beter begrijpbaar maakt voor zoekmachines. In boeken of online tutorials over SEO lees je doorgaans dezelfde tips op het vlak van SEO. Maar in veel gevallen lees of hoor je weinig over nieuwe manieren om je pagina's beter te laten scoren.
Zoekmachineoptimalisatie (Engels: search engine optimization of SEO) houdt in dat je door aanpassingen aan de HTML-code van je webpagina's, aan zoekmachines duidelijker kan maken waarover je webpagina gaat.
Een zoekmachine zoekt niet op het moment dat je een zoekopdracht ingeeft. Google maakt voortdurend een index van het ganse wereldwijde web. Hiervoor zet het bedrijf zoekrobots in. Dat zijn geen Star Wars-achtige robots, maar stukken software die websites bezoeken.
Je kan op heel eenvoudige wijze controleren hoe vaak je site is opgenomen in de Google-index/databank:
Tik de volgende zoekopdracht in in Google:

Als je één les hebt gekregen over SEO in je studieloopbaan, dan heb je ongetwijfeld al gehoord over metatags. Dat zijn stukjes HTML-code die je site beter begrijpbaar maken voor Google.
Je kan zelf controleren of die in een site of webpagina aanwezig zijn. Zet hiervoor de volgende stappen:
Bovenaan in de code moet je een regeltje vinden dat begint met
De regel in de HTML-code:

De titel in de zoekresultaten van Google:

De title-tag moet voor elke webpagina van je site anders zijn! Anders zou Google kunnen denken dat alle pagina's over hetzelfde onderwerp gaan.
Vaak hoor je dat de metatag "keywords" heel belangrijk is. De meeste zoekmachines houden er echter relatief weinig rekening mee omdat webmasters er vaak misbruik van gemaakt hebben om hun site beter te laten scoren. De metatag "description" is veel belangrijker. Vaak gebruikt Google die omschrijving om als tekstje in de zoekresultaten weer te geven.
De tags "author", "description" en "keywords" voor de website www.uitdenaad.be:

De tekst die als "content" bij de tag met de "name" "description" is ingevoerd (zie foto hierboven), verschijnt als tekst in de zoekresultaten bij Google. M.a.w. Google gebruikt de tekst die je zelf hebt ingesteld.
De site www.uitdenaad.bein Google:
Net zoals de title-tag, moet de description-metatag voor al je webpagina's verschillen. Anders meent Google dat al je pagina's over hetzelfde gaan.
Op https://webcode.tools/meta-tags-generatorkan je metatags en title-tags genereren voor al je webpagina's.
Een slimme webmaster voegt aan een site ook OG-tags toe. Sociale mediasites zoals Facebook, Twitter en Linkedin, gebruiken deze informatie als jijzelf of iemand anders één van je webpagina's deelt op hun site.
Met zulke OG (open graph)-tags kan je bijvoorbeeld instellen welke foto in facebook moet verschijnen als iemand één van je webpagina's deelt:
De OG-tags voor de site www.uitdenaad.be:

Het resultaat als je deze pagina deelt op Facebook:

Op https://webcode.tools/open-graph-generatorkan je zelf OG-tags genereren voor elk type informatie.
Een straffe uitspraak de titel hierboven, maar dan weet ik tenminste dat je dit even zal lezen. Als je als bedrijf een website hebt en daarnaast een afzonderlijke facebook-pagina of -groep, dan houd je de mensen weg van je site. Het is alsof één tijdens een uitzending de boodschap zou tonen om naar VTM te kijjken. Snap je?
Bovendien ben je dezelfde informatie meerdere malen online aan het publiceren. Vaak versturen bedrijven ook nog eens een nieuwsbrief, waarin nogmaals de zelfde informatie is opgenomen.
De meest geavanceerde manier om elk onderdeel van je pagina begrijpelijk te maken voor een "domme" zoekmachine, is door het toevoegen van JSON-LD-data. Dat zijn eveneens stukjes code in de bron van de webpagina die je site leesbaarder maken voor een zoekmachine.
Hieronder een voorbeeldje:

In het codevoorbeeld in de bovenstaande afbeelding zie je adresgegevens voor het bedrijf achter de website en een soort "schema" over de werking van de site zelf. Voor elk soort gegevens bestaat er wel een bepaald informatieschema. Op https://webcode.tools/json-ld-generatorvind je een tool waarmee je voor je eigen site JSON-LD-code kan genereren. Je kan zo'n blokjes code dus ook zelf maken en aan je webmaster bezorgen.
In een robots.txt-bestand op de website kan de webmaster bepalen welke bestanden en/of mappen een zoekmachine al dan niet mag bekijken en opnemen in de index. Hoe dit precies werkt, hoef je niet meteen te weten, maar Google vindt het wel fijn als er effectief zo'n bestand bestaat.
Controleer of er een robots.txt-bestand bestaat. Controleer of het bestand bestaat voor je eigen site door de domeinnaam in te voeren in de adresbalk van je browser (opgelet: niet in het zoekvenster van Google!), gevolgd door /robots.txt. Samengevat moet het er ongeveer als volgt uitzien: www.domeinnaam.tld/robots.txt
Een sitemap is een bestand op een website waarin een lijst met alle links naar de diverse webpagina's van je site zijn opgenomen. Vaak heet dit bestand sitemap.xml of sitemap.php. Ook hier hoef je niet te weten hoe dit in zijn werk gaat, maar het is wel belangrijk dat je site zo'n bestand bevat. Google kan zo makkelijker zien welke pagina's je site allemaal bevat.
Controleer of het bestand bestaat voor je eigen site door de domeinnaam in te voeren in de adresbalk van je browser (opgelet: niet in het zoekvenster van Google!), gevolgd door /sitemap.xml of /sitemap.php. Samengevat moet het er ongeveer als volgt uitzien: www.domeinnaam.tld/sitemap.xml
Liesbeth en Kris zijn innovatief in hun creaties en prettig-empathisch-volhoudend in de aanpak van hun projecten. Ze verstaan de kunst om op maat en met een vakkundig meesterschap, enthousiast kennis over te dragen.
Een overvloed aan kennis, die met passie en een ongebreidelde liefde voor het vak samengebracht wordt tot een kwalitatief product, om daarna nog eens extra overgoten te worden met een warme "Limburgse" gezelligheid. En dat laatste is iets waar ik als geboren en getogen Limburger toch recht-van-oordeel over heb, me dunkt ?
Voila, ik kan Liesbeth en Kris van Books&Bags niet op een andere manier omschrijven.
Als je de kans hebt, en je bent op zoek naar een product dat in hun expertise past, neem dan zeker eens de tijd om met een van hen (of allebei) een babbeltje te slaan. Ik garandeer u dat alles, wat hierboven beschreven staat, duidelijk zal worden.
Zo gaat dat nu eenmaal bij mensen die doordrongen zijn van datgene wat ze graag doen.
Toen we nog onderwijscollega's waren viel Liesbeth meteen op door haar enorme betrokkenheid bij het welzijn van de leerlingen. Verder was ze een uitmuntende lerares. Later bleek ook nog een ander talent op de voorgrond te komen binnen het domein van de handvaardigheid met het materiaal leder.
Kris was en is zo'n talentrijk man dat hij eigenlijk van alle markten thuis is. Hij is niet alleen de taalkundige en historicus maar eveneens een begenadigd muzikaal man en een computerwizard met daarnaast een meer dan gemiddelde in interesse voor stripverhalen. En last but not least ook meer dan een gemiddelde doe-het-zelver qua renovatiewerken. Beiden gaan ze steeds met volle overgave en passie ervoor om hun doelen te bereiken.










{kind=link}
{kind=link}
{kind=link}
{kind=link}